•
16-minute read
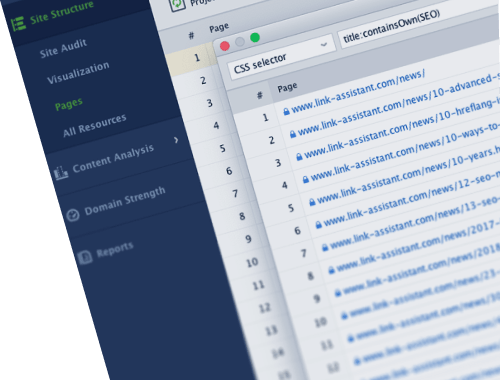

Custom Search is a great feature in SEO PowerSuite's WebSite Auditor that can power your technical SEO audit saving you tons of time on many tasks that used to take hours.
To help you make the most of Custom Search, I've put together some handy examples on how we use it at SEO PowerSuite — and how you can use it, too, for SEO, content marketing, and way beyond.
But before we get there…
Simply put, Custom Search is an option in WebSite Auditor that lets you look for specific pieces of content (text, HTML code, scripts, etc.) while crawling a site. These pieces can be fairly simple — say, if you're looking to find every mention of a certain SEO keyword on your website — and pretty complex — if you'd like to ensure that Google Tag Manager code is installed on your pages, appears at the right place in the HTML, and contains the correct tracking ID.
To get a feel of how Custom Search works, fire up WebSite Auditor (download it here if you don't already have it) and create a project for your site. Go to the Pages dashboard and click on the Custom Search button (mind that to use the option, you'll need a Professional or Enterprise WebSite Auditor license).
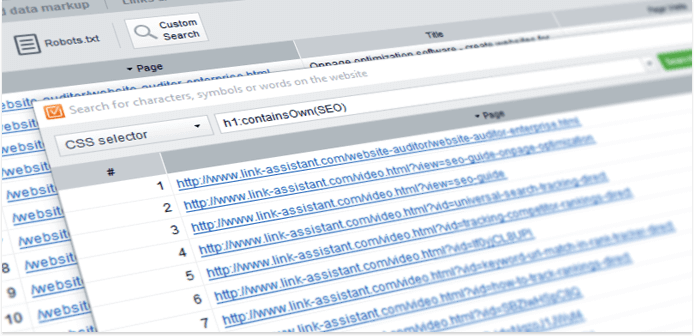
When you click on Custom Search, a pop-up window will appear asking you to input your query. There are 3 options, or search modes, to choose from: Contains, Does not contain, and CSS selector.
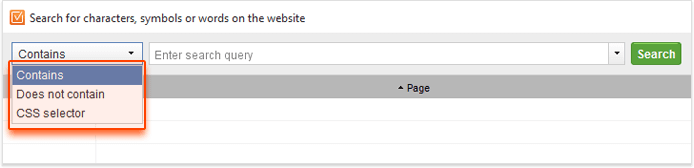
Contains will search for the exact match of the query in the HTML code of the site's pages.
Does not contain will do the opposite — search for pages that do not have the specified content in their HTML.
CSS selector will let you find occurrences of any selector you specify using CSS syntax (which can optionally be combined with regex using pseudo selectors). For a quick reference on how CSS selectors work in WebSite Auditor, jump to this article.
Whenever you make a search, the project site will be crawled according to the crawler settings specified in your project preferences. If you need to change these settings, click on the gear button next to the search bar before running a search:
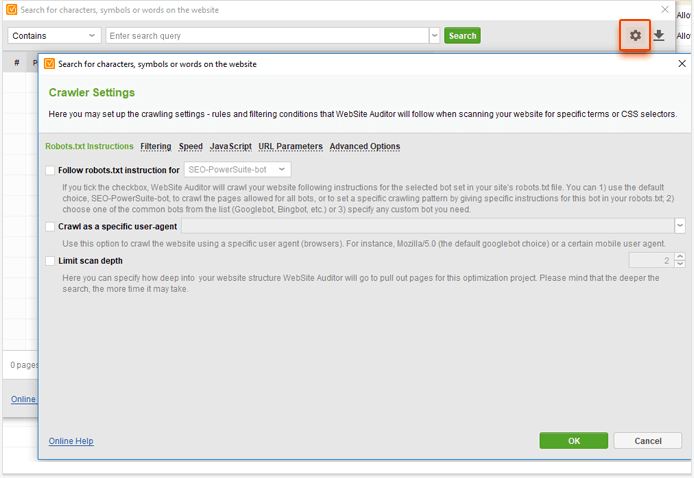
Here, you can select whether or not you want the crawler to follow robots.txt instructions, filter out certain pages or folders from the crawl, choose to execute JavaScript so that dynamically generated content gets crawled, and so on.
But enough with the theory — let's try using Custom Search on your own website.
How many tracking tags do you have on your website? Even if you "only" buy paid traffic from Google, Bing, Twitter, and Facebook and track SEO behavioral factors with Google Analytics, the number may well be over a dozen. Luckily, there's Google Tag Manager now — it keeps all your marketing scripts under one roof and makes it easier to control them. But even with Tag Manager, things can get (very) messy.
Let's say your website has been online for a while. It may have a blog, a forum, an online store, a bunch of old, static pages, and, to top these up, some fancy redesigned area steered by Drupal or Joomla. If at least some of that is the case, you'll likely end up with a dozen of scripts to control and a dozen of HTML templates they may hide in.
With Custom Search in WebSite Auditor, you can check if the Google Analytics or Tag Manager code is implemented across all of these pages, and, if not, which pages it's not on.
The simple way of doing this is by using the Contains (or Does not contain) search mode and typing in the specific code that you are looking for, such as, your Tag Manager tracking ID:
GTM-your_tracking_id
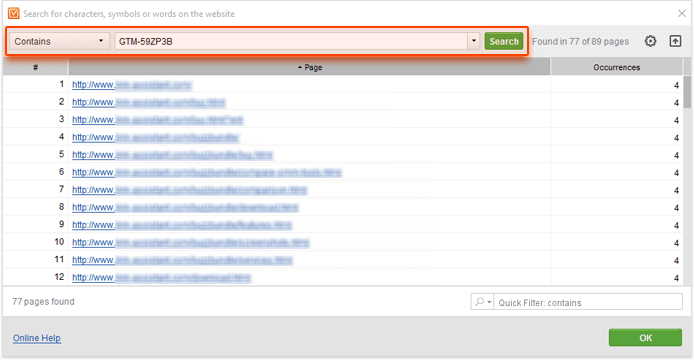
Voila — you've got a list of pages that do (or don't) have the tracking code implemented.
But hang on — what if the code itself is there, but it's not in the right places or is implemented incorrectly? This can frequently happen if your site has been online for a while and is relatively big.
To make sure GTM tracking is implemented correctly, using CSS selectors is your best option. The following selector will help you find all the pages that exactly match this criterion:
body > noscript:has(iframe[src$=GTM-your_tracking_id]):first-child
While it may look a little daunting at first glance, let's split this query into parts and see what it really does.
1. body > noscript selects all <noscript> tags that are direct children of the <body> tag.
2. :has() indicates that the element we've defined must contain the element specified in parenthesis.
3. iframe[src$=GTM-your_tracking_id] will search for an <iframe> tag that has an src attribute that ends with GTM-your_tracking_id, the ID of the Google Tag Manager container. Make sure to replace your_tracking_id with your own ID, such as "59ZP3B".
4. :first-child requires that the element (<noscript> in our case) must be the first child of its parent (<body>). This is important since to work properly, Google Tag Manager tracking code should be installed right after the opening of the <body> tag.
A quick search using this CSS selector gave me a list of pages which have the tracking implemented correctly:
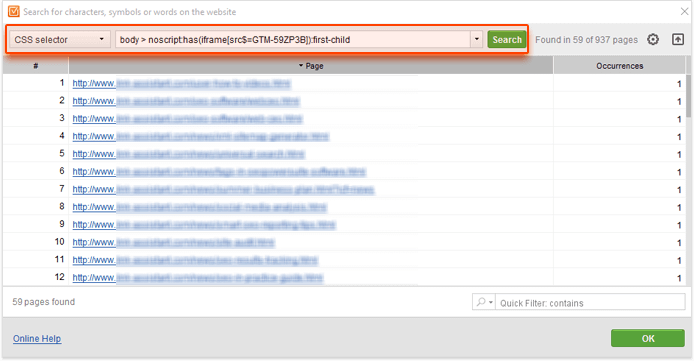
How time-saving was that? If you need to, you can view the matched fragment of the page's HTML without leaving the app. To do that, hover the mouse over the cell with the number of occurrences next to one of the records and click on the little Details button that appears:
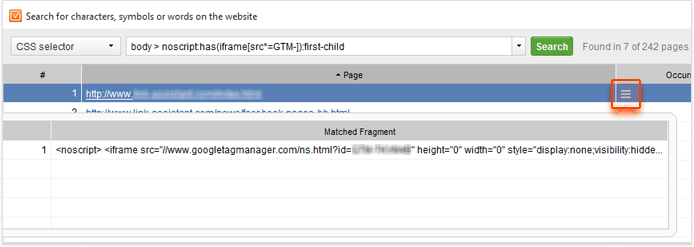
Once you have a list of pages with Google Tag Manager code installed correctly, it should be easy to match it with the list of pages that are supposed to have it and find errors.
There are many uses for Custom Search in on-page SEO; one is to make sure that the important elements of your pages contain the right keywords. In particular, you may want to pay closer attention to your titles, headings, image alt text, and meta tags.
Let's say, you are looking to find the pages on your site that contain your keyword in the title tag. In this case, your query may look like this:
title:containsOwn(your_keyword)
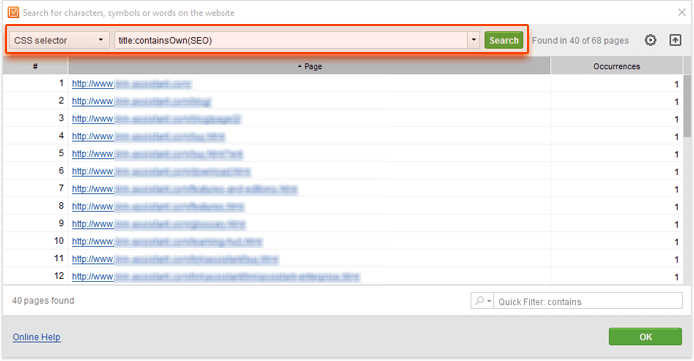
Similarly, if you are looking for H1 tags that contain a keyword, you may want to search using this query:
h1:containsOwn(your_keyword)
For meta descriptions, your query will look a little different:
meta[name=description][content*=your_keyword]
As you may have guessed, this query selects all <meta> tags with a name attribute that equals description and with a content attribute that includes your keyword.
Next, you you can put up the following query to search through images' alt text:
img[alt*=your_keyword]
Using similar logic, you can do the same for other page elements you are looking to dig through.
It is useful to go through your heading tags from time to time. If you do this now, I'm pretty positive you'll find out that some pages don't have an H1; some may have several; and others may be using the heading tags inconsistently. Let's see if this is the case on your site.
In your WebSite Auditor project, click on Custom Search. In the drop-down menu on the left, select Does not contain. In the search bar, type in:
<h1
Make sure to not include the closing ">", as your headings may have some custom attributes following the element's name. Finally, click Search.
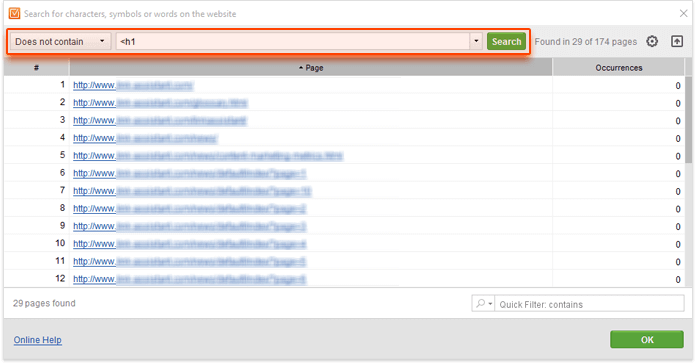
That's it: in a moment, you'll see the list of your pages that do not have an H1 heading. If you need to, feel free to copy the list of pages by hitting Ctrl + C (or Command + C if you're on a Mac).
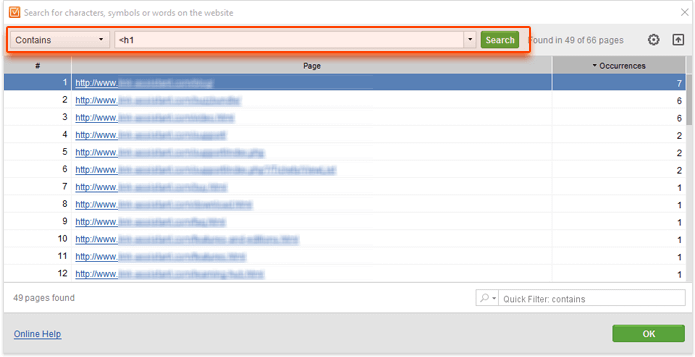
If you're looking to find pages that have more than one H1 tag, you'll need to choose Contains in the drop-down menu, and run the search for the same query:
<h1
When the search is complete, click on the header of the occurrences column to sort records by the number of occurrences. This way, you'll see pages with the biggest number of H1 tags first.
You may also want to check your pages against inconsistent use of all heading tags, e.g., pages where H2 headings come before H1 headings. In this case, you'd need to use the following CSS selector:
h2 ~ h1
In CSS syntax, ~ is used to select an element (H1 in this example) that follows a former element (H2).
If you are targeting users in a few different regions, you definitely know what hreflang is. Many sites serve visitors with content targeted to a certain region. Google uses the rel="alternate" and hreflang="x" attributes to serve the correct language and URL in its search results.
Perhaps the most commonly used way of specifying a hreflang link is using an HTML <link> element in the <head> section, like in this example:
<link rel="alternate" hreflang="es" href="/es/" />
With WebSite Auditor, you can now easily verify that all your pages have the hreflang tag in place, and implemented correctly.
Let's say, you're looking to identify pages that have a Spanish version specified in the link element. In this case, you may want to search in the Contains mode and use the following query:
hreflang="es-es"
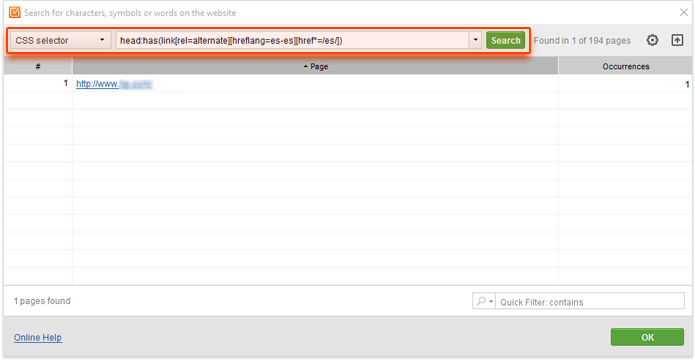
But again, if you're looking to dig to the bottom of things and make sure that the hreflang link is actually set up correctly, it's a good idea to use a more complex CSS selector for your search:
head:has(link[rel=alternate][hreflang=es-es][href*=/es/])
With this query, we are looking for all <head> HTML elements that contain a <link> element that has all of the following attributes: rel="alternate", hreflang="es-es", and their href attribute specifies any URL that contains /es/ in it.
In your WebSite Auditor project, you can easily check whether or not structured data markup is implemented on each of your pages even without Custom Search. To find it, go to the Open graph & structured data markup tab and look at the Structured Data Markup column.
But on top of knowing whether your pages have Schema markup or not, you may want to look for more specific Schema properties across your pages — especially if you're doing local SEO.
Some of the properties you may want to double-check are:
<span itemprop="streetAddress">your_address</span>
<span itemprop="telephone">your_phone</span>
<a itemprop="maps" href="your_google_maps_url">
But because these elements may have custom classes, IDs, titles, and what not, a search for an exact match in the Contains mode won't be very accurate. So… CSS selectors to the rescue!
Let's say you're about to check if the Telephone property is implemented correctly and contains the right phone number. Your CSS selector may look like this:
span[itemprop=telephone]:matchesOwn(your_phone)
This will select all <span> elements with an itemprop attribute set to "telephone", whose content matches the expression in the parenthesis:
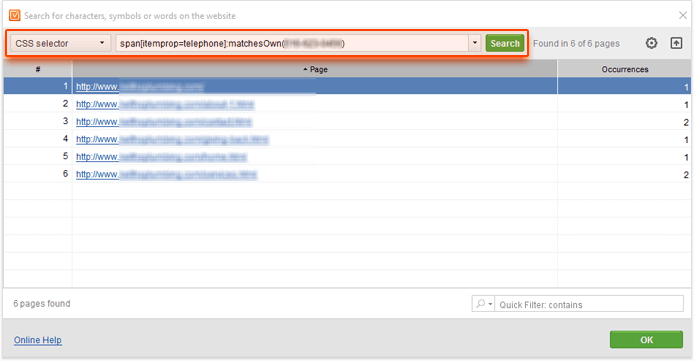
If you'd like to search pages that have an incorrect phone number in the Telephone property (rather than the ones with the correct one), use the following query:
span[itemprop=telephone]:not(:matchesOwn(your_phone))
Similarly, if you're looking for pages that use the Map property correctly, and that property contains the right URL, you may use this query:
a[itemprop=maps][href=your_google_maps_url]
For pages with an incorrect map URL specified in the property, use this one:
a[itemprop=maps]:not([href=your_google_maps_url]).
And so on, and so on.
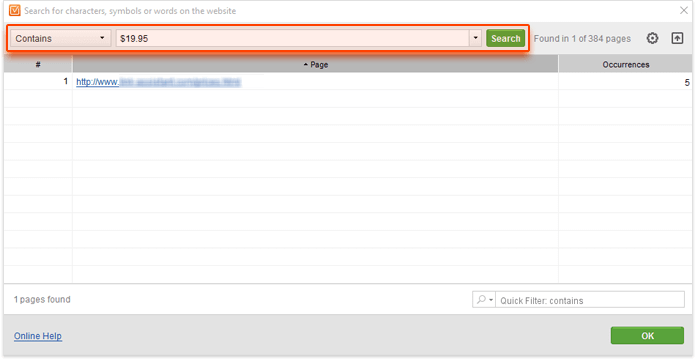
Say, you are changing the price for your product and need to look for instances of old pricing info on your site. Or, you are rebranding and need to make sure that your old brand name isn't mentioned anywhere. Or you are updating your business address and phone number. Custom Search is super helpful in finding traces of old, no-longer-relevant content that will surely pop up where you expect it least.
In most cases, all you need to do is run a simple query that includes your old price/company name/etc. and search for it in the Contains mode:
Internet marketers still argue about pros and cons of HTTPS (have a look at our takeaways from SMX East 2016 for a fresh take on the issue), and this post definitely isn't the place to go through them. Let's say you've already made your choice and decided to switch to HTTPS. The process is a lot of work — but you can save plenty of time on certain parts of it with Custom Search.
Here are a few things you might be willing to check and fix before you go HTTPS:
Let's start with canonicals. To identify canonical links that point to HTTP pages and need to be fixed, you can use the following query in the CSS selector mode:
link[rel=canonical][href^=http://]
It will help you find all <link> tags with a rel attribute set to "canonical" and a href attribute that starts with http://, like this one: <link rel="canonical" href="http://example.com/blog" />
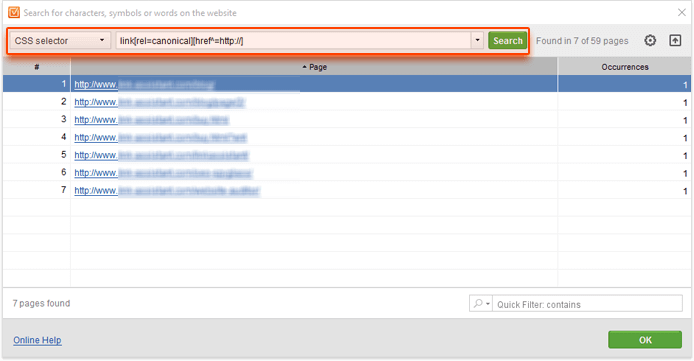
Next, you may want to check your internal links.
When you switch to HTTPS, you would normally set up a redirect that will force the display of the HTTPS page even if the user requests its HTTP version. Thus, all HTTP internal links will result in a redirect. On the one hand, the website will still function normally. On the other hand, additional redirects can slow down the page and waste your crawl budget.
There are two ways to fix that:
Whichever way you choose, a quick search using CSS selectors will help you find all absolute internal links that point to the HTTP versions of pages and need to be fixed. Your query may look like this:
a[href^=http://yourdomain.com]
This way, you'll be able to find all <a> elements that have an href attribute that begins with http://yourdomain.com — in other words, all absolute internal links pointing to the non-secure versions of your pages:
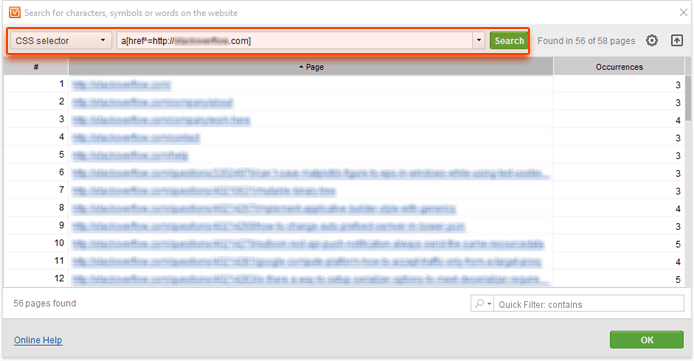
And lastly, you may want to make sure all resources — both internal and external — used on your HTTPS website are served via an encrypted connection. Otherwise, when someone visits one of your HTTPS pages, their browser will pop up a warning that says 'The page includes elements that come from unauthenticated sources'.
Images, videos, scripts, stylesheets, PDFs, and iframes are probably among the most frequently used resources on a page, so it's a good idea to double-check that all of those come from secure sources.
To detect non-secure images, scripts, and iframes, use this query:
*[src^=http://]
It will help you find all page elements whose src attribute that begins with http://:
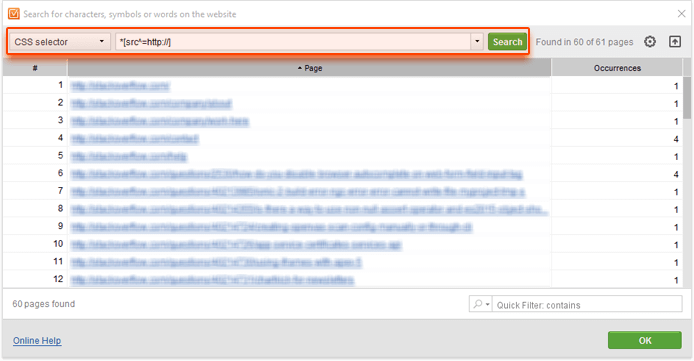
To look for non-HTTPS stylesheets, you'll need to use a different query, since the URL of the stylesheet is indicated not in the src attribute, but in the href attribute:
link[rel=stylesheet][href^=http://]
This will find all <link> elements with a rel set to "stylesheet" and with a href attribute beginning with http://.
Another helpful use for Custom Search is verifying that certain content — like social sharing buttons, comments, embedded videos and audios, and so on — is implemented consistently on your pages.
Let's say you are looking for pages that don't have social sharing buttons on your blog. The first thing to do is go to one of your blog posts in a browser, right-click the social sharing buttons, and click Inspect:
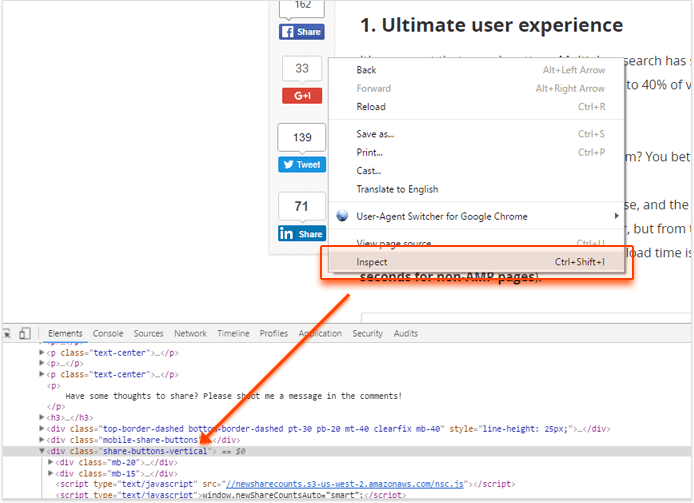
Next, you'd want to find the selector that you can use to find the buttons across all your posts; in the example above, a <div> element with a share-buttons-vertical class will be a good choice. To look for pages whose HTML doesn't contain this div, we can use the following CSS selector query:
html:not(:has(div.share-buttons-vertical))
This will look for pages whose HTML does not contain a <div> with a share-buttons-vertical class.
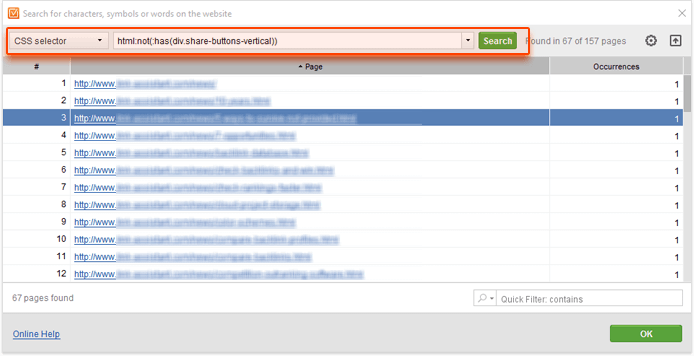
In the same way, you can search for any other piece of content — the embed code for YouTube, the Disqus iframe, etc. — across any site.
There are plenty of scenarios when you'd need to find a contact email address on a website, from link prospecting to building relationships with influencers to reaching out to potential SEO clients.
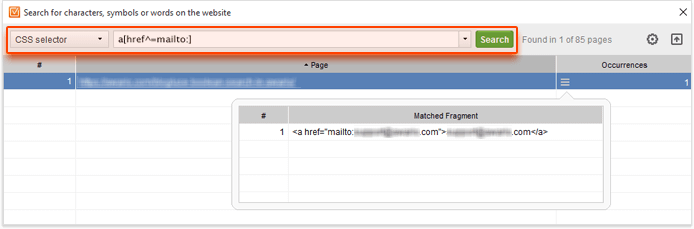
To do this with WebSite Auditor, you'll need to create a project for the website in question. Once the site has been crawled, navigate to the Pages module and click on Custom Search. Choose CSS selector in the drop-down menu, and type in:
a[href^=mailto:]
This query will let you find hyperlinks whose href attribute starts with mailto:.
But email addresses may often hide in the pages' text rather than the href attribute — that's why it's also useful to run an additional search for the following query:
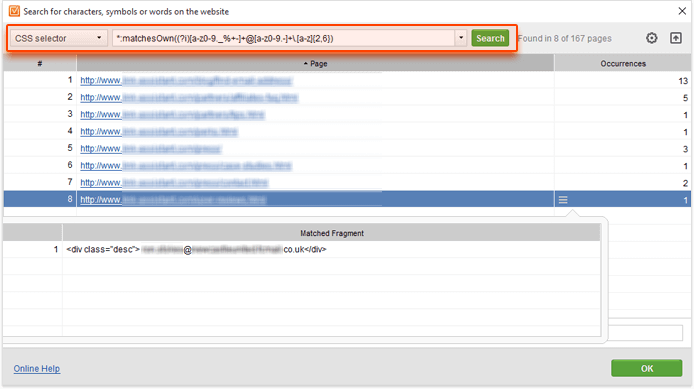
*:matchesOwn((?i)[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,6})
(This may look superfluously complex, but that's the common way of validating email addresses in regex. Using this query will ensure that you only find valid emails with proper syntax.)
Once you've found a few pages that match the query, click on the little Details button that appears upon hover in the Occurrences column to view the matched fragment. Now all you need to do is click Ctrl + C (or Command + C on a Mac) to copy the fragment.
This one is useful for anyone doing content marketing — it's a great way to discover valuable content ideas that have already worked great for someone else.
First, you'd need to launch WebSite Auditor and create a project for the site you're looking into, e.g., a competitor's site. (Mind that it may be useful to create your project for a specific directory or subdomain rather than the entire site, such as www.website.com/blog or blog.website.com.)
Now, let's say you want to look for posts with the biggest number of Twitter shares — definitely over 200. The first thing to do is open one of the posts on the site in your browser, find the Twitter share count on that page, right-click it, and hit Inspect (or Inspect element).
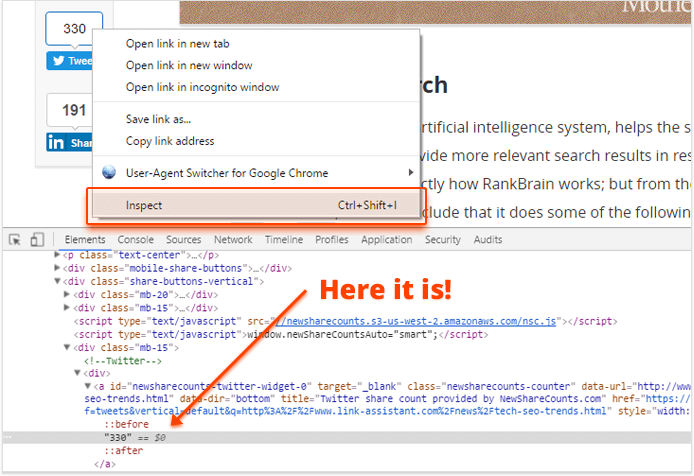
Now, you need to come up with a selector you would use to search for the Twitter share counts on that site. In my example, that's going to be the <a> element with a newsharecounts-counter class. So the query I'll be using to search for top shared posts will be:
a[class=newsharecounts-counter]:matchesOwn([1-9]\d{3,}|[2-9][0-9]\d)
Let's break it down to see what it does.
1. a[class=newsharecounts-counter] selects all <a> elements with class newsharecounts-counter.
2. :matchesOwn() selects only the previously specified elements whose text matches the regular expression defined in the parenthesis.
3. [1-9]\d{3,}|[2-9][0-9]\d is a regular expression for any number larger than 200. The [1-9]\d{3,} stands for any 4-digit number (1000 to 9999); | stands for "or"; and [2-9][0-9]\d is for any number between 200 and 999.
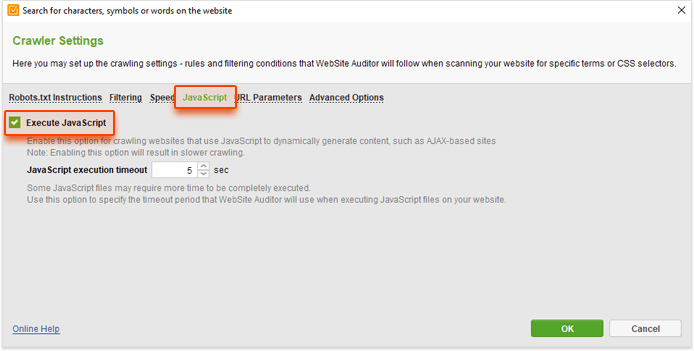
It is important to note that the social counters on blogs use JavaScript to display the data; that's why you need to enable rendering JavaScript in WebSite Auditor for this search. To do this, click on the gear button next to the search bar, go to JavaScript, and tick the Execute JavaScript box.
Click OK, and go on and run a search for your query:
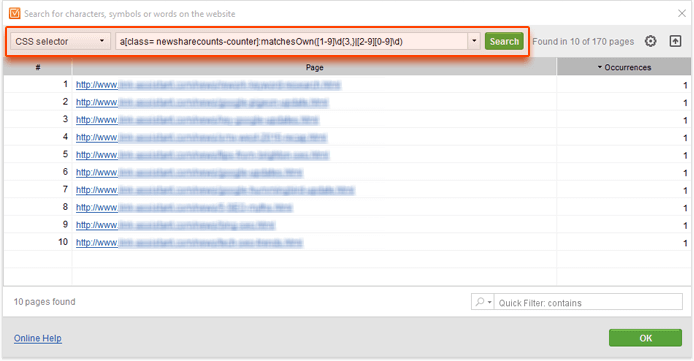
With this query, I found 10 posts on a blog I was looking through that have over 200 shares on Twitter. Neat, right?
As I said, these are only a few examples of what you can do with Custom Search. To help you dig to the bottom of things and formulate your own query, we've put up a full reference of CSS selectors with explanations and usage examples.
If you have any questions about using Custom Search or are not sure how to formulate a query to find what you're looking for — jump right to the comments and ask away!
As always, I'm looking forward to a great discussion in the comments below.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

