123061
•
20-minute read
•


A technical SEO audit is indeed a big deal. In fact, skipping regular checkups can totally mess up your website.
Overlooked issues and bugs often result in poor website indexing, faulty user experience, and lost profit. Not to mention ruining all your previous SEO efforts.
In this SEO audit checklist, I’ll walk you through the essentials of a technical SEO audit, from theory to practice. By taking these 12 essential steps, you’ll be able to fine-tune your website so that it not only impresses search engines but also makes users happy.
If you’re short of time, you can download our quick-bite Technical SEO Audit Checklist.
Technical SEO involves optimizing the technical aspects of a website to meet search engine standards and improving organic rankings and user experience. Key components include optimizing site speed, enhancing mobile-friendliness, structuring URL paths, implementing HTTPS, and ensuring proper site crawling and indexing.
A technical SEO audit is a checkup of your website’s digital health. It involves examining things like crawlability, indexing, site structure, website loading speed, and performance, among other elements.



To help you navigate, here's the 12-step SEO audit checklist:
Such a thorough examination helps you spot and fix technical issues so that your website runs smoothly, shows up in search, and provides an awesome user experience.
Technical SEO audits may pursue different goals. The most frequent cases include checking a website before launch, optimizing ongoing processes, handling site migrations, or resolving Google sanctions.
I aimed to make this SEO audit checklist universal, covering all major steps of a technical SEO audit. But you can adjust the approach to align with your unique needs and goals.
A technical SEO audit helps you find issues that can ruin your SERP rankings. If Google can’t crawl your content and index your pages, your website simply can’t rank and bring traffic.
However, a timely audit allows you to spot and fix those bugs before they cause serious damage. Such clean-ups contribute to boosting your website’s visibility in search engines, growing traffic, and generating more leads.
User experience (UX) plays a significant role in how your website ranks. A tech SEO audit will help you identify things that could spoil UX or even turn users away from your website.
Do users often encounter errors or broken links? Are they happy about page loading times? Can they navigate your website from mobile devices?
By creating a seamless user experience, you not only keep visitors on your site longer but also encourage them to come back. Since Google prioritizes spotless UX, the algorithms will consider your site more trustworthy as well.
Sudden ranking drops do not always signal severe breakdowns. As you know, Google regularly introduces core updates that can impact your rankings. Systematic audits and ranking checks ensure that you can quickly notice such updates and figure out your next move.
Friendly advice: don’t rush to immediately fix affected pages (especially if you’re not quite sure about what to fix).
Volatility is a normal thing during core updates. Just wait and browse the web for some information about the fresh update. In case your positions are not getting back to normal, then yes, you probably have to go and dig under the hood of your website.
Prior to starting with an SEO audit checklist, you need to set up analytics tools.
Firstly, you will need to access Google Search Console, which is the go-to tool for getting basic audit data and assessing your rankings from Google's perspective.
Next, since Google Search Console has limitations, you'll require an additional tool to provide a comprehensive technical overview of your website. I'll demonstrate how to conduct a technical SEO audit using SEO PowerSuite’s WebSite Auditor.
With these tools in place, you can get a substantial amount of data for a scrutinized website analysis. When selecting the best software for your needs, be sure to compare SEO solutions and pick the one that fits your requirements best.
Before you embark on a technical SEO audit (of a newly bought domain or an existing one), check if it's not under any search engine sanctions.
To do this, go to Google Search Console. In the sidebar menu, scroll down to the Security and Manual Actions tab.
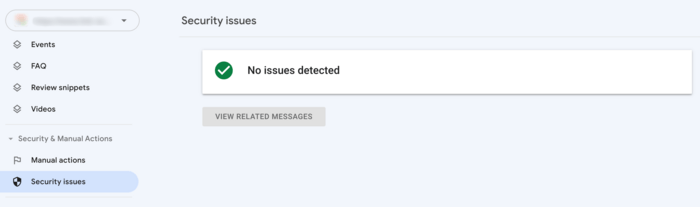
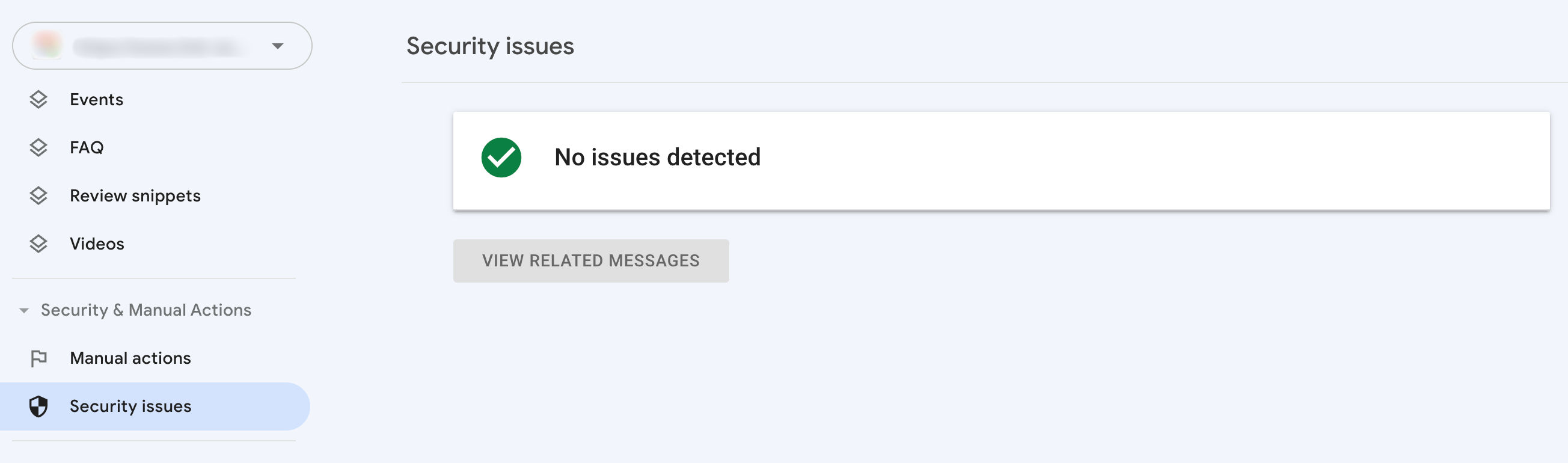
If your site has been penalized, you will see a corresponding notice in Google Search Console. Make sure to address the warning before you proceed further with an SEO audit checklist.
It is especially important to check the domain for penalties when you buy an already-used one. There is a risk of buying not only the domain but also its previous penalties by Google. To avoid this trap, consult our guides on how to choose expired domains, and how not to get trapped into the Google sandbox during a website launch.
Now that we’re done with preparatory work, let’s move on to the key steps of an SEO audit checklist.
The first step in our SEO audit checklist is to run an in-depth site scan to gather all website pages and resources like CSS, images, videos, JavaScript, and PDFs. This approach sets the stage for a thorough analysis of your entire site.
To initiate the scan, open WebSite Auditor and create a project. On the start screen, enter your website’s URL and click Next. If you’ve already used WebSite Auditor before, just click New on the top bar to start a new project.
By default, WebSite Auditor will crawl your website using the SEO-PowerSuite-bot. But if you want to change the crawler’s settings, say, set up robots.txt instructions for a specific search engine, tick Enable expert options.
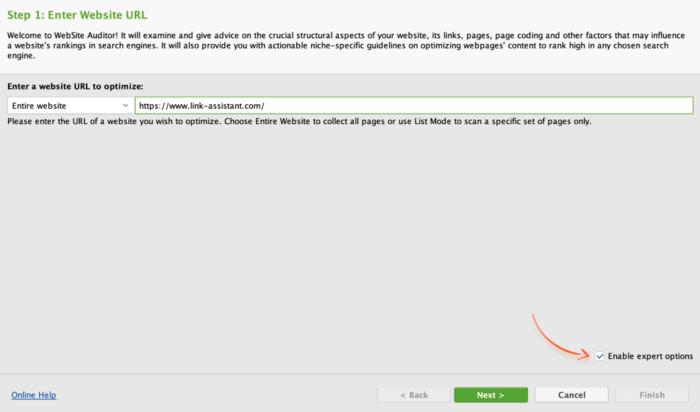
In these settings, you can also set additional parameters, such as scan depth limits, JavaScript rendering, URL parameters, etc.
A thorough examination of every page may take some time so feel free to grab a coffee or proceed with other tasks while the process is completed.
There are cases when you don't need to crawl the entire website but rather check specific sections or campaigns.
For that, select List Mode in the project creation dropdown menu. Add the domain link and a set of specific URLs you want to crawl.
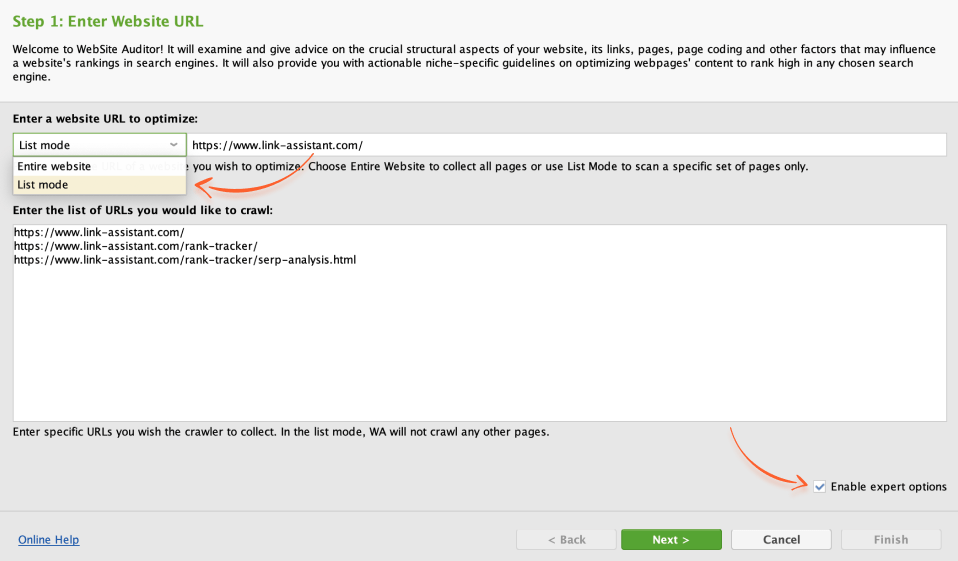
You can also Enable expert options to access advanced crawler settings for List Mode.
It's essential that Google and other search engines can crawl and index your website. Otherwise, your pages simply won’t rank.
Basically, there are two types of crawlability and indexing issues:
To verify if there are any crawlability and indexing issues with WebSite Auditor, navigate to Site Audit > Indexing and crawlability.
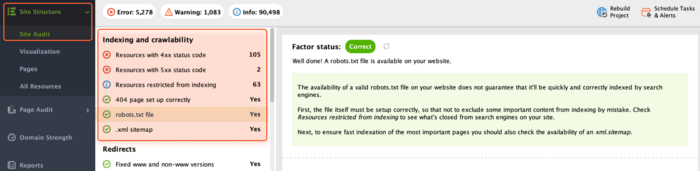
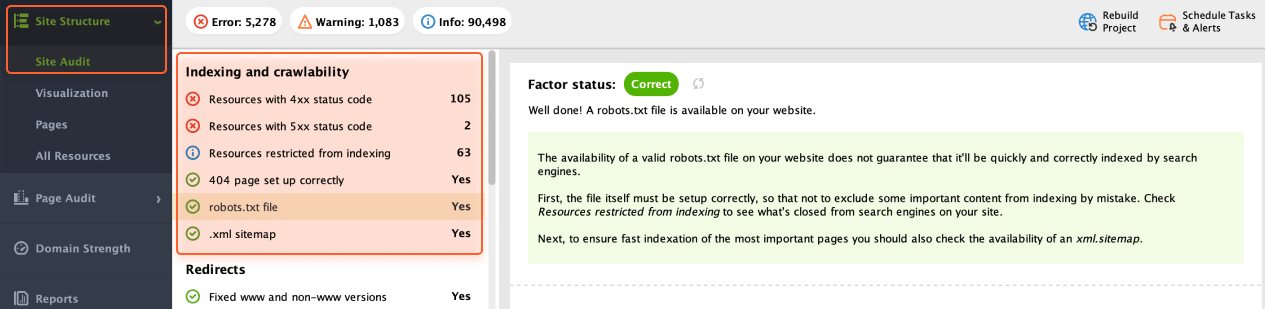
Here, you need to pay attention to the following elements: robots.txt, XML sitemap, and proper HTTP response codes.
A robots.txt file tells search engines which URLs the crawler can access on your site. This file is typically used to:
Click robots.txt file to see if it’s available on your website.
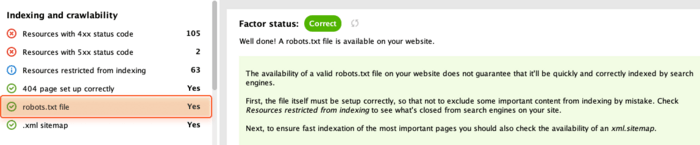
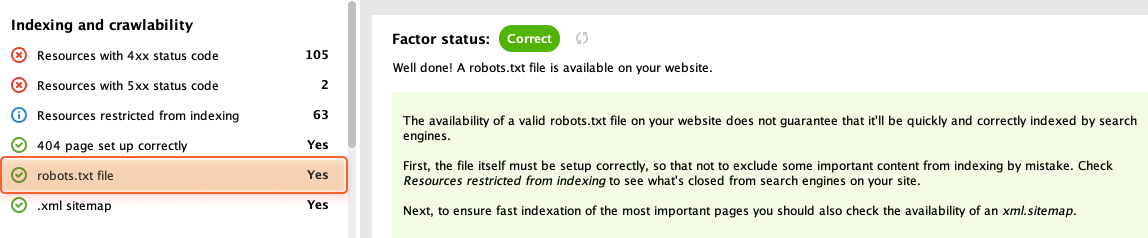
Now, you have to make sure that all your important pages are open for indexing. Head over to the Resources restricted from indexing section and review the list of pages currently restricted from indexing.
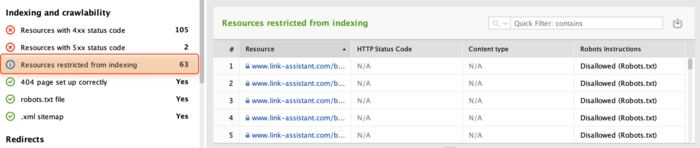
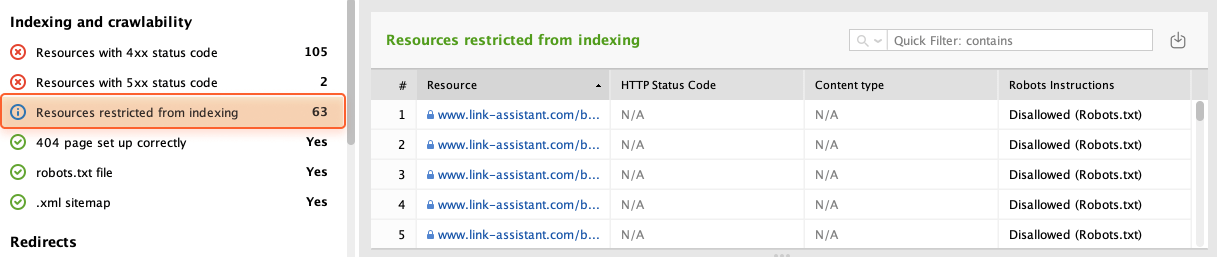
Several indicators show that a resource is not indexed:
If your website has no robots.txt file yet (or an existing one needs a makeover), you can fix that with WebSite Auditor. Jump into the Pages module, click on Website Tools, and pick Robots.txt.
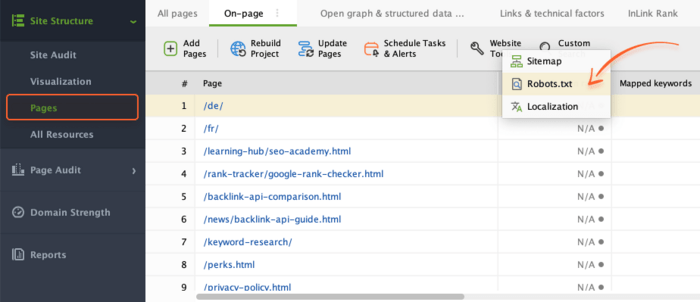

From there, you can either create a new robots.txt file or fetch your existing one to make some tweaks.
An XML sitemap is a technical file that lists all pages, images, videos, and other resources on your site, as well as the relationships between them. This file is crucial for SEO as it tells search engines how to crawl your site more efficiently.
You can check the presence of a sitemap on your website with WebSite Auditor in .xml sitemap in the Indexing and crawlability section.
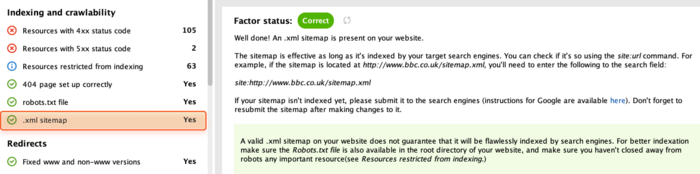
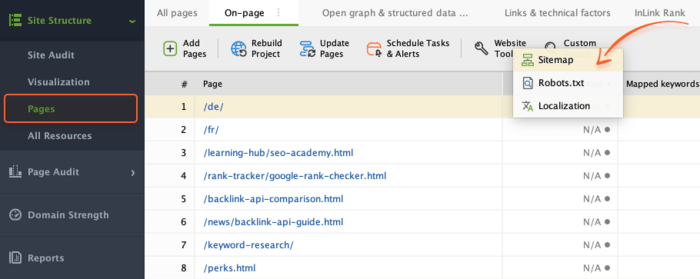
If you don't have a sitemap, you should create one right away. You can quickly generate the sitemap using Website Tools. Just switch to the Pages module, click on Website Tools, and pick Sitemap.
Let Google know about your sitemap. To do this, submit your sitemap manually to Google Search Console via Sitemaps.
HTTP response code errors can also lead to indexing issues. In the Site Audit module, explore the Indexing and crawlability section, namely Resources with 4xx status code, Resources with 5xx status code, and 404 page set up correctly.
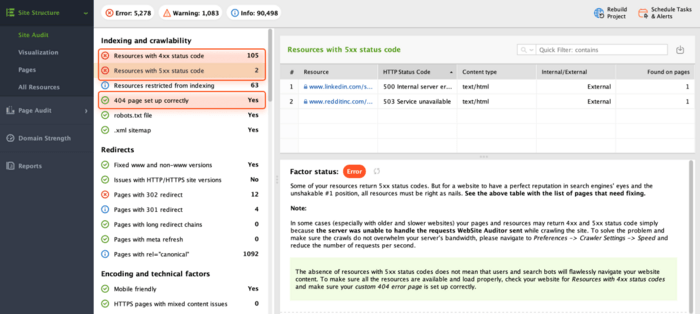
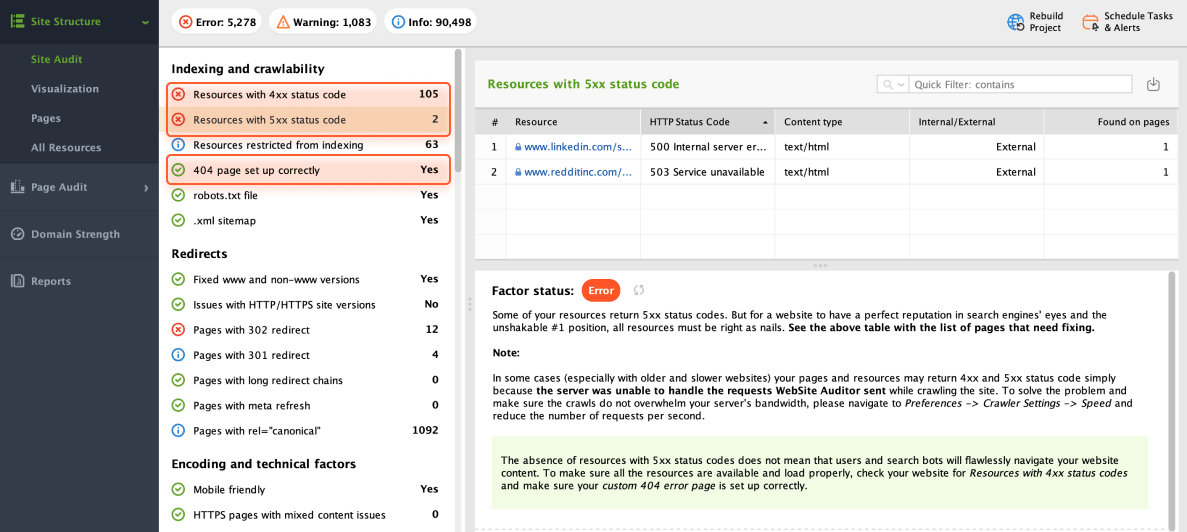
If any of these factors show an error or a warning status, WebSite Auditor will provide instructions on how to fix them.
Done with the second step of the SEO audit checklist. Let's move further!
A simple and clear website structure is a must-have for many reasons. The major ones include:
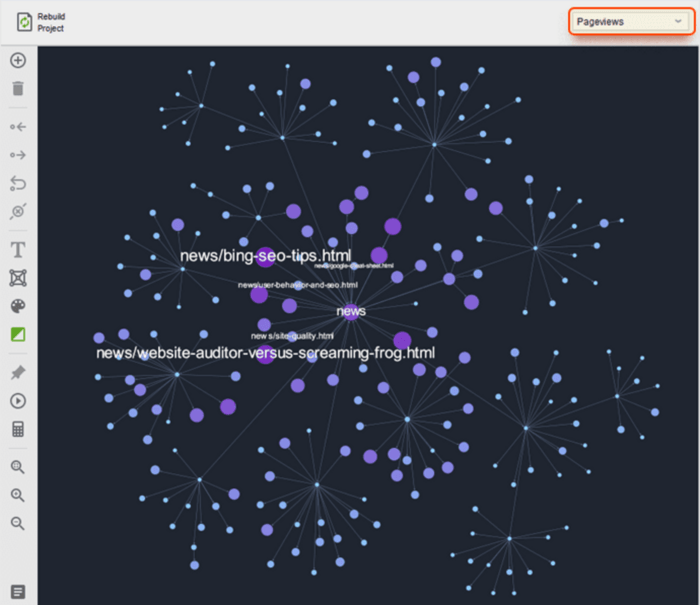
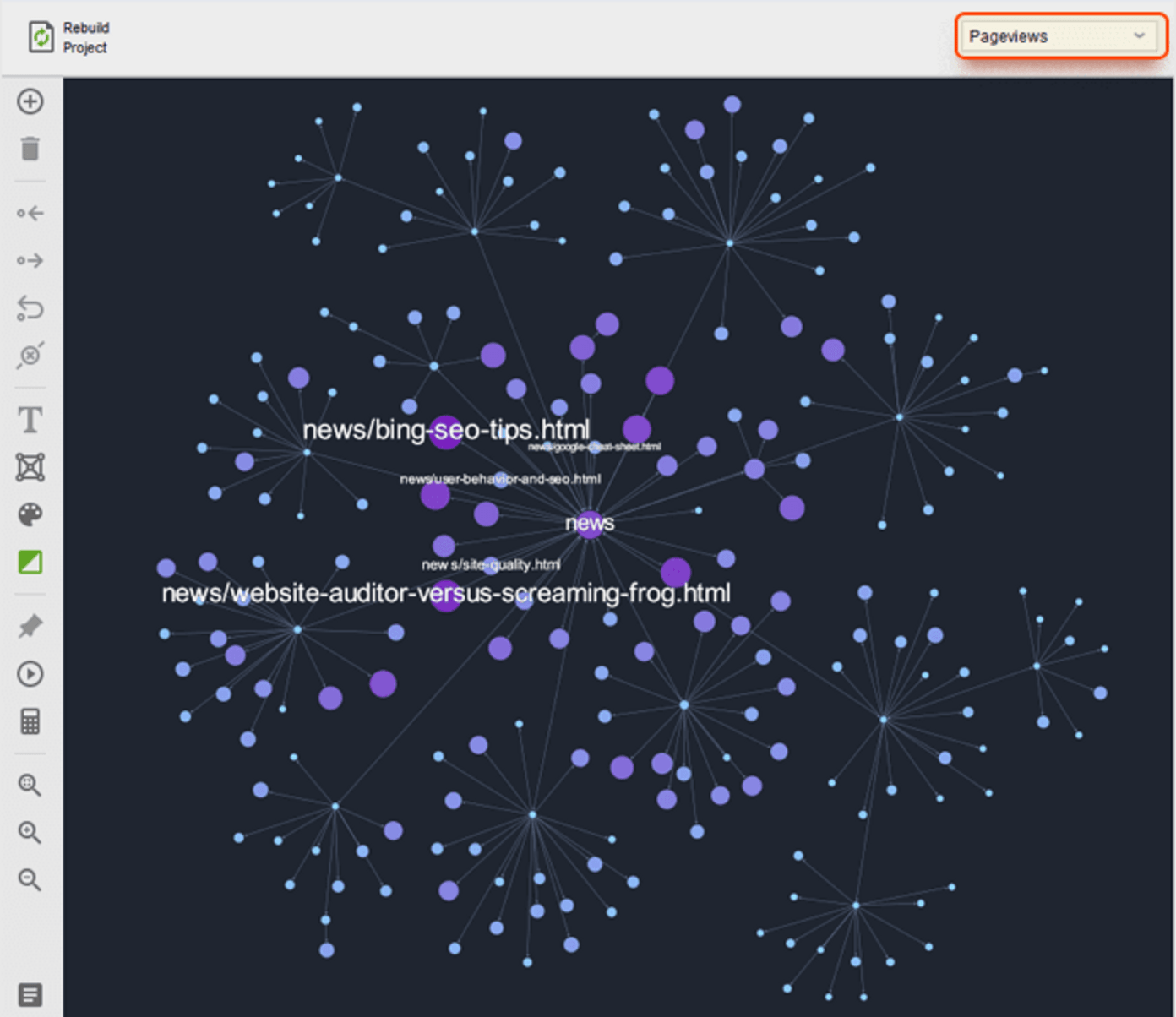
You can easily visualize the whole website structure using WebSite Auditor. Hop on to Site Structure and go to the Visualization module.
Once you're there, you'll see a graphical map of your pages and how they are related.
By default, pages are arranged by Click depth. This means that pages are shown according to the number of clicks needed to navigate to each page from the homepage.
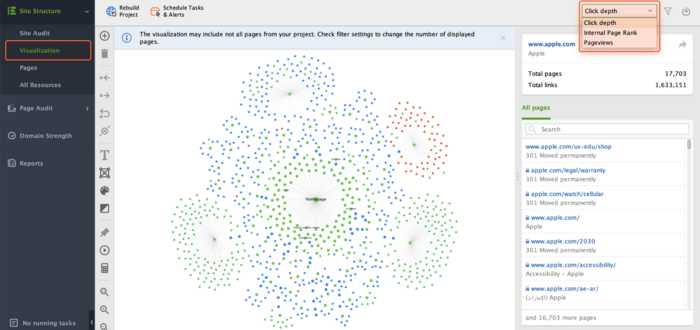
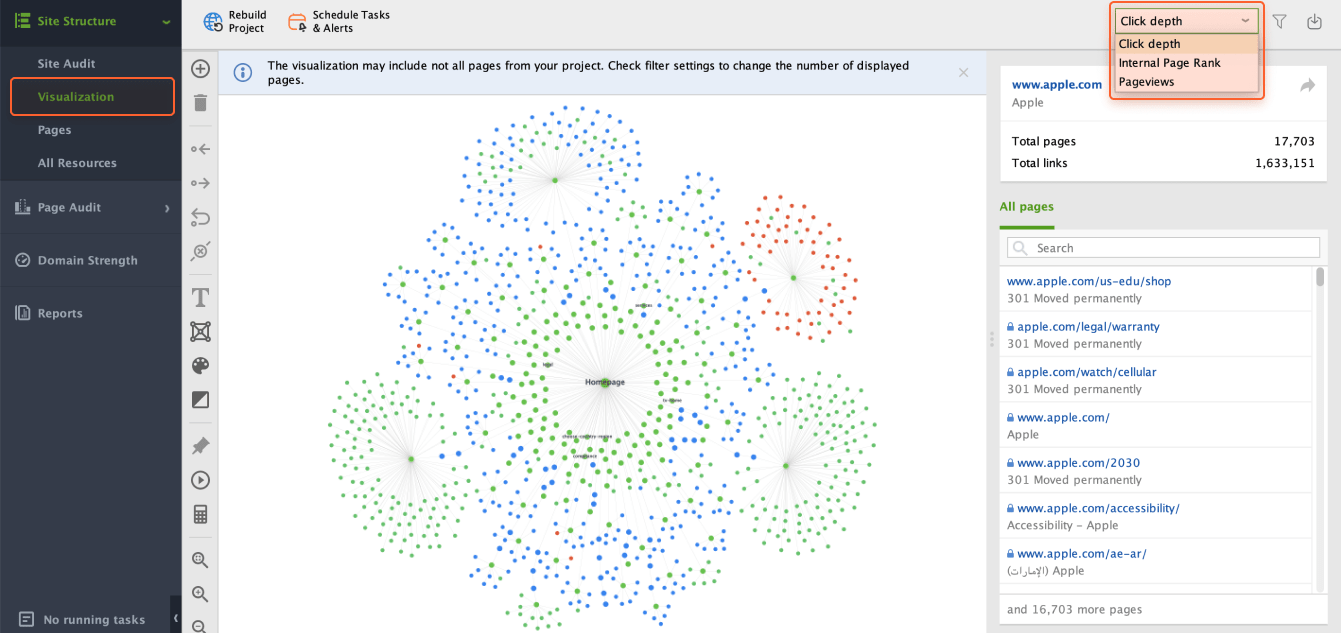
Check out the blue nodes for redirects and the red ones for broken links. And if you see any lonely grey nodes hanging around, those are your orphan pages.
You can also choose page representation by Internal Page Rank and Pageviews.
Internal Page Rank places pages based on their importance and authority within your website. The larger the node, the greater its value.
Pageviews arrange your website’s structure based on the most popular pages among your visitors. To set up a visual representation by Pageviews, connect your Google Analytics account by heading to Preferences > Google Analytics Settings.
Once done, refresh your data in Site Structure > Pages and hop over to the Visualization dashboard to rebuild your Pageviews graph. The node sizes now reflect the Pageviews value.
When reviewing your site’s structure, pay special attention to the following elements:
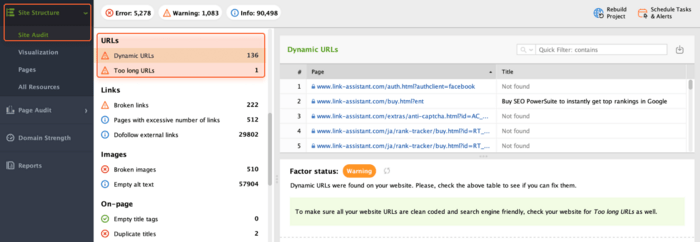
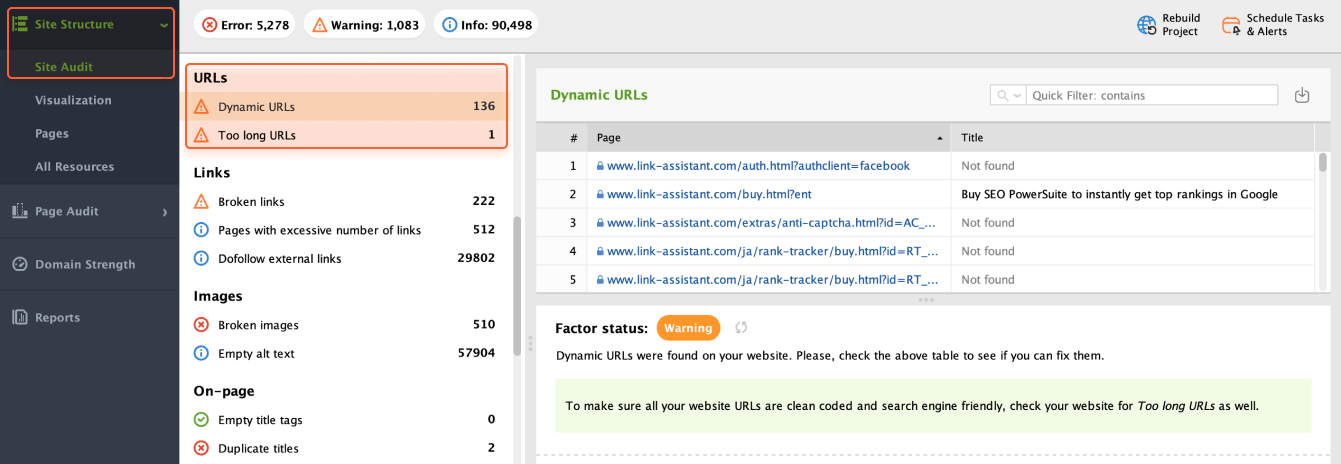
Let’s be honest, too-long or clumsy URLs don’t look trustworthy, neither for users nor for search engines. If you’re looking to optimize URLs, stick to the following best practices:
Make URLs simple and descriptive
Avoid making too-long URLs
Prefer static URLs over dynamic
Avoid using characters like "?", "_", and parameters
Try to use the main keyword of your page in the URL
You can look through your URLs in Site Audit > URLs.
Your website's navigation should be effortless for users so they can easily find what they’re looking for.
First, opt for clear menus. Overloaded menus and quirky names only seem cool but, in most cases, they confuse visitors.
Second, consider implementing breadcrumbs to help users grasp your page hierarchy. This user-friendly feature reduces frustration and enhances the browsing experience.
Breadcrumbs not only aid users but also provide valuable context to search engines about your site's content organization.
Despite all the tools available, creating menus that users and bots love still requires a human touch. So take your time to plan out your navigation elements carefully.
This step is one of the most important in our SEO audit checklist. When a web page's URL changes or moves to a new location, redirects are applied to help visitors land to the correct destination.
However, if redirects are set up incorrectly, visitors can encounter errors or irrelevant content. This harms their user experience and potentially drives them away from your website.
From an SEO perspective, improperly configured redirects can also prevent search engine crawlers from indexing and ranking your pages.
Here's what you can do to check if your redirects are set up properly:
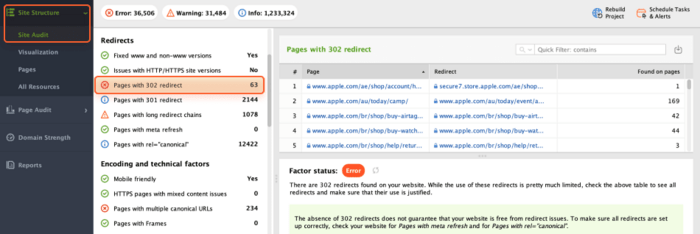
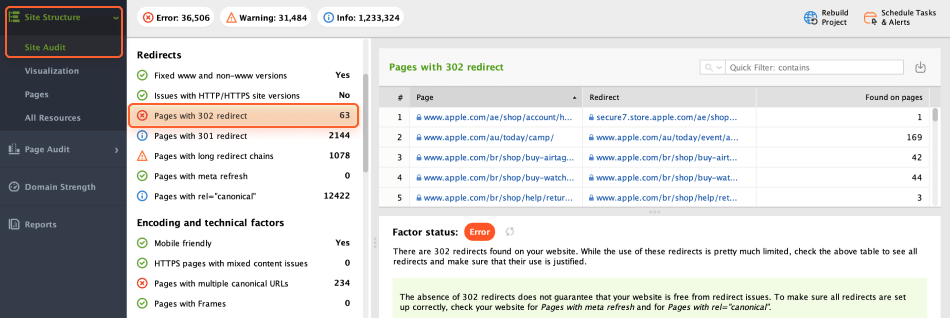
A 302 redirect is a type of HTTP status code used to temporarily redirect a web page to a different URL. It is used when a webpage is undergoing maintenance or when content has been temporarily moved to a different location.
While it's a valid method to redirect pages under specific circumstances, it does not pass on link juice to the destination URL.
To detect 302 redirects, head to Site Audit > Redirects. If your website has 302 redirects, look through the list and ensure their use is justified.
Another element that can affect your rankings is meta refresh. It is used to automatically redirect a webpage to a different URL. Spammers often exploit this method to redirect visitors to pages with unrelated or potentially harmful content. Search engines don’t approve such methods and can penalize your website for this.
To identify pages with meta refresh, head to Site Audit > Redirects.
In this case, we recommend opting for permanent 301 redirects as it’s usually a safer bet (unless the redirect is genuinely temporary).
If your website can be accessed with or without the "www" prefix in the URL, it’s crucial to make a choice and stick with it. Otherwise, both can be indexed by search engines, cause duplicate content issues, and undermine your website rankings.
To check www/no-www versions, open Site Audit > Redirects > Fixed www and non-www versions.
Here you’ll see if your website has variations that should be correctly redirected to the canonical version.
Like in the previous case with www/no-www versions, the HTTP/HTTPS versions of your website should be also set properly to avoid indexing both ones.
Google introduced HTTPS as a ranking signal in 2014, and today HTTPS is the standard for virtually all websites — especially those handling user data or transactions. HTTPS is a more secure encryption, highly recommended for most websites (especially when taking transactions and collecting sensitive user data.)
HTTPS is now a baseline requirement for any website. If you are working with a legacy site that hasn't yet migrated, consult our guide on migrating to HTTPS.
To check your website for common HTTP/HTTPS issues, open Site Audit > Redirects > Issues with HTTP/HTTPS site versions.
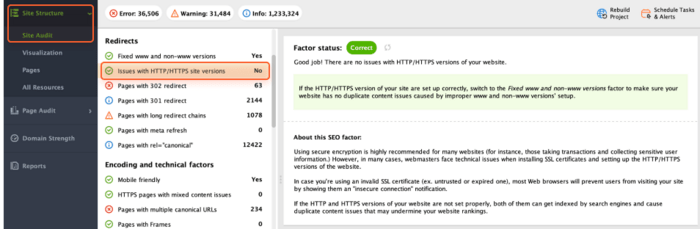
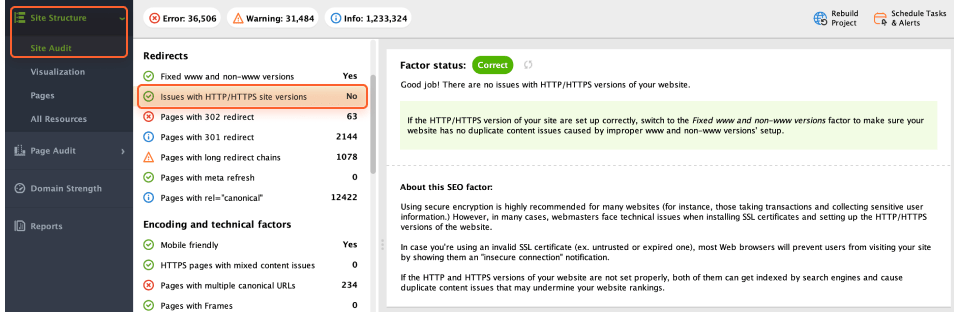
If any issues are found, WebSite Auditor will provide tips on resolving them.
Too-long redirect chains are a common pain in the neck. If you redirect several pages to one another with two or more 301 redirects, they will drop out of the index because Google does not crawl long redirect chains.
Thus, I recommend avoiding such multi-story redirect chains. Go to Site Audit > Redirects > Pages with long redirect chains. With a list of affected pages, you’ll be able to take action and cure this disease.
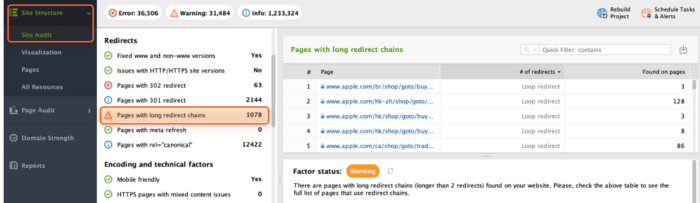
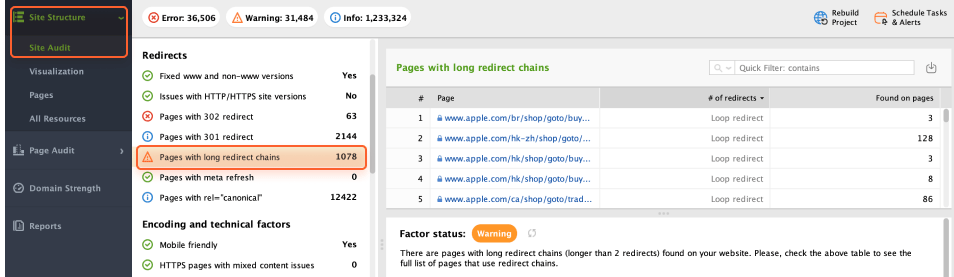
Prolonging existing redirects to the new site can hinder Google's ability to reach the intended page and waste the crawl budget. Moreover, long redirect chains deplete PageRank, diminishing the link juice your page should receive. Thus, it's important to eliminate long redirects on your site.
The rel="canonical" tag indicates the canonical version of a webpage when multiple URLs contain identical or similar content. It addresses issues of duplicate content by informing search engines which URL should be considered the main one.
Your task here is to set up canonical URLs for such pages. In the Site Audit module, navigate to Redirects > Pages with rel="canonical" to review which pages have canonical URLs set up.
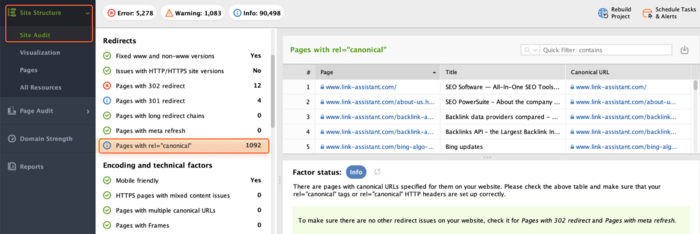
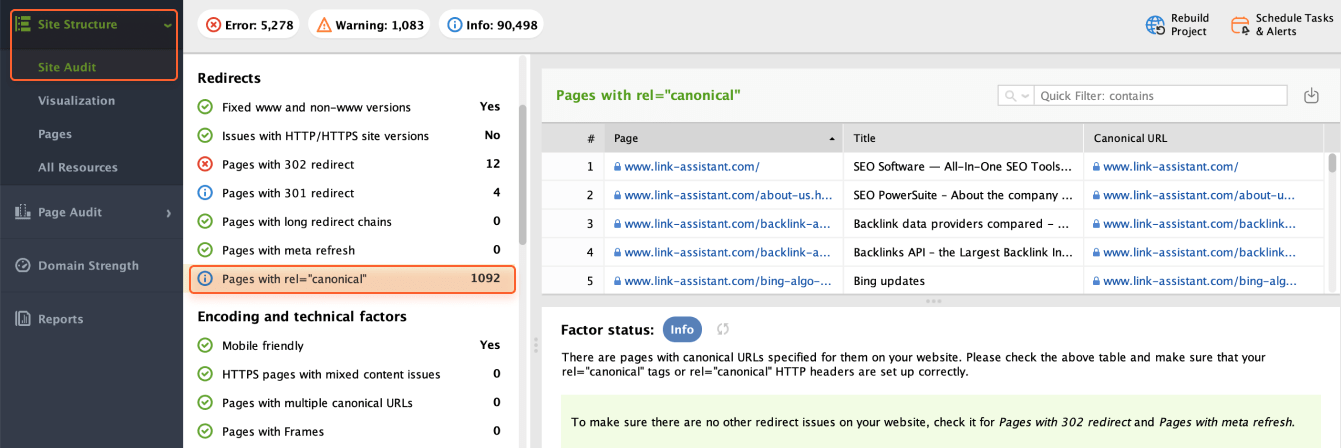
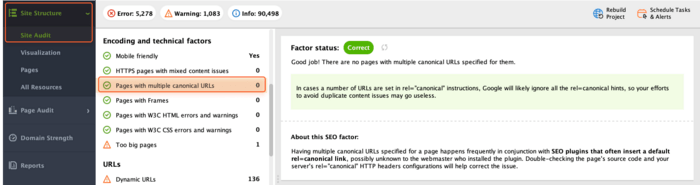
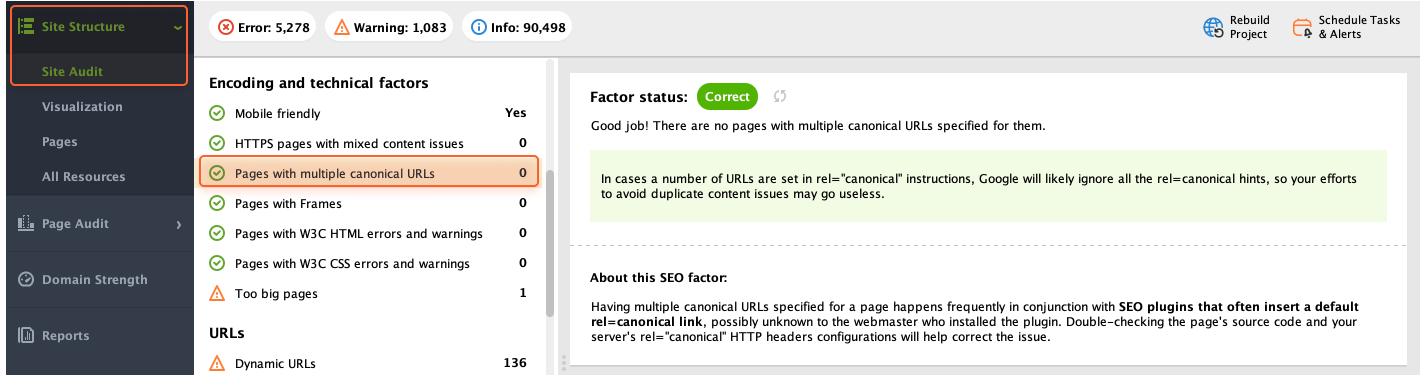
Plus, it's important to ensure that there aren't multiple canonical URLs assigned to a single page. Such conflicting signals can confuse Google and it will simply ignore all the rel=canonical tags. So, your attempts to eliminate duplicate content issues will stay ineffective.
To check this, review Pages with multiple canonical URLs in the Encoding and technical factors section.
Spotting internal linking problems on your site is crucial for maintaining your SEO health. When search engines struggle to understand the relations between content, certain pages may not be crawled or indexed correctly. That's why this step of the SEO audit checklist is extra important.
To avoid that, brush up on the following elements:
Broken links are like dead ends – they direct users to URLs that are inaccessible or no longer exist. As a result, users leave your website, and the link juice drains into nowhere. The more broken links you have, the higher the likelihood that Google may treat your content as spam.
While Google says that 404 errors are an inevitable part of web crawling, it's still not advisable to have a lot of them. Especially if you prioritize reputation management or your content falls within the YMYL (Your Money or Your Life) category.
To find all broken links on your website, scroll down to Broken links in the Links section of the Site Audit module.
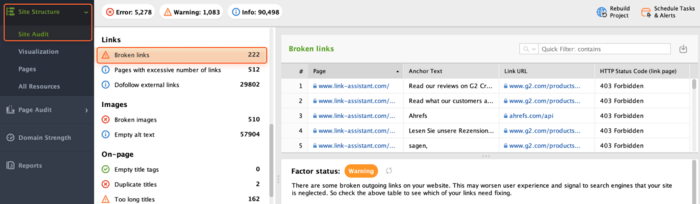
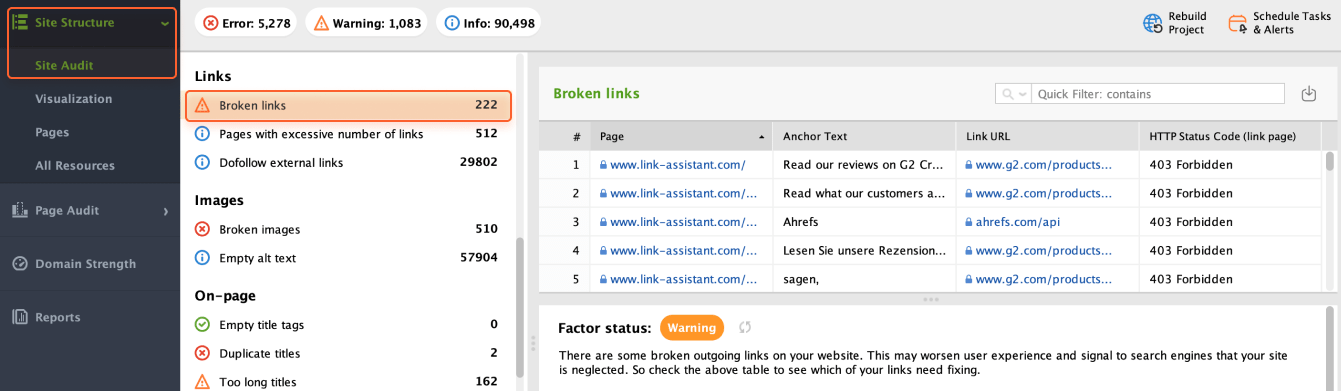
Here, you'll see the list of pages containing broken links, along with the URL of each broken link and its corresponding anchor text.
Once identified, you can take appropriate action:
Update the link to point to the correct URL
Remove the link if it is no longer relevant
Create a 301 redirect if you have similar information on another page
For more details and recommendations, explore our comprehensive guide on fixing broken links.
Sometimes, we may accidentally link too many resources on a single page. Even if you add those outgoing links with good intentions, Google may perceive your site as spammy. So it’s recommended not to cross the fine line between refining content with useful links and overwhelming your audience.
To check if you have pages too rich in links, head to Site Audit > Links > Pages with excessive number of links. WebSite Auditor will display a list of pages with the given issue.
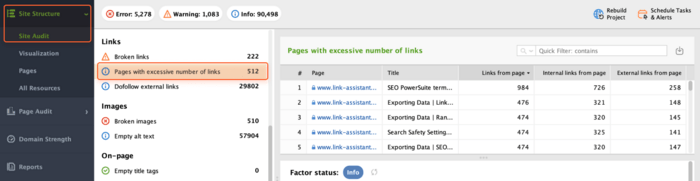
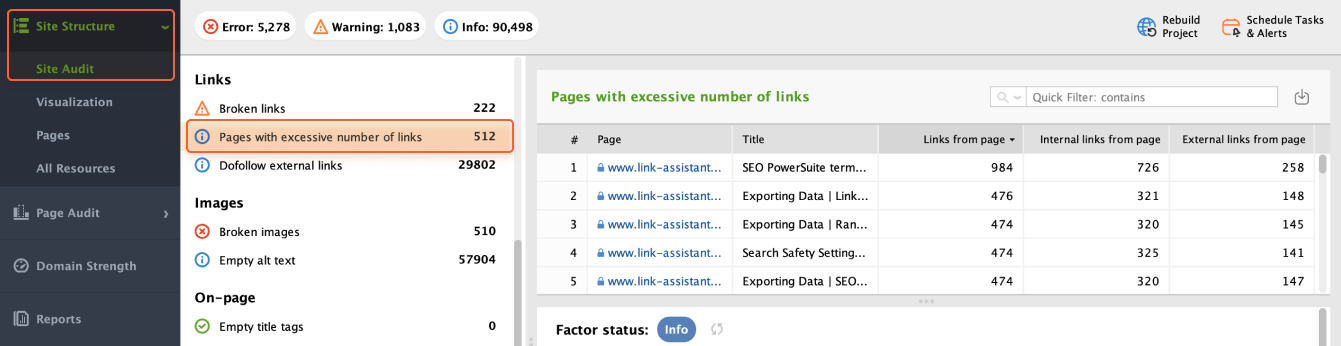
You just need to go through these pages and clean up unnecessary links.
Essentially, orphan pages are lost pages, no longer connected to the internal linking structure of the website. No active links point to them.
Use WebSite Auditor to locate these hidden pages. When creating a new project, tick Enable expert options and then select Search for orphan pages.
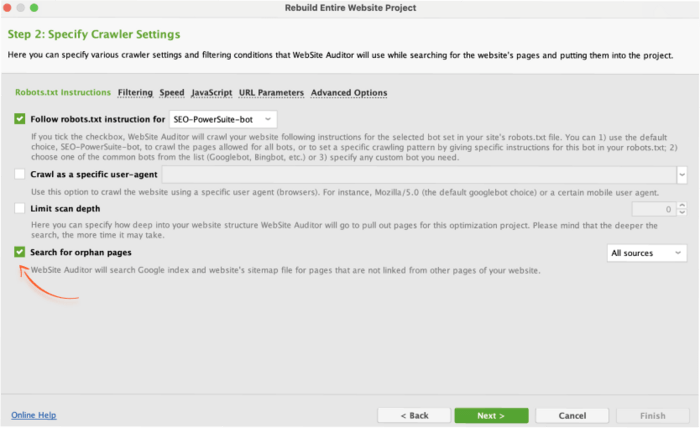
Once the crawl is complete, you’ll see orphan pages marked with grey nodes in the site structure.
But if you already created a project without enabling expert options, no worries. You can click Rebuild Project right in the Visualization module and recollect the data for your project.
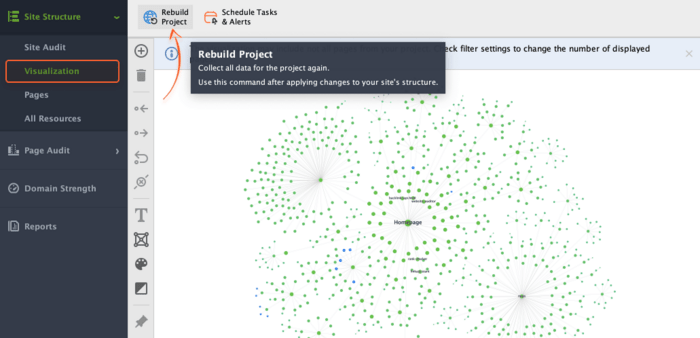
To deal with orphan pages, you can do the following:
If the page is important and has been overlooked, add a relevant link to reintegrate it into the website structure.
If the page duplicates existing content, set up a 301 redirect or set up rel="canonical" to direct traffic to the corresponding existing page.
Before you choose any of these solutions, I recommend checking each orphan page with Google Analytics to see if it gets traffic. If a page brings traffic, there is no need to delete it.
On-page tags are a direct ranking factor. Your pages will never show up in search without proper HTML tag optimization.
Search engines use titles and meta descriptions to form a search snippet. As the snippet is what users will see first, it greatly affects the organic click-through rate. So, make sure to address it.
Headings, together with paragraphs, bulleted lists, and other webpage structure elements, help create rich search results in Google. Moreover, they naturally improve readability and user interaction with the page, which may serve as a positive signal to search engines. You have to check and tidy up the titles, meta descriptions, and H1–H6 headings on all of your pages. WebSite Auditor can help you with that.
In the Site Audit module, check the On-page box to have the full picture of your on-page SEO health.
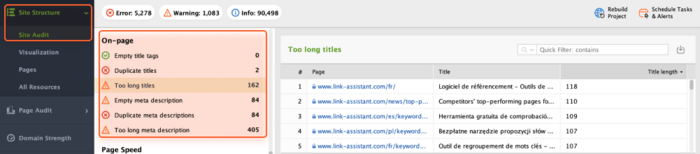
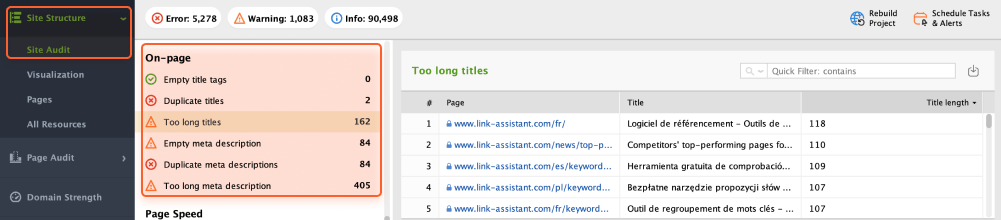
If you need to audit the individual page’s content in more detail, go to Page Audit > Content Audit and add the needed link to the search bar.
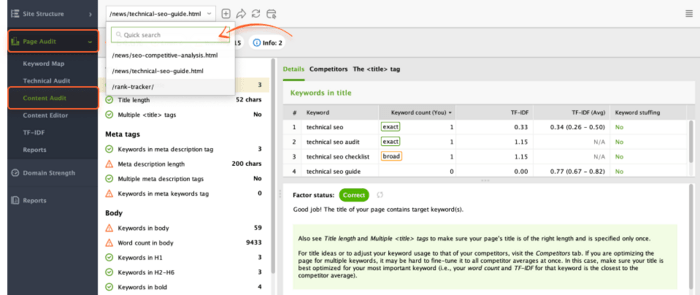
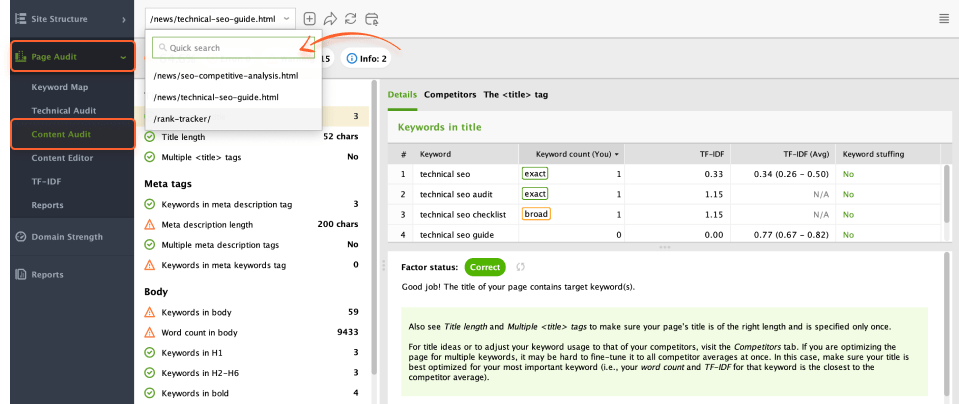
The app also has an in-built Content Editor tool that offers you suggestions on how to optimize pages’ content based on your top SERP competitors.
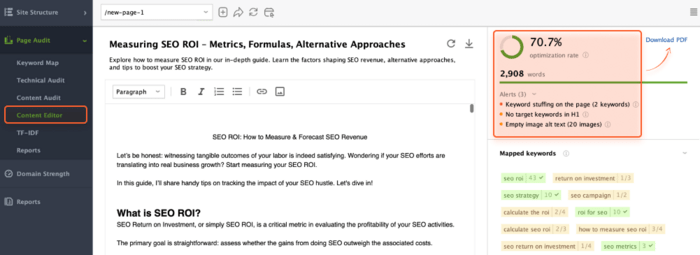
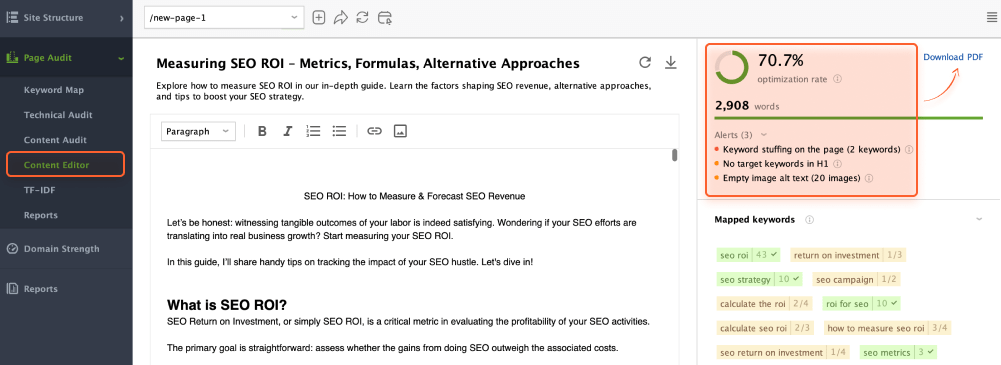
You can change the page’s content on the go to see how you can optimize the live version or Download PDF as a task for copywriters.
Though Google has no serious penalties for duplicate content, such pages can still ruin your position and reputation. For instance, Google’s algorithm can index the wrong version of a page and it will get into the SERP. Or the whole website may be poorly indexed and considered spammy due to the huge number of duplicates.
Of course, it’s much easier to avoid creating duplicate content than to find and fix it later. But judgment aside, sometimes it’s tough to avoid duplicates, especially on large e-commerce sites.
You can use WebSite Auditor to efficiently spot duplicate content issues. To do that, open the Site Audit module and check the On-page section (Duplicate titles and Duplicate meta descriptions). Here you will see the list of pages affected by the issue.
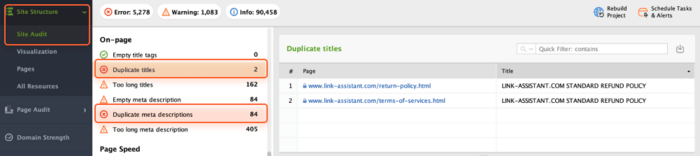
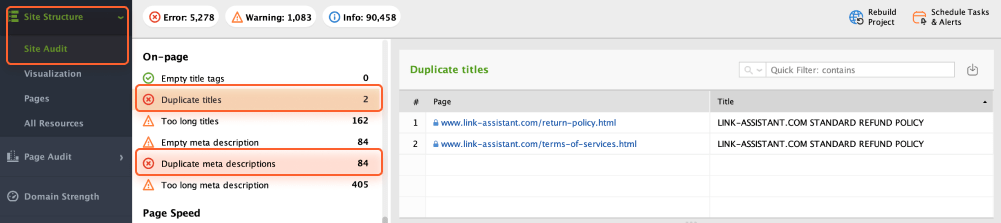
If duplicates are detected, you need to go through those pages and rewrite titles and descriptions. Plus, you can manually check if those pages provide valuable and unique content to users.
The pages with duplicate titles and meta description tags are likely to have nearly identical content as well.
If you also find duplicate content in the page text, you can do the following:
paraphrase the content to make it unique
set up a 301 redirect to ensure that both users and search engines can access the appropriate page
Site speed and page experience directly impact organic positions. As such, improving these aspects can lead to higher rankings and better visibility. At this step of the SEO audit checklist, you should audit your Core Web Vitals.
Core Web Vitals are a set of specific ranking factors that Google considers essential for measuring user experience.
Largest Contentful Paint (LCP): evaluates the loading time of your pages.
Cumulative Layout Shift (CLS): assesses the visual stability of a page during the loading process.
Interaction to Next Paint (INP): replaced FID as a Core Web Vitals metric in March 2024. INP evaluates how quickly a page responds to user actions like clicks, taps, and keyboard interactions during the entire visit — not just the first interaction.
With Core Web Vitals influencing rankings, it’s essential to guarantee seamless loading times and visual stability. WebSite Auditor can help you address this.
But before you start searching for pages that fall short of assessment standards, you need to get a Google PageSpeed Insights API key.
Simply open the Get Started page and click the Get a Key button.
Navigate to Site Audit > Page Speed > Pages that do not pass Core Web Vitals assessment to find areas that need improvement.
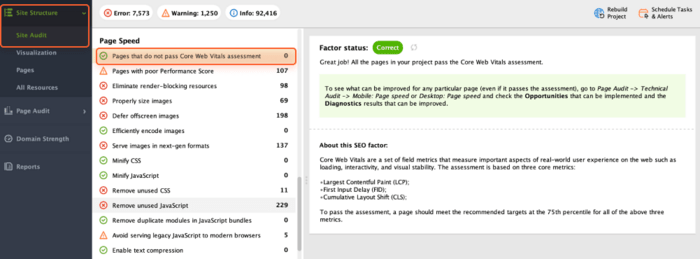
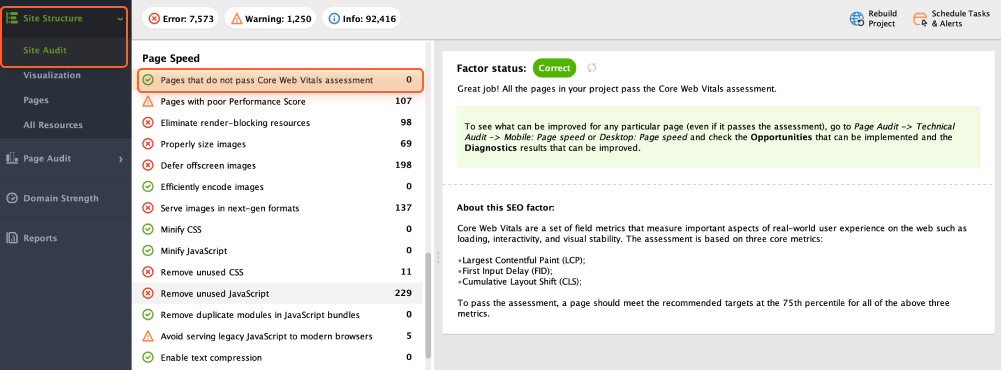
The benefit of using WebSite Auditor to audit Core Web Vitals is that you perform a bulk check for all the pages at a time. You receive up-to-date data from Google, relevant to the moment. If you see affected pages, follow the recommendations on the right to improve your website performance.
If you’re interested in exploring Core Web Vitals of a single page, navigate to the Page Audit section and access the Technical Audit tab.
Check the Mobile Friendliness and Page Speed section to identify actionable suggestions for optimizing performance.
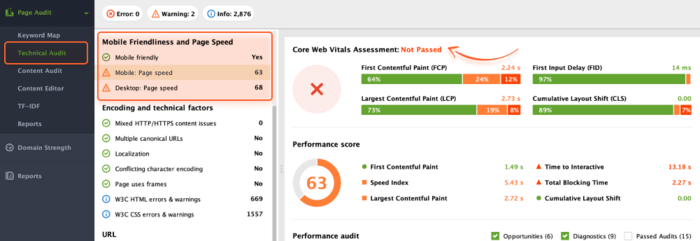
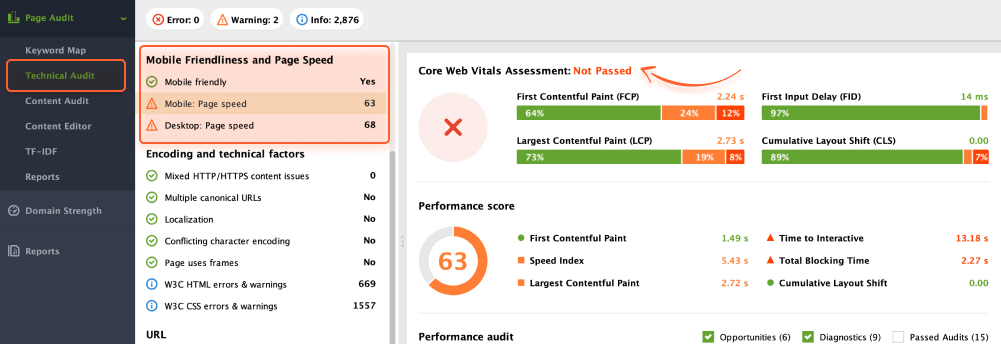
We recommend reviewing both the Mobile and Desktop aspects to enhance the performance of both versions of your page.
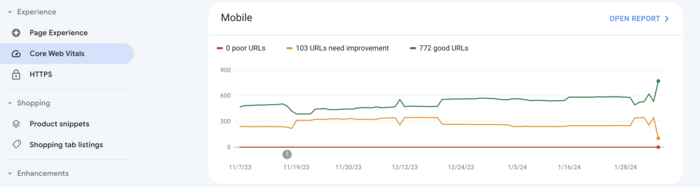
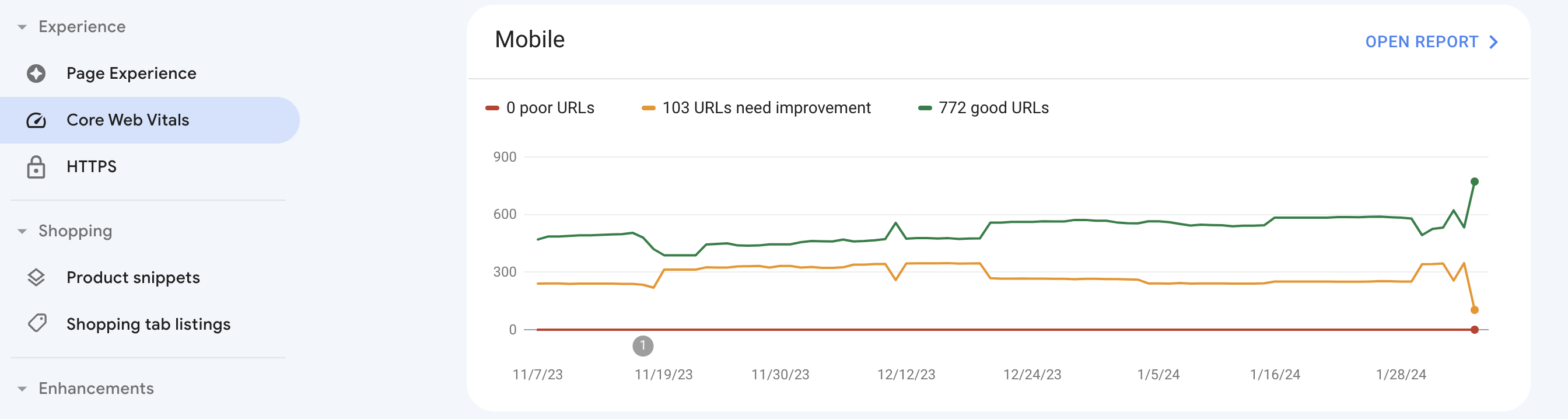
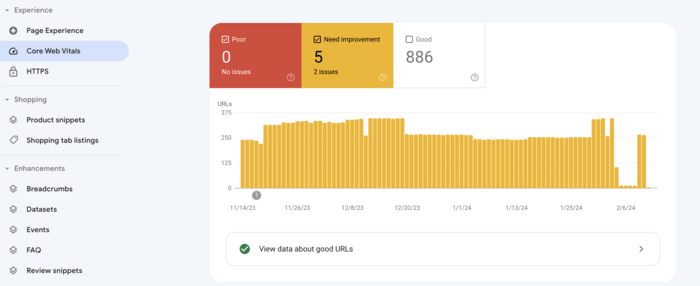
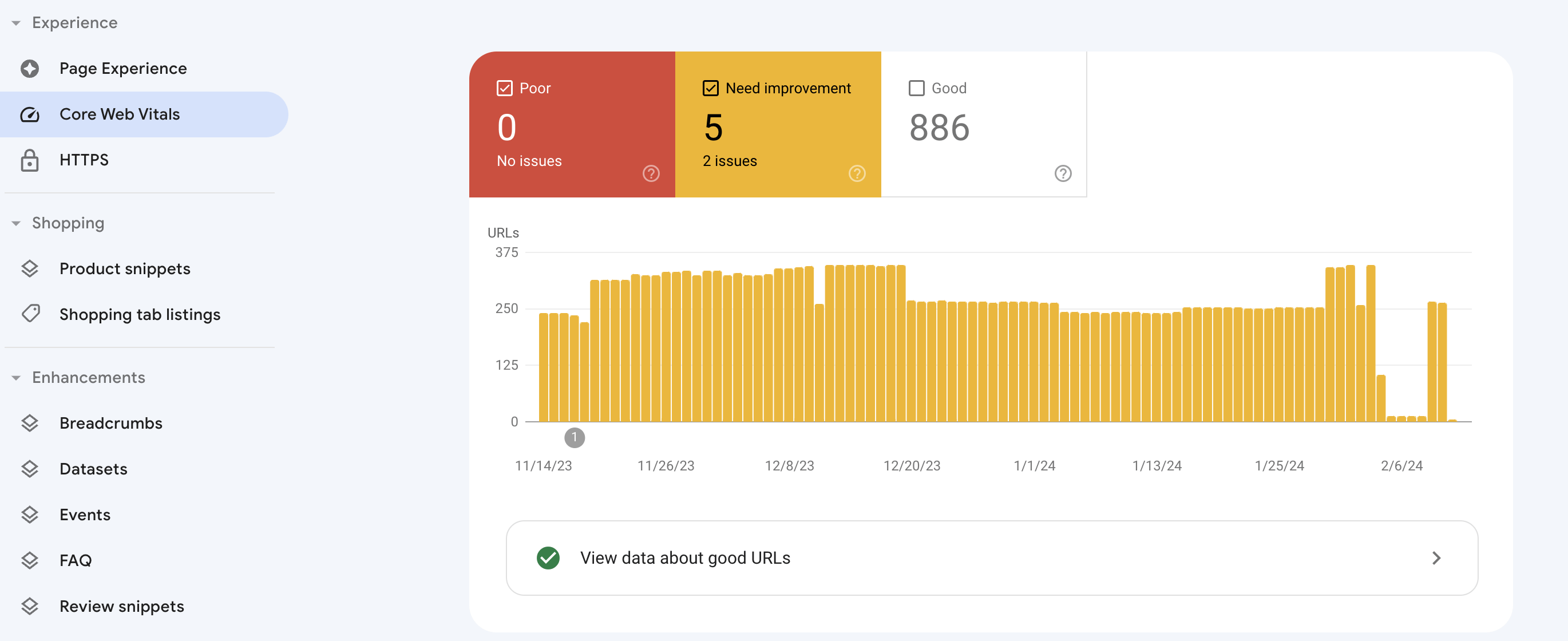
Alternatively, you can check Core Web Vitals using Google Search Console. Simply go to the Experience tab and click Core Web Vitals. The platform will showcase graphs on both mobile and desktop performance with an opportunity to open full reports with details and suggestions.
For a quicker check, you can also use the PageSpeed Insights tool. Simply enter the URL you want to analyze into the search bar, and the tool will generate a report with insights.
As you know, Google has fully switched to mobile-first indexing. So, mobile-friendliness bears paramount importance for organic rankings.
Typical issues that affect mobile-friendliness are as follows:
The text is too small to read
Viewport is not set
The content is wider than the screen
To assess mobile performance, go to Google Search Console and navigate to the Experience section, then open the Core Web Vitals report. Select the Mobile view to see pages with issues. For deeper diagnostics, use Google's PageSpeed Insights or Lighthouse, as the standalone Mobile Usability report and Page Experience report have been retired.
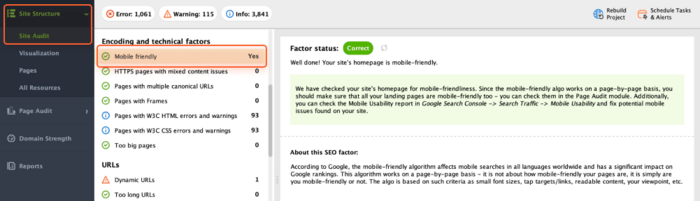
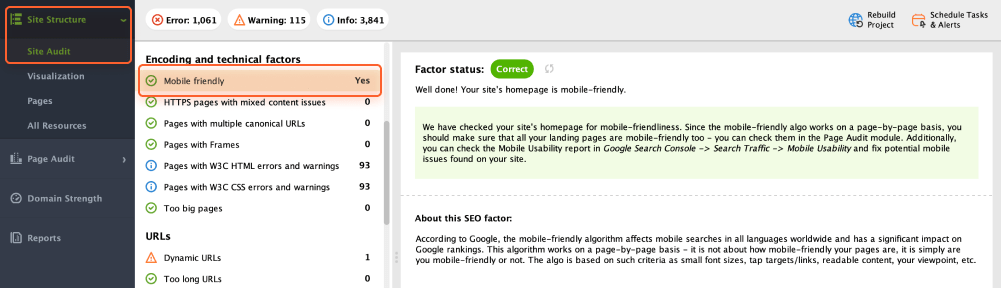
WebSite Auditor can also help you to review and point out some issues in mobile user experience. Go to Site Audit > Encoding and technical factors. The tool will show if the site is mobile-friendly (and showcase the list of issues, if any).
Even if the page seems fine and smooth visually, check its code anyway. Although the crooked code is not visible to users, Google can still see what’s under the hood. And if a search engine stumbles upon unreadable code, say goodbye to a decent loading speed and the first positions in the SERP.
The main aspects you should scrutinize in your website's code during a technical SEO audit:
W3C standards refer to the technical specifications established by the World Wide Web Consortium (W3C). These standards encompass protocols, languages, and guidelines that govern various aspects of web development, including HTML, CSS, XML, and more.
Adhering to W3C standards helps to build a robust and user-friendly web ecosystem.
To check that no pages show W3C errors or warnings, open Site Audit > Encoding and technical factors.
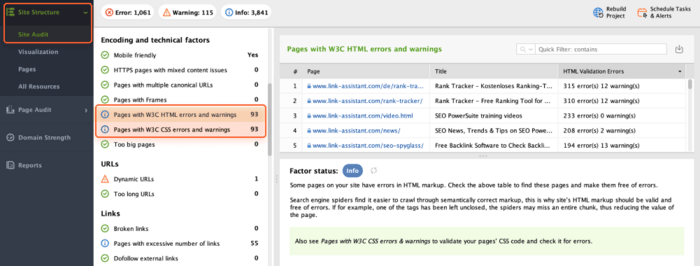
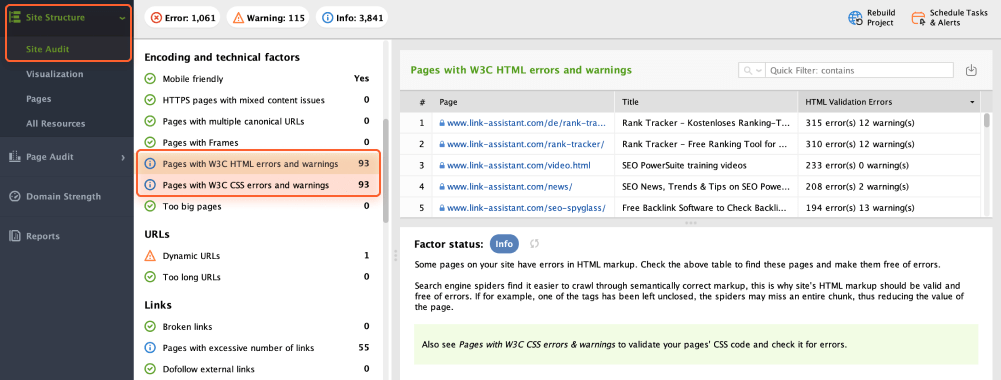
If any of your pages have issues, check the platform recommendations and take relevant measures.
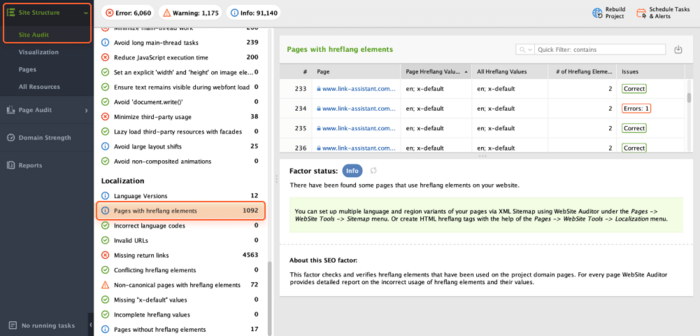
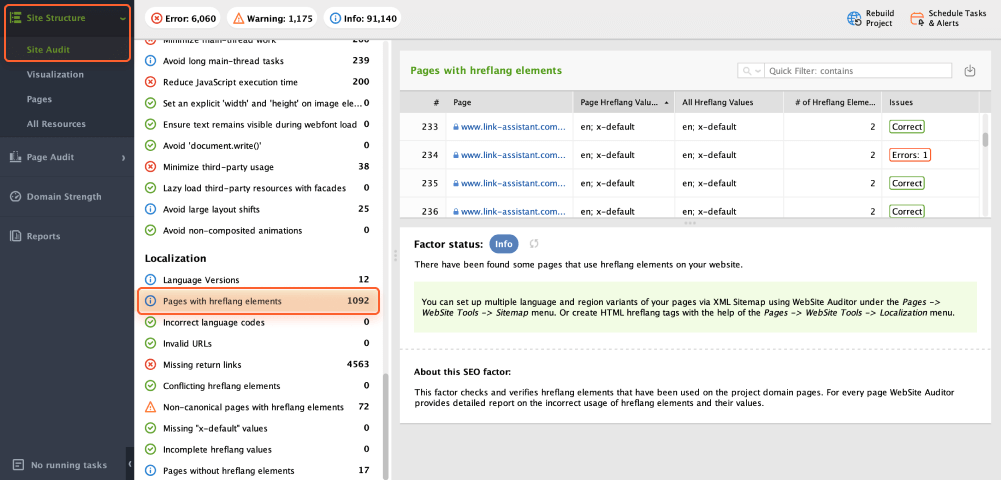
Hreflang is an HTML attribute used to specify the language and geographical targeting of webpages in multilingual websites. It helps search engines understand which version of a webpage serves users based on their language and location preferences.
However, incorrectly specified country codes or conflicting hreflang tags can lead to potential issues such as misinterpretation by search engines, improper indexing, and lower visibility.
To check your hreflang annotations, navigate to the Site Audit module and examine the Localization box.
Check Language Versions to see what language versions your website has. Additionally, review Pages with hreflang elements to get a list of URLs with those elements.
Your website may encounter various JavaScript issues, such as rendering errors, unused files, and more. If there are errors or conflicts in the JavaScript code, it can prevent certain parts of the page (or entire page) from loading and rendering properly. Google sees those pages as blank which leads to a decrease in rankings.
To audit your site for JavaScript issues, you need to enable JavaScript execution in expert options when you create a new project (or rebuild an existing one). To do this, click JavaScript and tick Execute JavaScript.
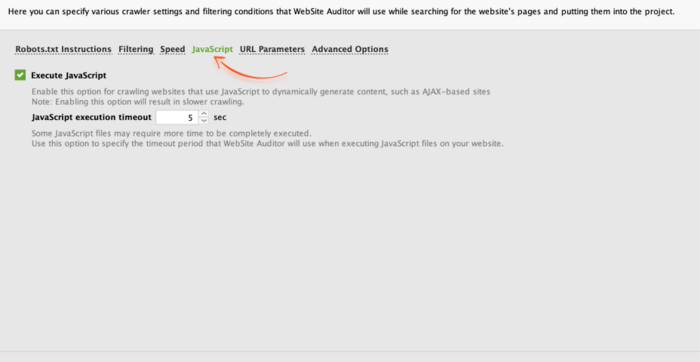
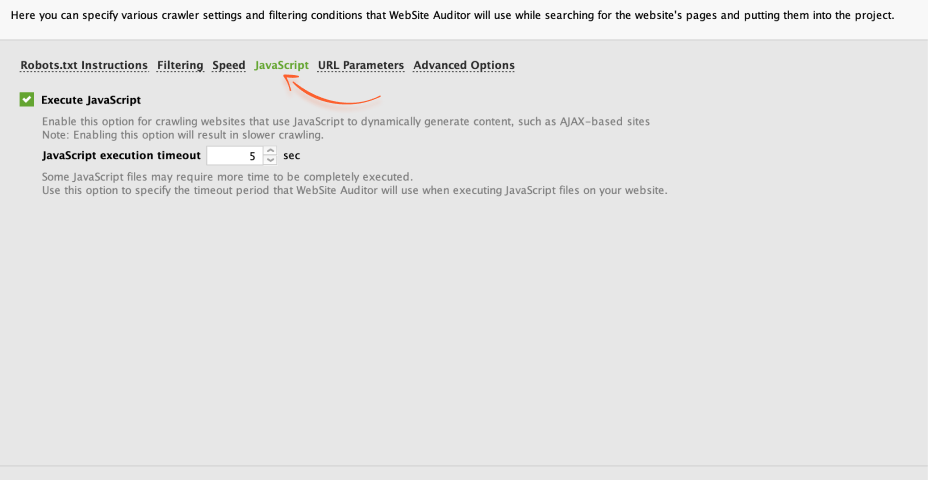
Once the crawling is done, open Site Audit > Page Speed to look through possible JavaScript issues.
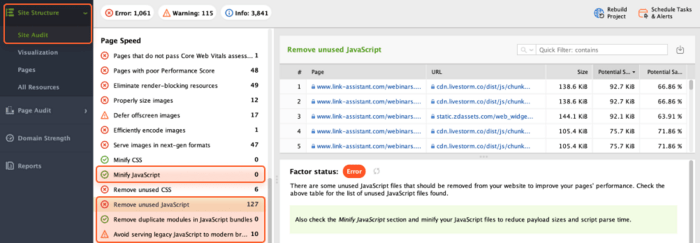
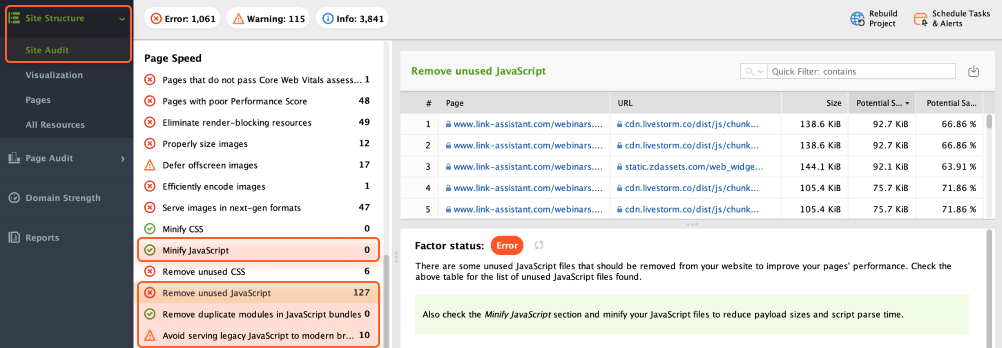
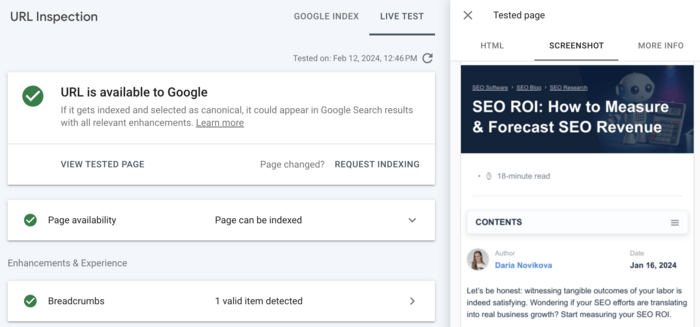
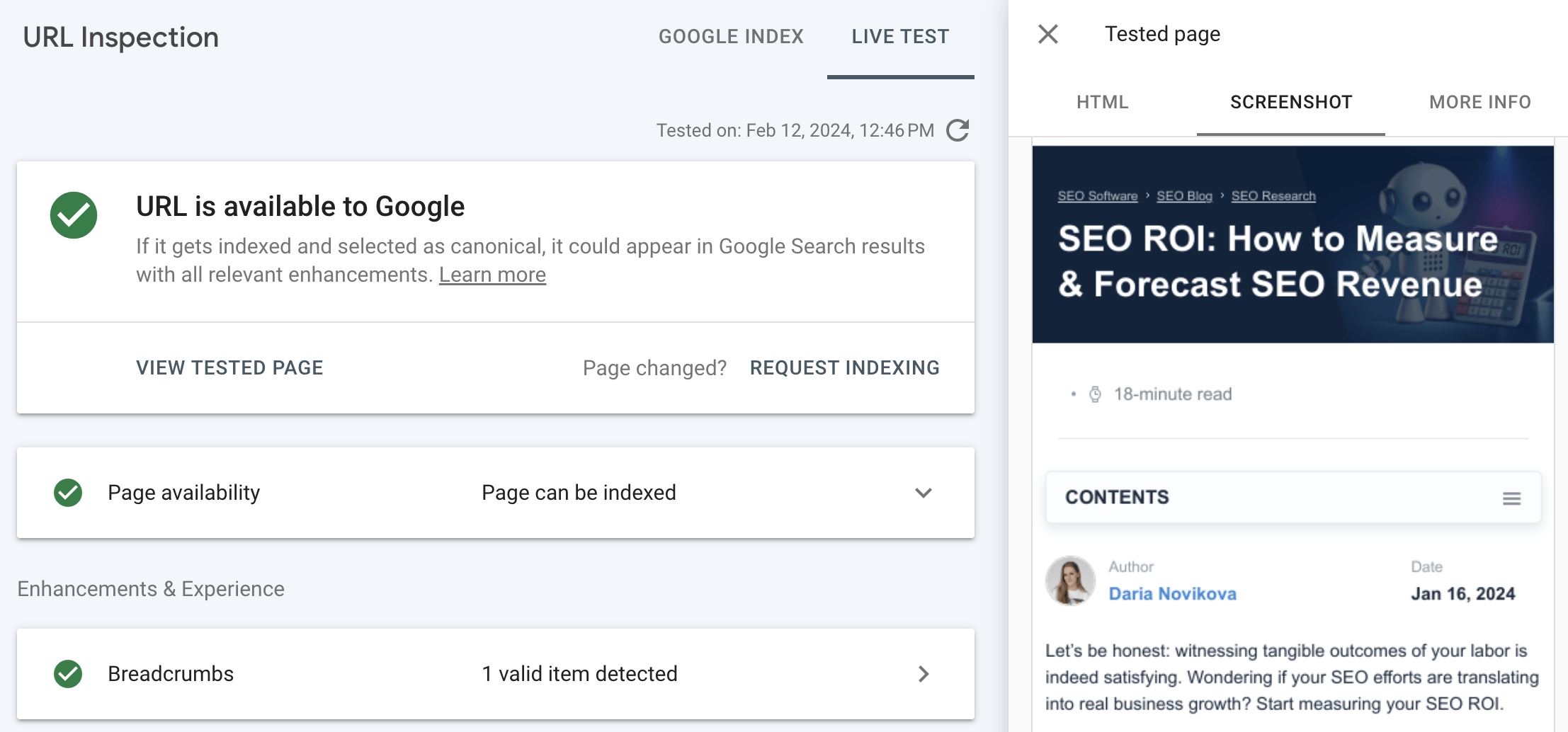
With a list of affected pages, you can also check how Google renders a certain page in Google Search Console.
Enter a page address in the URL Inspection tool and click the Test live URL button.
When testing is completed, you will be able to see a screenshot of the page as Google renders it.
Structured data is a semantic markup that lets search bots better understand a page’s content. If your pages contain information about an individual, product, or local business, among others, then the markup is especially recommended.
Say, your page features an apple pie recipe. In this case, you can use structured data to tell Google which text is the ingredients, cooking time, calorie count, and so forth. Since Google best understands digestible content format, the presence of structured data is your chance to get into rich snippets.
Mind that manipulating structured data may cause penalties from search engines. For example, the markup should not describe the content that is hidden from users (i.e. which is not located in the HTML of the page).
Test your markup using Google's Rich Results Test (to check eligibility for rich results in Google Search) or the Schema Markup Validator at validator.schema.org (for broader schema.org validation). Both replace the deprecated Structured Data Testing Tool.
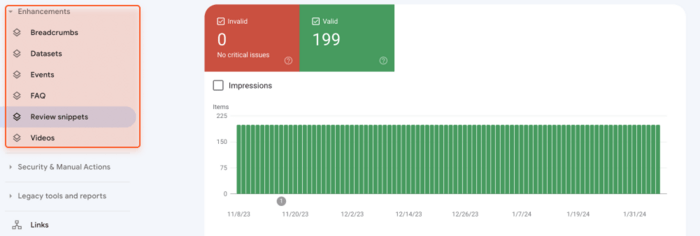
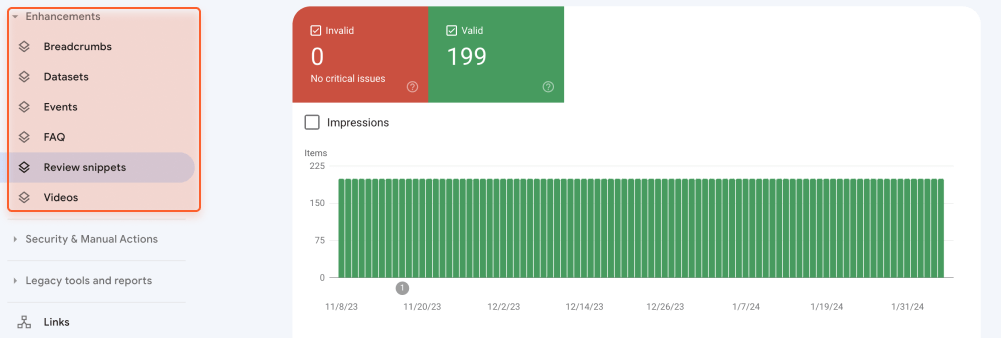
You can check the state of your schema markup in Google Search Console. Access Google Search Console, navigate to the Enhancements section, and review the status of different types of structured data markup implemented on your pages. The tool will also display critical issues, if any.
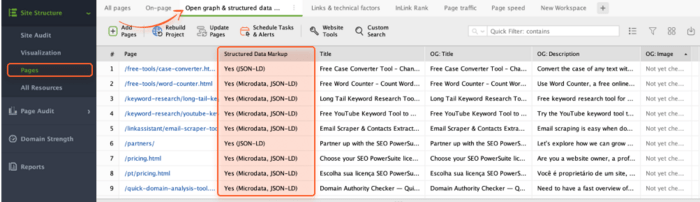
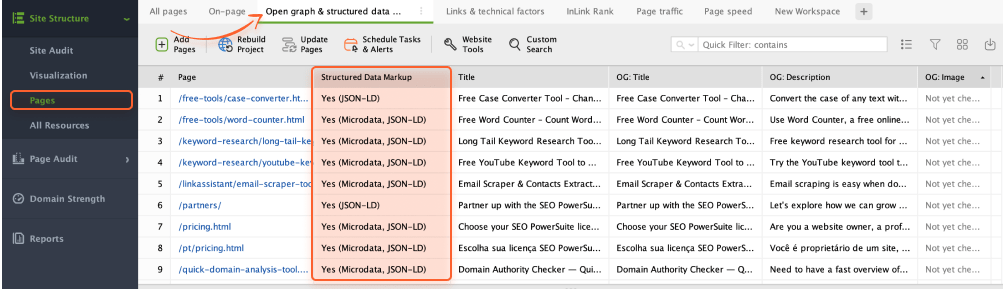
WebSite Auditor can also help you review all your structured data elements. Hop on to Pages > Open graph and structured data markup.
Once you’ve completed all the steps of the SEO audit checklist and fixed all the technical issues, you can ask Google to recrawl your pages to make it see the changes quicker.
To do this, in Google Search Console, submit the updated URL (or several URLs) to the URL Inspection tool and click Request indexing.
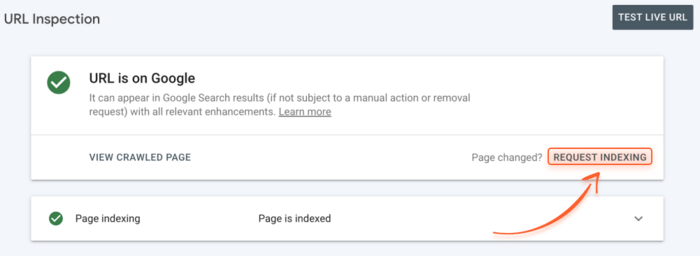
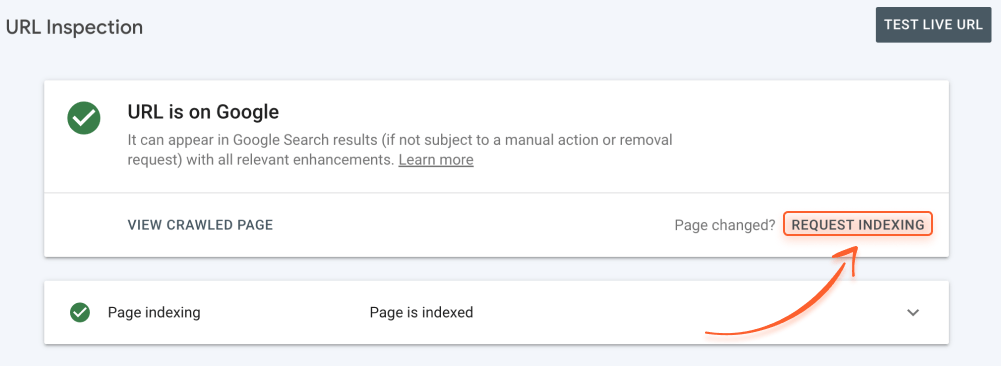
Keep in mind that you don’t need to force recrawling any time you change something on your website.
Consider recrawling if the changes are serious: say, you moved your site from HTTP to HTTPS, added structured data, did some great content optimization, or released an urgent blog post you want to appear on Google quickly.
Recrawling may take from a few days to several weeks, depending on how often the crawler visits the pages. Requesting a recrawl multiple times will not speed the process up.
If you need to recrawl a massive amount of URLs, you can submit a sitemap instead of manually adding each URL to the URL inspection tool.
Numerous unexpected events can happen on the web, and some of them can mess up your rankings. Plus, don’t forget about the human factor, as sometimes a website owner can accidentally break something. That’s why regular technical SEO audits of your website should be an essential part of your SEO strategy.
To play on the safe side, you can automate technical SEO audits and set up alerts in WebSite Auditor. In the Preferences menu, go to Schedule Tasks & Alerts. In the pop-up window, click Add and choose the Rebuild project option.
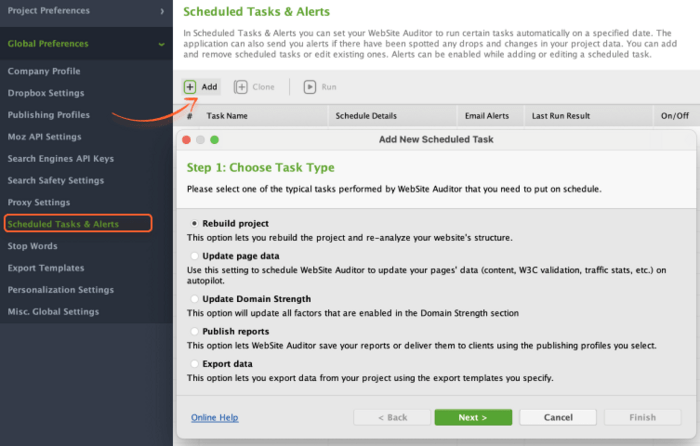
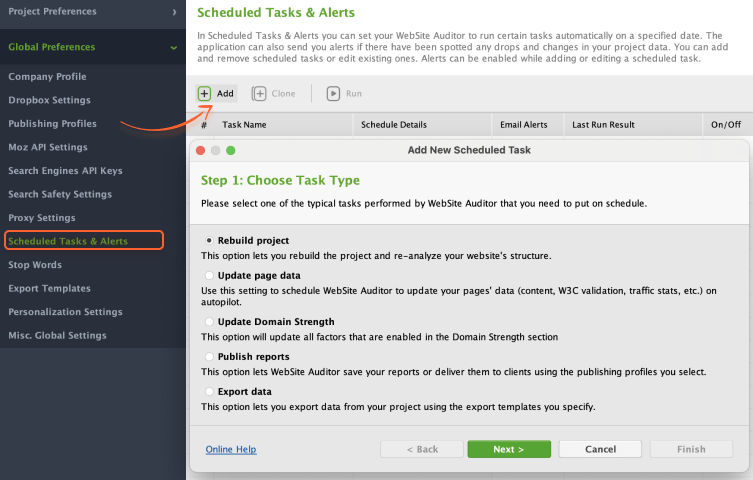
Select the project, set up the Task Schedule Settings, and click Next.
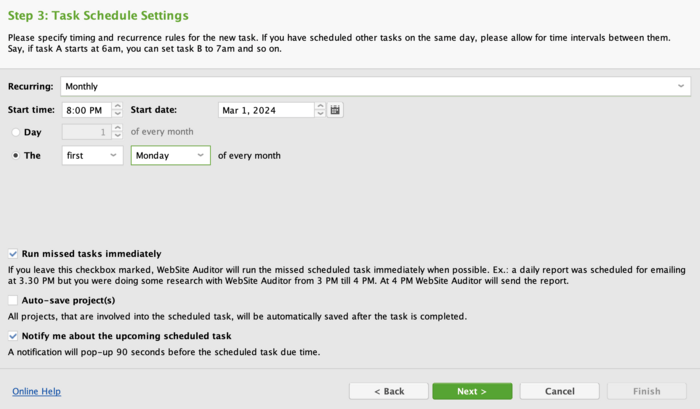
Select the conditions under which you should receive a notification and specify your email.
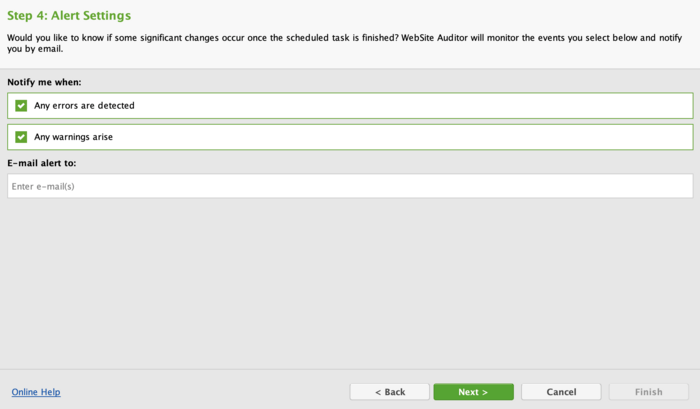
Here you are. WebSite Auditor will automatically recrawl your website and send timely alerts if something goes wrong.
I know, tackling a technical SEO audit may seem daunting at first sight. But I hope that following the instructions of my technical SEO audit checklist will help you nail this task and maintain your website in good shape.
And don’t forget to grab our SEO audit checklist for a quick revision later on.
If you have any extra lifehacks for checking your website’s SEO health, join our Facebook community to share your ideas.



