123148
•
20 minuten gelezen
•


Deze checklist beschrijft alle facetten van een technische site-audit, van theorie tot praktijk.
U leert welke technische bestanden er zijn, waarom SEO-problemen optreden en hoe u deze in de toekomst kunt oplossen en voorkomen, zodat u altijd beschermd bent tegen plotselinge dalingen in de ranking .
Onderweg zal ik enkele SEO-audittools laten zien, zowel populair als weinig bekend, om probleemloos een technische website-audit uit te voeren.
Het aantal stappen in uw technische SEO-checklist hangt af van de doelen en het type sites dat u gaat onderzoeken. We hebben ernaar gestreefd deze checklist universeel te maken en alle belangrijke stappen van technische SEO-audits te dekken.
1. Krijg toegang tot site-analyse en webmastertools
Om een technische audit van uw site uit te voeren, heeft u analyse- en webmastertools nodig, en het is geweldig als u deze al op uw website heeft geconfigureerd. Met Google Analytics , Google Search Console , Bing Webmaster Tools en dergelijke heb je al een grote hoeveelheid gegevens die nodig zijn voor een basiscontrole van de site .
2. Controleer de domeinveiligheid
Als u een bestaande website controleert die van de ranglijst is gedaald, moet u in de eerste plaats de mogelijkheid uitsluiten dat het domein onderhevig is aan sancties door zoekmachines.
Raadpleeg hiervoor Google Search Console. Als uw site is bestraft voor het bouwen van black-hat-links of als deze is gehackt, ziet u een overeenkomstige melding op het tabblad Beveiliging en handmatige acties van de console. Zorg ervoor dat u de waarschuwing op dit tabblad oplost voordat u verder gaat met een technische audit van uw site. Als je hulp nodig hebt, bekijk dan onze gids over hoe om te gaan met handmatige en algo-sancties .
Als u een geheel nieuwe site controleert die op het punt staat gelanceerd te worden, zorg er dan voor dat u controleert of uw domein niet is aangetast. Raadpleeg voor meer informatie onze handleidingen over het kiezen van verlopen domeinen en hoe u niet vast komt te zitten in de Google-sandbox tijdens het lanceren van een website.
Nu we klaar zijn met voorbereidend werk, gaan we stap voor stap verder met de technische SEO-audit van uw website.
Over het algemeen zijn er twee soorten indexeringsproblemen. Een daarvan is wanneer een URL niet is geïndexeerd, ook al zou dat wel moeten. De andere is wanneer een URL wordt geïndexeerd, hoewel dit niet de bedoeling is. Dus hoe controleer je het aantal geïndexeerde URL's van je site?
Als u wilt zien hoeveel van uw website daadwerkelijk in de zoekindex is terechtgekomen, raadpleegt u het dekkingsrapport in Google Search Console . Het rapport laat zien hoeveel van uw pagina's momenteel zijn geïndexeerd, hoeveel zijn uitgesloten en wat enkele van de indexeringsproblemen op uw website zijn.
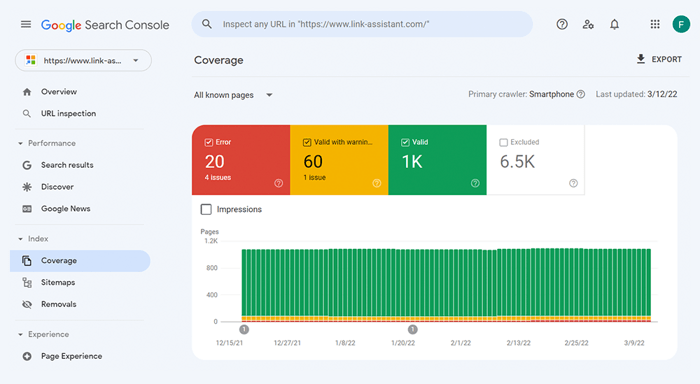

Het eerste type indexeringsproblemen wordt meestal gemarkeerd als een fout. Indexeringsfouten treden op wanneer u Google heeft gevraagd een pagina te indexeren, maar deze wordt geblokkeerd. Er is bijvoorbeeld een pagina toegevoegd aan een sitemap, maar deze is gemarkeerd met de noindex- tag of is geblokkeerd met robots.txt.
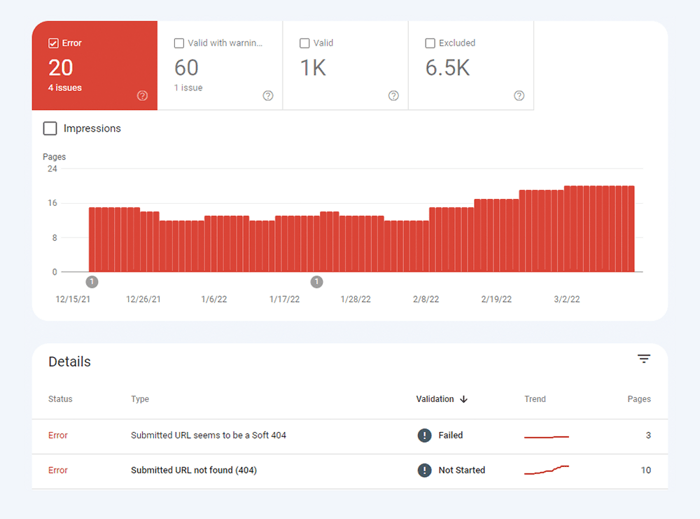
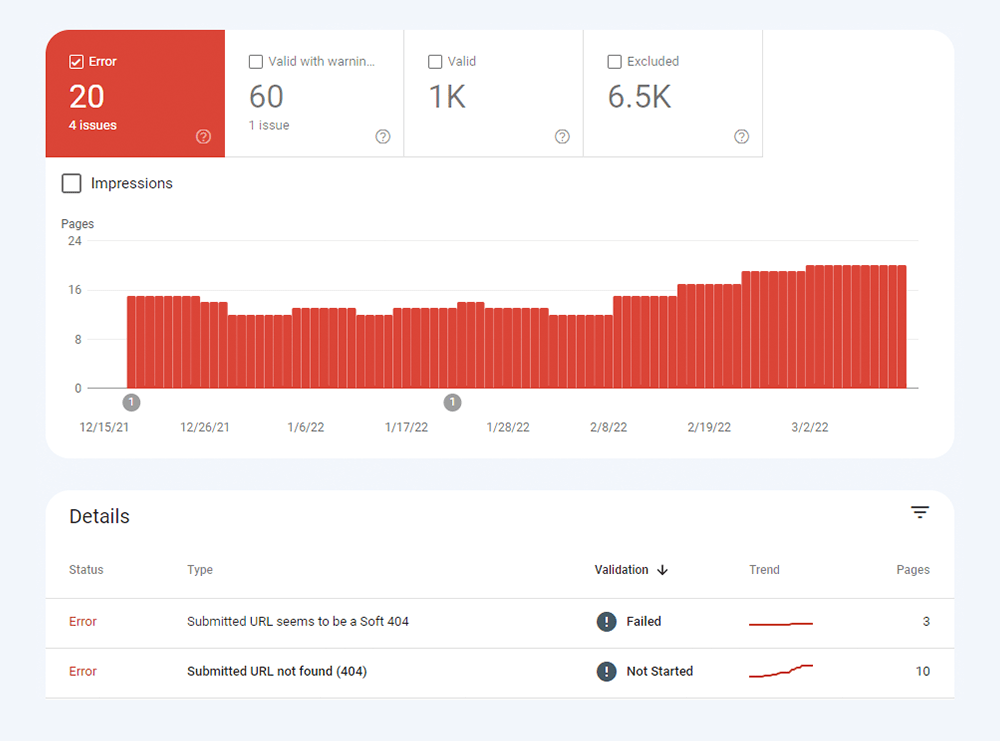
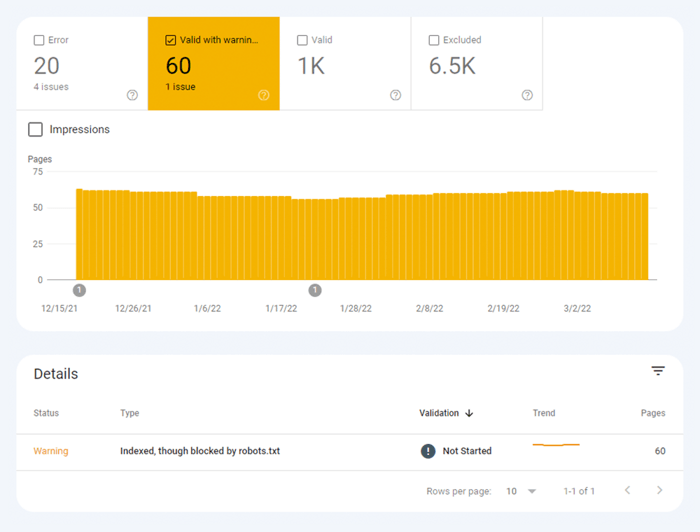
Het andere type indexeringsproblemen is wanneer de pagina is geïndexeerd, maar Google niet zeker weet of deze geïndexeerd had moeten worden. In Google Search Console worden deze pagina's meestal gemarkeerd als Geldig met waarschuwingen .

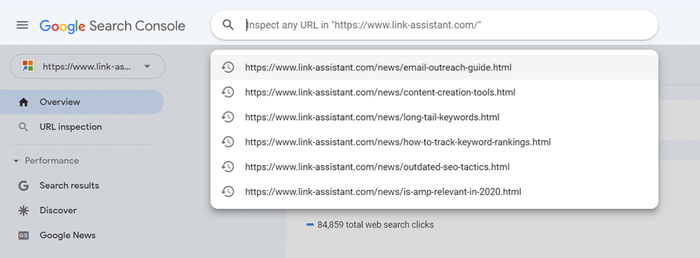
Voer voor een afzonderlijke pagina de URL-inspectietool in Search Console uit om te controleren hoe de zoekbot van Google deze ziet. Klik op het betreffende tabblad of plak de volledige URL in de zoekbalk bovenaan, en het zal alle informatie over de URL ophalen, zoals deze de laatste keer door de zoekbot is gescand.
Vervolgens kunt u op Test Live URL klikken en nog meer details over de pagina bekijken: de responscode, HTML-tags, de schermafbeelding van het eerste scherm, enz.
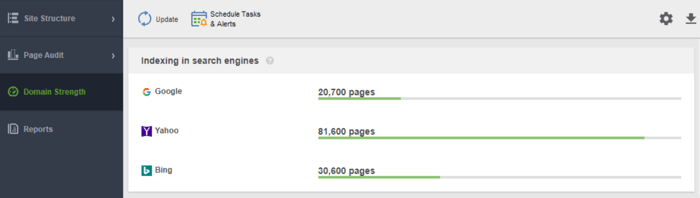
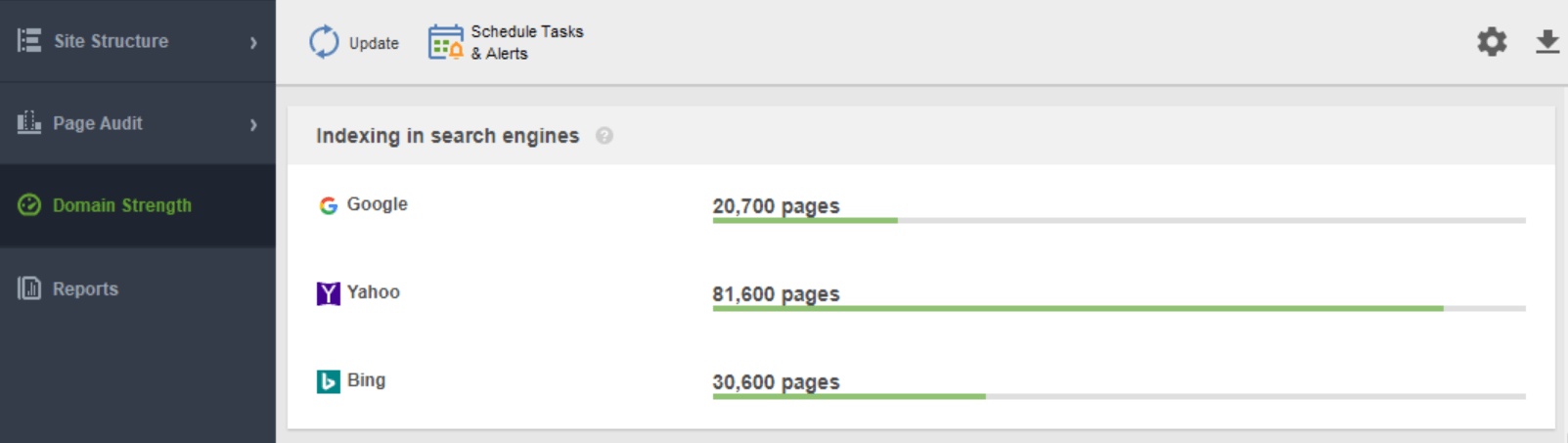
Een ander hulpmiddel om uw indexering te controleren is WebSite Auditor . Start de software en plak de URL van uw website om een nieuw project te maken en door te gaan met het controleren van uw site. Zodra de crawl voorbij is, ziet u alle problemen en waarschuwingen in de module Sitestructuur van WebSite Auditor. Bekijk in het rapport Domain Strength het aantal pagina's dat is geïndexeerd, niet alleen in Google, maar ook in andere zoekmachines.
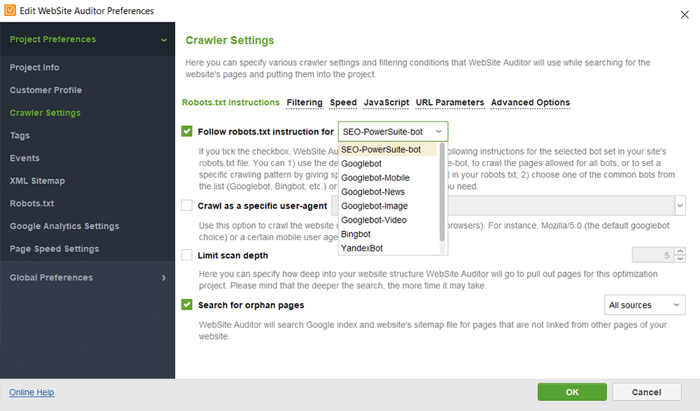
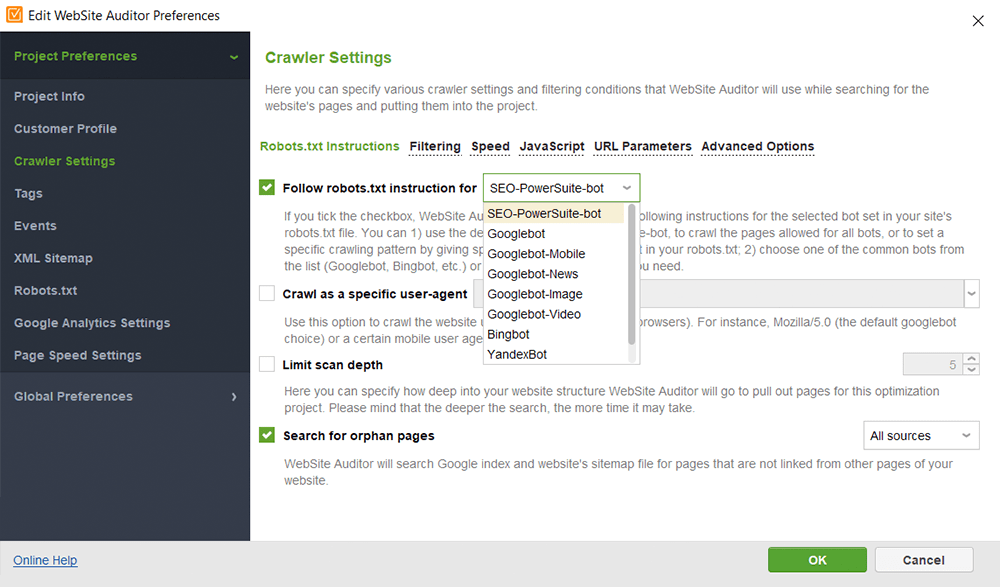
In WebSite Auditor kunt u uw sitescan aanpassen door een andere zoekbot te kiezen en de crawlinstellingen op te geven. Definieer in de projectvoorkeuren van de SEO-spin de bot van de zoekmachine en een specifieke user-agent. Kies welke soorten bronnen u tijdens het crawlen wilt onderzoeken (of sla het scannen juist over). U kunt de crawler ook opdracht geven om subdomeinen en met een wachtwoord beveiligde sites te controleren, speciale URL-parameters te negeren en meer.
Bekijk deze gedetailleerde video-walkthrough om te leren hoe u uw project opzet en websites analyseert.
Telkens wanneer een gebruiker of een zoekbot een verzoek naar de server stuurt die de websitegegevens bevat, registreert het logbestand hierover een vermelding. Dit is de meest correcte en geldige informatie over crawlers en bezoekers op uw site, indexeringsfouten, verspilling van crawlbudgetten, tijdelijke omleidingen en meer. Aangezien het moeilijk kan zijn om logbestanden handmatig te analyseren, hebt u een programma voor het analyseren van logbestanden nodig.
Welke tool u ook besluit te gebruiken, het aantal geïndexeerde pagina's moet dicht bij het werkelijke aantal pagina's op uw website liggen.
En laten we nu verder gaan met hoe u het crawlen en indexeren van uw website kunt regelen.
Als u geen technische SEO-bestanden met crawl-besturingselementen heeft, zullen zoekbots standaard nog steeds uw site bezoeken en deze crawlen zoals deze is. Met technische bestanden kunt u echter bepalen hoe bots van zoekmachines uw pagina's crawlen en indexeren, dus ze worden ten zeerste aanbevolen als uw site groot is. Hieronder vindt u enkele manieren om regels voor indexering/crawlen te wijzigen:
Dus, hoe kunt u ervoor zorgen dat Google uw site sneller indexeert door ze allemaal te gebruiken?
Een sitemap is een technisch SEO-bestand dat alle pagina's, video's en andere bronnen op uw site weergeeft, evenals de onderlinge relaties. Het bestand vertelt zoekmachines hoe ze uw site efficiënter kunnen crawlen en speelt een cruciale rol in de toegankelijkheid van uw website.
Een website heeft een sitemap nodig wanneer:
Er zijn verschillende soorten sitemaps die u aan uw site wilt toevoegen, grotendeels afhankelijk van het type website dat u beheert.
Een HTML-sitemap is bedoeld voor menselijke lezers en bevindt zich onderaan de website. Het heeft echter weinig SEO-waarde. Een HTML-sitemap toont de primaire navigatie voor mensen en repliceert meestal de links in sitekoppen. Ondertussen kunnen HTML-sitemaps worden gebruikt om de toegankelijkheid te verbeteren voor pagina's die niet in het hoofdmenu zijn opgenomen.
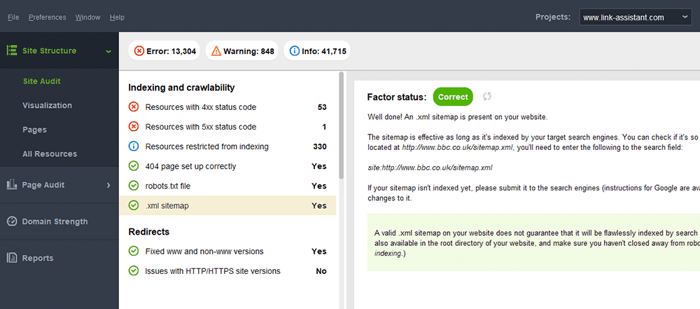
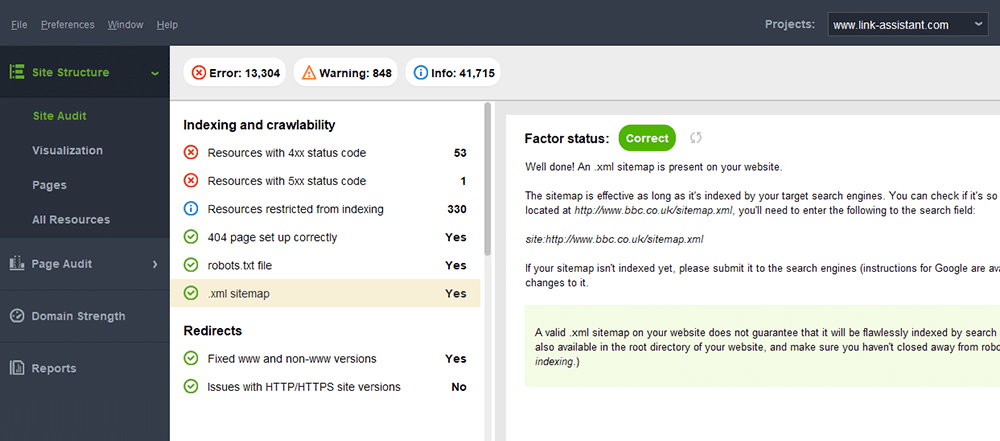
In tegenstelling tot HTML-sitemaps zijn XML-sitemaps machineleesbaar dankzij een speciale syntaxis. De XML-sitemap bevindt zich in het hoofddomein, bijvoorbeeld https://www.link-assistant.com/sitemap.xml. Verderop bespreken we de vereisten en opmaaktags voor het maken van een correcte XML-sitemap.
Dit is een alternatief soort sitemap dat beschikbaar is voor bots van zoekmachines. De TXT-sitemap geeft eenvoudig alle website-URL's weer, zonder enige andere informatie over de inhoud te verstrekken.
Dit type sitemaps is handig voor grote afbeeldingenbibliotheken en grote afbeeldingen om ze te helpen scoren in Google Afbeeldingen zoeken. In de afbeeldingssitemap kunt u aanvullende informatie over de afbeelding opgeven, zoals geolocatie, titel en licentie. U kunt maximaal 1000 afbeeldingen voor elke pagina weergeven.
Videositemaps zijn nodig voor video-inhoud die op uw pagina's wordt gehost om deze beter te laten scoren in Google Video Search. Hoewel Google het gebruik van gestructureerde gegevens voor video's aanbeveelt, kan een sitemap ook nuttig zijn, vooral wanneer u veel video-inhoud op een pagina heeft. In de videositemap kunt u extra informatie over de video toevoegen, zoals titels, beschrijving, duur, miniaturen en zelfs of deze gezinsvriendelijk is voor Safe Search.
Voor meertalige en multiregionale websites zijn er verschillende manieren waarop zoekmachines kunnen bepalen welke taalversie op een bepaalde locatie moet worden weergegeven. Hreflangs zijn een van de vele manieren om gelokaliseerde pagina's weer te geven, en daarvoor kunt u een speciale hreflang-sitemap gebruiken. De hreflang-sitemap vermeldt de URL zelf samen met het onderliggende element dat de taal-/regiocode voor de pagina aangeeft.
Als u een nieuwsblog beheert, kan het toevoegen van een News-XML-sitemap een positieve invloed hebben op uw posities op Google Nieuws. Hier voegt u informatie toe over de titel, de taal en de publicatiedatum. U kunt maximaal 1000 URL's toevoegen aan de Nieuws-sitemap. De URL's mogen niet ouder zijn dan twee dagen, daarna kun je ze verwijderen, maar ze blijven 30 dagen in de index staan.
Als uw website een RSS-feed heeft, kunt u de feed-URL indienen als een sitemap. De meeste blogsoftware kan een feed maken, maar deze informatie is alleen nuttig voor het snel ontdekken van recente URL's.
Tegenwoordig zijn de meest gebruikte XML-sitemaps, dus laten we kort de belangrijkste vereisten voor het genereren van XML-sitemaps herzien:
De XML-sitemap is UTF-8-gecodeerd en bevat verplichte tags voor een XML-element:
Een eenvoudig voorbeeld van een one-entry XML-sitemap ziet eruit
Er zijn optionele tags om de prioriteit en frequentie van paginacrawls aan te geven - <priority>, <changefreq> (Google negeert deze momenteel) en <lastmod> waarde wanneer deze correct is (bijvoorbeeld in vergelijking met de laatste wijziging op een pagina) .
Een typische fout bij sitemaps is het ontbreken van een geldige XML-sitemap op een groot domein. U kunt de aanwezigheid van een sitemap op de uwe controleren met WebSite Auditor . Zoek de resultaten in het gedeelte Site-audit > Indexering en doorzoekbaarheid .
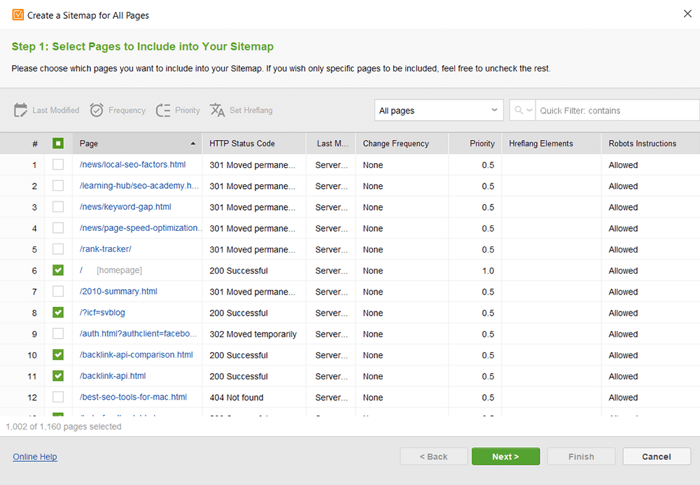
Als je geen sitemap hebt, moet je er nu echt een gaan maken. U kuntde sitemap snel genereren met behulp van de websitetools van WebSite Auditor wanneer u overschakelt naar het gedeelte Pagina's .
En laat Google weten over uw sitemap. Om dit te doen, kunt u
Het is een feit dat het hebben van een sitemap op uw website niet garandeert dat al uw pagina's worden geïndexeerd of zelfs gecrawld . Er zijn enkele andere technische SEO-bronnen, gericht op het verbeteren van de site-indexering. We zullen ze in de volgende stappen bekijken.
Een robots.txt-bestand vertelt zoekmachines tot welke URL's de crawler op uw site toegang heeft. Dit bestand dient om te voorkomen dat uw server wordt overbelast met verzoeken, om het crawlverkeer te beheren . Het bestand wordt meestal gebruikt om:
Robots.txt wordt in de root van het domein geplaatst en elk subdomein moet een apart bestand hebben. Houd er rekening mee dat het niet groter mag zijn dan 500 kB en moet reageren met een 200-code.
Het robots.txt-bestand heeft ook zijn syntaxis met regels voor Toestaan en Disallow :
Verschillende zoekmachines kunnen de richtlijnen anders volgen. Google stopte bijvoorbeeld met het gebruik van de richtlijnen noindex, crawl-delay en nofollow van robots.txt. Daarnaast zijn er speciale crawlers zoals Googlebot-Image, Bingbot, Baiduspider-image, DuckDuckBot, AhrefsBot, etc. U kunt dus de regels definiëren voor alle zoekbots of afzonderlijke regels voor slechts enkele.
Het schrijven van instructies voor robots.txt kan behoorlijk lastig worden, dus de regel hier is om minder instructies en meer gezond verstand te hebben. Hieronder staan enkele voorbeelden van het instellen van de instructies voor robots.txt.
Volledige toegang tot het domein. In dit geval is de afwijzingsregel niet ingevuld.
Volledige blokkering van een host.
De instructie staat het crawlen van alle URL's die beginnen met uploaden achter de domeinnaam niet toe.
De instructie staat Googlebot-News niet toe om alle gif-bestanden in de nieuwsmap te crawlen.
Houd er rekening mee dat als u een algemene instructie A instelt voor alle zoekmachines en één beperkte instructie B voor een specifieke bot, de specifieke bot de beperkte instructie kan volgen en alle andere algemene regels kan uitvoeren die standaard zijn ingesteld voor de bot, aangezien deze wordt niet beperkt door regel A. Bijvoorbeeld, zoals in de onderstaande regel:
Hier kan AdsBot-Google-Mobile bestanden in de tmp-map crawlen ondanks de instructie met het jokerteken *.
Een van de typische toepassingen van de robots.txt-bestanden is om aan te geven waar de sitemap zich bevindt. In dit geval hoeft u geen user-agents te vermelden, aangezien de regel van toepassing is op alle crawlers. De sitemap moet beginnen met een hoofdletter S (onthoud dat het bestand robots.txt hoofdlettergevoelig is) en de URL moet absoluut zijn (dwz deze moet beginnen met de volledige domeinnaam).
Houd er rekening mee dat als u tegenstrijdige instructies instelt, crawlerbots voorrang zullen geven aan de langere instructie. Bijvoorbeeld:
Hier is het script /admin/js/global.js ondanks de eerste instructie nog steeds toegestaan voor crawlers. Alle andere bestanden in de map admin zijn nog steeds niet toegestaan.
U kunt de beschikbaarheid van het robots.txt-bestand controleren in WebSite Auditor. U kunt het bestand ook genereren met behulp van de generatortool robots.txt , en het verder opslaan of rechtstreeks uploaden naar de website via FTP.
Houd er rekening mee dat het robots.txt-bestand openbaar beschikbaar is en dat sommige pagina's mogelijk worden weergegeven in plaats van verborgen. Als u enkele privémappen wilt verbergen, maak ze dan met een wachtwoord beveiligd.
Ten slotte garandeert het robots.txt-bestand niet dat de niet-toegestane pagina niet wordt gecrawld of geïndexeerd . Als Google wordt geblokkeerd voor het crawlen van een pagina, wordt deze waarschijnlijk uit de index van Google verwijderd, maar de zoekbot kan de pagina nog steeds crawlen na enkele backlinks die ernaar verwijzen. Dus hier is een andere manier om te voorkomen dat een pagina wordt gecrawld en geïndexeerd: meta-robots.
Meta-robottags zijn een geweldige manier om crawlers te instrueren hoe ze individuele pagina's moeten behandelen. Meta-robottags worden toegevoegd aan het <head>-gedeelte van uw HTML-pagina, dus de instructies zijn van toepassing op de hele pagina. U kunt meerdere instructies maken door metatagrichtlijnen van robots te combineren met komma's of door meerdere metatags te gebruiken. Het kan er zo uitzien:
U kunt bijvoorbeeld meta-robottags opgeven voor verschillende crawlers
Google begrijpt tags als:
De tegenovergestelde tags index / volgen / archiveren hebben voorrang op de overeenkomstige verbodsrichtlijnen. Er zijn enkele andere tags die aangeven hoe de pagina in zoekresultaten kan verschijnen, zoals snippet / nosnippet / notranslate / nopagereadaloud / noimageindex .
Als u andere tags gebruikt die geldig zijn voor andere zoekmachines maar onbekend zijn bij Google, zal Googlebot deze gewoon negeren.
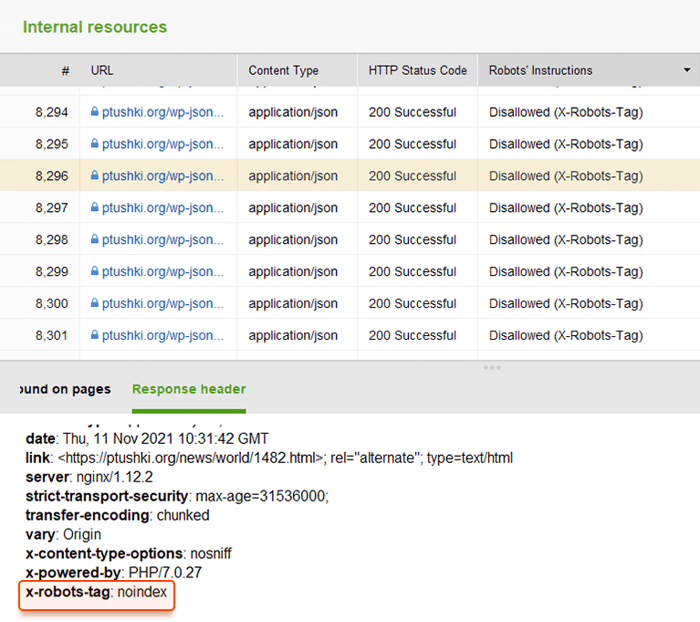
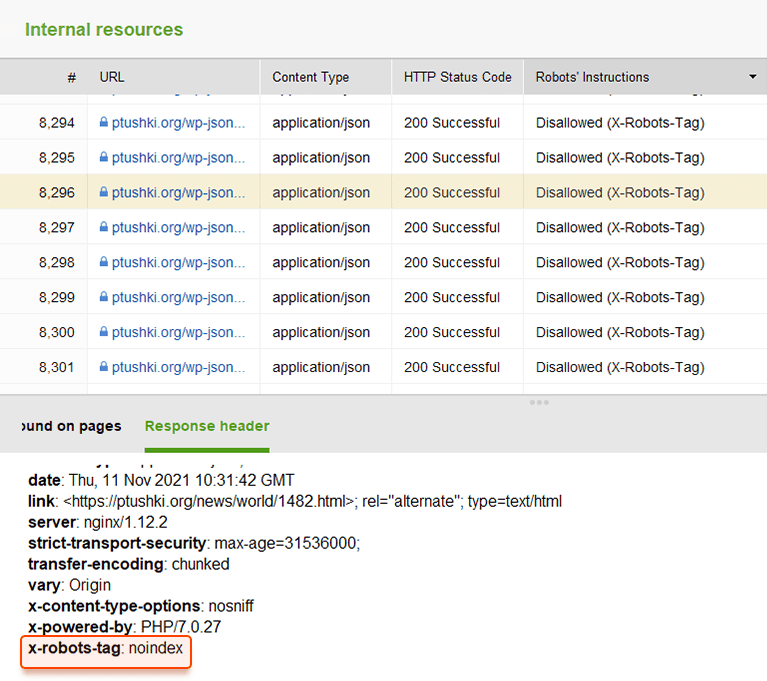
In plaats van metatags kunt u een responsheader gebruiken voor niet-HTML-bronnen , zoals pdf's, video- en afbeeldingsbestanden. Stel in dat een X-Robots-Tag-header wordt geretourneerd met de waarde noindex of geen in uw antwoord.
U kunt ook een combinatie van richtlijnen gebruiken om te definiëren hoe het fragment eruit zal zien in de zoekresultaten, bijvoorbeeld max-image-preview: [setting] of nosnippet of max-snippet: [number] , etc.
U kunt de X-Robots-Tag toevoegen aan de HTTP-antwoorden van een website via de configuratiebestanden van de webserversoftware van uw site. Uw crawlrichtlijnen kunnen wereldwijd op de hele site worden toegepast voor alle bestanden, maar ook voor individuele bestanden als u hun exacte namen definieert.
U kunt snel alle robotinstructies bekijken met WebSite Auditor . Ga naar Sitestructuur > Alle bronnen > Interne bronnen en controleer de kolom Instructies voor robots . Hier vindt u de niet-toegestane pagina's en welke methode wordt toegepast, robots.txt, metatags of X-Robots-tag.
De server die een site host, genereert een HTTP-statuscode wanneer hij reageert op een verzoek van een client, browser of crawler. Als de server reageert met een 2xx-statuscode, kan de ontvangen inhoud in aanmerking komen voor indexering. Andere reacties van 3xx tot 5xx geven aan dat er een probleem is met het weergeven van inhoud. Hier volgen enkele betekenissen van de HTTP-statuscodeantwoorden:
301-omleidingen worden gebruikt wanneer:
302 tijdelijke omleiding
De tijdelijke 302-omleiding mag alleen op tijdelijke pagina's worden gebruikt. Bijvoorbeeld wanneer u een pagina opnieuw ontwerpt of een nieuwe pagina test en feedback verzamelt, maar niet wilt dat de URL uit de rankings zakt.
304 om de cache te controleren
304-responscode wordt ondersteund in alle populaire zoekmachines, zoals Google, Bing, Baidu, Yandex, enz. De juiste instelling van de 304-responscode helpt de bot te begrijpen wat er op de pagina is veranderd sinds de laatste crawl. De bot stuurt een HTTP-verzoek If-Modified-Since. Als er geen wijzigingen zijn gedetecteerd sinds de laatste crawldatum, hoeft de zoekbot de pagina niet opnieuw te crawlen. Voor een gebruiker betekent dit dat de pagina niet volledig opnieuw wordt geladen en dat de inhoud uit de browsercache wordt gehaald.
De 304-code helpt ook om:
Het is belangrijk om de caching van niet alleen de inhoud van de pagina te controleren, maar ook van statische bestanden, zoals afbeeldingen of CSS-stijlen. Er zijn speciale tools, zoals deze , om de 304-responscode te controleren.


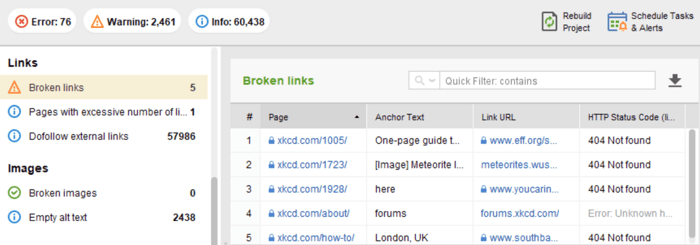
Meestal treden problemen met de serverresponscode op wanneer crawlers de interne en externe links naar de verwijderde of verplaatste pagina's blijven volgen en 3xx- en 4xx-antwoorden krijgen.
Een 404-fout geeft aan dat een pagina niet beschikbaar is en de server stuurt de juiste HTTP-statuscode naar de browser - een 404 Not Found.
Er zijn echter zachte 404-fouten wanneer de server de 200 OK-antwoordcode verzendt, maar Google vindt dat dit 404 zou moeten zijn. Dit kan gebeuren omdat:
Bekijk in de Site Audit- module van WebSite Auditor de bronnen met de responscode 4xx, 5xx onder het tabblad Indexering en doorzoekbaarheid en een apart gedeelte voor verbroken links op het tabblad Links .
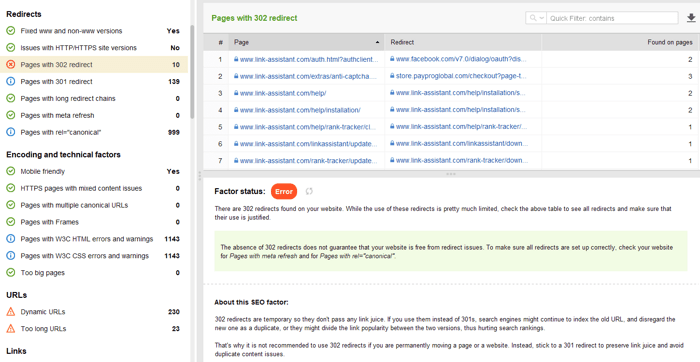
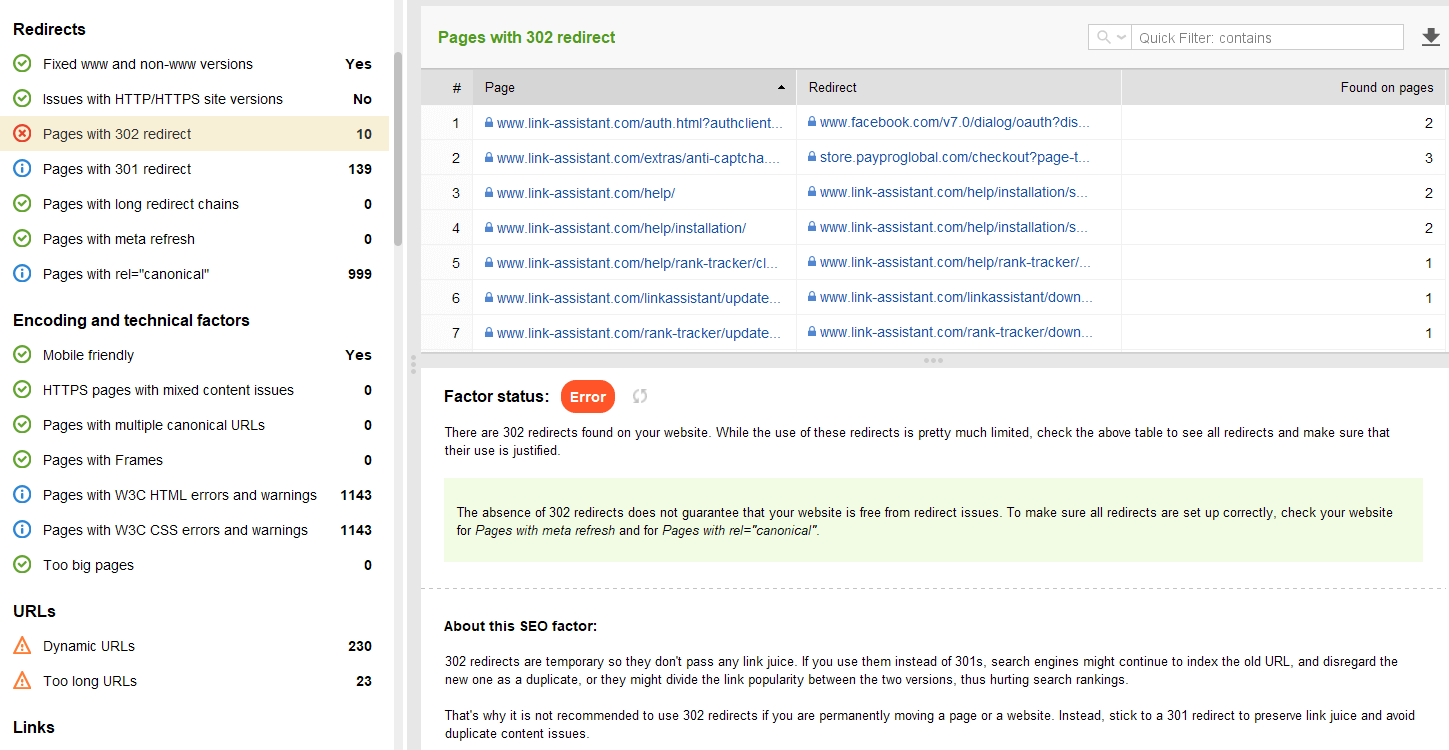
Enkele andere veelvoorkomende omleidingsproblemen met 301/302-antwoorden:
U kunt alle pagina's met 301- en 302-omleidingen bekijken in het gedeelte Site-controle > Omleidingen van WebSite Auditor.
Duplicatie kan een ernstig probleem worden bij het crawlen van websites. Als Google dubbele URL's vindt , zal het beslissen welke van hen een primaire pagina is en deze vaker crawlen, terwijl de duplicaten minder vaak worden gecrawld en mogelijk helemaal uit de zoekindex vallen. Een trefzekere oplossing is om een van de dubbele pagina's aan te duiden als canoniek, de hoofdpagina. Dit kan worden gedaan met behulp van het rel=”canonical” -attribuut, geplaatst in de HTML-code van de pagina's of de HTTP-headerantwoorden van een site.
Google gebruikt canonieke pagina's om uw inhoud en kwaliteit te beoordelen, en meestal linken zoekresultaten naar canonieke pagina's, tenzij de zoekmachines duidelijk aangeven dat een niet-canonieke pagina beter geschikt is voor de gebruiker (het is bijvoorbeeld een mobiele gebruiker of een zoeker op een specifieke locatie).
Zo helpt canonicalisatie van relevante pagina's om:
Dubbele problemen betekenen dat identieke of vergelijkbare inhoud op verschillende URL's wordt weergegeven. Vrij vaak verschijnen duplicaties automatisch vanwege technische gegevensverwerking op een website.
Sommige CMS'en kunnen automatisch dubbele problemen genereren vanwege de verkeerde instellingen. Er kunnen bijvoorbeeld meerdere URL's worden gegenereerd in verschillende website-directories, en dit zijn duplicaten:
Paginering kan ook duplicatieproblemen veroorzaken als het onjuist wordt geïmplementeerd. De URL voor de categoriepagina en pagina 1 tonen bijvoorbeeld dezelfde inhoud en worden dus als duplicaten behandeld. Een dergelijke combinatie zou niet moeten bestaan, of de categoriepagina zou als canoniek moeten worden gemarkeerd.
Sorteer- en filterresultaten kunnen worden weergegeven als duplicaten. Dit gebeurt wanneer uw site dynamische URL's maakt voor zoek- of filterquery's. U krijgt URL-parameters die aliassen van queryreeksen of URL-variabelen vertegenwoordigen, dit zijn het deel van een URL dat volgt op een vraagteken.
Om te voorkomen dat Google een aantal bijna identieke pagina's crawlt, stelt u in om bepaalde URL-parameters te negeren. Om dat te doen, start u Google Search Console en gaat u naar Verouderde tools en rapporten > URL-parameters . Klik aan de rechterkant op Bewerken en vertel Google welke parameters moeten worden genegeerd - de regel is van toepassing op de hele site. Houd er rekening mee dat de parametertool voor gevorderde gebruikers is, dus het moet nauwkeurig worden gebruikt.
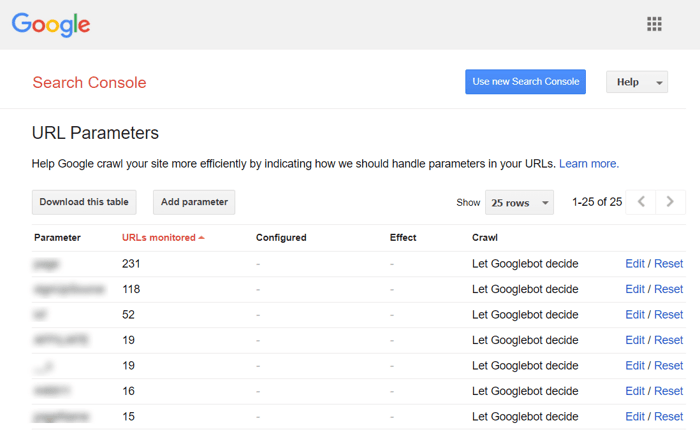
Het duplicatieprobleem doet zich vaak voor op e-commercewebsites die gefacetteerde filternavigatie mogelijk maken, waardoor de zoekopdracht wordt beperkt tot drie, vier en meer criteria. Hier is een voorbeeld van het instellen van crawlregels voor een e-commercesite: bewaar URL's met langere, nauwere zoekresultaten in een specifieke map en verbied deze door een robots.txt-regel.
Logische problemen in de structuur van de website kunnen duplicatie veroorzaken. Dit kan het geval zijn wanneer u producten verkoopt en één product tot verschillende categorieën behoort.
In dit geval moeten de producten via slechts één URL toegankelijk zijn. De URL's worden beschouwd als volledige duplicaten en zijn schadelijk voor SEO. De URL moet worden toegewezen via de juiste instellingen van het CMS, waardoor een unieke enkele URL voor één pagina wordt gegenereerd.
Gedeeltelijke duplicatie gebeurt vaak bij WordPress CMS, bijvoorbeeld wanneer er tags worden gebruikt. Terwijl tags het zoeken op de site en gebruikersnavigatie verbeteren, genereren WP-websites tag- pagina's die kunnen samenvallen met de categorienamen en vergelijkbare inhoud vertegenwoordigen uit het voorbeeld van artikelfragmenten. De oplossing is om tags verstandig te gebruiken en er slechts een beperkt aantal toe te voegen. Of u kunt een meta-robot noindex dofollow toevoegen aan tagpagina's.
Als u ervoor kiest om een afzonderlijke mobiele versie van uw website weer te geven en in het bijzonder AMP-pagina's voor mobiel zoeken te genereren, heeft u mogelijk dubbele van dit soort.
Om aan te geven dat een pagina een duplicaat is, kunt u een <link>-tag gebruiken in het head-gedeelte van uw HTML. Voor mobiele versies is dit de link-tag met de waarde rel=“alternate”, zoals deze:
Hetzelfde geldt voor AMP-pagina's (die niet de trend zijn, maar nog steeds kunnen worden gebruikt om mobiele resultaten weer te geven). Bekijk onze handleiding over de implementatie van AMP-pagina's .
Er zijn verschillende manieren om gelokaliseerde inhoud te presenteren. Wanneer u inhoud presenteert in verschillende taal-/landinstellingen en u alleen de koptekst/voettekst/navigatie van de site heeft vertaald, maar de inhoud in dezelfde taal blijft, worden de URL's behandeld als duplicaten.
Stel het weergeven van meertalige en multiregionale sites in met behulp van hreflang- tags, voeg de ondersteunde taal-/regiocodes toe aan de HTML, HTTP-antwoordcodes of in de sitemap.
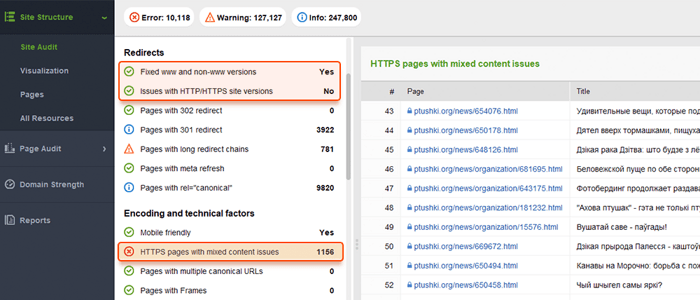
Websites zijn meestal beschikbaar met en zonder "www" in de domeinnaam. Dit probleem komt vrij vaak voor en mensen linken naar zowel www- als niet-www-versies. Als u dit oplost, voorkomt u dat zoekmachines twee versies van een website indexeren. Hoewel een dergelijke indexering geen boete oplevert, is het een best practice om één versie als prioriteit in te stellen.
Google geeft de voorkeur aan HTTPS boven HTTP, aangezien veilige codering ten zeerste wordt aanbevolen voor de meeste websites (vooral bij het uitvoeren van transacties en het verzamelen van gevoelige gebruikersinformatie). Soms hebben webmasters te maken met technische problemen bij het installeren van SSL-certificaten en het instellen van de HTTP/HTTPS-versies van de website. Als een site een ongeldig SSL-certificaat heeft (niet-vertrouwd of verlopen), zullen de meeste webbrowsers voorkomen dat gebruikers uw site bezoeken door hen op de hoogte te stellen van een "onveilige verbinding".
Als de HTTP- en HTTPS-versies van uw website niet correct zijn ingesteld, kunnen beide geïndexeerd worden door zoekmachines en problemen met dubbele inhoud veroorzaken die de positie van uw website kunnen ondermijnen.
Als uw site al HTTPS gebruikt (gedeeltelijk of volledig), is het belangrijk om veelvoorkomende HTTPS-problemen te elimineren als onderdeel van uw SEO-site-audit. Vergeet vooral niet om te controleren op gemengde inhoud in het gedeelte Site-audit > Codering en technische factoren .
Problemen met gemengde inhoud doen zich voor wanneer een anders beveiligde pagina een deel van de inhoud (afbeeldingen, video's, scripts, CSS-bestanden) laadt via een niet-beveiligde HTTP-verbinding. Dit verzwakt de beveiliging en kan voorkomen dat browsers de niet-beveiligde inhoud of zelfs de hele pagina laden.
Om deze problemen te voorkomen, kunt u de primaire www- of niet-www-versie voor uw site instellen en bekijken in het .htaccess-bestand . Stel ook het voorkeursdomein in Google Search Console in en geef HTTPS-pagina's aan als canoniek.
Als u eenmaal de volledige controle heeft over de inhoud op uw eigen website, zorg er dan voor dat er geen dubbele titels, koppen, beschrijvingen, afbeeldingen enz. zijn. Voor een hint over dubbele inhoud op de hele site, zie de On-page sectie in WebSite Auditor 's Site Audit dashboard. De pagina's met dubbele titels en metabeschrijvingstags hebben waarschijnlijk ook bijna identieke inhoud.
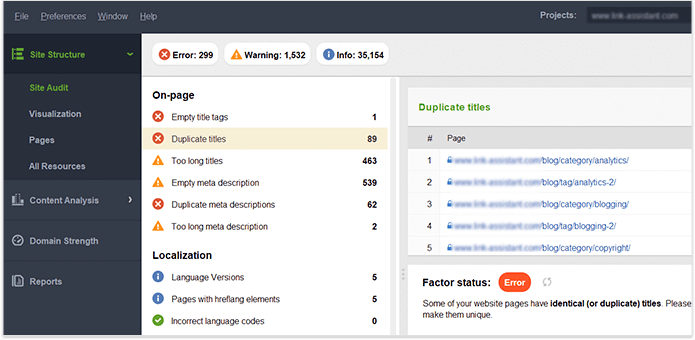
Laten we samenvatten hoe we indexatieproblemen ontdekken en oplossen. Als je alle bovenstaande tips hebt gevolgd, maar sommige van je pagina's nog steeds niet in de index staan, is hier een samenvatting van de reden waarom dit kan zijn gebeurd:
Waarom wordt een pagina geïndexeerd terwijl dat niet zou moeten?
Houd er rekening mee dat het blokkeren van een pagina in het robots.txt-bestand en het verwijderen van de pagina uit de sitemap geen garantie is dat deze niet wordt geïndexeerd. U kunt onze gedetailleerde gids raadplegen over hoe u kunt voorkomen dat pagina's correct worden geïndexeerd .
Ondiepe, logische site-architectuur is belangrijk voor zowel gebruikers als bots van zoekmachines. Een goed geplande sitestructuur speelt ook een grote rol in de ranglijst omdat:
Let bij het beoordelen van de structuur van uw sites en interne koppelingen op de volgende elementen.
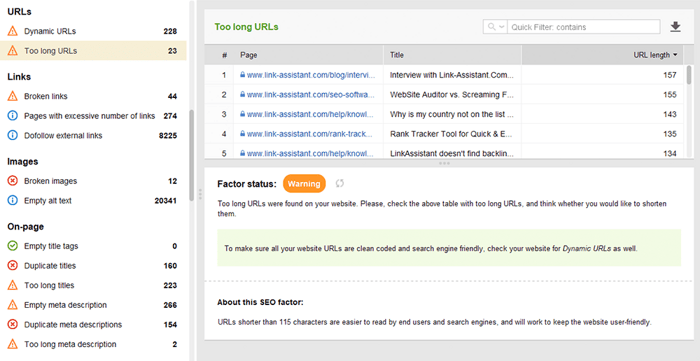
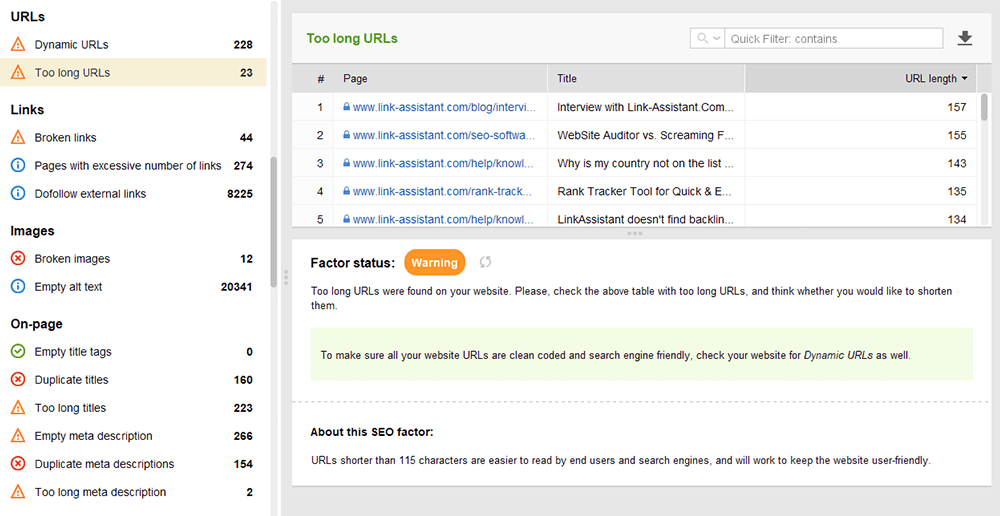
Geoptimaliseerde URL's zijn om twee redenen cruciaal. Ten eerste is het een kleine rankingfactor voor Google. Ten tweede kunnen gebruikers in de war raken door te lange of onhandige URL's. Denk aan uw URL-structuur en houd u aan de volgende praktische tips :
U kunt uw URL's controleren in de sectie Sitecontrole > URL's van Website Auditor.
Er zijn veel soorten links, waarvan sommige min of meer gunstig zijn voor de SEO van uw website. Dofollow contextuele links geven bijvoorbeeld de link juice door en dienen als een extra indicator voor zoekmachines waar de link over gaat. Links worden als van hoge kwaliteit beschouwd wanneer (en dit verwijst naar zowel interne als externe links):
Navigatielinks in kopteksten en zijbalken zijn ook belangrijk voor website-SEO, omdat ze gebruikers en zoekmachines helpen bij het navigeren door de pagina's.
Andere links hebben mogelijk geen rankingwaarde of schaden zelfs een site-autoriteit. Bijvoorbeeld enorme uitgaande links voor de hele site in sjablonen (die gratis WP-sjablonen vroeger veel hadden). Deze gids over de soorten links in SEO vertelt hoe je op de juiste manier waardevolle links opbouwt.
U kunt de WebSite Auditor -tool gebruiken om interne links en hun kwaliteit grondig te onderzoeken.
Weespagina's zijn niet-gelinkte pagina's die onopgemerkt blijven en uiteindelijk uit de zoekindex kunnen vallen. Om verweesde pagina's te vinden, gaat u naar Site Audit > Visualisatie en bekijkt u de visuele sitemap . Hier ziet u eenvoudig alle niet-gelinkte pagina's en lange omleidingsketens (301- en 302-omleidingen zijn blauw gemarkeerd).
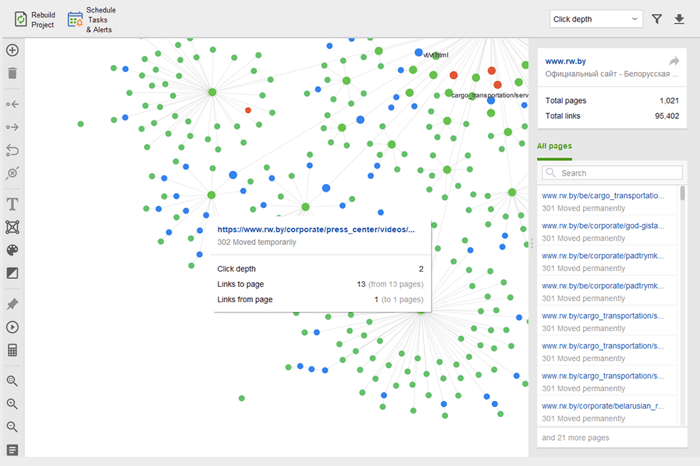
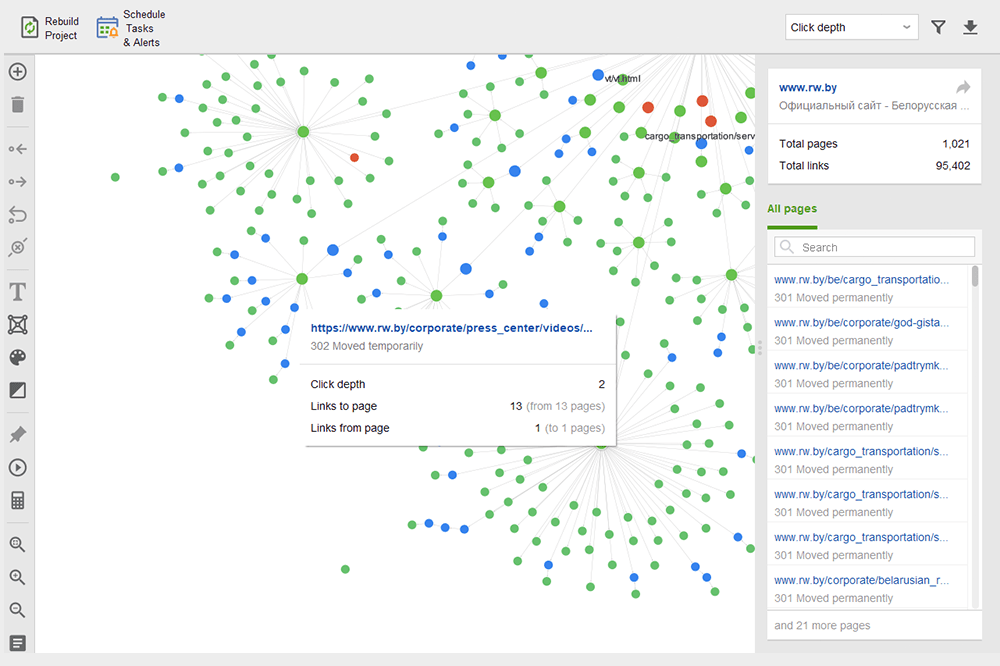
U kunt de hele structuur van de site overzien, het gewicht van de hoofdpagina's onderzoeken - door paginaweergaven (geïntegreerd vanuit Google Analytics), PageRank en de hoeveelheid links die ze krijgen van inkomende en uitgaande links te controleren. U kunt koppelingen toevoegen en verwijderen en het project opnieuw opbouwen, waarbij u de prominentie van elke pagina opnieuw berekent.
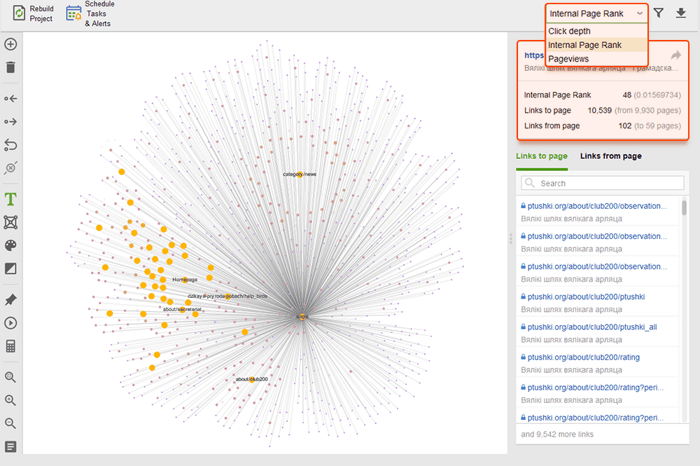
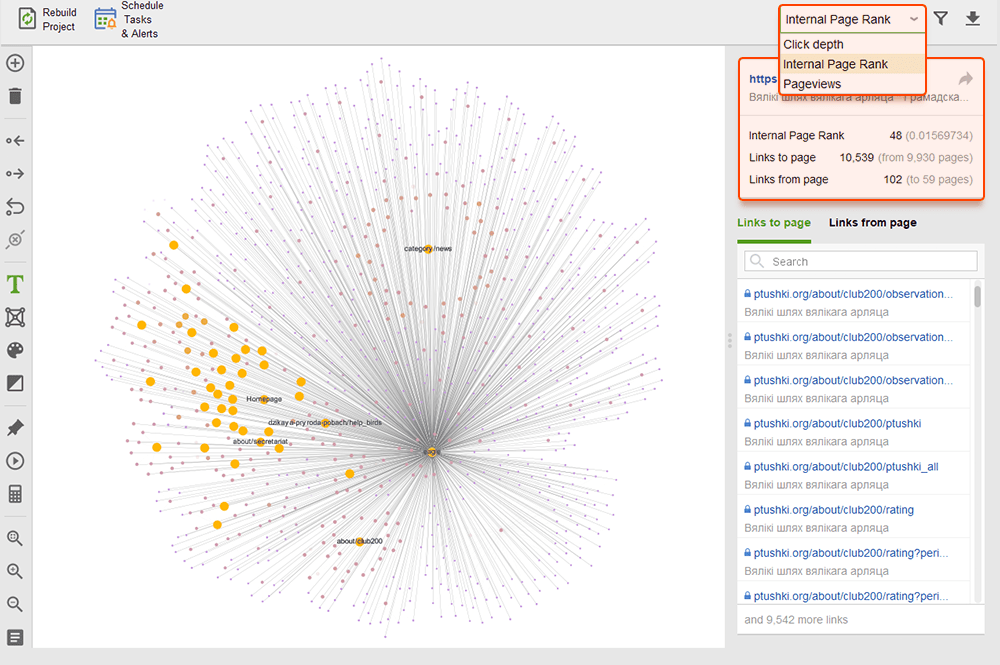
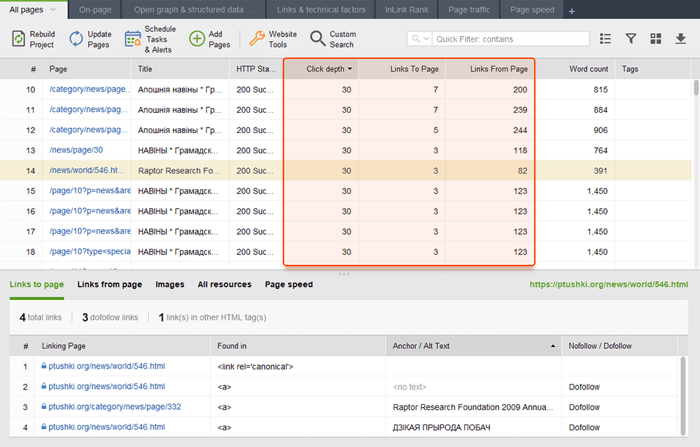
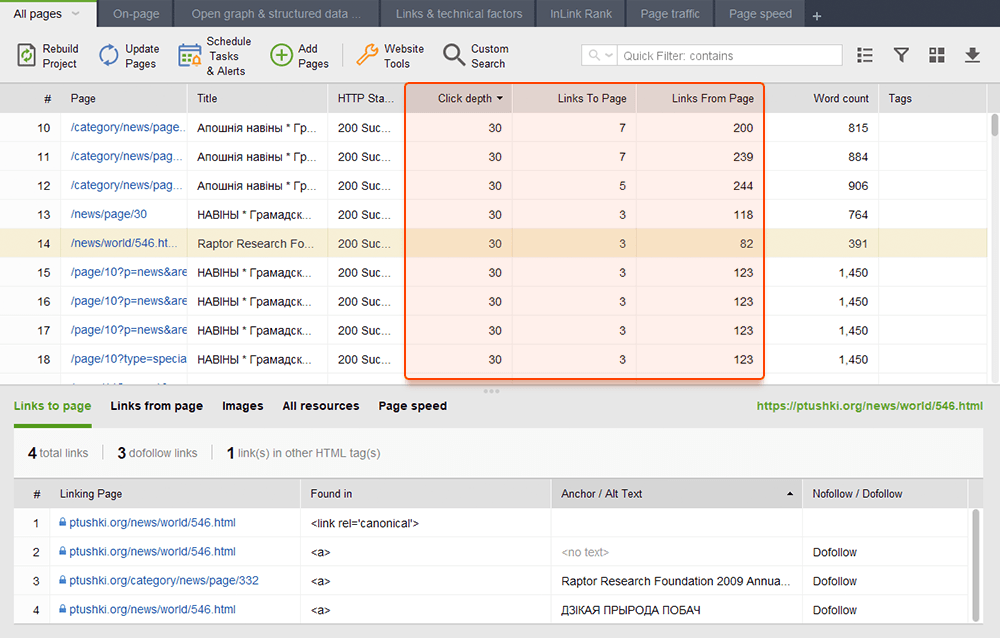
Terwijl u uw interne links controleert, controleert u de klikdiepte. Zorg ervoor dat de belangrijke pagina's van uw site niet meer dan drie klikken verwijderd zijn van de startpagina. Een andere plaats om de klikdiepte in WebSite Auditor te bekijken, is door naar Sitestructuur > Pagina's te gaan. Sorteer vervolgens de URL's op klikdiepte in aflopende volgorde door twee keer op de kop van de kolom te klikken.
Paginering van blogpagina's is noodzakelijk voor vindbaarheid door zoekmachines, hoewel het de klikdiepte vergroot. Gebruik een eenvoudige structuur in combinatie met een bruikbare sitezoekopdracht om het voor gebruikers gemakkelijker te maken om elke bron te vinden.
Raadpleeg voor meer informatie onze gedetailleerde gids voor SEO-vriendelijke paginering .
Breadcrumb is een markup-type dat helpt bij het maken van rijke resultaten in zoekresultaten, waarbij het pad naar de pagina binnen de structuur van uw site wordt weergegeven. Breadcrumbs verschijnen dankzij de juiste koppeling, met geoptimaliseerde ankers op interne links en correct geïmplementeerde gestructureerde gegevens (we zullen een paar paragrafen hieronder op de laatste ingaan).

Interne koppelingen kunnen zelfs van invloed zijn op de positie van uw site en de manier waarop elke pagina in de zoekresultaten wordt weergegeven. Raadpleeg voor meer informatie onze SEO-gids voor interne koppelingsstrategieën .
Sitesnelheid en pagina-ervaring hebben een directe invloed op organische posities. De reactie van de server kan een probleem worden voor de prestaties van de site wanneer er te veel gebruikers tegelijk een bezoek brengen. Wat de paginasnelheid betreft, verwacht Google dat de grootste pagina-inhoud in 2,5 seconden of minder in de viewport wordt geladen, en beloont uiteindelijk pagina's die betere resultaten leveren. Daarom moet de snelheid zowel aan de server- als aan de clientzijde worden getest en verbeterd.
Laadsnelheidstesten ontdekken server-side problemen wanneer te veel gebruikers tegelijkertijd een website bezoeken. Hoewel het probleem verband houdt met serverinstellingen, moeten SEO's er rekening mee houden voordat ze grootschalige SEO- en advertentiecampagnes plannen. Test de maximale capaciteit van uw server als u een toename van het aantal bezoekers verwacht. Let op de correlatie tussen de opkomst van bezoekers en de responstijd van de server. Er zijn belastingtesttools waarmee u talloze gedistribueerde bezoeken kunt simuleren en uw servercapaciteit kunt crashen.
Aan de serverkant is een van de belangrijkste statistieken de TTFB- meting, of tijd tot eerste byte . TTFB meet de duur vanaf het moment dat de gebruiker een HTTP-verzoek doet tot de eerste byte van de pagina die door de browser van de client wordt ontvangen. De reactietijd van de server is van invloed op de prestaties van uw webpagina's. TTFB-audit mislukt als de browser langer dan 600 ms wacht voordat de server reageert. Houd er rekening mee dat de eenvoudigste manier om TTFB te verbeteren is om over te stappen van gedeelde hosting naar beheerde hosting , aangezien u in dit geval alleen een dedicated server voor uw site heeft.
Hier is bijvoorbeeld een paginatest gemaakt met Geekflare - een gratis tool om de prestaties van de site te controleren . Zoals u kunt zien, laat de tool zien dat TTFB voor deze pagina langer is dan 600 ms, dus moet worden verbeterd.

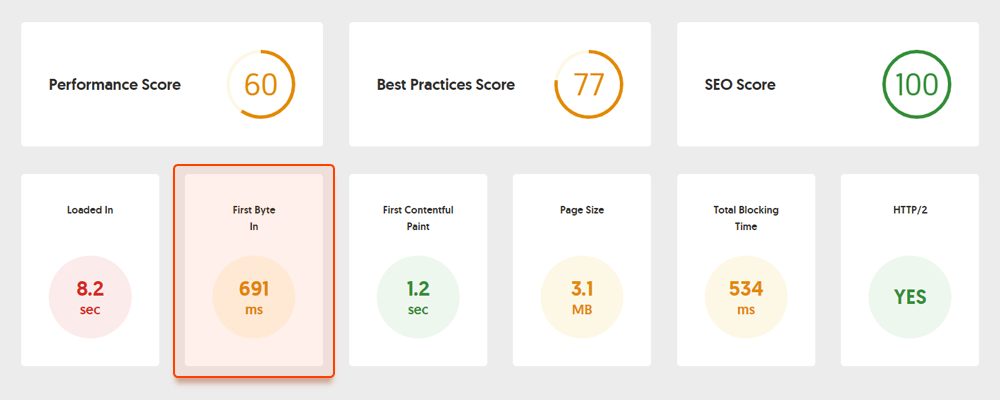
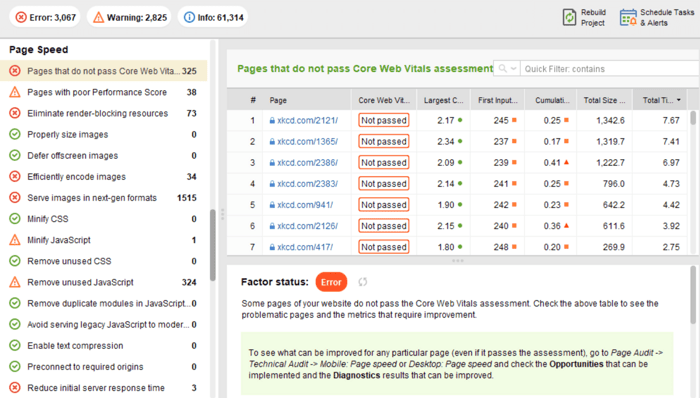
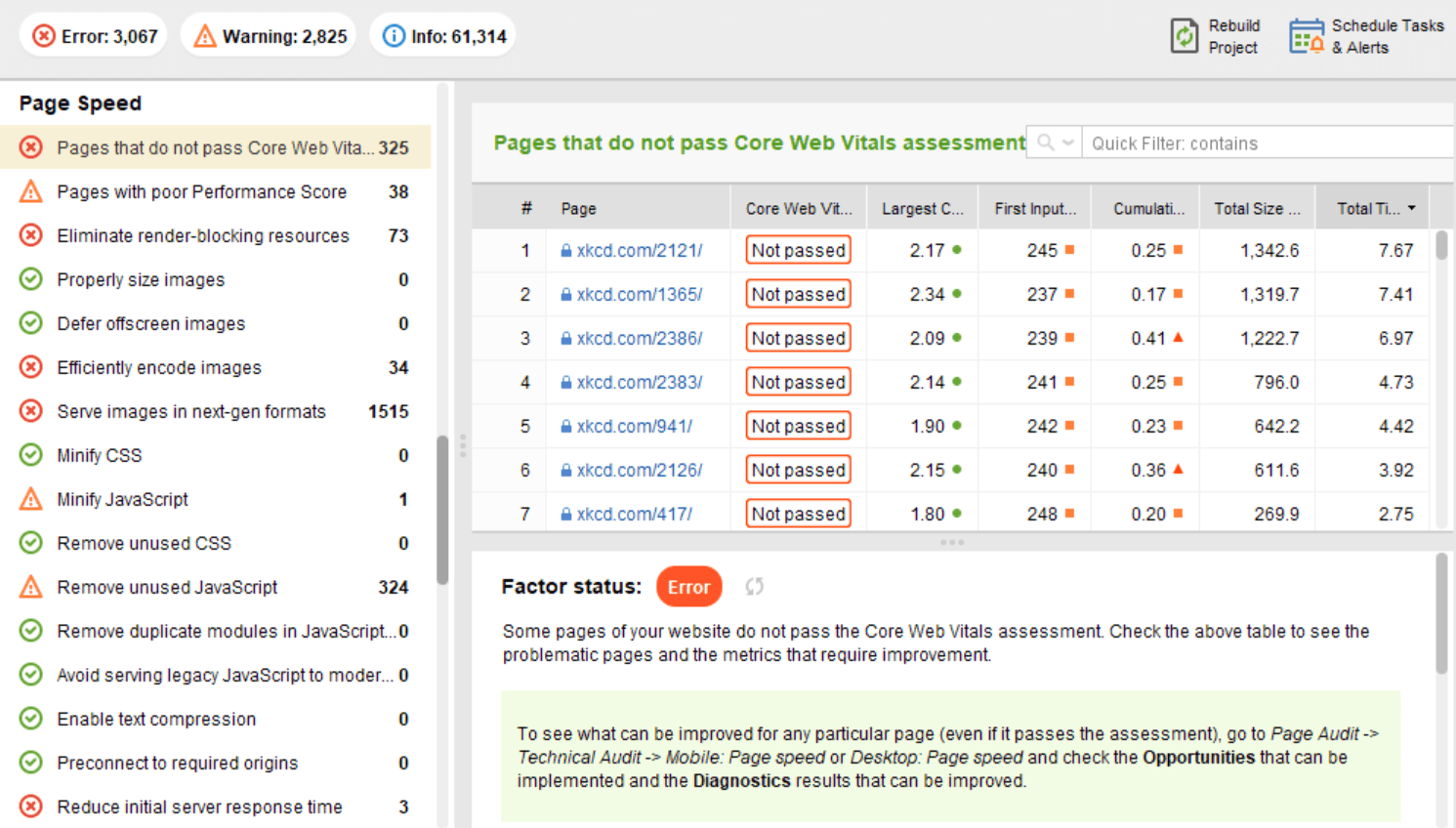
Aan de kant van de klant is de paginasnelheid echter niet eenvoudig te meten, en Google heeft lange tijd met deze statistiek geworsteld. Eindelijk is het aangekomen bij Core Web Vitals - drie statistieken die zijn ontworpen om de waargenomen snelheid van een bepaalde pagina te meten. Deze statistieken zijn Largest Contentful Pain (LCP), First Input Delay (FID) en Cumulative Layout Shift (CLS). Ze tonen de prestaties van een website met betrekking tot laadsnelheid, interactiviteit en visuele stabiliteit van de webpagina's. Als je meer informatie nodig hebt over elke CWV-statistiek, bekijk dan onze gids over Core Web Vitals .
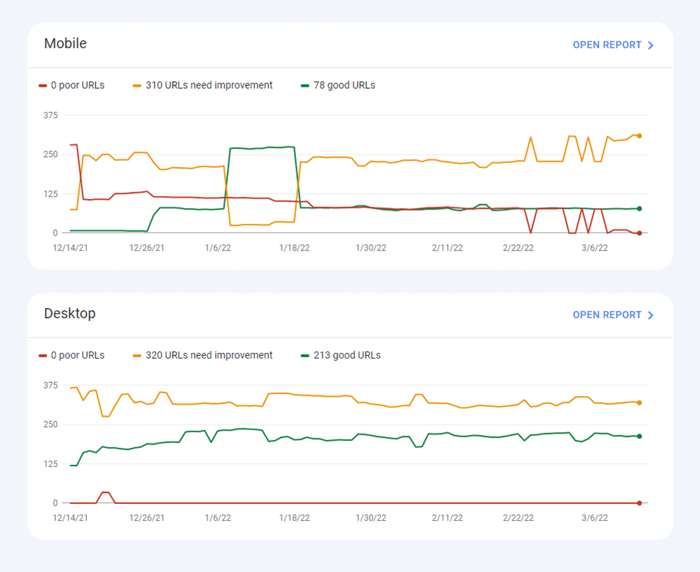
Onlangs zijn alle drie de Core Web Vitals-statistieken toegevoegd aan WebSite Auditor . Dus als u deze tool gebruikt, kunt u elke metrische score zien, een lijst met problemen met de paginasnelheid op uw website en een lijst met getroffen pagina's of bronnen. De data worden geanalyseerd via de PageSpeed API key die gratis gegenereerd kan worden.
Het voordeel van het gebruik van WebSite Auditor om CWV te controleren, is dat u een bulkcontrole voor alle pagina's tegelijk uitvoert. Als u ziet dat veel pagina's hetzelfde probleem hebben, is het probleem waarschijnlijk de hele site en kan het met één enkele oplossing worden opgelost. Het is dus eigenlijk niet zoveel werk als het lijkt. Het enige dat u hoeft te doen, is de aanbevelingen aan de rechterkant te volgen en uw paginasnelheid zal binnen de kortste keren omhoog gaan.
Tegenwoordig overtreft het aantal mobiele zoekers dat van desktops. In 2019 implementeerde Google mobile-first indexing , waarbij de smartphone-agent websites voor de Googlebot-desktop crawlt. Mobielvriendelijkheid is dus van het grootste belang voor organische rankings.
Opmerkelijk genoeg zijn er verschillende benaderingen om mobielvriendelijke websites te maken:
De voor- en nadelen van elke oplossing worden uitgelegd in onze gedetailleerde gids over hoe u uw website mobielvriendelijk kunt maken . Bovendien kun je AMP-pagina's opfrissen - hoewel dit geen geavanceerde technologie is, werkt het nog steeds goed voor sommige soorten pagina's, bijvoorbeeld voor nieuws.
Mobielvriendelijkheid blijft een cruciale factor voor websites die één URL aanbieden voor zowel desktops als mobiele apparaten. Bovendien blijven sommige gebruikssignalen, zoals de afwezigheid van opdringerige interstitials, een relevante factor voor zowel desktop- als mobiele rankings. Daarom moeten webontwikkelaars zorgen voor de beste gebruikerservaring op alle soorten apparaten.
De mobielvriendelijke test van Google omvat een selectie van bruikbaarheidscriteria, zoals viewport-configuratie, gebruik van plug-ins en de grootte van tekst en klikbare elementen. Het is ook belangrijk om te onthouden dat mobielvriendelijkheid per pagina wordt beoordeeld, dus u moet elk van uw bestemmingspagina's afzonderlijk controleren op mobielvriendelijkheid, één voor één.
Om je hele website te beoordelen, schakel je over naar Google Search Console. Ga naar het tabblad Ervaring en klik op het rapport Mobiele bruikbaarheid om de statistieken voor al uw pagina's te bekijken. Onder de grafiek ziet u een tabel met de meest voorkomende problemen die van invloed zijn op uw mobiele pagina's. Door op een probleem onder het dashboard te klikken, krijgt u een lijst met alle betrokken URL's.
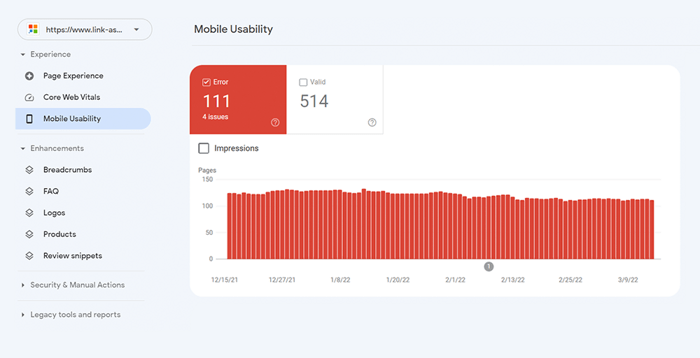

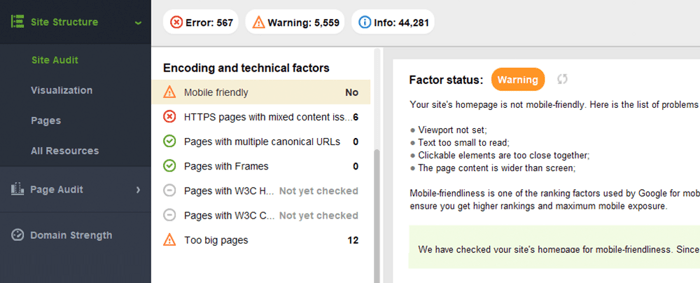
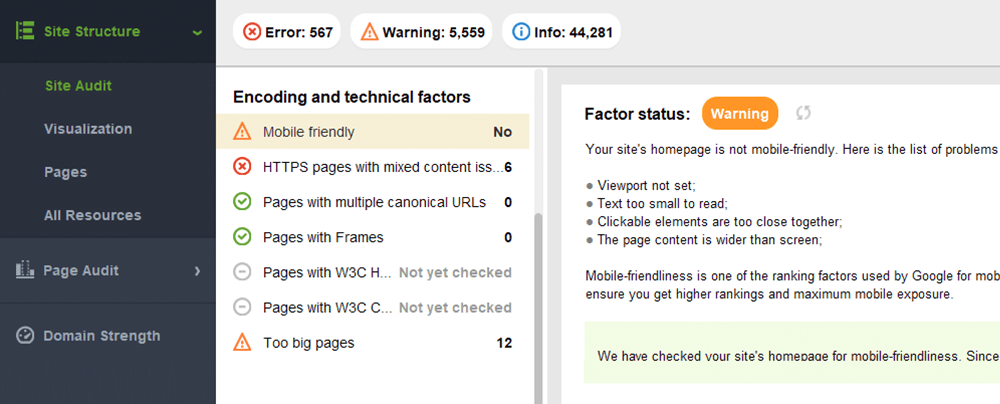
Typische problemen met mobielvriendelijkheid zijn:
WebSite Auditor beoordeelt ook de mobielvriendelijkheid van de startpagina en wijst op problemen in de mobiele gebruikerservaring. Ga naar Site Audit > Codering en technische factoren . De tool laat zien of de site mobielvriendelijk is en geeft eventuele problemen weer:
On-page signalen zijn directe rankingfactoren en hoe goed de technische deugdelijkheid van uw website ook is, uw pagina's zullen nooit in de zoekresultaten verschijnen zonder de juiste optimalisatie van HTML-tags . Het is dus uw doel om de titels, metabeschrijvingen en H1-H3-koppen van uw inhoud op uw website te controleren en op te ruimen.
De titel en metabeschrijving worden door zoekmachines gebruikt om een zoekresultaatfragment te vormen. Dit fragment is wat gebruikers als eerste zien, dus het heeft een grote invloed op de organische klikfrequentie .
Koppen, samen met alinea's, lijsten met opsommingstekens en andere structuurelementen van webpagina's, helpen bij het creëren van rijke zoekresultaten in Google. Bovendien verbeteren ze natuurlijk de leesbaarheid en gebruikersinteractie met de pagina, wat een positief signaal kan zijn voor zoekmachines. In de gaten houden:
Dupliceer titels, koppen en beschrijvingen over de hele site — corrigeer ze door voor elke pagina unieke titels te schrijven.
Optimalisatie van de titels, koppen en beschrijvingen voor zoekmachines (d.w.z. de lengte, trefwoorden, enz.)
Dunne inhoud — pagina's met weinig inhoud zullen bijna nooit rangschikken en kunnen zelfs de autoriteit van de site bederven (vanwege het Panda-algoritme), dus zorg ervoor dat uw pagina's het onderwerp diepgaand behandelen.
Optimalisatie van afbeeldingen en multimediabestanden — gebruik SEO-vriendelijke formaten, pas lazyloading toe, pas de grootte van de bestanden aan om ze lichter te maken, enz. Lees voor meer informatie onze gids over beeldoptimalisatie .
WebSite Auditor kan u veel helpen met deze taak. In het gedeelte Sitestructuur > Site-audit kunt u de problemen met metatags op de hele website in bulk controleren. Als u de inhoud van de afzonderlijke pagina's in meer detail wilt controleren, gaat u naar het gedeelte Paginacontrole . De app heeft ook een ingebouwde schrijftool Content Editor die u suggesties biedt voor het herschrijven van pagina's op basis van uw beste SERP-concurrenten. U kunt de pagina's onderweg bewerken of de aanbevelingen downloaden als taak voor copywriters.
Lees voor meer informatie onze SEO-optimalisatiegids op de pagina .
Gestructureerde gegevens zijn semantische markeringen waarmee zoekbots de inhoud van een pagina beter kunnen begrijpen. Als uw pagina bijvoorbeeld een recept voor appeltaart bevat, kunt u gestructureerde gegevens gebruiken om Google te vertellen welke tekst de ingrediënten zijn, wat de kooktijd is, het aantal calorieën, enzovoort. Google gebruikt de opmaak om rich snippets voor uw pagina's in SERP's te maken.
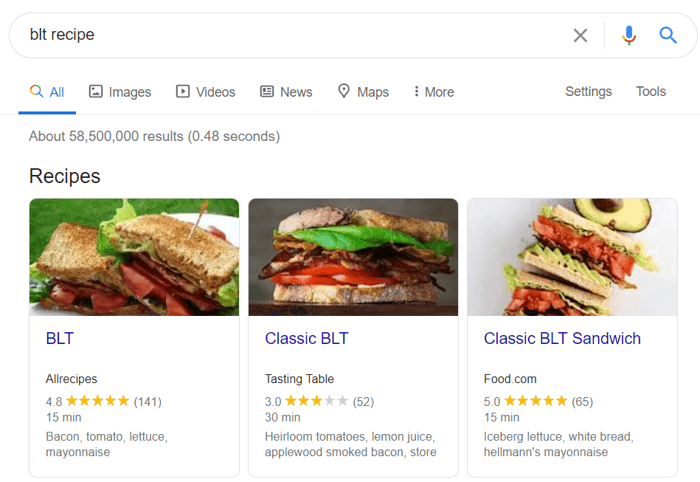
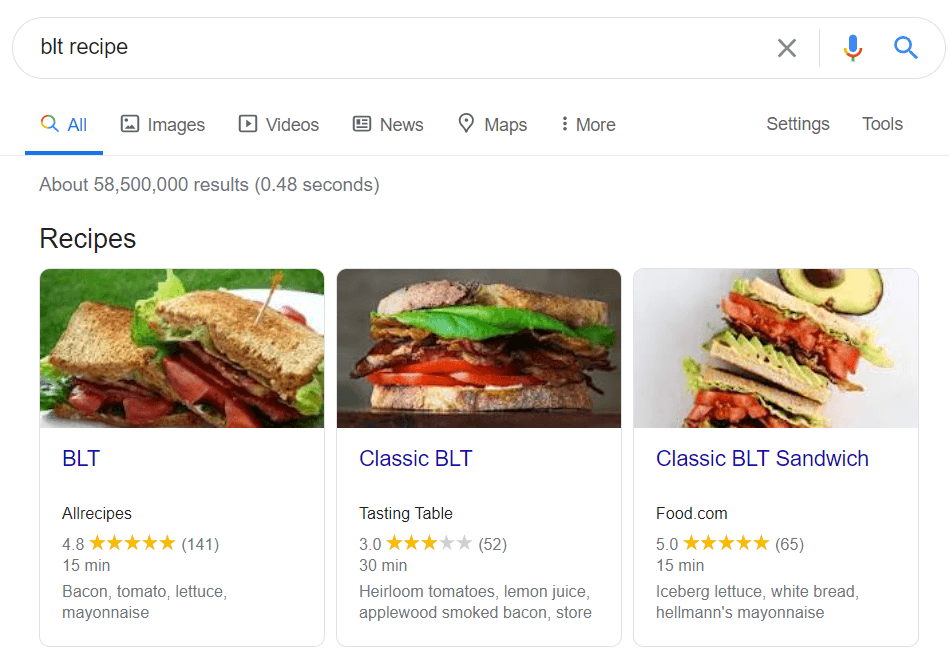
Er zijn twee populaire standaarden voor gestructureerde gegevens, OpenGraph voor mooi delen op sociale media en Schema voor zoekmachines. De varianten van de markup-implementatie zijn de volgende: Microdata, RDFa en JSON-LD . Microdata en RDFa worden toegevoegd aan de HTML van de pagina, terwijl JSON-LD een JavaScript-code is. Dit laatste wordt aanbevolen door Google.
Als het inhoudstype van uw pagina een van de onderstaande is, wordt de opmaak met name aanbevolen:
Houd er rekening mee dat het manipuleren van gestructureerde gegevens kan leiden tot boetes van zoekmachines. De opmaak mag bijvoorbeeld niet de inhoud beschrijven die voor gebruikers verborgen is (dwz die zich niet in de HTML van de pagina bevindt). Test uw opmaak met de tool voor het testen van gestructureerde gegevens voordat u deze implementeert.
U kunt uw markeringen ook controleren in Google Search Console op het tabblad Verbeteringen . GSC geeft de verbeteringen weer die u op uw website heeft doorgevoerd en laat u weten of dit is gelukt.
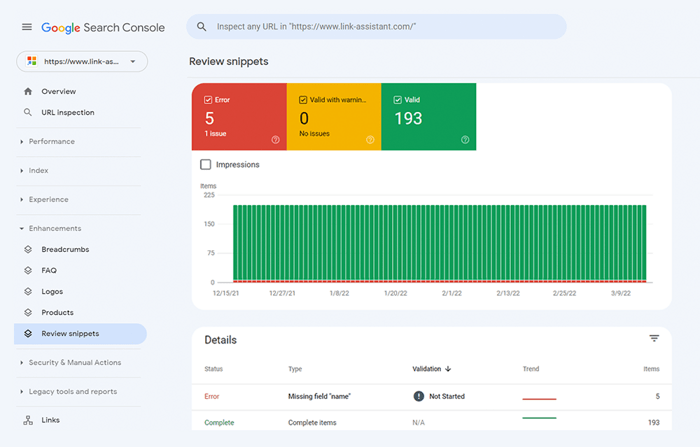
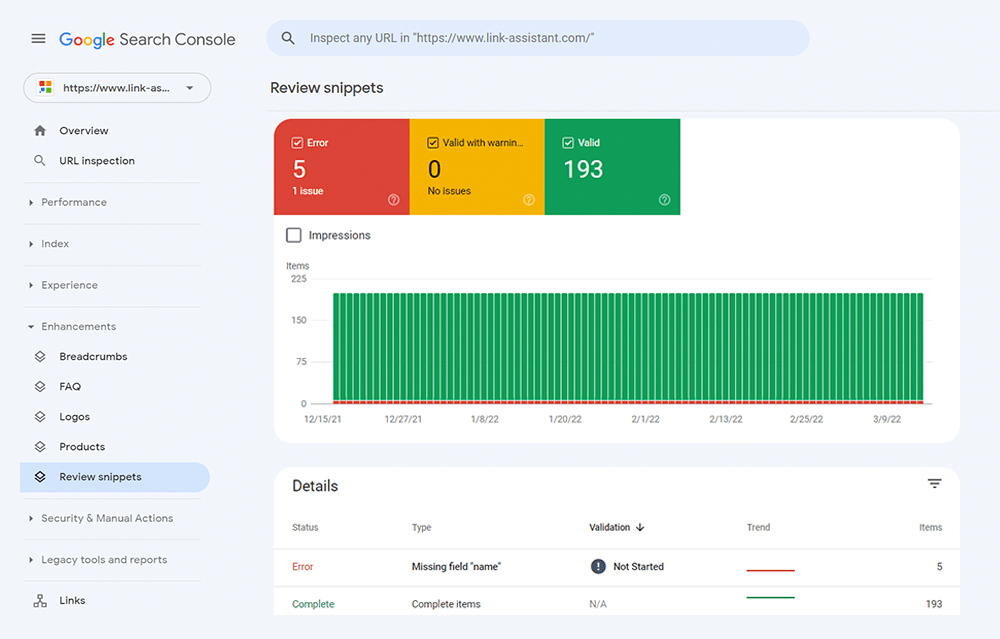
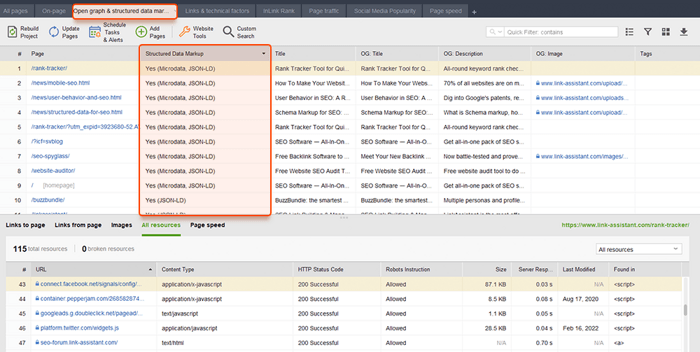
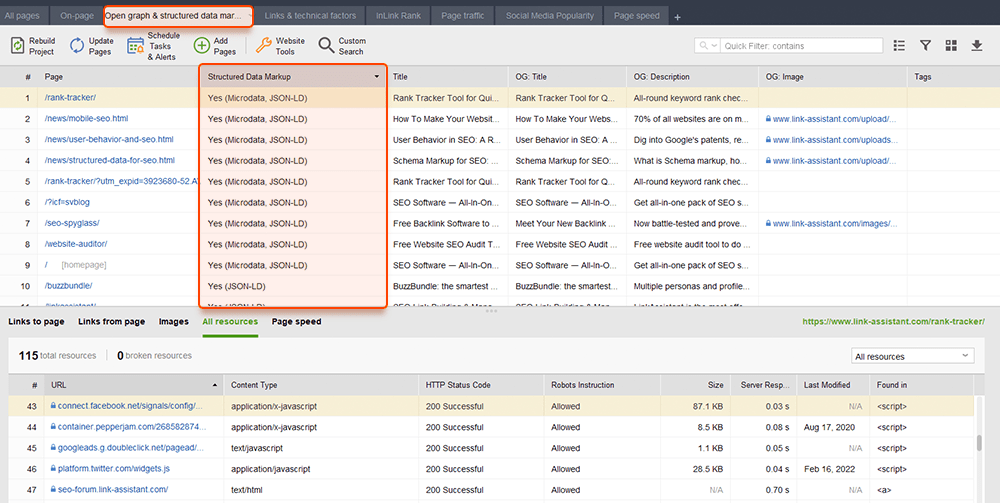
Ook hier kan WebSite Auditor u helpen. De tool kan al uw pagina's bekijken en de aanwezigheid van gestructureerde gegevens op een pagina, het type, titels, beschrijvingen en URL's van OpenGraph-bestanden weergeven.
Als je Schema-opmaak nog niet hebt geïmplementeerd, bekijk dan deze SEO-gids over gestructureerde gegevens . Houd er rekening mee dat als uw website een CMS gebruikt, gestructureerde gegevens standaard kunnen worden geïmplementeerd, of u kunt deze toevoegen door een plug-in te installeren (overdrijf toch niet met plug-ins).
Nadat u uw website heeft gecontroleerd en alle ontdekte problemen heeft opgelost, kunt u Google vragen uw pagina's opnieuw te crawlen om de wijzigingen sneller te laten zien.
Dien in Google Search Console de bijgewerkte URL in bij de URL-inspectietool en klik op Indexering aanvragen . U kunt ook gebruikmaken van de Test Live URL- functie (voorheen bekend als de functie Fetchen als Google ) om uw pagina in zijn huidige vorm te bekijken en vervolgens indexering aan te vragen.
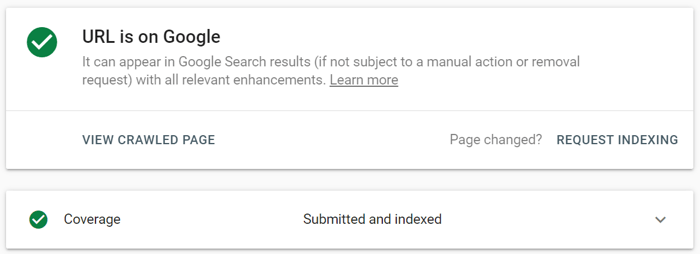
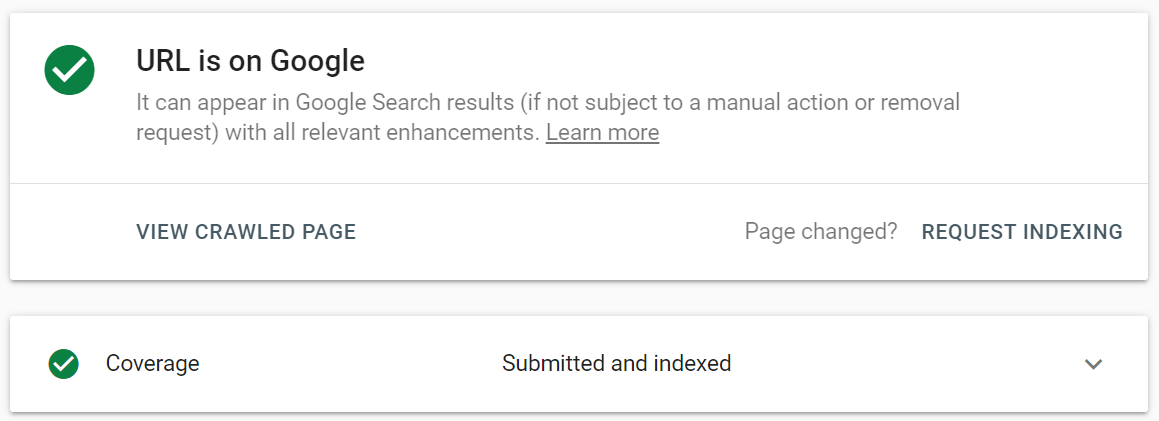
Met de URL-inspectietool kunt u het rapport uitbreiden voor meer details, live URL's testen en indexering aanvragen.
Houd er rekening mee dat u het opnieuw crawlen niet hoeft af te dwingen wanneer u iets op uw website wijzigt. Overweeg opnieuw te crawlen als de wijzigingen serieus zijn: stel dat u uw site van http naar https heeft verplaatst, gestructureerde gegevens heeft toegevoegd of een geweldige inhoudsoptimalisatie heeft uitgevoerd, een urgent blogbericht heeft gepubliceerd dat u sneller op Google wilt laten verschijnen, enz. Houd er rekening mee dat Google een limiet heeft op het aantal recrawl-acties per maand, maak er dus geen misbruik van. Bovendien geven de meeste CMS alle wijzigingen door aan Google zodra u ze aanbrengt, dus u hoeft niet de moeite te nemen om opnieuw te crawlen als u een CMS gebruikt (zoals Shopify of WordPress).
Het opnieuw crawlen kan enkele dagen tot enkele weken duren, afhankelijk van hoe vaak de crawler de pagina's bezoekt. Meerdere keren een recrawl aanvragen zal het proces niet versnellen. Als u een enorm aantal URL's opnieuw moet crawlen, dient u een sitemap in in plaats van elke URL handmatig toe te voegen aan de URL-inspectietool.
Dezelfde optie is beschikbaar in Bing Webmaster Tools. Kies gewoon de sectie Mijn site configureren in uw dashboard en klik op URL's indienen . Vul de URL in die u opnieuw wilt indexeren en Bing zal deze binnen enkele minuten crawlen. Met de tool kunnen webmasters voor de meeste sites tot 10.000 URL's per dag indienen.
Er kunnen veel dingen gebeuren op internet, en de meeste zullen uw rankings waarschijnlijk beter of slechter beïnvloeden. Daarom zouden regelmatige technische audits van uw website een essentieel onderdeel moeten zijn van uw SEO-strategie.
U kunt bijvoorbeeld technische SEO-audits automatiseren in WebSite Auditor . Maak gewoon een Rebuild Project- taak en stel de schema-instellingen in (bijvoorbeeld een keer per maand) om uw website automatisch opnieuw te laten crawlen door de tool en de nieuwe gegevens op te halen.
Als u de resultaten van de audit wilt delen met uw klanten of collega's, kiest u een van de downloadbare SEO-rapportagesjablonen van de WebSite Auditor of maakt u een aangepaste sjabloon.
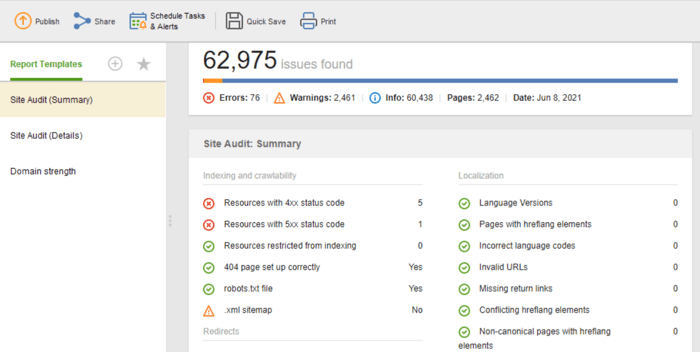
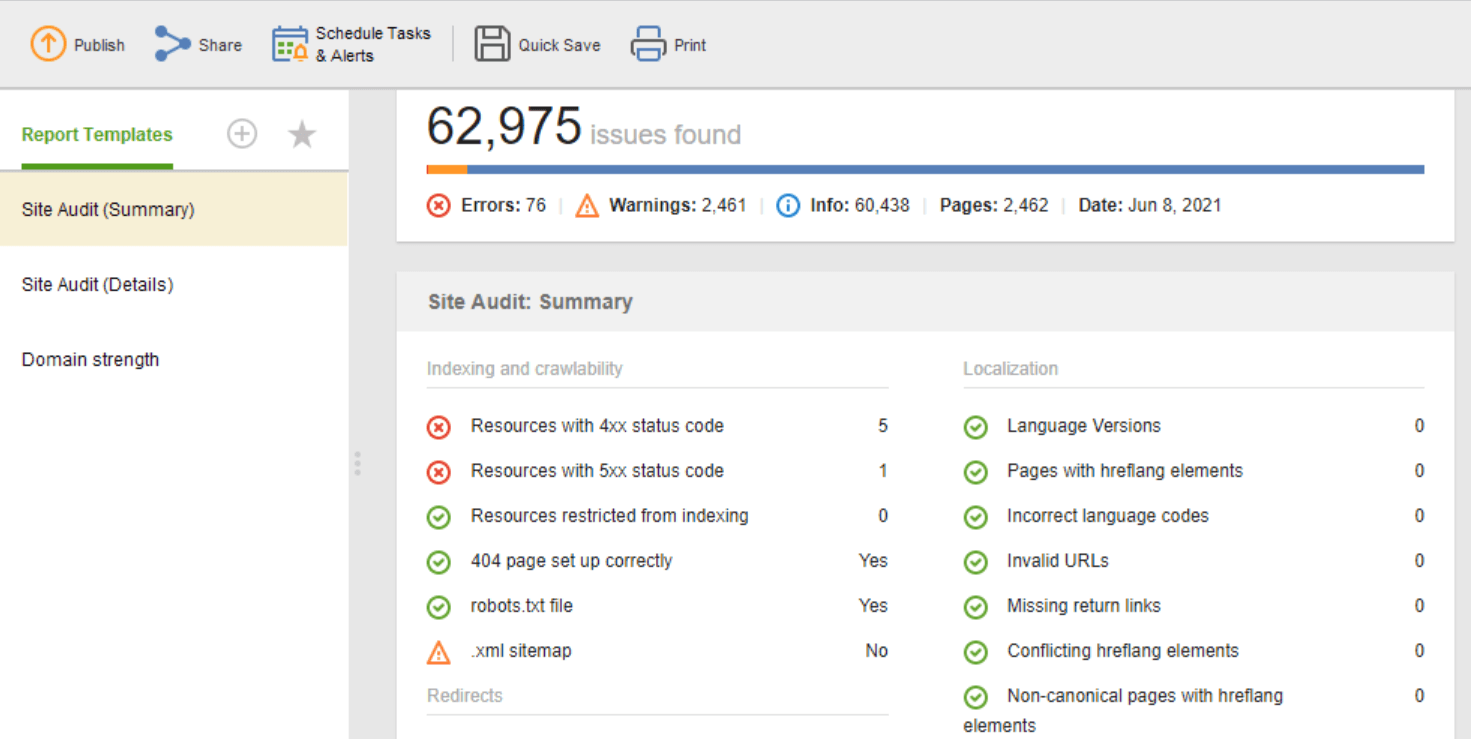
De sjabloon Site Audit (Samenvatting) is geweldig voor website-editors om de reikwijdte van het optimalisatiewerk te zien. De sjabloon Site Audit (Details) is meer verklarend en beschrijft elk probleem en waarom het belangrijk is om het op te lossen. In Website Auditor kunt u het site-auditrapport aanpassen om de gegevens te verkrijgen die u regelmatig moet controleren (indexering, verbroken links, op de pagina, enz.). Exporteer vervolgens als CSV/PDF of kopieer en plak alle gegevens in een spreadsheet bij de hand het over aan ontwikkelaars voor fixes.
Bovendien kunt u een volledige lijst met technische SEO-problemen op elke website automatisch verzamelen in een Site Audit-rapport in onze WebSite Auditor. Bovendien geeft een gedetailleerd rapport uitleg over elk probleem en hoe het kan worden opgelost.
Dit zijn de basisstappen van een regelmatige technische site-audit. Ik hoop dat de gids op de beste manier beschrijft welke tools je nodig hebt om een grondige site-audit uit te voeren, op welke SEO-aspecten je moet letten en welke preventieve maatregelen je moet nemen om een goede SEO-gezondheid van je website te behouden.
Wat is technische SEO?
Technische SEO houdt zich bezig met de optimalisatie van technische aspecten van een website die zoekbots helpen om effectiever toegang te krijgen tot uw pagina's. Technische SEO omvat crawlen, indexeren, problemen aan de serverzijde, pagina-ervaring, het genereren van metatags, sitestructuur.
Hoe voer je een technische SEO-audit uit?
Technische SEO-audit begint met het verzamelen van alle URL's en het analyseren van de algehele structuur van uw website. Vervolgens controleert u de toegankelijkheid van de pagina's, de laadsnelheid, tags, details op de pagina, enz. De technische SEO-audittools variëren van gratis webmastertools tot SEO-spiders, logbestandanalyzers, enz.
Wanneer moet ik mijn site controleren?
Technische SEO-audits kunnen verschillende doelen nastreven. Misschien wilt u een website controleren voordat deze wordt gelanceerd of tijdens het lopende optimalisatieproces. In andere gevallen implementeert u mogelijk sitemigraties of wilt u Google-sancties opheffen. Per geval zullen de reikwijdte en methoden van technische audits verschillen.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |