237501
•
11-minute read
•


How do you find all pages existing on a website? The first idea that comes to mind is to google the site’s domain name.
But what about URLs that fail to get indexed? Or orphan pages? Or web cache?
Finding all the pages on a website is pretty easy; however, it requires some extra attention considering there are pages that are hidden from the eyes of visitors or search bots. This guide shows 8 different methods of finding all the site's pages along with the tools to use.



Here's how to find all pages on a website:
There are tons of reasons why you may need to find all pages on a website. To name a few:
Technical issues such as broken links, server errors, slow page speed, or bad mobile usability prevent Google from indexing website pages. So, site SEO audits reveal how many URLs a website has and which of them are problematic. In the end, this helps SEOs estimate the scope of future work in the project.
If your website has duplicate content, then Google may fail to index all of the duplicates. The same concerns long redirect chains and 404 URLs: if there are many of them on a site, the crawl budget is spent in vain. As a result, the search bots visit the site less often, and it will be indexed worse overall. That is why regular audits are needed even if something looks normal in general.
Some pages are not needed in the search index—for example, login pages for admins, pages in development, or shopping carts. Still, these pages might be indexed against your will because of conflicting rules or errors in your technical files. For example, if you rely solely on robots.txt to disallow a page, the URL still may get crawled and appear in search.
Google aims to provide the best possible results for its users, so if your content is of poor quality, thin, or duplicate, then it may fail to get indexed. It is good to have a list of all your pages to know what topics you have not covered yet.
With all your content inventory at hand, you will be able to plan your content strategy more effectively. And with dedicated AI-powered content marketing software you'll be able to create content that fuels traffic and conversions.
Orphans are pages without incoming links, so users and search bots visit them rarely or do not visit them at all. Orphan pages may get indexed in Google and draw accidental users. However, a large number of orphan pages on a website spoils its authority: the site structure is not crystal clear, the pages may look unhelpful or unimportant, and all the deadwood will drag down the website's total visibility.
To plan a website redesign and improve the user experience, you will first need to find all its pages and relevant metrics.
A clear and organized structure with a logical hierarchy of all pages can help search engines find your content more easily. So, all important URLs must be reachable within one, two, or three clicks from the homepage.
Although user experience does not affect crawling and ranking, it matters to the quality signals of your website – successful purchases, the number of returning visitors, pageviews per visitor, and tons more other metrics show how much your website is useful for the visitors.
By auditing your competitors’ pages, you can dig deeper into their SEO strategies: reveal their top traffic pages, the most linked to pages, the best referral sources, etc. This way, you can get valuable insights and learn what works well for your competitors. You can borrow their techniques and compare results to see how to improve your own website.
There are many ways to find all pages on a website, but for each case, you can use a different method to do that. So, let’s see the pros and cons of each method and how to employ it with no fuss.
Checking all the pages on a website lets you really get what the site's all about and what it has to offer. This way, you can see if it clicks with what you're looking for.
Finding all the pages on a website allows you to confirm the reliability and coherence of the information it presents. This is especially crucial for sites that deal with significant or sensitive subjects.
Getting familiar with all the pages on a website can help you get the hang of its layout. This makes it simpler to spot what you need and smooths out your overall experience as you navigate through the site.
Viewing all the pages on a website can shed light on the organization that runs it—its ambitions, principles, and purpose. This insight is valuable for users interested in getting to know more about the company or entity behind the scenes.
Keeping a detailed list of all the pages on your website helps keep things tidy and makes it easier to access and refresh your content whenever needed.
Maintaining a list of all pages on your website allows you to spot any duplicate content or gaps that might be dragging down your SEO performance.
You can find all the pages on a website using Google search. Enter "site:example.com" (replace example.com with the website URL) and press search. This will reveal all the pages Google has indexed for that specific website.
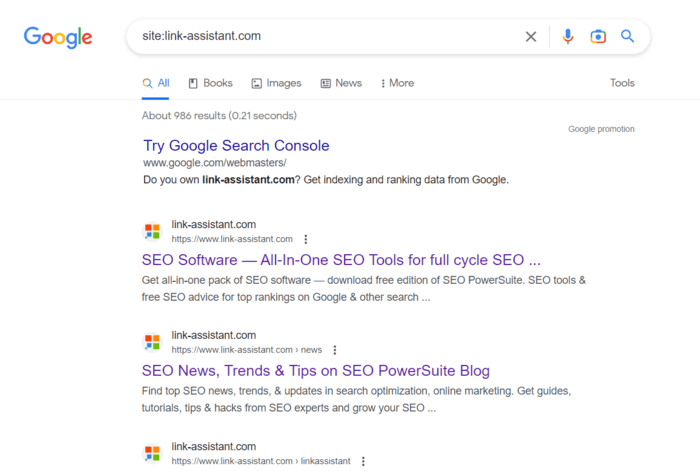
However, it's important to remember that the search results shown by the “site:” operator might not reflect the precise number of your site’s indexed pages.
First, there is no guarantee that Google will index every page immediately after crawling it. It may exclude certain pages from the index for various reasons: for example, if it considers some pages to be duplicates or of low quality.
Second, the “site:” search operator may also show pages that have been removed from your website, but they are kept as cached or archived pages on Google.
Therefore, the “site:” search query is a good start to get an approximate picture of how large your site is. But to find the rest of the pages that might be missing from the index, you will need some other tools.
Robots.txt is a technical file that instructs search bots about how to crawl your website, using the allow/disallow rules for individual pages or whole directories.


Thus, the file will not show you all the pages on your site. However, it can help you locate pages that are banned from being accessed by search bots.
How-to
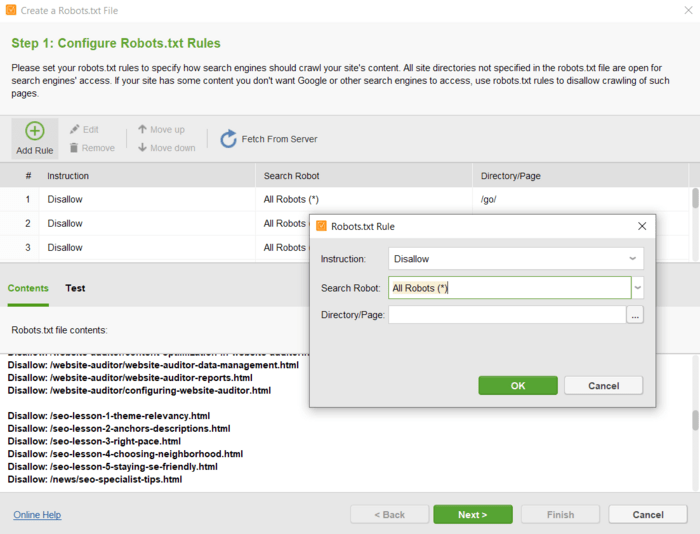
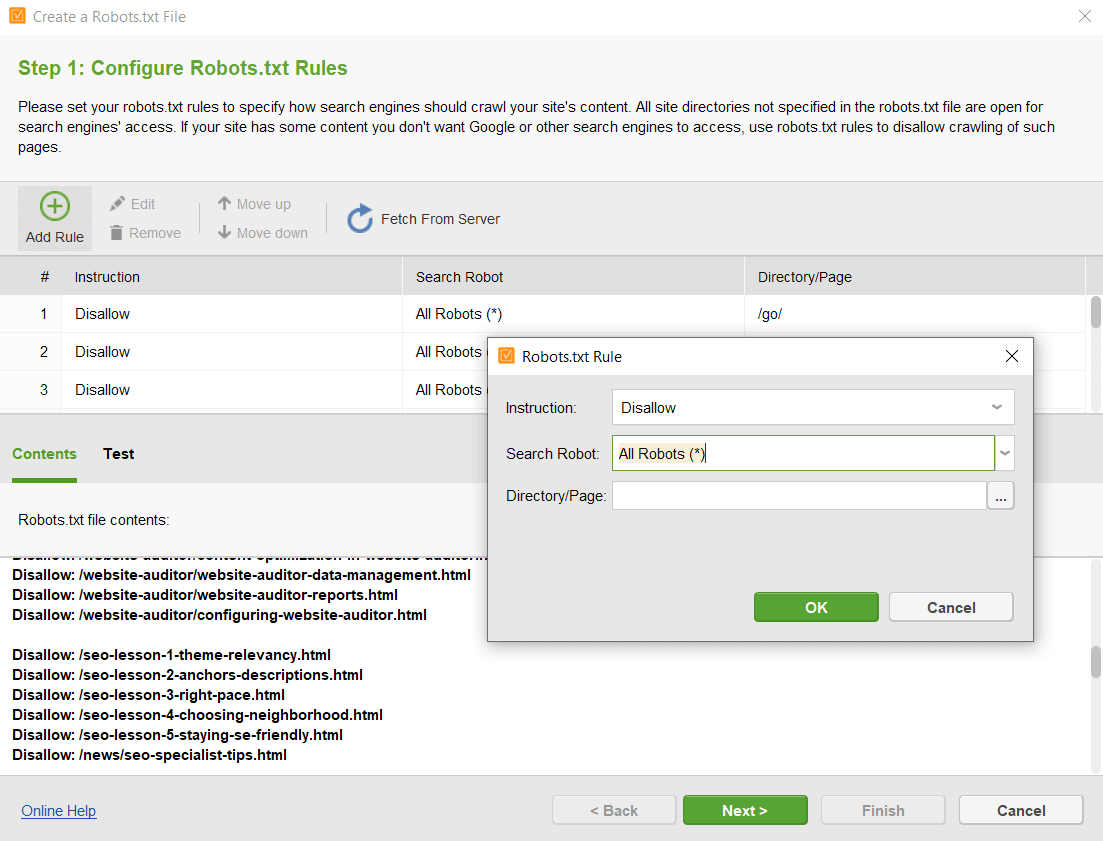
Here are the steps on how to find the restricted pages using robots.txt:
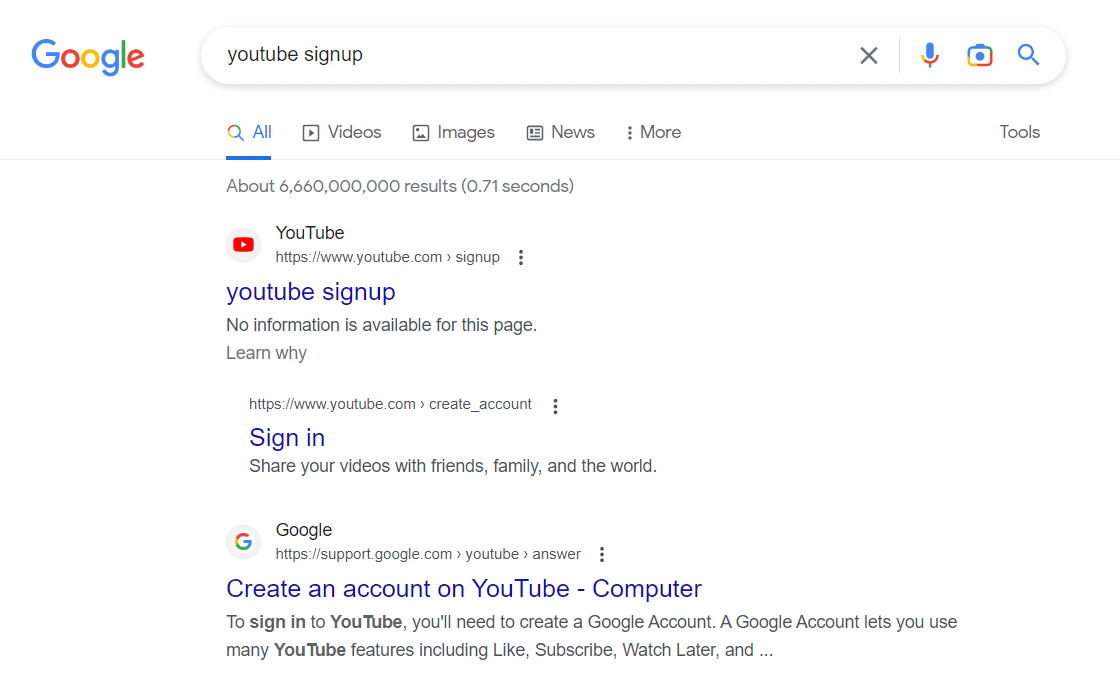
Here is an example of robots directives for YouTube.
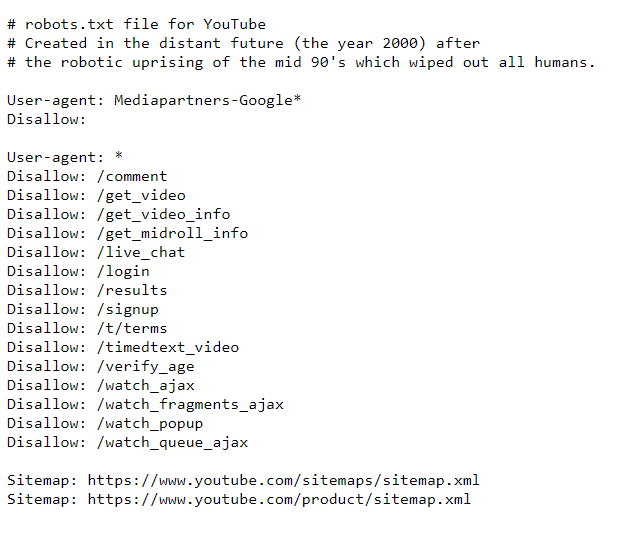
Check how it works. For example, the sign-up page is disallowed. However, you still can get it when searching on Google – notice that no descriptive information is available for the page.
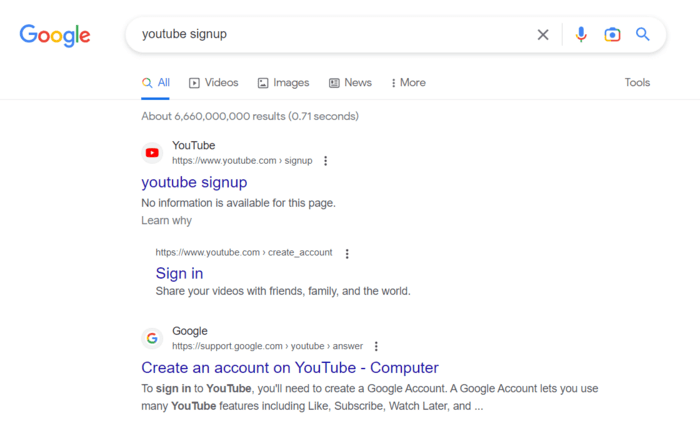
It is necessary to recheck your robots.txt rules to make sure that all of your pages are crawled properly. So, you might need a tool such as Google Search Console or a site crawler to review it. I’ll dwell on it in a moment.
And so far, if you want to learn more about the purpose of the file, read this guide to hiding web pages from indexing.
A sitemap is another technical file that webmasters use for proper site indexing. This document, often in XML format, lists all the URLs on a website that should be indexed. A sitemap is a valuable source of information about a website’s structure and content.
Large websites may have several sitemaps: as the file is limited by size to 50,000 URLs and 50 MB, it can be split into several ones and include a separate sitemap for directories, images, videos, etc. E-commerce platforms like Shopify or Wix generate sitemaps automatically. For others, there are plugins or sitemap generator tools to create the files.
How-to
Among all, a website's sitemap lets you easily find all pages on it and ensure that they are indexed:


You should also recheck the correctness of your sitemap once in a while, as it may have issues too: it might be blank, responding with a 404 code, cached long ago, or it may simply contain the wrong URLs that you don’t want to appear in the index.
A good method to validate your sitemap is to use a website crawling tool. There are several website crawler tools available online, and one of them is WebSite Auditor which is a powerful SEO tool for sitewide SEO audits. Let’s see how it can help you find all the pages on a website and validate technical files.
How-to
Here is how you can use WebSite Auditor to find all the pages on your website:
You can specify the instructions for a certain search bot or user agent; tell the crawler to ignore URL parameters, crawl a password-protected site, crawl a domain alone or together with subdomains, etc.
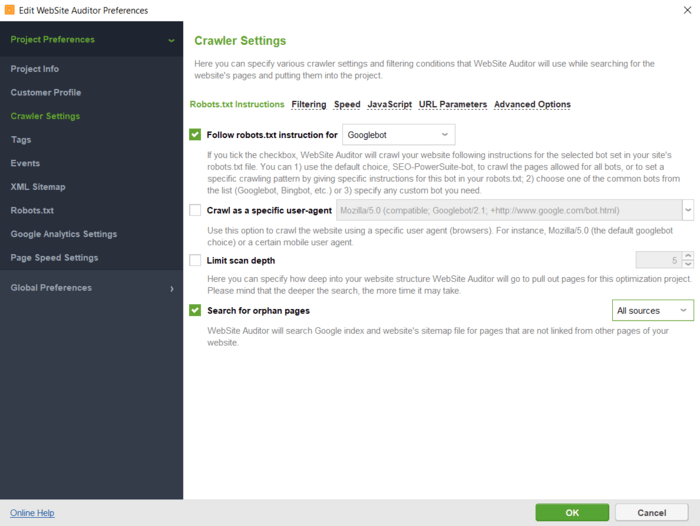
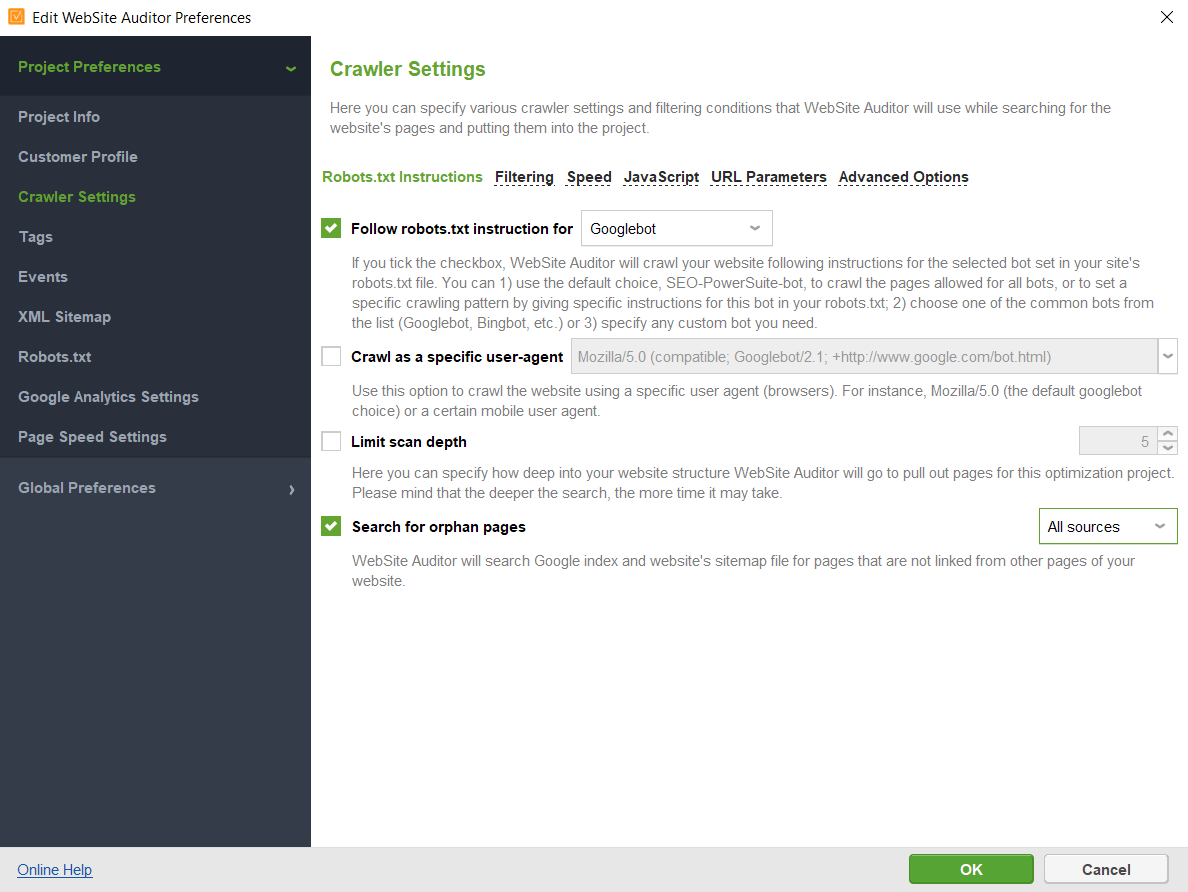
After you click OK, the tool will audit your site and collect all the pages in the Site Structure > Pages section.
WebSite Auditor will help you recheck if the URLs are properly optimized for search engines. You will get to know the tool in a few minutes, as the setup is quick, and the interface is pretty intuitive.
Here is a short video guide for you:
Let’s see what you can get from the website crawling tool.
In the All pages tab, you can sort the list by URL, title, or any other column by clicking on the column header.
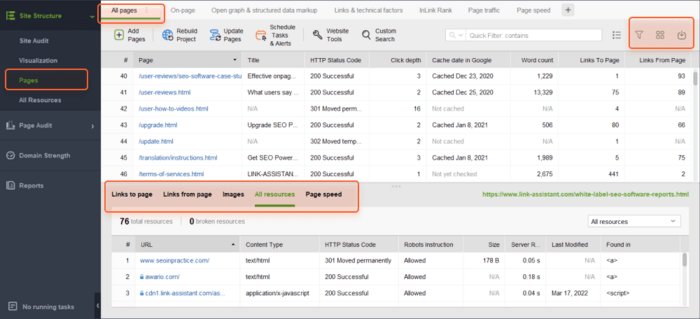
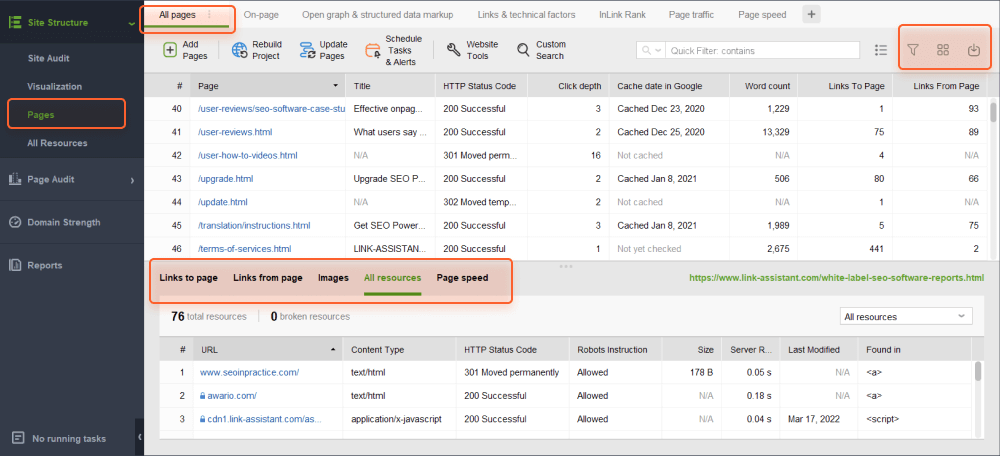
You can use the search box to filter the list of pages by keyword or page URL. This can be helpful if you're looking for a specific page or group of pages.
Besides, you can add visible columns to present more information about this page, such as meta tags, headings, keywords, redirects, or any other on-page SEO element.
Finally, you can click on any URL to examine all resources on the page in the lower half of the workspace.
All the data can be handled inside the tool or copy/exported in CSV or Excel format.
The Site Audit section will show you lists of pages split by types of errors, such as:
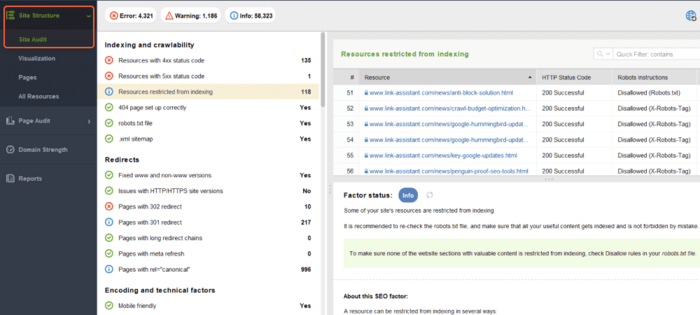
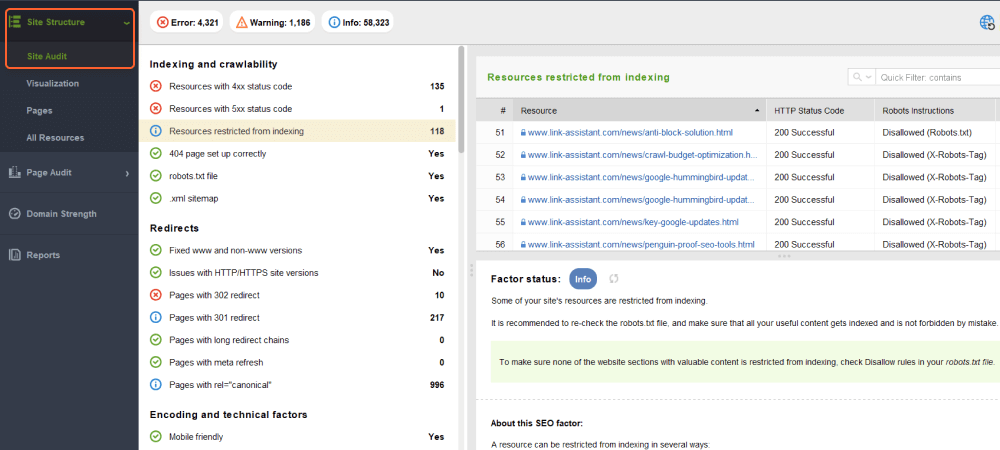
Under each type of issue, you will see an explanation of why this factor is important and a few suggestions on how to fix it.
Besides, you can examine your visual sitemap in Site Structure > Visualization, which shows relations between all your URLs. The interactive map allows you to add or remove pages and links to adjust your site structure. You can recalculate the Internal PageRank value and check the Pageviews (as tracked by your Google Analytics).
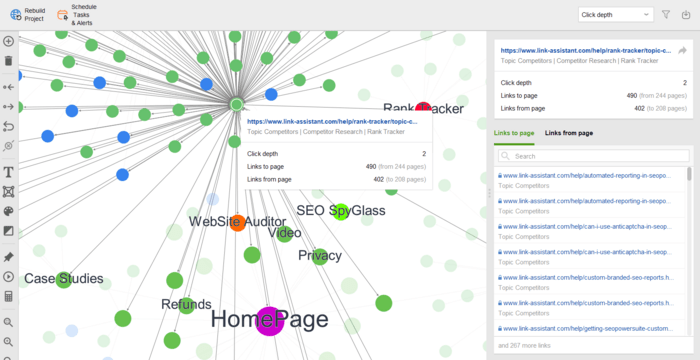
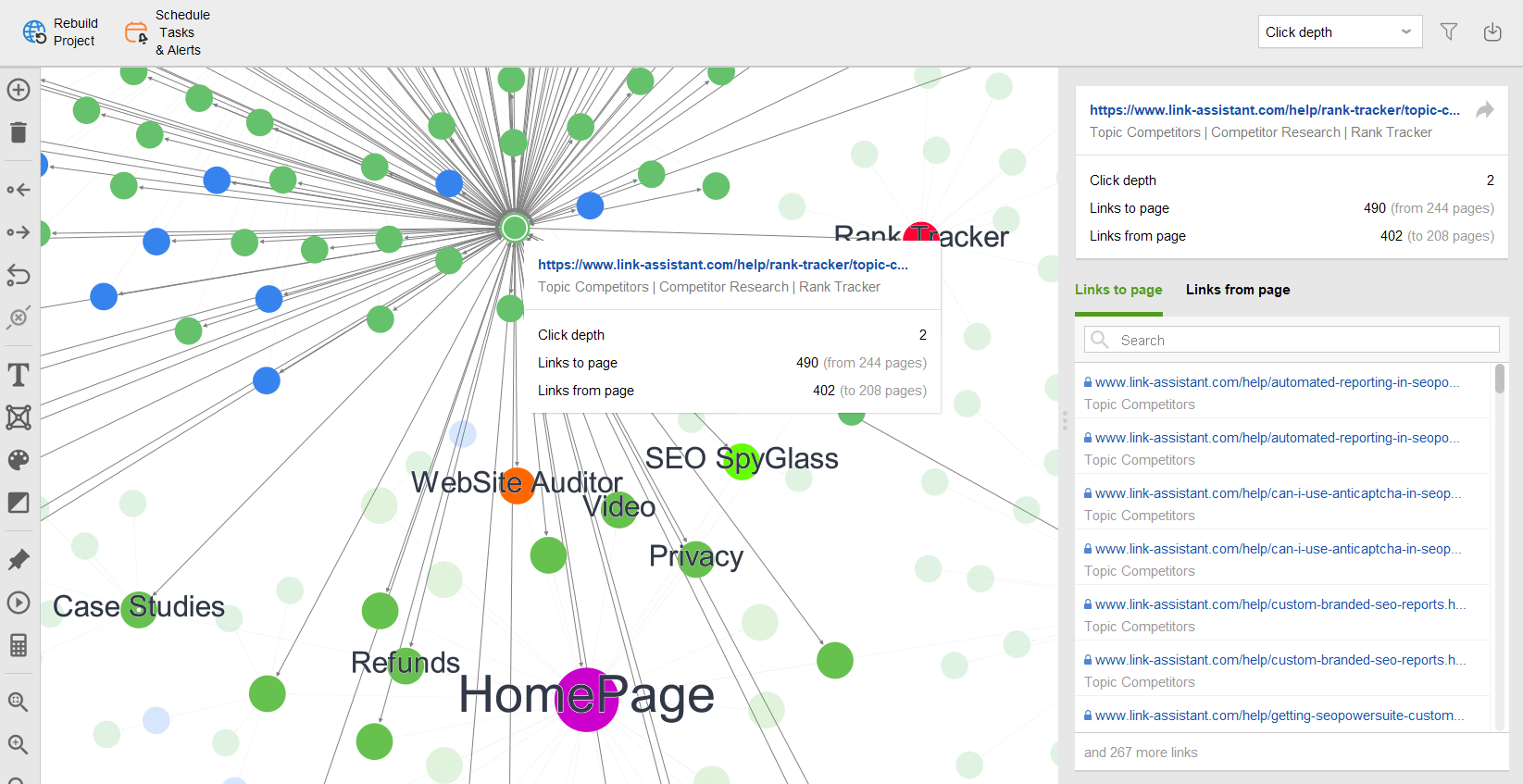
On top of that, WebSite Auditor also checks the availability of both your robots.txt file and the sitemap.
It lets you edit the technical files in the Website tools and upload them straight to your site with the proper settings.
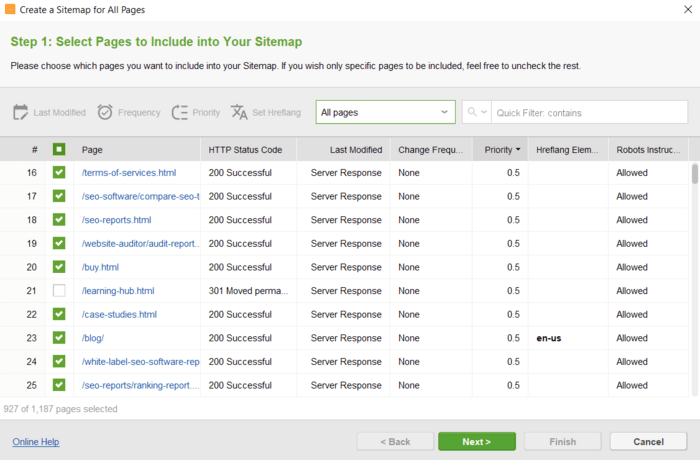
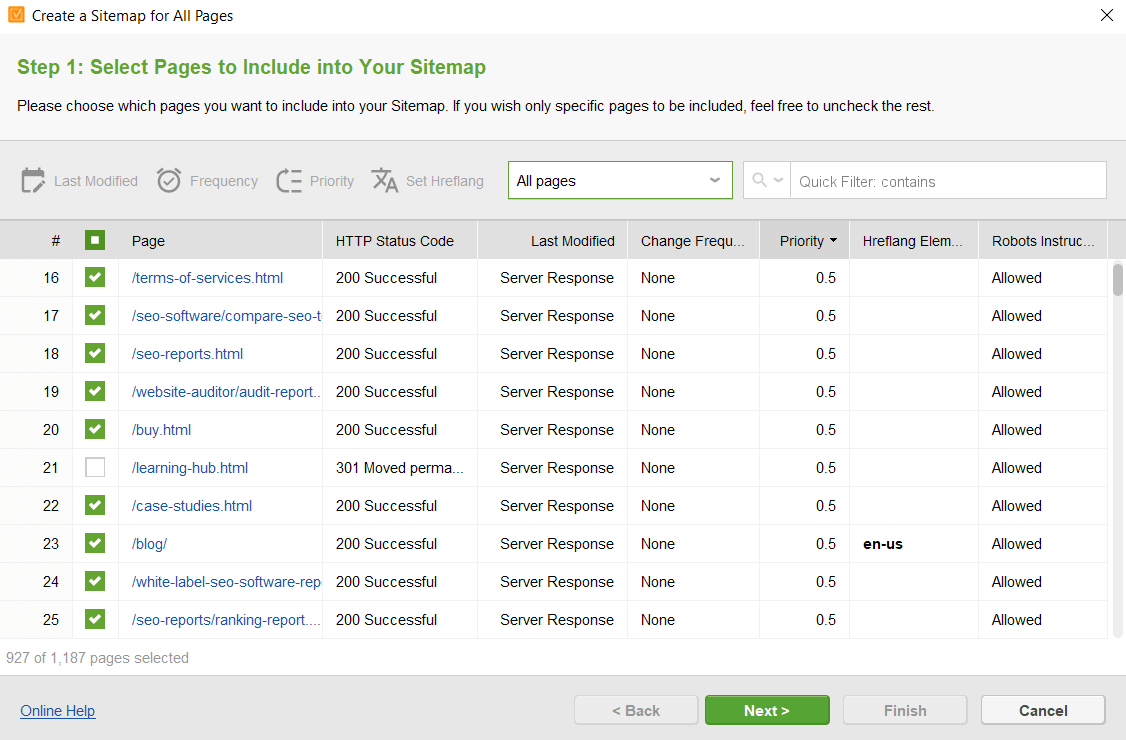
You will not need to observe any special syntax when editing the files – just select the required URLs and apply the necessary rules. Then, click to generate the files and save them to your computer or upload to the site via FTP.
One more great tool to find all pages on a website is Google Search Console. It will help you check the pages’ indexingand reveal the issues that hamper search bots from correctly indexing these URLs.
How-to
You can get a breakdown of all your pages by their indexing status, including those pages that have not been indexed yet.
Here is how to find all pages on a website with Search Console:
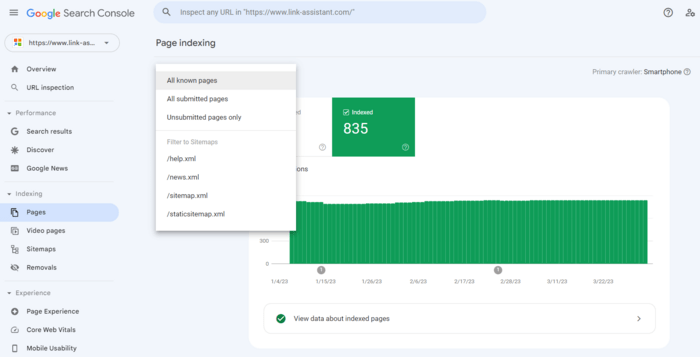
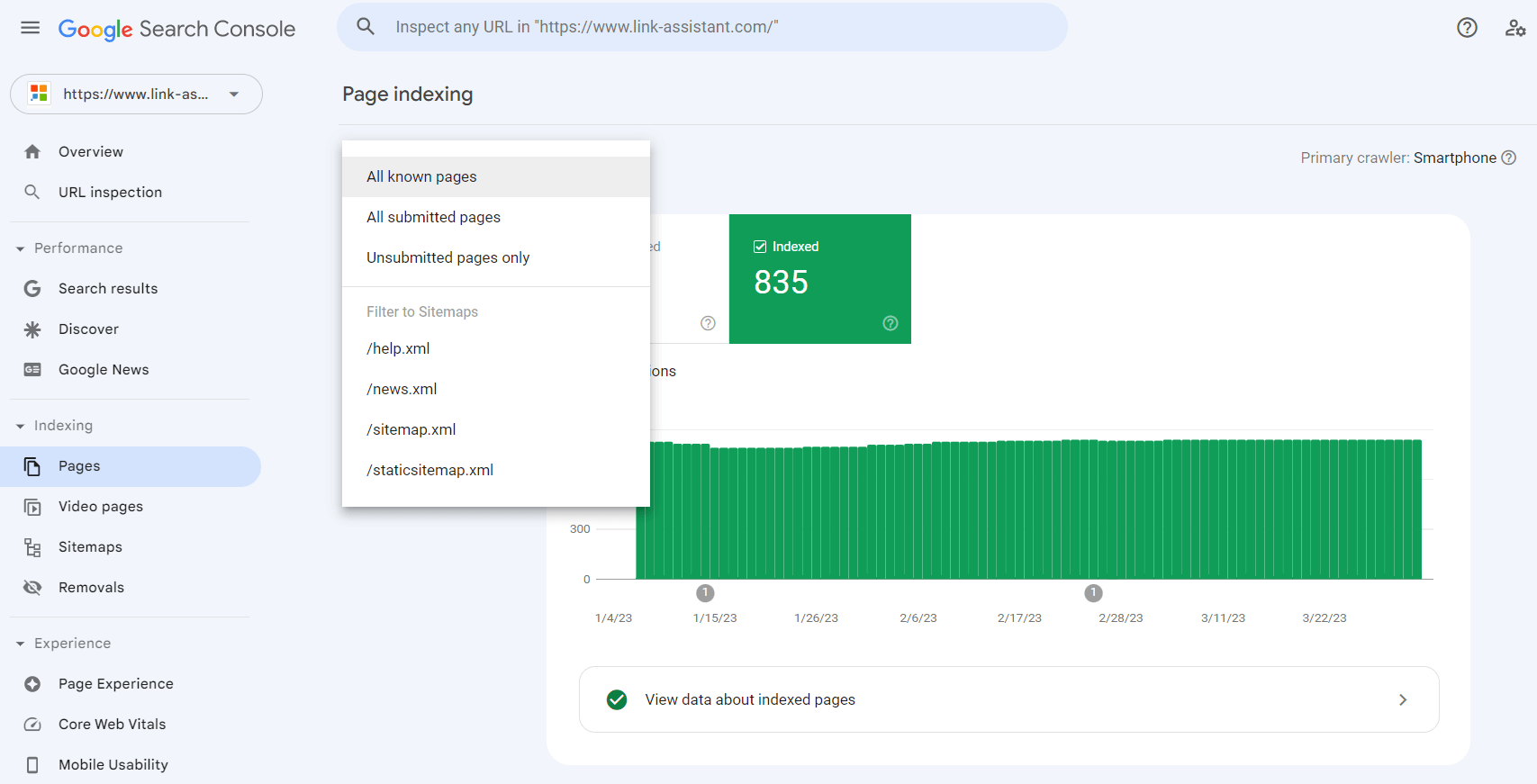
1. Go to the Indexing report and click View data about indexed pages. You will see all the pages that the search bot last crawled on your website. However, mind that there will be a limit in the table of up to 1,000 URLs. There is a quick filter to sort all known pages from all submitted URLs, etc.
2. Enable the Not indexed tab. Below, the tool gives you the details on why each URL is not indexed.
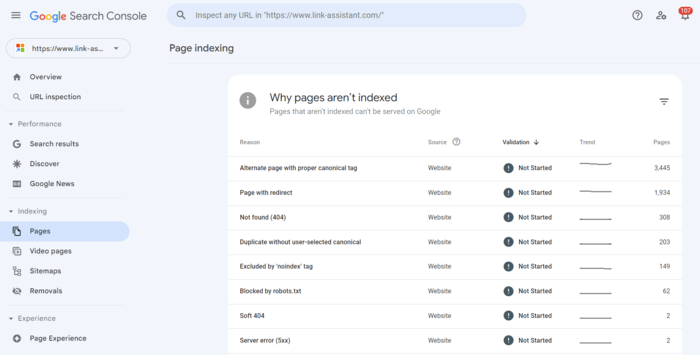
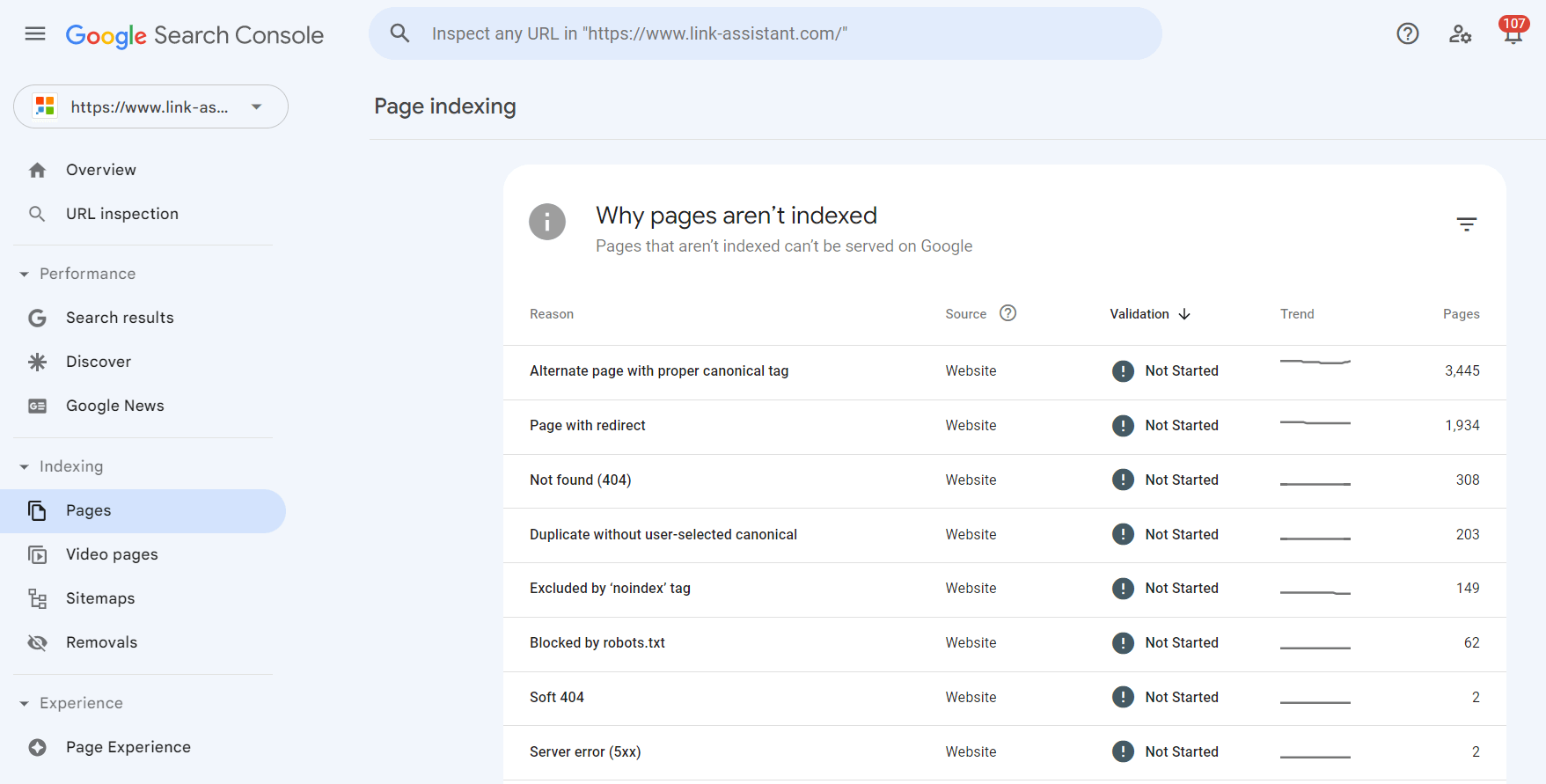
Click on each reason and see the URLs affected by the issue.
The difficulty is that you will get not only the main URLs of your pages but also anchor links, pagination pages, URL parameters, and other garbage that requires manual sorting. And the list might be incomplete because of the 1,000 entries limit in the table.
Among other things, mind that different search engines may have other indexing rules, and you need to use their webmaster tools to find and handle such issues. For example, use Bing Webmaster tools, Yandex Webmaster, Naver Webmaster, and others to check indexing in the respective search engines.
I guess Google Analytics 4 is one of the most widely used analytics platforms, so any website owner or editor is familiar with it.
How-to
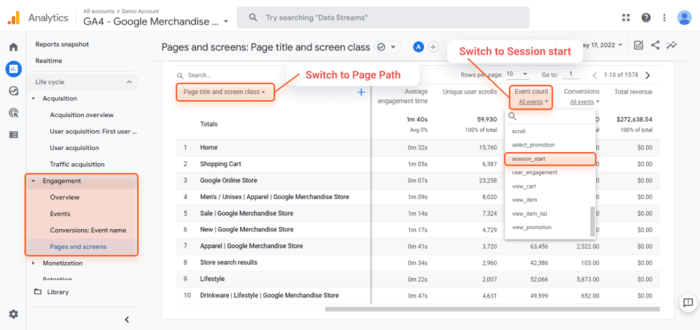
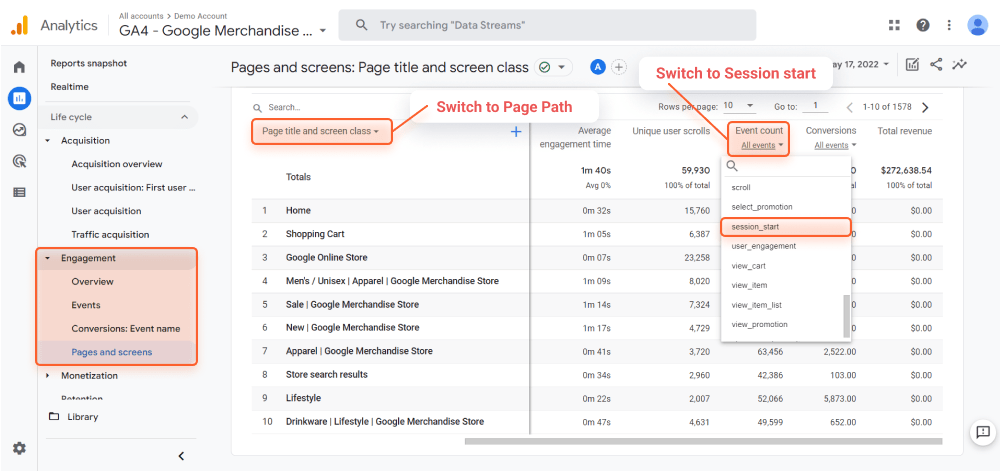
Just like with Search Console, Google Analytics 4 will include URL parameters and the like. You can export the list of pages as a CSV or an Excel sheet by clicking on the Export button at the top of the page.
Some websites are really huge, and even powerful SEO spiders may have a hard time crawling all of their pages. Log analysis is a good option for finding and examining all pages on large websites.
By analyzing your website's log file, you can identify all the pages that get visitors from the web, their HTTP responses, how frequently crawlers visit the pages, and so forth.
Log files rest on your server, and you’ll need the required level of access to retrieve it and a log analyzer tool. So, this method is more suitable for tech-savvy people, webmasters, or developers.
How-to
Here are the steps to find all your site's pages using log analysis:
Another way to find all the pages on a website is to refer to your Content Management System (CMS), which will contain all the URLs on the website you have once created. An example of a CMS is WordPress or Squarespace.
How-to
Although CMSs are quite different in appearance, the general steps apply to most of them:
Mind that there can be categories, blog posts, or landing pages, which are different types of pages that may belong to different sections in the CMS.
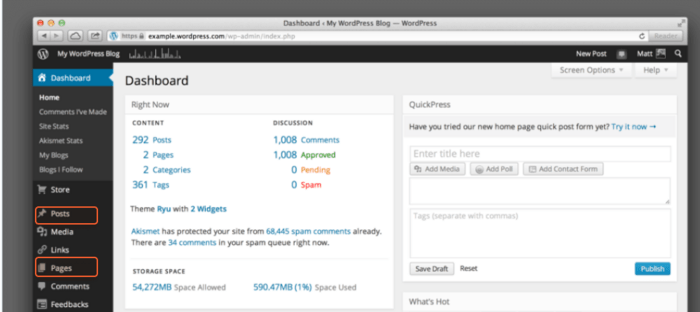
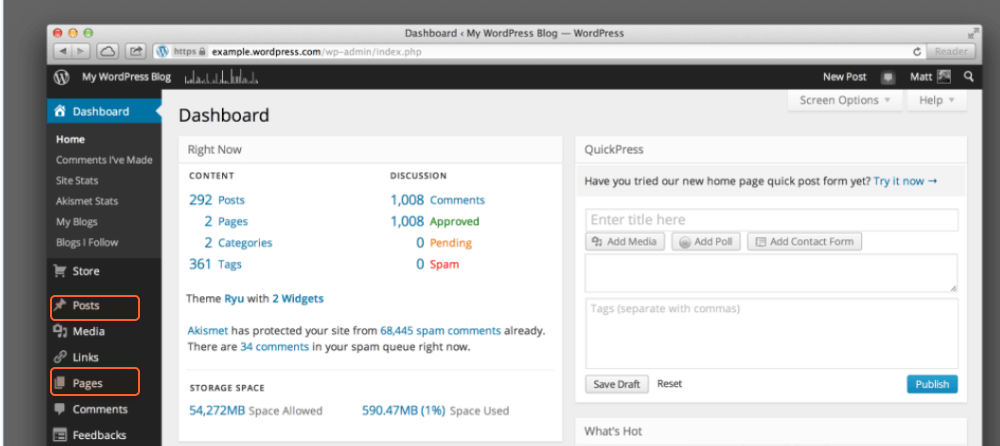
Most CMSs allow sorting the URLs by the date of their creation, author, category, or some other criteria. You can also use the search box to filter the list of pages by keywords or titles.
To find all pages on a website, there is a great array of methods and tools. The one you choose depends on the purpose and the scope of work to do.
I hope you’ve found this list helpful and will now be able to easily collect all your site’s pages even if you’re new to SEO.
If you have a question not answered yet, feel free to ask in our user group on Facebook.



