42104
•
17 minuten gelezen
•


Latent Semantic Indexing is een techniek voor het ophalen van informatie die is uitgevonden lang voordat internet in gebruik werd genomen. Op een gegeven moment, toen Google zijn ranking-algoritmen begon te verbeteren, ontstond er controverse over LSI-zoekwoorden en of deze gunstig zijn voor de SEO van websites.
In dit artikel zal ik dieper ingaan op de oorsprong van latente semantische indexering en het concept van LSI-trefwoorden. En ik zal een aantal LSI-hulpmiddelen voor het genereren van zoekwoorden laten zien die u kunt gebruiken bij copywriting. Genieten!
Latent Semantic Indexing, kortweg LSI, is een wiskundige techniek die relaties tussen woorden in een verzameling documenten vindt. Met behulp van LSI kunnen we een tiental teksten vergelijken en concluderen dat sommige qua onderwerp vergelijkbaar zijn. Het algoritme lokt gelijkenis uit, zelfs als het trefwoord van het hoofdonderwerp in sommige teksten niet rechtstreeks wordt gebruikt.
Met andere woorden,
De behoefte aan latente semantische analyse ontstond in de tijd dat de computercapaciteiten toenamen en programmeurs de toegang van gebruikers tot informatie probeerden te verbeteren. Tekstgerelateerde informatieverwerking vereiste een efficiëntere semantische analyse. De LSI-techniek was bedoeld om verschillende problemen van tekstanalyse aan te pakken, namelijk synoniemen en polysemie.
Wat zijn synoniemen?
Synonymie is een taalkundige term die het bestaan van verschillende woorden voor hetzelfde ding of concept beschrijft. Voor de route die je gaat, heb je bijvoorbeeld een aantal woorden om deze te beschrijven als een route, een weg, een oprit, een passage.
Wat is polysemie?
Polysemie is een taalkundige term voor één woord met meer dan één betekenis. Polysemen hebben verschillende, maar toch verwante betekenissen. Neem het woord rijden: je kunt een voertuig besturen, of je kunt je vriend vanuit een pub naar huis rijden, of je kunt gewoon een hele tijd rijden. Een ander ding is dat je iemand gek kunt maken. Het woord kan een vastberadenheid, een reis, een brede pas voor voertuigen, een computergedeelte, enz. betekenen.
Wat is homonymie?
Een iets ander fenomeen is homonymie wanneer woorden hetzelfde worden gespeld (homografen) of hetzelfde klinken (homofonen), maar verschillende concepten betekenen, die qua oorsprong geen verband houden. Zo moet je als werkwoord zijn of niet zijn, en is er een bij als insect.
Deze taalkundige verschijnselen zijn de drijvende kracht achter alle woordspelingen en humor in kunst en literatuur.

Toch zijn synoniemen en polysemie de belangrijkste redenen waarom exacte trefwoorden niet geschikt zijn voor zoekmachines.
LSI onthult onderliggende semantische structuren die verborgen of verduisterd kunnen worden vanwege de variabiliteit van de bewoordingen. Met deze techniek kunnen overeenkomsten tussen verschillende documenten in een verzameling teksten worden gevonden en de meest relevante ervan worden opgehaald voor het onderzoek van de zoeker.
LSI is een gepatenteerde technologie, gepubliceerd in 1988 (en het patent liep af in 2008).
LSI gebruikt een term-documentmatrix en Singular Value Decomposition (SVD), een veelgebruikte lineaire algebratechniek, om conceptuele correlaties in een geheel van teksten te leren. Tenzij u bekend bent met bewerkingen op matrices en eigenvectoren, zal het enige tijd duren voordat u begrijpt hoe het werkt, maar hier is een korte poging.
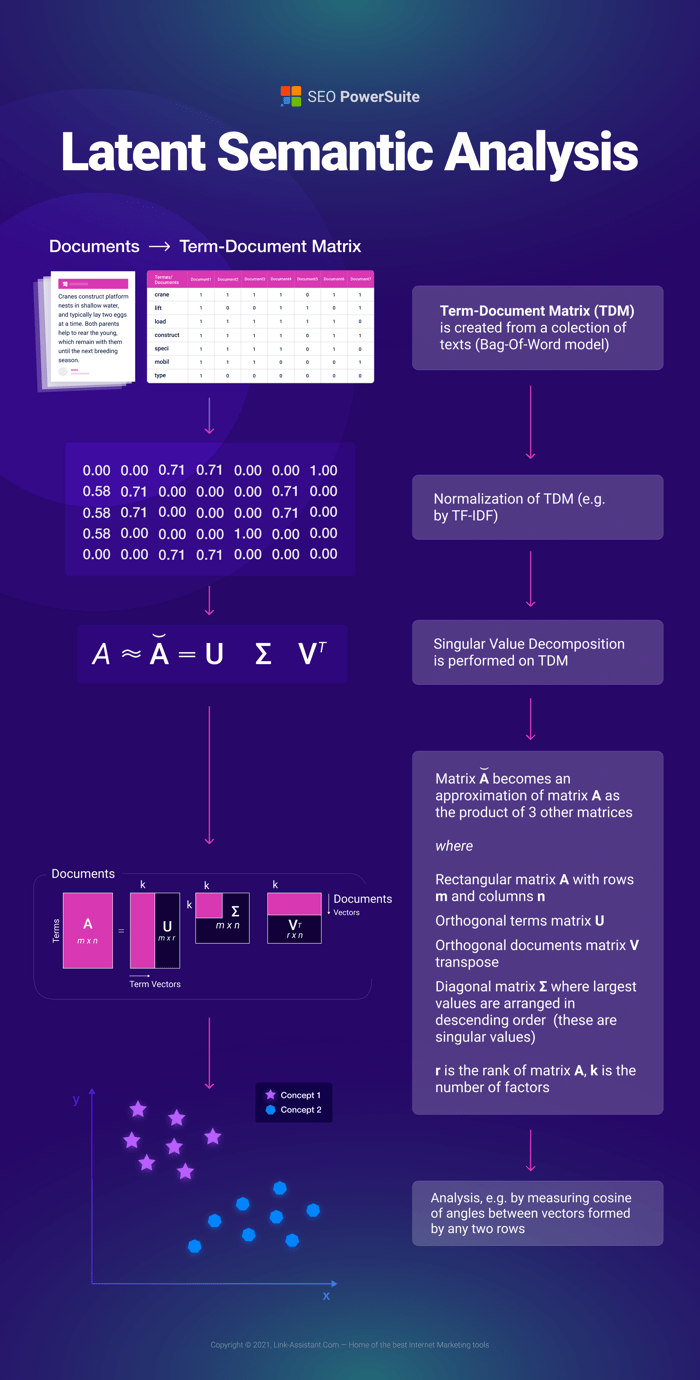
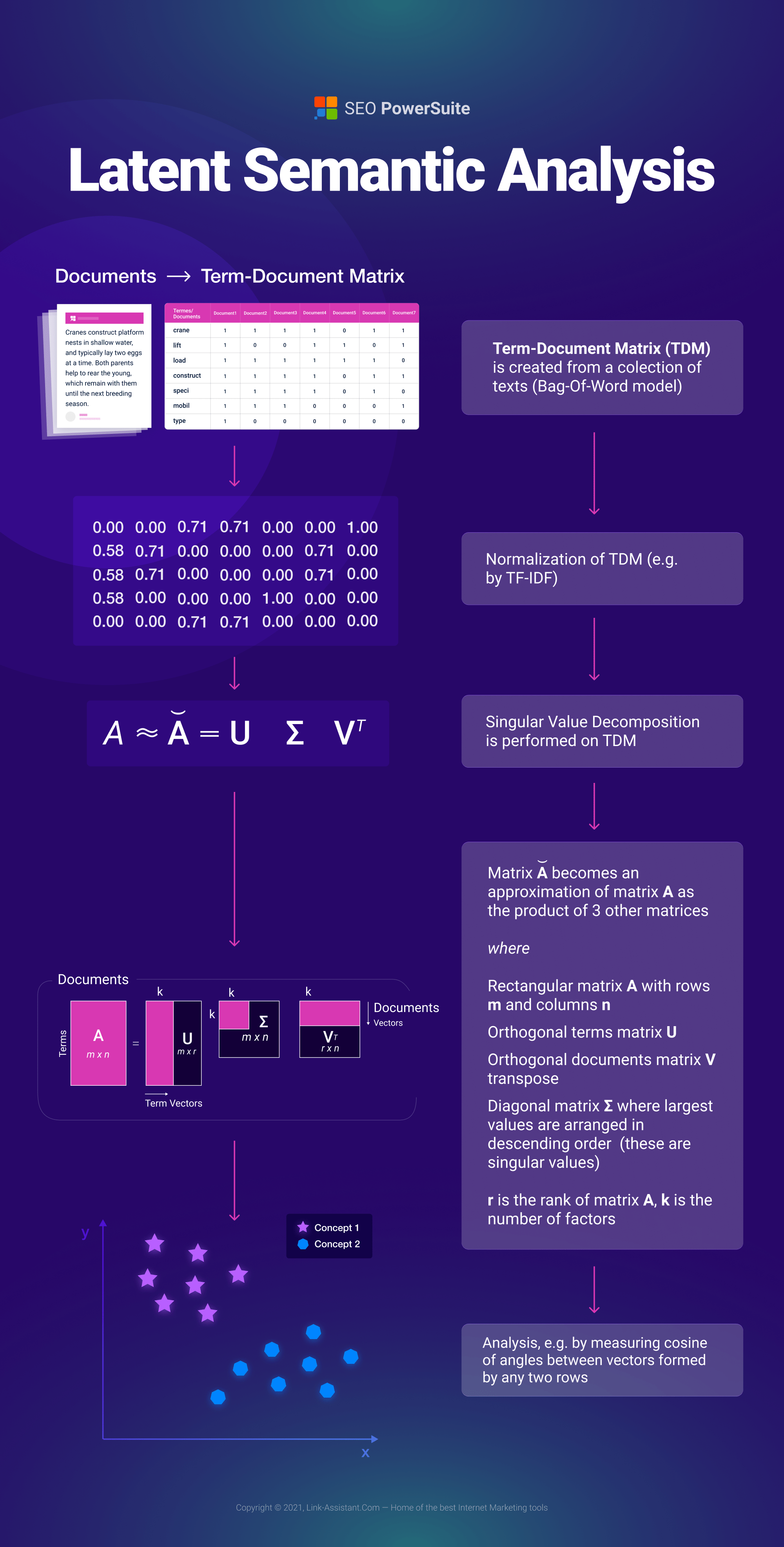
De berekeningen identificeren gelijktijdige gebeurtenissen in de tekstmassa, waardoor concepten worden onthuld die gemeenschappelijk zijn voor verschillende documenten in de verzameling teksten. Het voordeel van LSI is dat het helpt bij het elimineren van ruis en het transformeren van een zeer schaarse TDM-matrix in een benaderde matrix van lage rang die gemeenschappelijke structuren onthult. De tekortkomingen van LSI zijn de complexiteit van de berekeningen.
Dit is een animatie van een LSA-voorbeeld uit de inleiding tot tutorials over onderwerpmodellering.

LSI kan worden gebruikt om termen met termen, documenten met documenten en termen met documenten te vergelijken. In een meer specifiek geval dient het om de aangrenzende termen te vinden (dat zijn de termen die qua gewicht het dichtst bij elkaar liggen), waarbij een cluster van woorden wordt gevonden die nauw verwant zijn aan één concept. Dit kunnen niet alleen synoniemen zijn, maar ook tegenstellingen, of eenvoudigweg woorden die vaak samengaan met het hoofdonderwerp. Dankzij het woord clustering dat LSI doet, is het effectief voor het zoeken en categoriseren van documenten.
LSI-trefwoorden zijn woorden die semantisch gerelateerd zijn aan het hoofdonderwerptrefwoord van de pagina en die in een verscheidenheid aan vergelijkbare teksten kunnen worden gevonden.
Laten we, voor een eenvoudig begrip van wat LSI-trefwoorden zijn, eens kijken naar een willekeurige zoekopdracht, bijvoorbeeld 'klimaatverandering'. Denk eerst aan de associaties die je hebt met het woord zin.
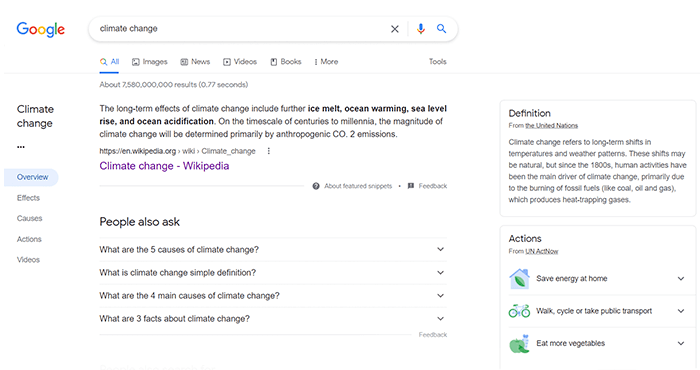
Als u het in de zoekbalk typt, krijgt u een aantal pagina's van verschillende soorten. Google haalt de definitie van de term uit Wikipedia in een aanbevolen fragment, waarbij vetgedrukt de belangrijkste termen worden benadrukt die verband houden met klimaatverandering: 'ijssmelt', 'opwarming van de oceaan', 'stijging van de zeespiegel' en 'verzuring van de oceaan'.
Op de pagina met zoekresultaten vinden we nog een paar relevantere termen, zoals 'opwarming van de aarde', 'uitstoot van broeikasgassen', enz. Dit zijn woorden en zinsdelen die in de meeste teksten naast ons belangrijkste zoekwoord verschijnen.
De lastige vraag over LSI is...
Voor iedereen die zich afvraagt of Google LSI-zoekwoorden gebruikt, is er voor eens en voor altijd één kort antwoord van Google-vertegenwoordiger John Mueller:
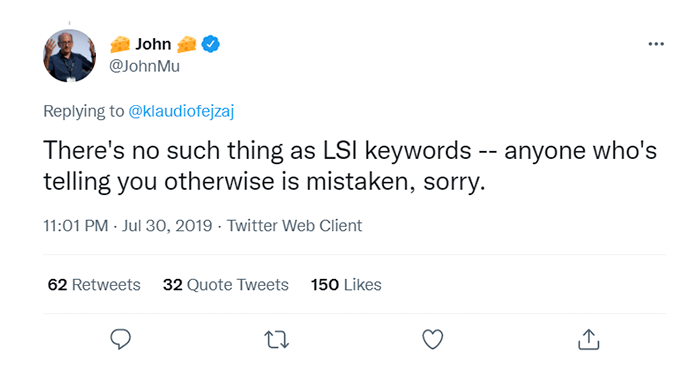
Waarom wordt Google dan geassocieerd met latente semantische analyse? We weten zeker dat de zoekmachine van Google polysemen en synoniemen onderscheidt. Voor populaire zoekopdrachten moeten op zijn minst meerdere resultaten op de SERP ongeveer hetzelfde aspect van het onderwerp bestrijken, aangezien Google met succes het trefwoord identificeert en polysemen onderscheidt (uiteraard wanneer u het specificeert, maar ook op basis van uw zoekgeschiedenis), en zelfs de bedoeling van de zoekopdracht om de meest relevante teksten te tekenen.
Bovendien krijgt Google elke dag 15% van de zoekopdrachten die het nog nooit eerder is tegengekomen. Hoe gaat het met hen om?
De waarheid is dat je nauwelijks een Google-onderzoekspaper over LSI-trefwoorden kunt noemen waaruit blijkt in welk stadium LSI mogelijk in zijn algoritmen is geïmplementeerd. Zeker, tegenwoordig gebruikt Google geavanceerdere algoritmen voor natuurlijke taalverwerking om het steeds groter wordende internet te scannen. Bill Slawski maakt hier duidelijk waarom Google nauwelijks LSI gebruikt voor zoeken, en haalt patenten uit 2017 aan, waarbij hij als voorbeeld geeft dat een nieuwer Google-algoritme RankBrain gebaseerd is op een woordvectorbenadering.
Vanaf de nieuwste algoritmische updates gebruikt Google BERT om de relevantie van zoekresultaten voor zoekopdrachten van gebruikers te verbeteren. Het neurale netwerk voor natuurlijke taalverwerking wordt gebruikt voor het rangschikken van passages of om de diepe semantiek in video's te begrijpen, wat veel ingewikkelder lijkt te zijn dan LSI.
Gerelateerd lezen Google's MUM: zoekupdates en SEO-implicaties
LSI is uitgevonden tijdens de opkomst van internet. Voor het web dat zo groot is als het nu is, is LSI niet praktisch, laat staan voldoende.
Eén ding om in gedachten te houden is dat LSI slechts een van de vele technieken van semantische analyse is, naast Probabilistische Latente Semantische Analyse, Principal Component Analysis, Latent Dirichlet Allocation, Word2Vec, enz.
Hoewel de LSI-techniek wordt afgedaan als te oud en eenvoudig voor de hedendaagse zoekbehoeften, wordt de term 'LSI-trefwoorden' door contentmarketeers gebruikt om de reikwijdte van het optimalisatiewerk dat op een pagina wordt uitgevoerd te beschrijven. Wat is de waarde van LSI-zoekwoorden voor SEO?
Het belangrijkste voordeel van LSI-zoekwoorden is dat u ze kunt gebruiken om de SEO op de pagina te verbeteren. LSI-tools zijn niet bedoeld om de algoritmen van Google aan te passen. Ze richten zich op tekstanalyse om woorden en zinsneden te vinden die van nature naast elkaar voorkomen, op basis van teksten die al beschikbaar zijn op de SERP.
Met LSI kunt u de context verrijken met semantisch gerelateerde trefwoorden. Het gebruik van LSI-trefwoorden zou u moeten helpen de natuurlijke context voor de vraag te creëren en het onderwerp diepgaander te behandelen. Je kunt het beschouwen als een soort hulpmiddel bij het schrijven van inhoud.
De term 'LSI copywriting' wordt in contentmarketing gebruikt om het proces aan te duiden waarbij gerelateerde termen aan uw content worden toegevoegd. Grof gezegd neigt SEO-copywriting af te wijken van verouderde en onnatuurlijke technieken voor het vullen van zoekwoorden. Het richt zich eerder op het creëren van gebruiksvriendelijke content: copywriters moeten teksten op een natuurlijke manier schrijven en toegevoegde waarde bieden aan gebruikers (hetzelfde waar zoekmachines naar streven).
Als we het dus hebben over LSI-zoekwoorden, bedoelen we het vinden van relevante gerelateerde zoekwoorden die kunnen worden toegevoegd om de inhoud te verbeteren. In dat geval spreken we van een marketingconcept dat door contentmakers wordt gebruikt.
Denk eerst na. Als u een expert bent, heeft u voldoende ideeën om in uw artikel te ontwikkelen. Wat als je geen ideeën meer hebt? Gebruik zoekwoordhulpmiddelen.
De eerste methode die in je opkomt als je op zoek bent naar LSI-zoekwoorden, is het gebruik van Google-zoekwoordsuggesties. Als we het echter hebben over de reguliere hulpprogramma's voor zoekwoorden van Google, kunnen we deze niet gebruiken als LSI-zoekwoordgeneratoren, aangezien de algoritmen van Google niet over latente semantische indexering gaan.
Hoewel automatisch aanvullen van Google ongetwijfeld de beste bron is voor het ontdekken van zoekwoorden, is dit niet altijd wat we bedoelen met LSI-zoekwoorden. Let bovendien op het verschil tussen long-tail-zoekwoorden en semantische LSI-zoekwoorden. Long-tail-zoekwoorden bevatten al uw hoofdzoekwoord, ze passen hoogstwaarschijnlijk in uw inhoud en u wilt ze waarschijnlijk bijhouden als uw doelzoekwoorden. Terwijl LSI-zoekwoorden mogelijk helemaal niet uw doelzoekwoord bevatten.
Beneden in de SERP ziet u altijd het universele zoekresultaat dat bekend staat als het vak Mensen vragen ook. Het is waarschijnlijker dat deze plaats u een aantal geweldige semantisch gerelateerde onderwerpen biedt.
Terwijl u de doos uitpakt, ziet u nog meer vragen en antwoorden. Hoe meer vragen je ziet, hoe meer vragen Google voorstelt. De voorgestelde onderwerpen zullen echter steeds verder van uw kernthema verwijderd raken.
De aanwijzingen in het PPA-vak zijn een grote keuze aan LSI-trefwoorden die kunnen worden geoptimaliseerd voor mobiel gesproken zoeken en FAQ-boxen.
Hier is nog een gratis hulpprogramma voor het genereren van zoekwoorden van Google. Ga op de pagina met zoekresultaten naar de resultaten van Gerelateerde zoekopdrachten, de onderwerpen die het meest voorkomen naast uw belangrijkste zoekterm. Bij vergelijkbare zoekopdrachten vindt u een aantal goede subonderwerpen die u aan uw hoofdinhoud kunt toevoegen en uw artikel diepgaander kunt maken. Synoniemen en gerelateerde termen zijn een leuke manier om uw inhoud te verrijken.
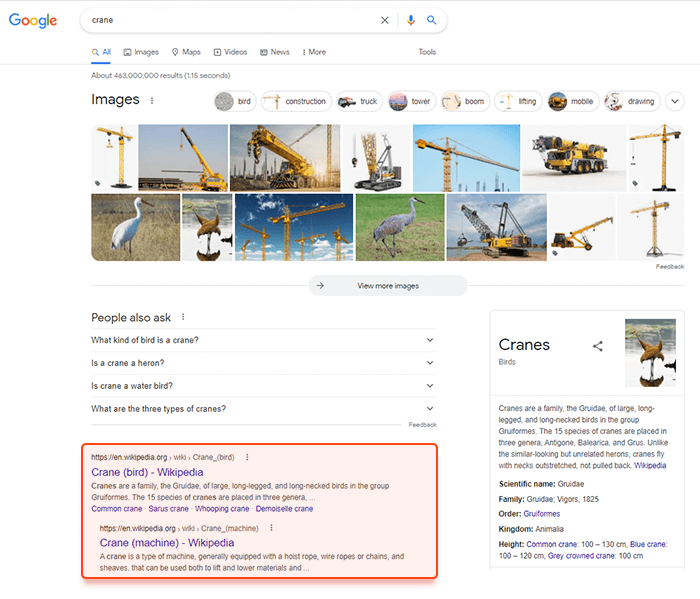
Google Afbeeldingen is een andere eenvoudige methode om trefwoorden te vinden met behulp van labels. De tool stelt de meest populaire korte zoekwoorden voor, die door semantiek nauw verbonden zijn met het doelzoekwoord en in overvloed worden weergegeven in de afbeeldingsresultaten.
Gerelateerd lezen: 20+ gratis tools voor zoekwoordonderzoek
Een eenvoudige LSI-sleutelwoordgenerator voor academisch onderzoek is XLSTAT, een add-on voor Excel. XLSTAT biedt een gratis proefperiode van twee weken om het uit te proberen en een demospreadsheet, waarin wordt getoond hoe u LSI kunt toepassen op uw documenttermenmatrix.
Eerst moet u uw DTM maken met binaire waarden voor woordvoorvallen in uw teksten. Ga vervolgens, met XSTAT geactiveerd in Excel, naar Geavanceerde functies (door op de knop + te drukken) en selecteer Tekstmining > Latente semantische analyse. Ga verder met het instellen van de gewenste instellingen voor uw gegevens en klik op OK om deze toe te passen.
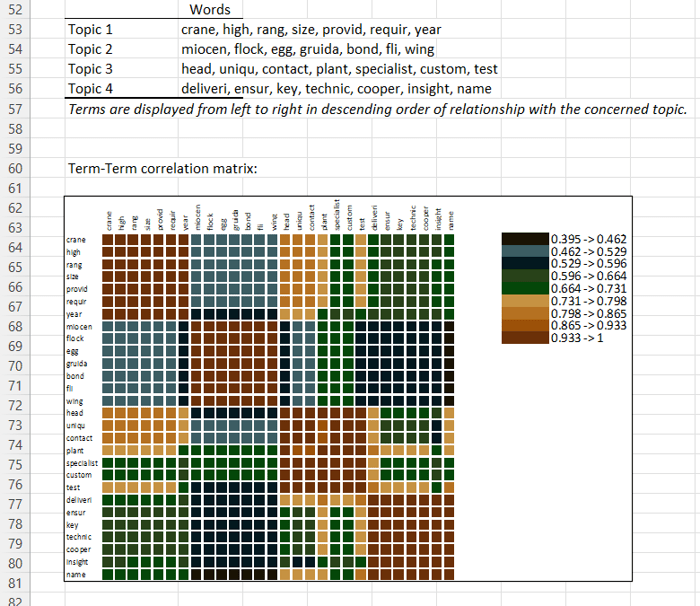

De tool geeft u de lijst met onderwerpen die de LSI-tool uit uw gegevens haalt. Om de kwaliteit van de resultaten snel te kunnen interpreteren, genereert de tool een scree plot, waarbij het belang van de onderwerpen wordt gemeten via eigenwaarden en het cumulatieve variabiliteitspercentage. Er zijn ook visualisaties van relaties tussen termen en tussen documenten.
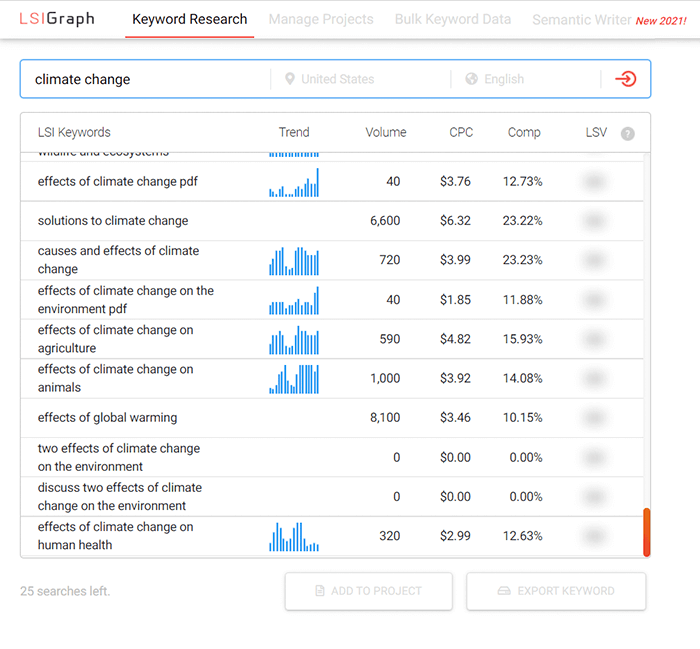
LSI Graph is een mooie semantische zoekwoordentool die voor zichzelf spreekt. Hiermee kunt u gratis 10 zoekopdrachten per dag uitvoeren. Ga gewoon naar de website, plak uw startzoekwoord en u krijgt een lijst met LSI-zoekwoorden, vergezeld van SEO-statistieken die u helpen de meest veelbelovende zoekwoordzinnen te kiezen. De resultaten zullen een heleboel ideeën opleveren om uw inhoud te verrijken met meer onderwerpen of functies.
In LSI Graph kunt u het zoekvolume voor het trefwoord, de kosten per klik en trends over een bepaalde periode bekijken. LSIGraph voert een zoekopdracht op LSI-trefwoorden uit met behulp van zijn eigen gepatenteerde meting, bekend als Latent Semantic Value (LSV). In de rechterwerkruimte ziet u de best presterende inhoud met actieve links waarmee u ze snel kunt bekijken.
LSI Graph biedt ook premiumfuncties, waaronder bulkzoekwoordbeheer en de Semantic Writer-tool. Met de tool kunt u de inhoud in de app optimaliseren, LSI-trefwoorden genereren en deze naast uw inhoud bekijken, het aantal woorden, de trefwoorddichtheid meten, enz. In feite biedt de Semantic Writer een helpende hand aan SEO-copywriters, met een speciale focus op onderzoek LSI-trefwoorden.
Keysearch is een ander gratis hulpmiddel om LSI-trefwoorden voor uw inhoud te ontdekken. Het algoritme voor het vinden van zoekwoorden achter de tool doorzoekt de eerste pagina met zoekresultaten van Google voor uw hoofdzoekwoord en analyseert alle pagina's op de rankingpagina's om de woorden en zinsdelen te vinden die daarin het vaakst worden gebruikt.
Nogmaals, u krijgt al uw trefwoordonderzoeksstatistieken, zoals zoektrends, CPC-kosten en zelfs de kracht van de domeinen die op de SERP staan voor het trefwoord, samen met hun links, organisch verkeer en populariteit op sociale media.
Keysearch biedt een Content Assistant-tool die gebruikmaakt van het algoritme voor diepgaande analyse. Het voegt een nieuw niveau toe aan het vinden van LSI-trefwoorden. De tool bevat gerelateerde zoekopdrachten van Google plus de hoogst gerangschikte zoekwoorden voor het eerste resultaat in Google. Op deze manier vindt u de meest winstgevende sleutelwoorden van de beste pagina die het meeste organische verkeer naar de website trekt.
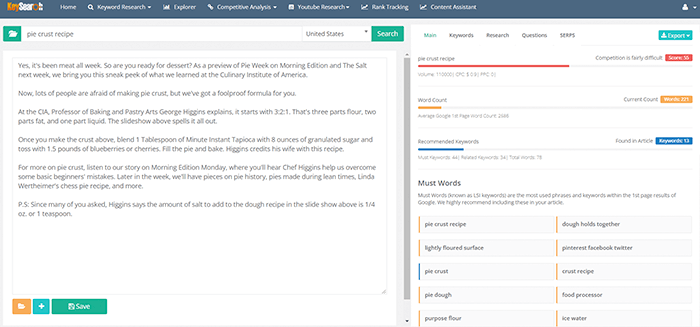
Keysearch combineert dus de kenmerken van een trefwoordtool voor onderzoek met een tool voor het schrijven van inhoud die helpt bij het creëren van inhoud op basis van SERP-analyse. Dit is een eenvoudige en gemakkelijke manier om LSI-zoekwoorden te genereren die u aan uw inhoud kunt toevoegen en die worden opgehaald door automatische analyse van topresultaten, gerelateerde zoekopdrachten van Google en vragenvakken.
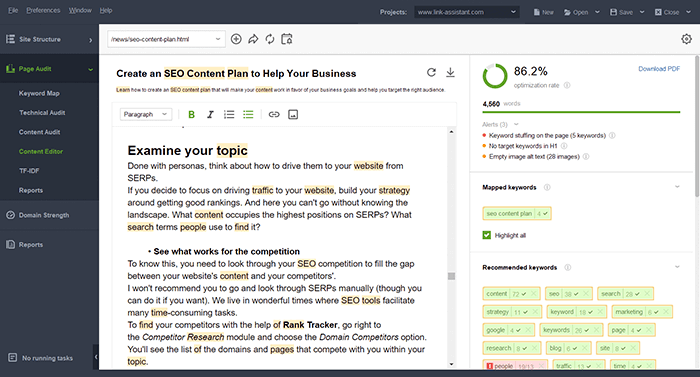
Content Editor maakt deel uit van WebSite Auditor, een tool van SEO PowerSuite-software die de functies van een sitecrawler en een app voor inhoudoptimalisatie in één combineert. Voor het maken van inhoud heeft WebSite Auditor een aparte module om individuele pagina's te controleren, en de slimme schrijfassistent om pagina's in-app te optimaliseren.
Om LSI-trefwoorden te vinden, start u de WebSite Auditor en gaat u naar de module Pagina-audit > Content Editor. Druk op de knop + om de URL toe te voegen van de pagina die u gaat optimaliseren (de bestaande of nieuwe pagina) en ga vervolgens verder met het toevoegen van uw doelzoekwoord voor de pagina.
De Content Editor-tool analyseert de SERP voor pagina's met de hoogste ranking en biedt optimalisatietips op de pagina.
In het hoofdvenster heeft u de bewerkingsruimte waar u uw inhoud kunt maken en de optimalisatiescore rechts in de app kunt zien verbeteren.
Als alternatief is er voor makers van inhoud een optie om aanbevelingen naar een PDF-bestand te exporteren en deze over te dragen voor gebruik in een ander schrijfhulpmiddel.
Het veld voor het aantal trefwoorden kan worden bewerkt. U kunt de bestaande zoekwoordfrequentie op de pagina bekijken en zien hoe u deze kunt verbeteren door meer of minder zoekwoorden te gebruiken. U kunt dit veld handmatig bewerken (en u kunt ook handmatig meer van uw LSI-trefwoorden toevoegen).
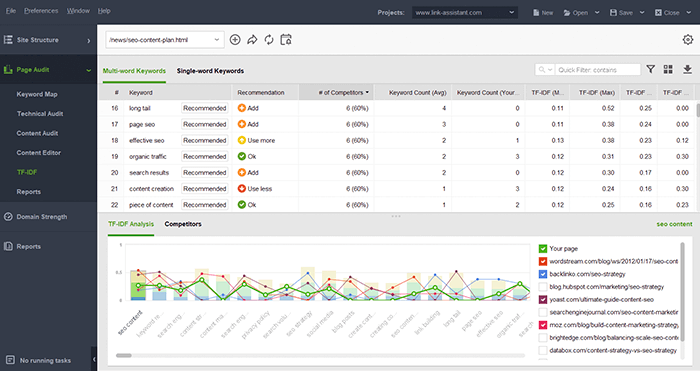
Er is een speciale TF-IDF-tool in WebSite Auditor die staat voor 'Term Frequency - Inverse Document Frequency'. TF-IDF meet het belang van een trefwoordzin door deze te vergelijken met de frequentie van de term in een groot aantal documenten. In principe volgt deze inhoudsanalysetechniek dezelfde stappen als LSI voordat SVD wordt toegepast. Terwijl LSI uitzoekt welke onderwerpen gemeenschappelijk zijn voor welke documenten in een verzameling teksten, weegt TF-IDF eenvoudigweg de termen daarin af.

Het mooie van de TF-IDF-tool in Content Editor is dat het het woordgebruik in duidelijk gevisualiseerde grafieken weergeeft. Het toont het gemiddelde aantal zoekwoorden op de pagina's van concurrenten en berekent het aantal zoekwoorden dat u op uw pagina moet gebruiken. De tool voor snelle suggesties raadt aan een nieuw zoekwoord toe te voegen of minder zoekwoorden te gebruiken om overmatig gebruik van zoekwoorden te voorkomen.
De Content Editor biedt het aanbevolen aantal trefwoorden die u in uw inhoud kunt gebruiken, afkomstig uit de inhoud van uw beste concurrenten en gefilterd op de TF-IDF-parameter. U kunt de lijst met concurrenten uitpakken en de URL's bekijken, samen met het verkeer dat de pagina heeft gegenereerd via de organische zoekopdracht naar het doelzoekwoord. U kunt een voorbeeld van de tekstversie van de pagina rechtstreeks in de tool bekijken of naar de site gaan via een snelle link vanuit de tool.
Nadat de inhoudsanalyse is voltooid, stelt de tool onderwerpen en vragen voor waar u in uw inhoud bij stil moet staan, rechtstreeks uit de SERP van Google (sectie 'Mensen vragen ook' ). Dit helpt je om meer onderwerpideeën te bedenken en je hoofdthema dieper te behandelen.
Naarmate u nieuwe inhoud blijft toevoegen, verandert het gewicht van elk zoekwoord ten opzichte van het totale aantal woorden. Een speciale Word-cloudwidget illustreert het gewicht van uw zoekwoorden in de inhoud.
Kan het vermelden van verwante woorden en zinnen de ranking verbeteren? Niet precies, het effect is niet gegarandeerd. Je voegt relevante trefwoorden toe aan je inhoud en breidt het onderwerp uit, je gaat er dieper op in. Ondertussen krijgt u meer zoekwoorden op uw pagina en worden uw doelzoekwoorden ondersteund door verbeterde context. Zoekalgoritmen kunnen enkele aanvullende zoekopdrachten onthullen waarvoor uw pagina's zijn bedoeld. Dit leidt tot meer relevant organisch verkeer naar uw site en draagt bij aan uw algehele online zichtbaarheid. Maar welke aanvullende zoekwoorden zijn het beste voor on-page optimalisatie?
Of zoekmachines LSI tegenwoordig wel of niet gebruiken, het concept van LSI-trefwoorden wordt door SEO's gebruikt om te helpen bij het creëren van inhoud. Als u de rol van LSI-zoekwoorden begrijpt, kunt u ze effectief onderdeel maken van uw zoekwoordstrategie. Houd er rekening mee dat de algoritmen van Google honderden rangschikkingsfactoren gebruiken waarbij de inhoud de koning is.
Welke tool of techniek u ook voor het zoeken naar zoekwoorden toepast, u hoeft zich alleen maar te concentreren op het maken van inhoud van hoge kwaliteit. Twijfel niet aan de waarde van longreads, want geweldige inhoud krijgt een stem van gebruikers en zoekmachines zien het.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |