7 Sneaky Types of Duplicate Content


Duplicate content is a big topic in the SEO space. When we hear about it, it's mostly in the context of Google penalties; but this potential side effect of content duplication is not only blown up in importance (Google hardly ever penalizes sites for duplicate content per se), but also hardly the gravest consequence of the issue. The 3 far more likely problems that may be caused by an SEO duplicate page, they are the following:
- Wasted crawl budget. If content duplication appears internally on your site, it's guaranteed to send some of your crawl budget (aka the number of your pages search engines crawl per unit of time) to waste. This means that the important pages on your site are going to be crawled less frequently.
- Link juice dilution. For both external and internal content duplication, link juice dilution is one of the biggest SEO downsides. Over time, both URLs may build up backlinks pointing to them, and unless one of them has a canonical link (or a 301 redirect) pointing to the original piece, the valuable links that would have helped the original page rank higher get distributed between both URLs.
- Only one of the pages ranking for target keywords. When Google finds duplicate content or copied content instances, it will typically show only one of them in response to search queries — and there's no guarantee it's going to be the one you want to rank.
But all of these scenarios are preventable if you know where duplicate content may hide, how to detect it, and how to deal with duplicate content. In this article, I'm going to outline first and foremost 'What is duplicate content', along with the 7 common types of content duplication — and then dealing with duplicate content.
1. Scraped content
Scraped content is basically an unoriginal piece of content on a site that has been copied from another website without permission. As I said earlier, Google may not always be able to tell between the original content and the duplicate content, so it's often the site owner's task to be on the lookout for scrapers and know what to do if their content gets stolen.
Alas, this isn't always easy or straightforward. But here's a little trick that I personally use.
If you track how your content gets shared and linked to online (and if you have a blog, you really should) via a social media/Web monitoring app, like Awario, you can hit two birds with one stone here. In your monitoring tool, you would typically use your post's URL and title as keywords in your alert. To also search for scraped versions of your content, all you need to do is add another keyword – an extract from your post. Ideally, it should be pretty long, e.g., a sentence or two. Surround the piece with double quotes to make sure you're searching for an exact match. It's going to look like this:
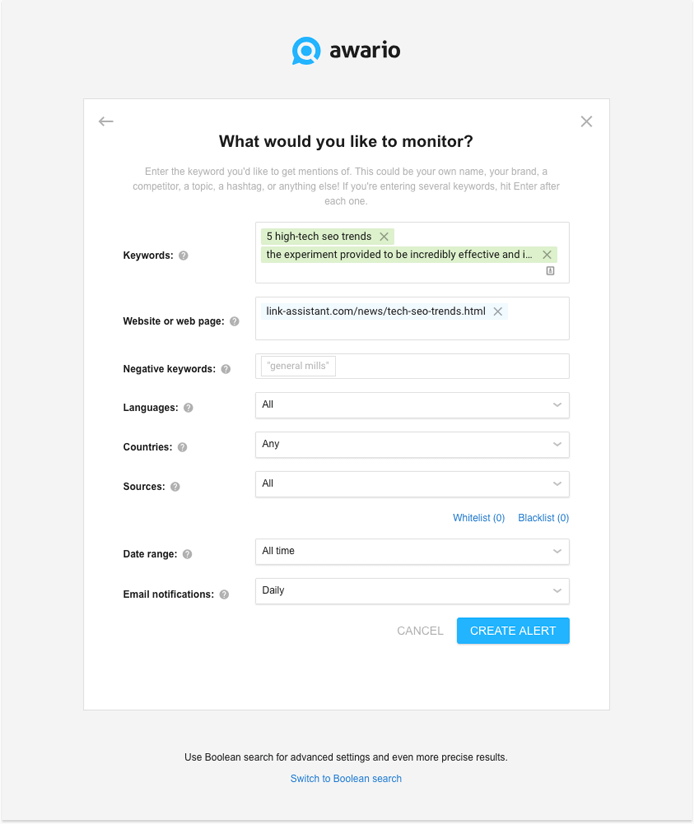
With this setup, the app is going to look for both mentions of your original article (like shares, links and such) and the potential scraped or copied content of the versions found on other sites.
If you do find duplicate website content, it's a good idea to first contact the webmaster asking them to remove the piece (or put a canonical link to the original if that works for you). If that's not effective, you may want to report the scraper using Google's copyright infringement report.
2. Syndicated content
Syndicated content is content republished on a different website with the permission of the original piece's author. This is what duplicate content generally refers to, so while it is a legit way to get your content in front of a new audience, it's important to set guidelines for the publishers you work with to make sure syndication doesn't turn an SEO duplicate page into an SEO problem.
Ideally, the publisher should use the 'rel=canonical' tag on the article to indicate that your site is the original source of the content, avoiding a duplicate content penalty. Another option is to use a noindex tag on the syndicated content. It's always best to manually check this whenever a syndicated piece of your content goes live on another site.
3. HTTP and HTTPS pages
One of the most common internal duplication problems are identical HTTP and HTTPS URLs on a site, even when both feature the same original content. These issues arise when the switch to HTTPS isn't implemented with the thorough attention the process requires. The two most common scenarios when this happens are:
1. Part of your site is HTTPS and uses relative URLs. It's often fair to use a single secure page or directory (think login pages and shopping carts) on an otherwise HTTP site. However, it's important to keep in mind that these pages may have internal links pointing to relative URLs rather than absolute URLs:
- Absolute URL: /rank-tracker/
- Relative URL: /rank-tracker/
Relative URLs don't contain protocol information; instead, they use the same protocol as the parent page they are found on. If a search bot finds an internal link like this and decides to follow it, it'd go to an HTTPS URL. It could then continue the crawling by following more relative internal links, and may even crawl the entire website in the secure format, and thus index two completely identical versions of your site's pages. In this scenario, you'd want to use absolute URLs instead of relative URLs in internal links. If there already are duplicate HTTP and HTTPS pages on your site, permanently redirecting the secure pages to the correct HTTP versions is the best solution.
2. You've switched your entire site to HTTPS, but its HTTP version is still accessible. This can happen if there are backlinks from other sites pointing to HTTP pages, or because some of the internal links on your site still contain the old protocol, and the non-secure pages do not redirect visitors to the secure ones. To avoid dilution of link juice and wasting your crawl budget, use the 301 redirect on all your HTTP pages, and make sure that all internal links on your site are specified via relative URLs.
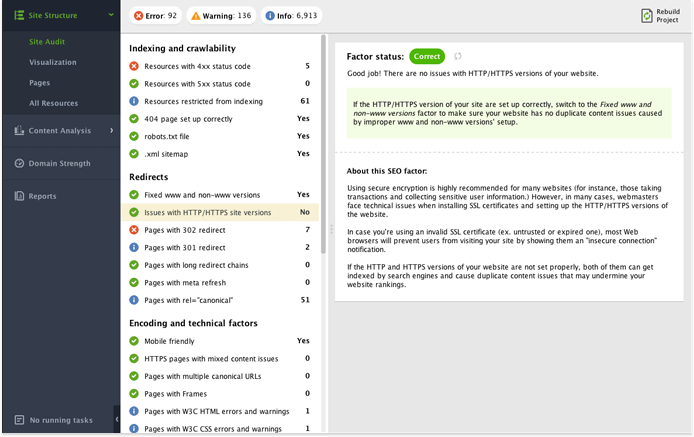
You can quickly check if your site has an HTTP/HTTPS duplication problem in SEO PowerSuite's WebSite Auditor. All you need to do is create a project for your website; when the app is done crawling, click on Issues with HTTP/HTTPS site versions in your site audit to see where you stand.
4. WWW and non-WWW pages
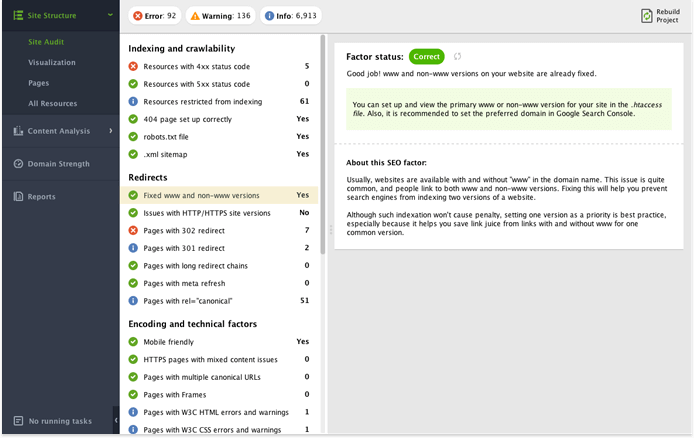
One of the oldest causes for duplicate content in the book is when the site's WWW and non-WWW versions are both accessible. Like with HTTPS causing internal content duplication, this duplicate content generally can fixed by implementing 301 redirects. Perhaps an even better option is specifying your preferred domain in Google Search Console.
To check if there are instances of such duplication on your site, look at Fixed www and non-www versions (under Redirects) in your WebSite Auditor project.
5. Dynamically generated URL parameters
Dynamically generated parameters are often used to store certain information about the users (such as session IDs), or to display a slightly different version of the same page (such as one with sorting or filtering adjustments made). This results in URLs that look like this:
- URL 1: /rank-tracker.html?newuser=true
- URL 2: /rank-tracker.html?order=desc
While these pages will typically contain the same (or highly similar) content, both are fair game for Google to crawl. Often, dynamic parameters will create not two, but dozens of different versions of the URL, which can result in massive amounts of crawl budget spent in vain.
To check if this is a problem on your site, go to your WebSite Auditor project and click Rebuild Project. At Step 1, check the Enable expert options box. At the next step, select Googlebot to in the Follow robots.txt instructions for… option.
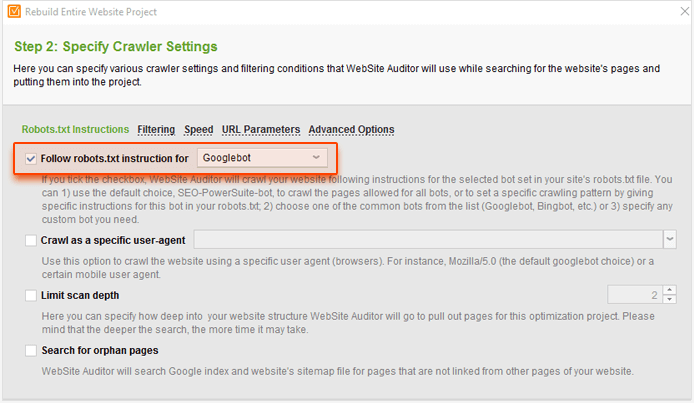
Then, switch to the URL Parameters tab and uncheck the Ignore URL parameters box.
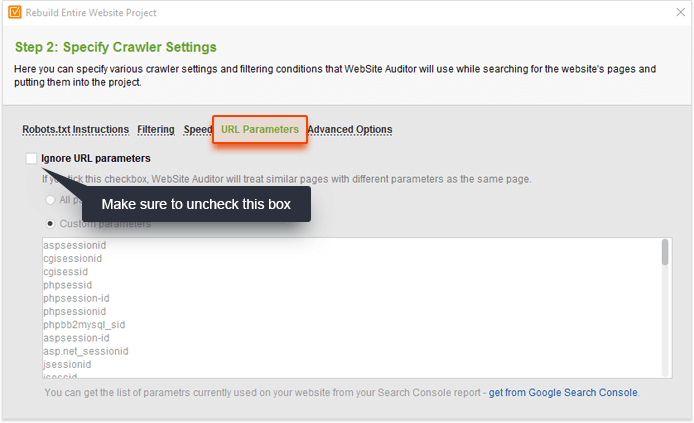
This setup will let you crawl your site like Google would (following robots.txt instructions for Googlebot) and treat URLs with unique parameters as separate pages. Click Next and proceed with the next steps like usual for the crawl to start. When WebSite Auditor is done crawling, switch to the Pages dashboard and sort the results by the Page column by clicking on its header. This should let you easily spot duplicate pages or copied content with parameters in the URL.
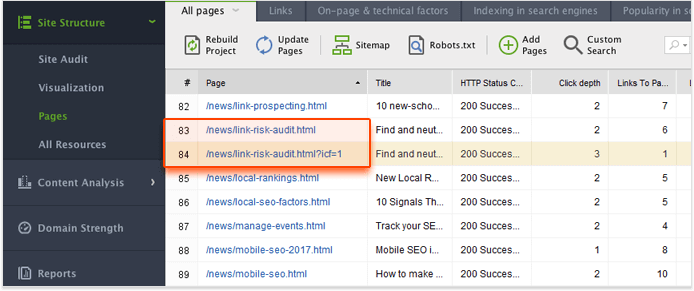
If you do find such issues on your site, make sure to use the Parameter Handling Tool in Google Search Console. This way, you will be telling Google which of the parameters need to be ignored during crawls.
6. Similar content
When people talk about content duplication, they often imply completely identical content. However, pieces of very similar content also fall under Google's definition of duplicate content:
"If you have many pages that are similar, consider expanding each page or consolidating the pages into one. For instance, if you have a travel site with separate pages for two cities, but the same information on both pages, you could either merge the pages into one page about both cities or you could expand each page to contain unique content about each city."
Such issues can frequently occur with e-commerce sites, with product descriptions for similar products that only differ in a few specs. To tackle this and avoid trouble with search engine rankings, try to make your product pages diverse in all areas apart from the description: user reviews are a great way to achieve this. On blogs, similar content issues may arise when you take an older piece of content, add some updates, and rework it into a new post. In this scenario, using a canonical link (or a 301 redirect) on the older article is the best solution.
7. Printer-friendly pages
If your multiple pages on your site have printer-friendly versions accessible via separate URLs, it will be easy for Google to find and crawl those through internal links. Obviously, the content on the page itself and its printer-friendly version is going to be identical — thus wasting your crawl budget once again.
If you do offer printer-friendly pages to your site's visitors, it's best to close them from search engine bots via a noindex tag. If they are all stored in a single directory, such as https://www.link-assistant.com/news/print, you can also add a disallow rule for the entire directory in your robots.txt.
Final thoughts
Specific duplicate content SEO can be a pain those who work with SEO, as it dilutes your pages' link juice (aka ranking power) and drains crawl budget, preventing new pages from getting crawled and indexed. Remember that your best tools to combat the problem are canonical tags, 301 redirects, and robots.txt, and incorporate duplicate content checks into your site auditing routine to improve indexation and rankings.
What are the instances of duplicate content you've seen on your own site, and which techniques do you use to prevent duplication? I'm looking forward to your thoughts and questions in the comments below.

Head of SEO at SEO PowerSuite
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

