30696
•
8-minute read


It’s common to think of a crawl budget as something beyond our control. Or rather, it’s common not to think of a crawl budget at all. And yet, as our websites grow bigger, crawl budget becomes a major influence on our presence in search. In this article, I will discuss the importance of crawl budget, as well as share some practical advice on managing crawl budget for your website.
Crawl budget is the amount of resources Google is willing to spend crawling your website. It could be said that your crawl budget equals the number of pages crawled per day, but it’s not exactly true. Some pages drain more resources than others, so the number of crawled pages can vary even though the budget remains the same.
When allocating the crawl budget, Google will generally look at four things: your website’s popularity, update rate, number of pages, and the capacity to handle crawling. But even though it’s a sophisticated algorithm, there is still room for you to interfere and help Google manage the way it crawls your website.
Crawl budget determines how quickly your pages appear in search. The main issue here is that there could be a mismatch between the crawl budget and the update rate of your website. If it happens, you will experience a growing lag between the moment you create or update a page and the moment it appears in search.
One possible reason you are not getting enough crawl budget is Google does not consider your website to be important enough. So it’s either spammy or delivers a very poor user experience or probably both. In which case, there isn’t much you can do except publish better content and wait for your reputation to improve.
Another possible reason you are not getting enough crawl budget is your website is full of crawling traps. There are certain technical issues where a crawler could be stuck in a loop, fail to find your pages, or be otherwise discouraged from visiting your website. In which case, there are some things you can do to improve your crawling dramatically and we will discuss them further below.
Crawl budget could become an issue if you are running a large or a medium website with a frequent update rate (from once a day to once a week). In this case, a lack of crawl budget could create a permanent index lag.
It could also be an issue when launching a new website or redesigning an old one and there is a lot of change happening quickly. Although this type of crawling lag will eventually resolve on its own.
Regardless of the size of the website, it’s best to audit it for possible crawling issues at least once. If you are running a large website then do it now, if you are running a smaller website then just put it on your to-do list.
There are quite a few things you should (or should not) do to encourage search spiders to consume more pages of your website and do it more often. Here is an action list for maximizing the power of your crawl budget:
A sitemap is a document that contains all of the pages you want to be crawled and indexed in search.
Without a sitemap, Google would have to discover the pages following internal links on your site. This way it would take a while for Google to understand the scope of your website and to decide which of the discovered pages should be indexed and which shouldn’t.
With a sitemap, Google knows exactly how big your website is and which pages are meant to be indexed. There is even an option to tell Google what the priority of each page is and how often it is updated. With all this information available, Google can design the most appropriate crawling pattern for your website.
Note: It is important to mention that Google treats a sitemap as a recommendation, not an obligation — it is free to disregard your sitemap and choose a different crawling pattern for your website.
Now, there are many ways you can create a sitemap. If you are using a CMS platform, like Shopify, then your sitemap might be generated automatically and already available at yourwebsite.com/sitemap.xml. Other CMS platforms will definitely have SEO plugins offering a sitemap service.
If you have a custom-built website or you don’t want to burden your website with extra plugins, you can use WebSite Auditor to generate and manage your sitemap. Go to Site Structure > Pages > Website Tools > Sitemap and you will get a full list of your website’s pages. You can sort the pages by HTTP status and exclude the ones that cannot be accessed, as well as change pages’ priority, update rate, and last modified date:
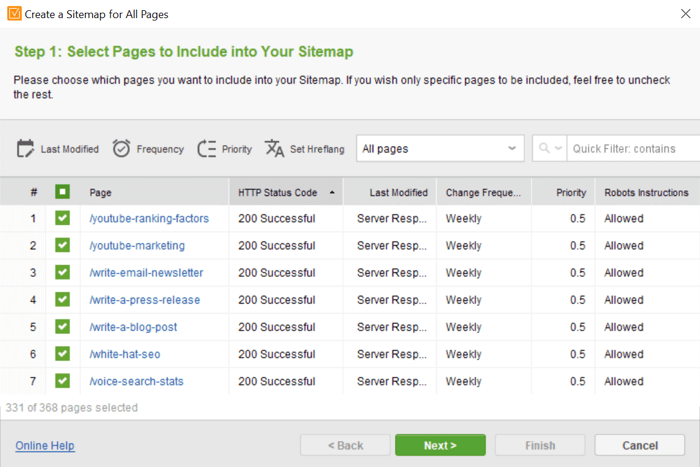
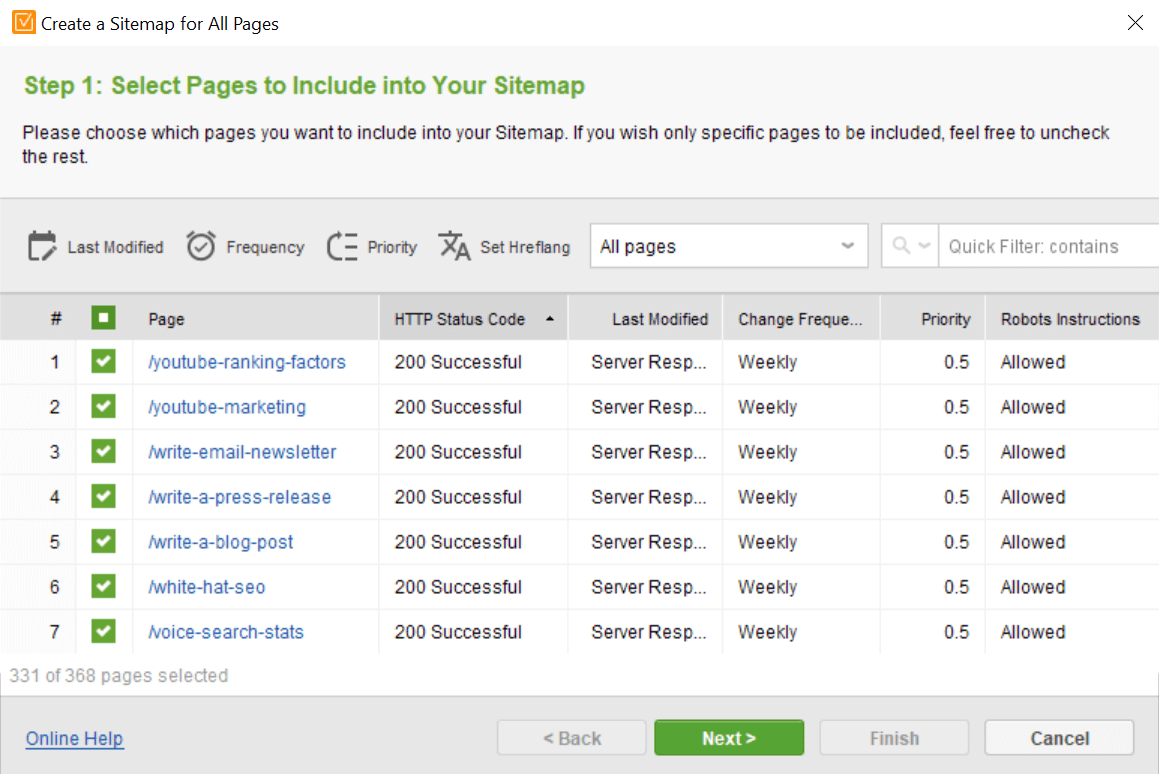
When you are done editing your sitemap, click Next and choose options for downloading the document — it will be automatically converted to proper sitemap protocol. You can then add the sitemap to your website as well as submit it to Google Search Console:
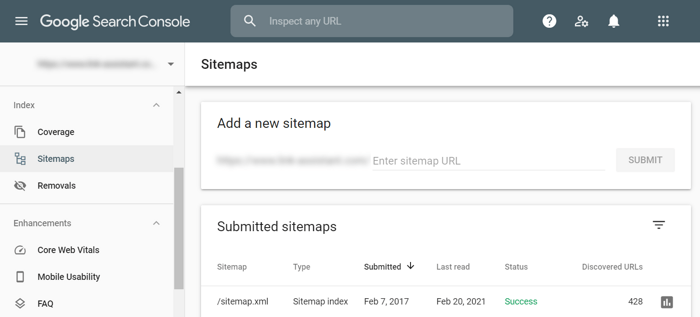
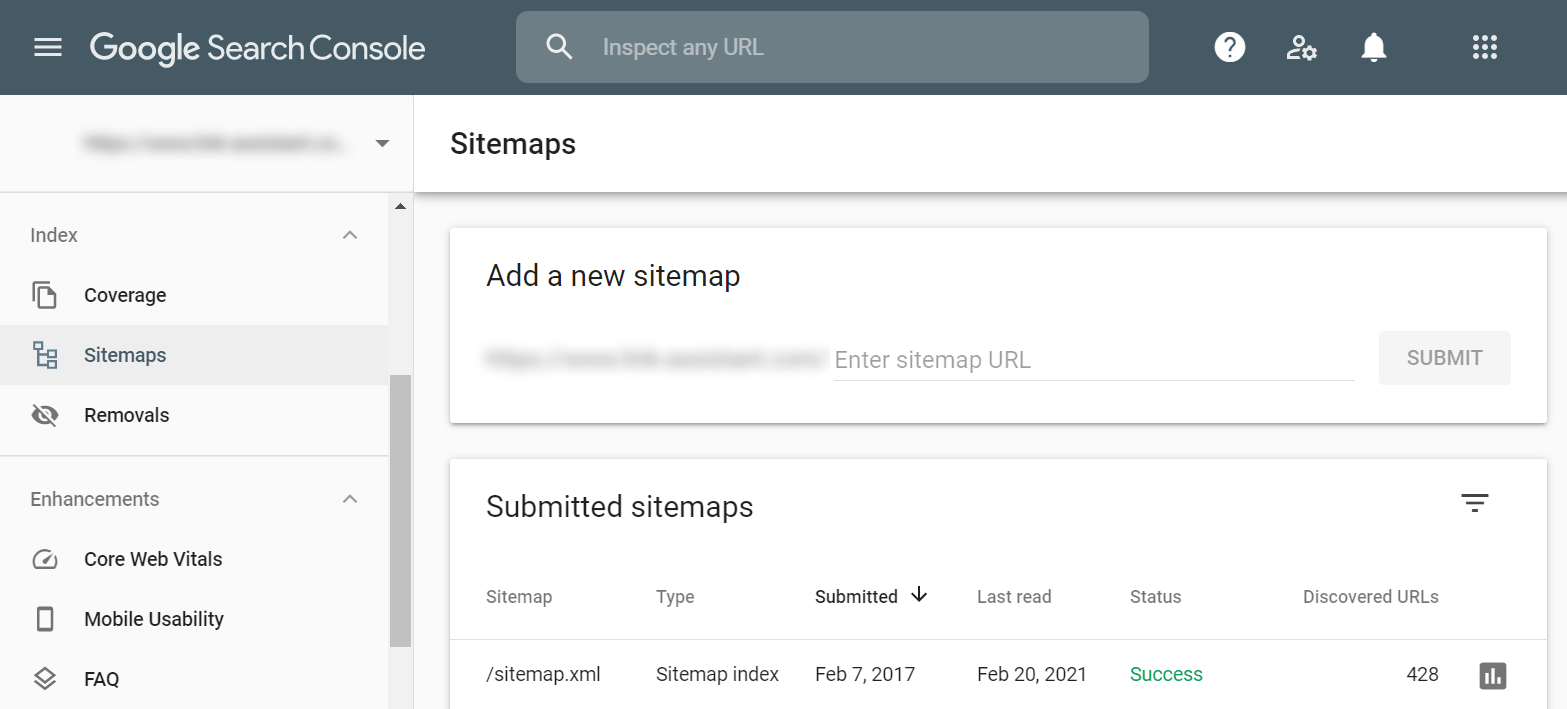
It is also common to have several sitemaps for the same website. Sometimes it’s done for convenience — it’s easier to manage thematically similar pages. Other times it’s done out of necessity — the sitemap document has a limit of 50K pages and if you have a bigger website you are forced to create several sitemaps in order to cover all of them.
One common crawling issue is Google thinks the page should be crawled but it cannot be accessed. In this case, one of two things might have happened:
Option 1. The page should not be crawled and it was submitted to Google by mistake. In this case, you have to un-submit the page either by removing it from your sitemap or by removing internal links to the page or possibly both.
Option 2. The page should be crawled and the access is denied by mistake. In this case, you should check what’s blocking the access (robots.txt, 4xx, 5xx, redirect error) and fix the issue accordingly.
Whichever the case, these mixed signals force Google into dead ends and waste your crawl budget unnecessarily. The best way to find and resolve these issues is by checking your Coverage report in Google Search Console. The Error tab is dedicated to crawling conflicts and provides you with the number of errors, error types, and the list of affected pages:
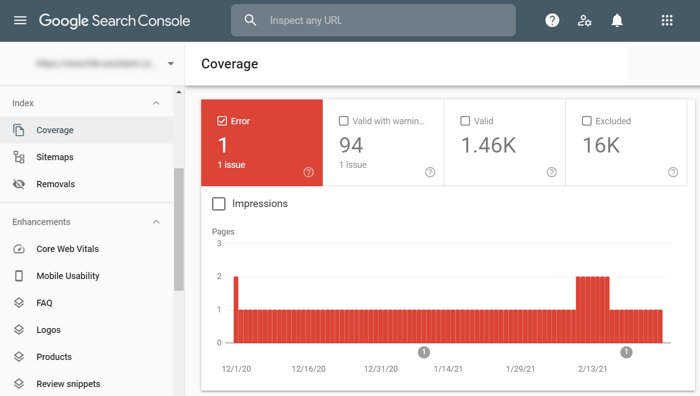
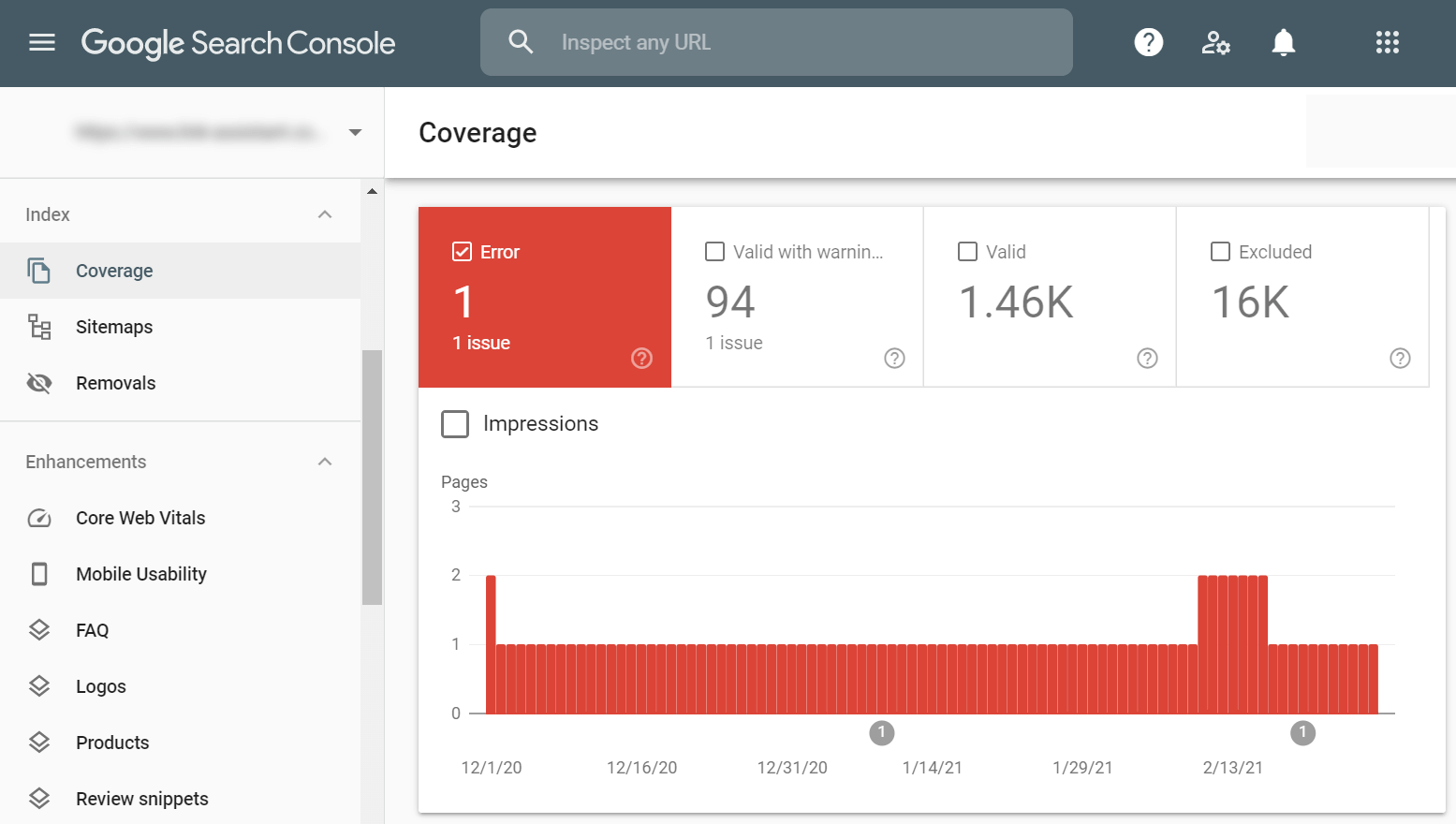
Another type of crawling conflict is when a page was crawled and indexed by mistake. This is obviously a waste of your crawling budget, but, more importantly, it could be a security concern as well. If you used the wrong way to block crawling, it could mean some of your private pages got indexed and are now publicly available.
To find such pages, it’s also best to turn to Google Search Console and its Coverage report. Switch to the Valid with warning tab and you will get the number of pages crawled, as well as suspected issues and the list of affected pages:
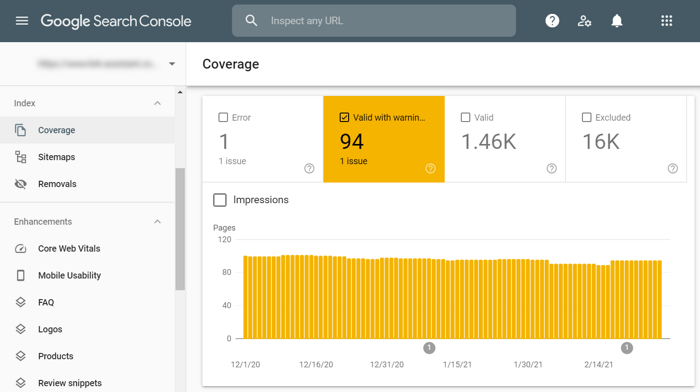
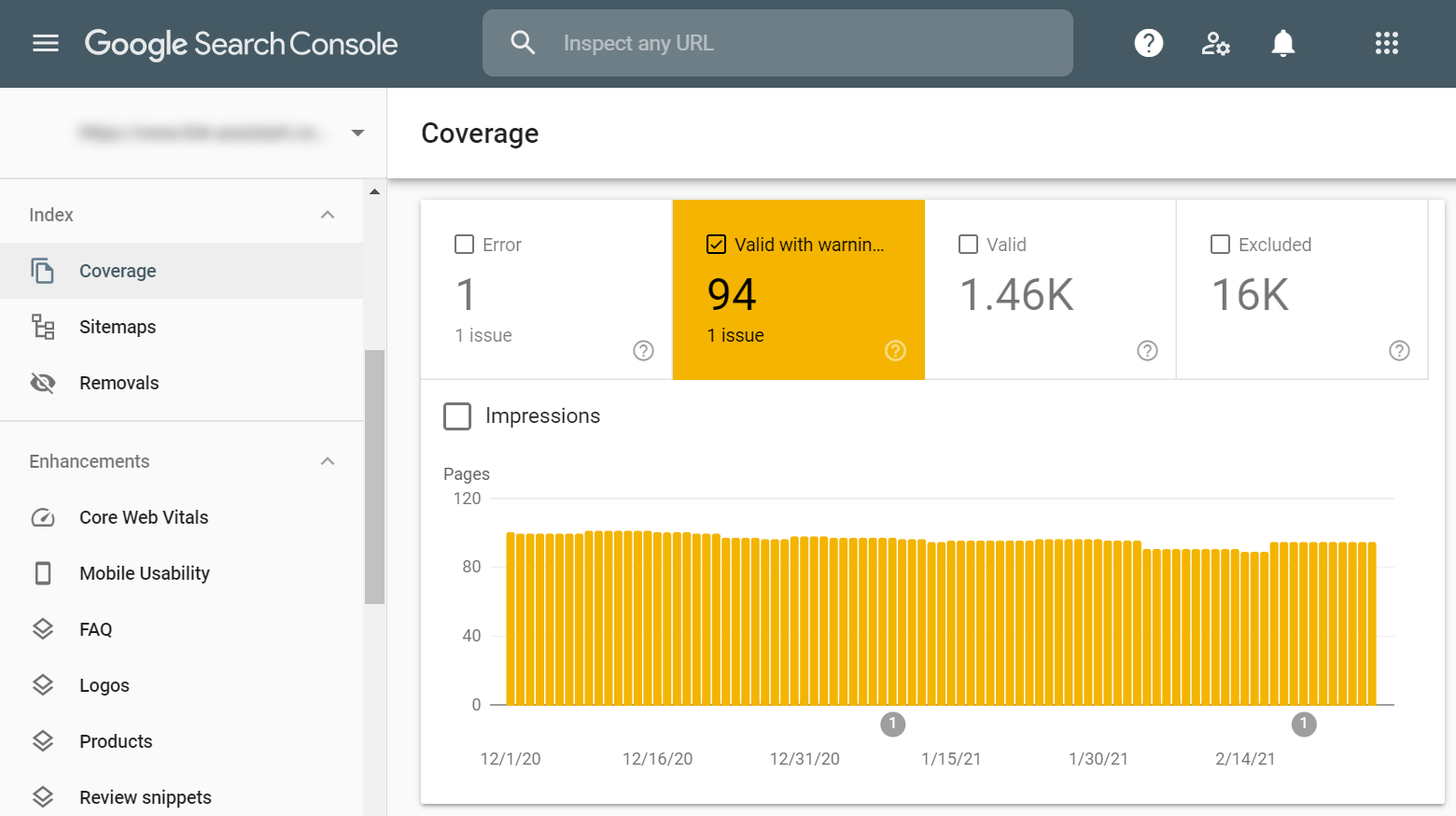
The most common issue with these pages is that they are blocked with a robots.txt file. It is still common for webmasters to use robots.txt in an attempt to stop the page from being indexed. At the same time, Google treats robots.txt instructions as a recommendation and may decide to still show ‘blocked’ pages in search.
To resolve these issues, review the list of pages and decide whether you want them indexed or not. If not, you have to use the noindex meta tag to block the crawler completely and then remove the page from search via Index > Removals > New request. If yes, you have to remove the page from the disallow directive of your robots.txt file.
You can save a good share of your crawl budget by telling Google to ignore non-essential resources. Things like gifs, videos, and images can take up a lot of memory, but are often used for decoration or entertainment and may not be important for understanding the content of the page.
To stop Google from crawling these non-essential resources, disallow them with your robots.txt file. You can disallow individual resources by name:
User-agent: *
Disallow: /images/filename.jpg
You can also disallow entire file types:
User-agent: *
Disallow: /*.gif$
If there's an unreasonable number of 301 and 302 redirects in a row, the search engines will stop following the redirects at some point, and the destination page may not get crawled. More to that, each redirected URL is a waste of a "unit" of your crawl budget. Make sure you use redirects no more than twice in a row, and only when it is absolutely necessary.
To get a full list of pages with redirects, launch WebSite Auditor and go to Site Structure > Site Audit > Redirects. Click on Pages with 302 redirect and Pages with 301 redirect for a full list of redirected pages. Click on Pages with long redirect chains to get a list of URLs with more than 2 redirects:
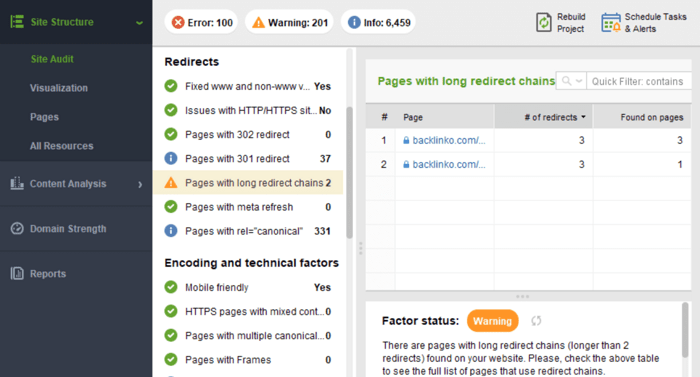
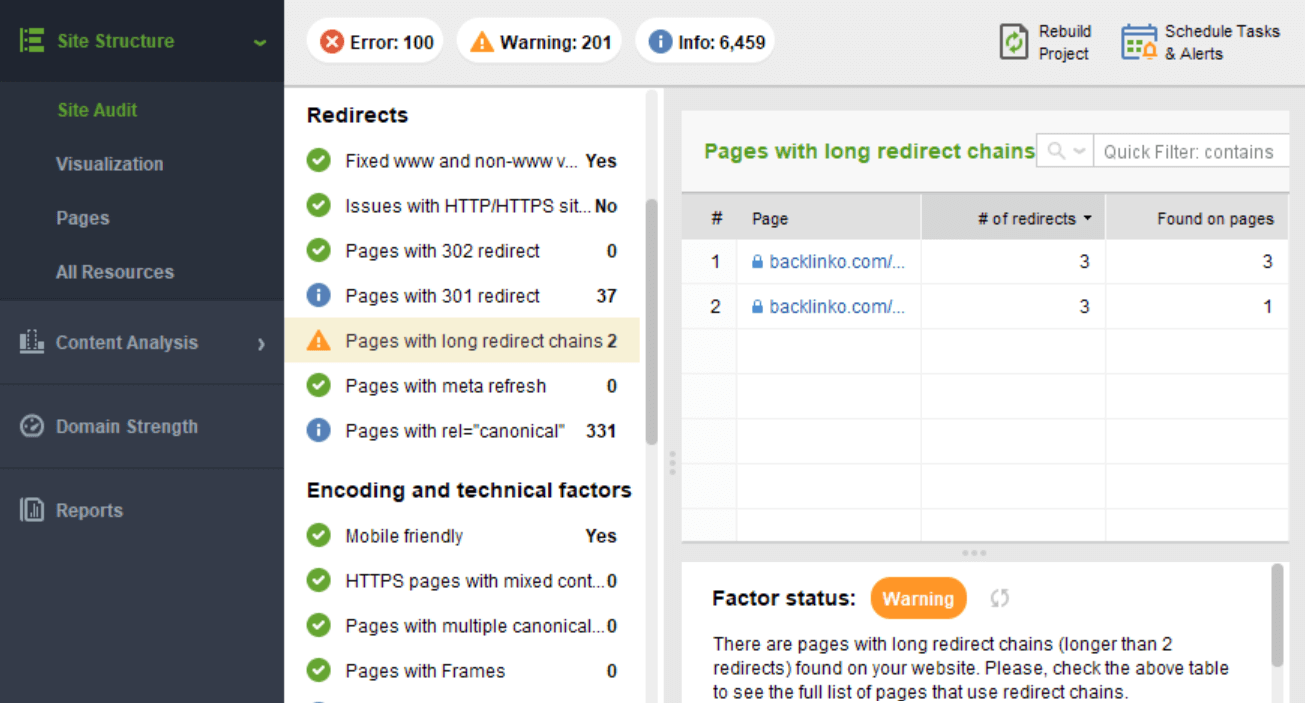
Popular content management systems generate lots of dynamic URLs, all of which lead to the same page. By default, search engine bots will treat these URLs as separate pages. As a result, you may be both wasting your crawl budget and, potentially, breeding duplicate content issues.
If your website's engine or CMS adds parameters to URLs that do not influence the content of the pages, make sure you let Google know about it by managing these parameters in your Google Search Console account, under Legacy tools and reports > URL Parameters:
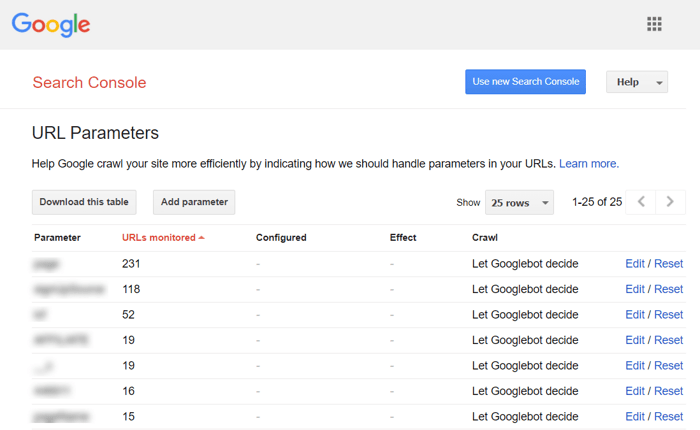
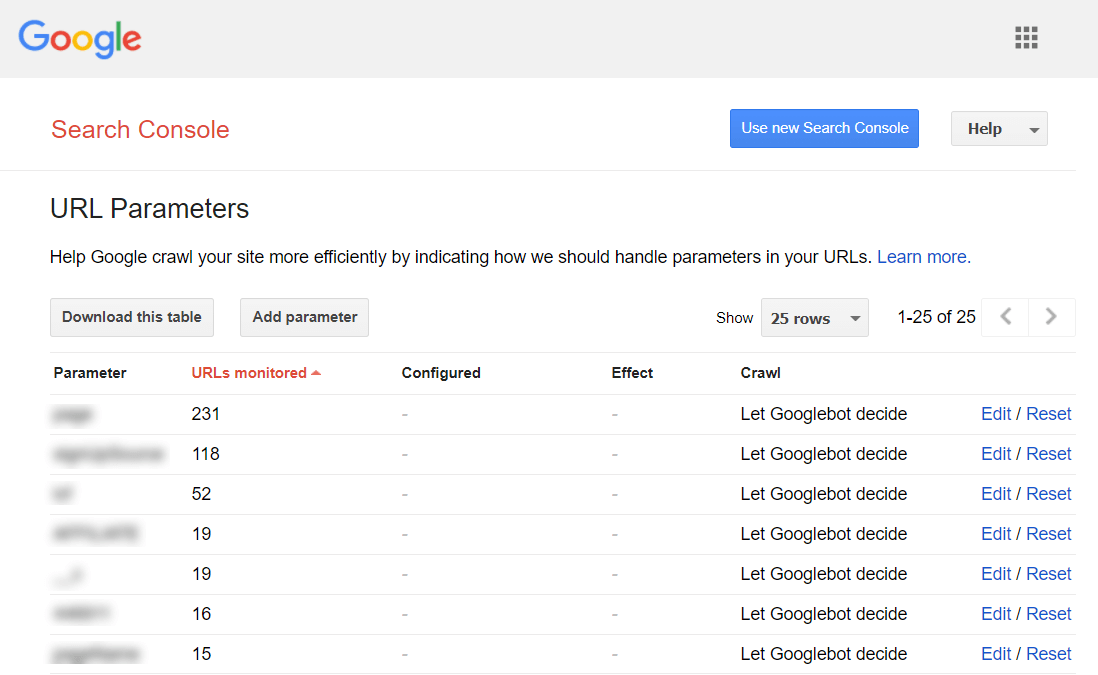
There, you can click Edit opposite any parameter and decide whether the page is allowed to be seen by search users.
Duplicate content means having two or more pages with largely similar content. This could happen for a variety of reasons. Dynamic URLs is one of them, but also A/B testing, www/non-www versions, http/https versions, content syndication, and the specifics of some CMS platforms. The problem with having duplicate content is that you waste double the budget to crawl the same piece of content.
To resolve duplicate content issues you’d first have to find duplicate pages. One way to do this is by looking for duplicate titles and meta descriptions in the WebSite Auditor tool:
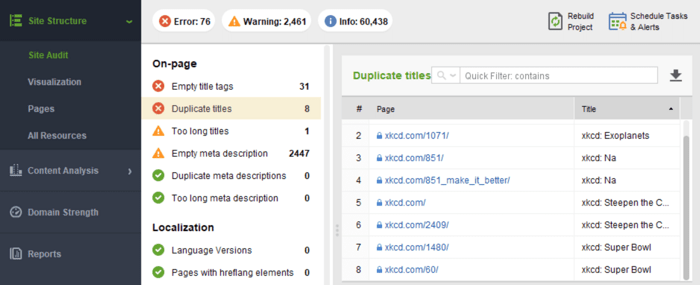
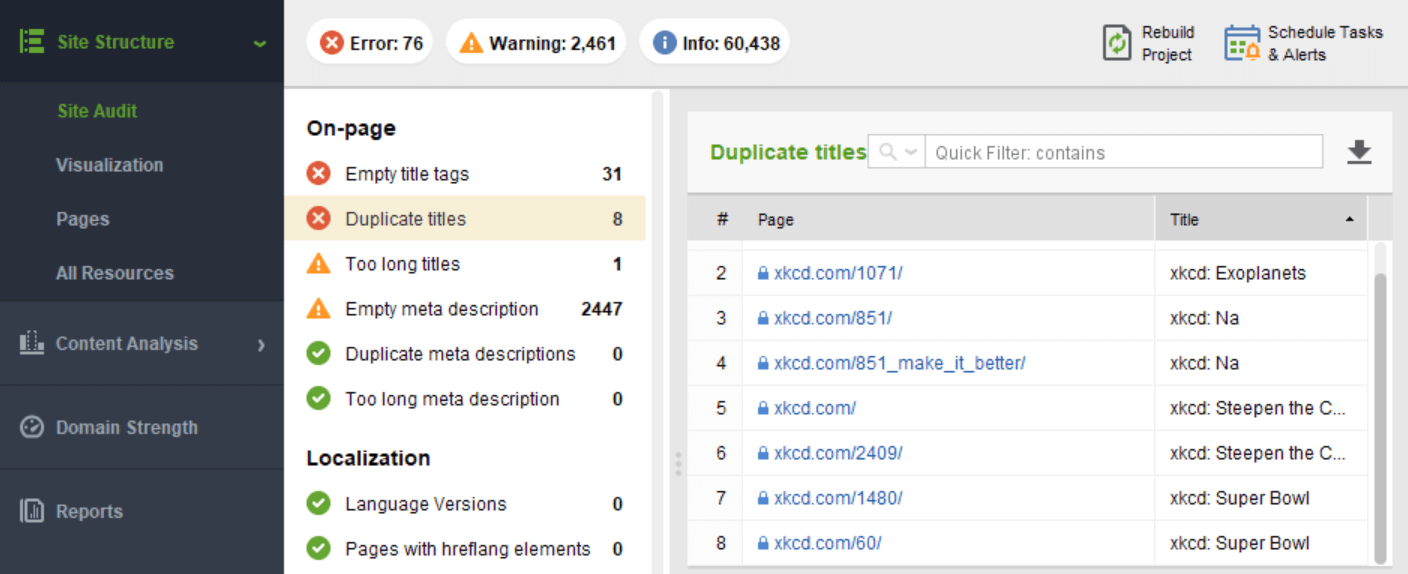
Titles, and especially meta descriptions are a good indicator of pages having the same content. If you find any of the pages that are indeed similar, then you have to decide which one is the main one and which one is a duplicate. Now go to the duplicate page and add this code to the <head> section:
<link rel="canonical" href="https://example.com/main-page" />
Where the URL is the address of the main page.
This way Google will ignore duplicate pages and focus on crawling main pages instead.
Though internal linking doesn't have a direct correlation with your crawl budget, Google says that pages linked directly from your homepage might be considered more important and crawled more often.
In general, keeping important areas of your site no farther than three clicks away from any page is good advice. Include the most important pages and categories in your site menu or footer. For bigger sites, like blogs and e-commerce websites, sections with related posts/products and featured posts/products can be a great help in putting your landing pages out there — both for users and search engines.
If you need detailed instructions, I highly recommend you go through this internal linking guide.
In case you’ve just published or updated an amazing and just cannot wait for Google to crawl it, cut the lines by using Google Search Console’s request indexing feature. All you have to do is paste your URL into the URL inspection field at the top, click enter, and then request indexing:


And you can actually do it even if the page is already indexed, but you have just updated it:
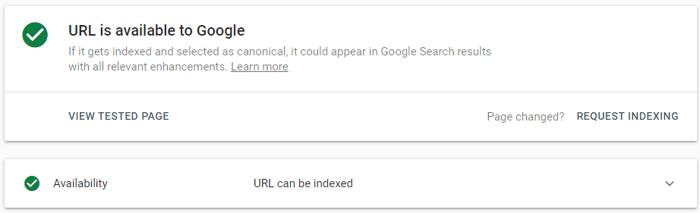
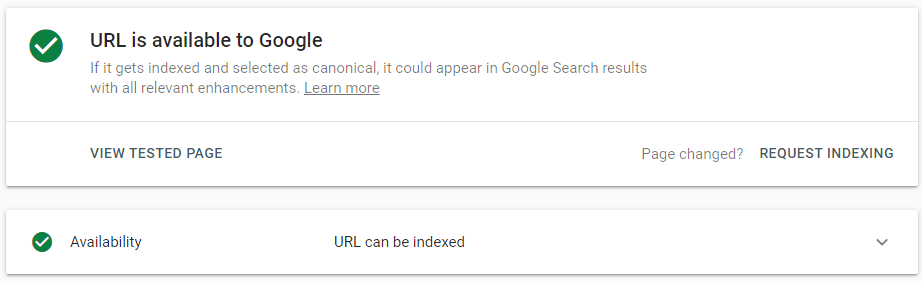
The effect of this feature is not immediate. As is everything with Google, this request is more like a very polite recommendation.
As you can see, SEO is not all about 'valuable content' and 'reputable links'. When the foreside of your website looks polished, it may be time to go down to the cellar and do some spider hunting — it's sure to work wonders in improving your site's performance in search. Now that you have all the necessary instruments and knowledge for taming search engine spiders, go on and test it on your own site, and please share the results in the comments!

