How to Handle JavaScript Rendering


With JavaScript's seemingly infinite possibilities, ordinary websites based only on HTML and CSS are becoming a thing of the past. But while JavaScript allows for a dynamic experience for users, it's also creating a minefield for developers. Because of this, JavaScript SEO has become something impossible to ignore, particularly when it comes to making sure that Googlebot analyzes correct JavaScript rendering.
How Does JS Work?
For those who are unfamiliar with JavaScript, here's a quick introduction.
Alongside HTML and CSS, JavaScript is one of the three core web development technologies. HTML is used to create static pages (meaning the code is displayed in the browser as is, and cannot change based on the user's actions), whereas JavaScript makes a Web page dynamic. A programmer can use JavaScript to change the values and properties of an SEO tag as the user clicks a button or chooses a value from a drop-down box. JavaScript is placed on the page together with the HTML code, and it works in conjunction with the code.
Client-side and server-side rendering
There are two concepts we need to mention when talking about JavaScript. And it is very important to understand the differences between them: server-side rendering and client-side rendering.
Traditionally, as is the case with static HTML pages, the code is rendered on the server (server-side rendering). When visiting a page, Googlebot gets the complete and "ready" content, so it doesn't need to do anything but download the CSS files and show the information in your browser.
JavaScript, on the other hand, is generally run on the client machine (client-side rendering), meaning that Googlebot initially gets a page without any content, and then JavaScript creates the DOM (Document Object Model) that is used to load the rendered content. This happens every time a page is loaded.
Obviously, if Googlebot is unable to execute and render JavaScript properly, it's unable to render the page and the main content you wanted it to see. And this is where most of the problems with JavaScript SEO arise from.
Now let's look at how you can avoid these said problems.
How to check if your website is rendered properly
Getting Googlebot to correctly render your site requires you to focus on properly rendering both the links and content on your website. If you don't render links, Googlebot will have difficulty finding its way around your site. And if you don't properly render the content on your website, Googlebot won't be able to see it.
Here are some options to help you improve your future JavaScript SEO.
1. The 'site:' command
First of all, the site: command will show you how many pages of your website are currently indexed by Google. If many of them aren't in the index yet, it might be a sign of rendering problems with internal links.
Second, you might want to check if your JavaScript-loaded content itself is already indexed by Google.
To do that, you need to find a certain line of text that is not presented in your initial HTML code and is only loaded after JavaScript is executed. After that, search for this line of text in the Google index using the 'site:yourdomain.com' command.
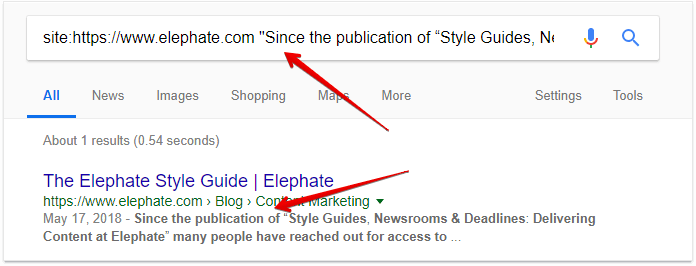
Note that this won't work with the cache: command, since the cached versions of your pages contain only the original, not yet rendered code.
2. The Evergreen GoogleBot
Googlebot is the crawler that visits web pages to include them within Google Search index. The number one question Google got from the community at events and social media was if they could make Googlebot evergreen with the latest Chromium. At the time of writing, GoogleBot runs on the latest version of Chrome, 74.
This is a game changer for SEO, because now you can check how Google actually renders a page instead of guessing and hoping for the best.
3. Chrome DevTools
Some parts of your JavaScript-based website might be programmed to execute upon a certain user's action – a click, a scroll, etc. However, Googlebot is not a user. It's not going to click or scroll down, so it simply won't see the content you're loading upon these actions.
The quickest and easiest way to check if all the JavaScript-based elements are loaded without any user actions is by using Chrome DevTools:
- Open your website in Chrome
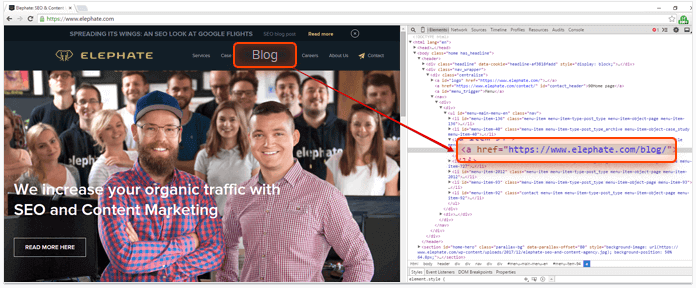
- Open the Elements tab in DevTools
- See how your page was rendered by looking through the actual page's DOM built by the browser – make sure all the crucial navigational and content elements are already present there.
I recommend checking it in Chrome 41. This will provide you with confidence that the element can technically be seen by Googlebot.
You can also, of course, check it in your current Chrome version and make some comparisons.
4. Google Search Console's Fetch and Render
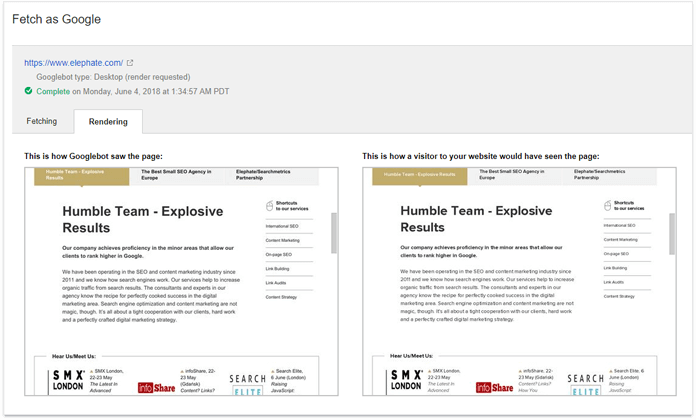
Another useful tool, which can provide us with an idea of how Google renders our website, is the Fetch and Render function in Google Search Console.
First, you have to copy and paste your URL. Then click 'Fetch and Render' and wait a while. This will allow you to see if Googlebot can render your page and see any related articles, copy or links.
Here you can also use Google's Mobile-Friendly Test, which will show you JavaScript errors and the rendered page's code.
5. Server logs analysis
The last thing you can resort to in order to verify how Googlebot crawls your website is the server logs analysis. By taking a hard look at the server logs, you can check if specific URLs were visited by Googlebot and which sections were or were not crawled by Googlebot.
There are many elements you can analyze thanks to your server side logs. For example, you can check if Googlebot visits your older articles — if not, there is probably a problem with the links, which could be caused by problems with JS.
You can also check if Googlebot sees every section of your website — if not, this could also be caused by rendering problems.
Server logs won't show you how Googlebot sees the pages. You can only check if the pages were visited and what response codes were sent. Additional analysis will be needed to determine whether or not any problems were caused by JavaScript.
Furthermore, by looking into the server logs, you can check if Googlebot requested your crucial JavaScript render HTML, or completely ignored it.
Possible problems in rendering your website
Even if your page is rendered correctly by Fetch and Render in the Search Console, this does not mean you can sit back and relax. There are still other problems you need to keep an eye out for.
Let's start with some of the biggest problems that could seriously upset your JavaScript SEO plans…
1. Timeouts
Although exact timeouts are not specified, it's said that Google can't wait for a script longer than 5 seconds. Our experiments at Elephate confirm this rule. If the script loads for more than 5 seconds, Google generally will not index the content it takes to generate.
Fetch and Render will show you if the page can be rendered by Google, but it will not include timeouts. It's important to remember that Fetch and Render is much more forgiving than a standard Googlebot, so you'll need to take the extra step to make sure that the scripts you are serving are able to load under 5 seconds.
2. Browser limitations
As I mentioned earlier, Google uses a somewhat outdated version of its browser to render websites: the three-year-old Chrome 41. And since JavaScript SEO and the technology behind it has evolved and is continuing to evolve very fast, some of its newest features that work in the latest versions of Chrome may not be supported in Chrome 41.
Therefore, the best solution is to download the Chrome 41 browser (at the time of writing, the version that Google uses for web rendering) and familiarize yourself with it. Check the console log to see where any errors occur, and have your developers fix them.
3. Content requiring user interaction to load
I know I said this already, but it really needs repeating: Googlebot does not act like a user. Googlebot does not click on buttons, does not expand "read more", does not enter tabs, does not fill any forms... it only reads and follows.
This means that the entire content you want to be rendered should be loaded immediately to the DOM and not after the action has been performed.
This is particularly important with regard to "read more" content and menus, for example, in a hamburger menu.
What can we do to help Googlebot render websites better?
Googlebot's rendering of websites isn't a one-way street. There are plenty of things developers can do to facilitate the process, helping to both shine a spotlight on the things you want Googlebot to render and provide developers with a good night's dreaming about successful JavaScript SEO.
Avoid 'OnClick' links
Search engines do not treat 'onclick="window.location="' as ordinary links, which means that in most cases they won't follow this type of navigation—and search engines most definitely won't treat them as internal link signals.
It is paramount that the links are in the DOM before the click is made. You can check this by opening the Developers Tools in Chrome 41, and check if the important links have already been loaded — without any extra user actions.
Avoid # in URLs
The # fragment identifier is not supported and ignored by Googlebot. So instead of using the example.com/#url URL structure, try to stick to the clean URL formatting — example.com/url.
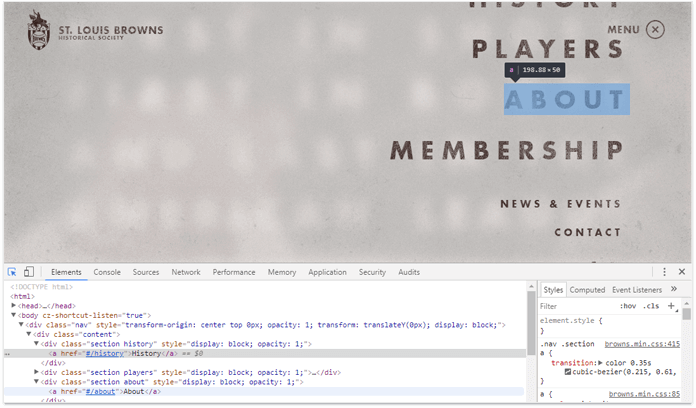
Unique URLs per a unique piece of content
Each piece of your content must be located "somewhere" for a search engine to index it. This is why it's important to remember that if you dynamically change your content without changing a URL, you're preventing search engines from accessing it.
Avoid JS errors
HTML is very forgiving, but JavaScript is definitely not.
If your website contains errors in JS scripts, they will simply not be executed, which may lead to your website content not being displayed at all. One error in the script can cause a domino effect resulting in a lot of additional errors.
To check the code and keep your JavaScript free from errors, you can once again use the Chrome DevTools and review the Console tab to see what errors occurred and in which line of the JavaScript code.
Don't block JS in robots.txt
Blocking JS files is a very old practice, but it still happens quite often. It even sometimes occurs as a default in some CMSs. And while the goal is to optimize the crawl budget, blocking JS files (and CSS style sheets) is considered a very bad practice. Don't take it from me, here's what Google has to say about the topic:
"We recommend making sure Googlebot can access any embedded resource that meaningfully contributes to your site's visible content or its layout..."
So don't even dream about blocking search engine crawlers with something like this:

Otherwise your JavaScript SEO will take a real hit.
Prerender
When you discover that Google has a problem rendering your JavaScript website, you can use prerendering.
Prerendering is providing a ready-made, JavaScript render HTML document of your website. This means that Googlebot does not receive JavaScript render HTML, but pure HTML. At the same time, the user who visits the site gets the same JavaScript-rich version of your page.
The most popular solution is to use external services for prerendering, like Prerender.io, which is compatible with all of the most important JS frameworks.
Essentially you render HTML in a way that includes all potential JavaScript too — you just need to add middleware or a snippet to your web server.
The 21st century way
It's one thing to present you this list of guidelines and tips but something else entirely to demonstrate the process on how they can be implemented. Using a tool from the leaders in the market called WebSite Auditor, we're going to analyze a sample site for common JavaScript errors.
Included in this tool, are recommendations on how to tackle other issues you'll encounter in JavaScript, which will no doubt be useful to those without a lifetime of experience dealing with the language.
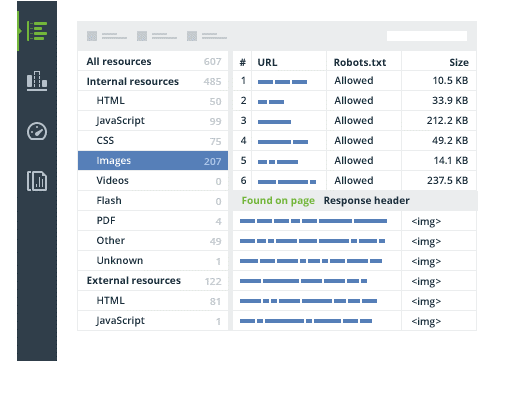
WebSite Auditor can execute JavaScript and crawl dynamically generated content — exactly like modern browsers (and Google) do. That means that if your site is built on AJAX (with a platform like Wix or Squarespace) or uses JavaScript to generate some of its content, WebSite Auditor is able to render, crawl it and fully analyze — taking out all the heavy lifting.
Why not give it a try and download it for free.
Summary
The topic of JavaScript SEO is the most dynamic topic in the SEO world and is definitely worth your attention, especially as it is developing so rapidly. The issues described in this article are only a small part of what you can investigate in order to make sure that Googlebot is correctly rendering your website. If you're interested in getting the bigger picture, check out Onely’s Ultimate Guide to JavaScript SEO.

Bartosz Goralewicz is the co-founder of Elephate, which was recently awarded "Best Small SEO Agency" at the 2018 European Search Awards. Since 2019, he is the founder and CEO of Onely — The Most Advanced Technical SEO Agency on the Planet. Onely believes in paving new ways in the SEO industry through bold, precise SEO campaigns for clients, SEO experiments and case studies. Bartosz leads a highly specialized team of technical SEO experts who work on the deep technical optimization of large, international structures. Website technical audit is not only Bartosz's job, but one of his biggest passions, which is why he enjoys traveling around the world to share this enthusiasm with like-minded SEO folks.

