40668
•
10-minute read
•


Indexation of site pages is what the search engine optimization process starts with. Letting engine bots access your content signifies that your pages are ready for visitors, they don't have any technical issues, and you want them to show up in SERPs, so all-embracing indexation sounds like a huge benefit at first sight.
However, certain types of pages would better be kept away from SERPs to secure your rankings. Which means you need to hide them from indexing. In this post, I’ll guide you through the types of content to hide from search engines and show you how to do it.
Let’s get down to business without further ado. Here’s the list of pages you’d better hide from search engines, so as not to make them appear in SERPs.
Protecting content from direct search traffic is a must when a page holds personal information. These are the pages with confidential company details, information about alpha products, user profiles’ info, private correspondence, payment data, etc. As private content should be hidden from anyone else but the data owner, Google (or any search engine) shouldn’t make these pages visible to wider audiences.
In case a login form is placed not on a homepage but a separate page, there’s no real need to show this page in SERPs. Such pages do not carry any additional value for users, which may be considered thin content.
These are the pages users see after a successful action on a website, be that a purchase, registration, or anything else. These pages are also likely to have thin content and carry little to no additional value for searchers.
The content on this type of pages duplicates that of the main pages on your website, meaning these pages would be treated as total content duplicates if crawled and indexed.
This is a common problem for big ecommerce websites which have many products that differ only in size or color. Google may not manage to tell the difference between these and treat them as content duplicates.
When users come to your website from SERPs, they expect to click your link and find the answer to their query. Not another internal SERP with a bunch of links. So if your internal SERPs get to index, they are likely to bring nothing but low time on page and a high bounce rate.
If your blog has all the posts written by a single author, then the author’s bio page is a pure duplicate of a blog homepage.
Much like login pages, subscription forms usually feature nothing but the form to enter your data to subscribe. Thus the page a) is empty, b) delivers no value to users. That’s why you have to restrict search engines from pulling them to SERPs.
A rule of thumb: pages that are in the process of development must be kept away from search engine crawlers until they are fully ready for visitors.
Mirror pages are identical copies of your pages on a separate server/location. They will be considered technical duplicates if crawled and indexed.
Special offers and ad pages are only meant to be visible to users after they complete any special actions or during a certain time period (special offers, events, etc.). After the event is over, these pages don’t have to be seen by anyone, including search engines.
And now the question is: how to hide all the above-mentioned pages from pesky spiders and keep the rest of your website visible the way it should be?
As you set up the instructions for search engines, you have two options. You can restrict crawling, or you can restrict the indexing of a page.
Possibly, the simplest and most direct way to restrict search engine crawlers from accessing your pages is by creating a robots.txt file. Robots.txt files let you proactively keep all unwanted content out of the search results. With this file, you can restrict access to a single page, a whole directory, or even a single image or file.


The procedure is pretty easy. You just create a .txt file that has the following fields:
Note that some crawlers (for example Google) also support an additional field called Allow:. As the name implies, Allow: lets you explicitly list the files/folders that can be crawled.
Here are some basic examples of robots.txt files explained.


* in the User-agent line means that all search engine bots are instructed not to crawl any of your site pages, which is indicated by /. Most likely, that’s what you'd rather prefer to avoid, but now you get the idea.


By the example above, you restrict Google's Image bot from crawling your images in the selected directory.
You can find more instructions on how to write such files manually in the Google Developer’s guide.
But the process of creating robots.txt can be fully automated – there is a wide range of tools that are capable of creating such files. For example, WebSite Auditor can easily compile a robots.txt file for your website.
As you launch the tool and create a project for your website, go to Site Structure > Pages, click the wrench icon, and select Robots.txt.
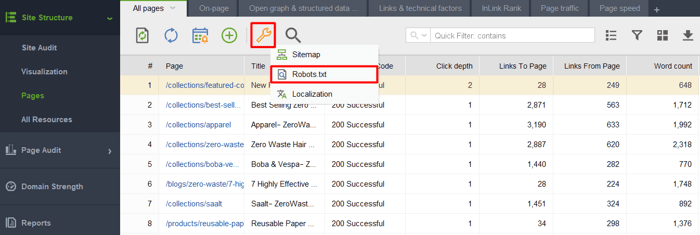
Then click Add Rule and specify the instructions. Choose a search bot and a directory or page you want to restrict crawling for.

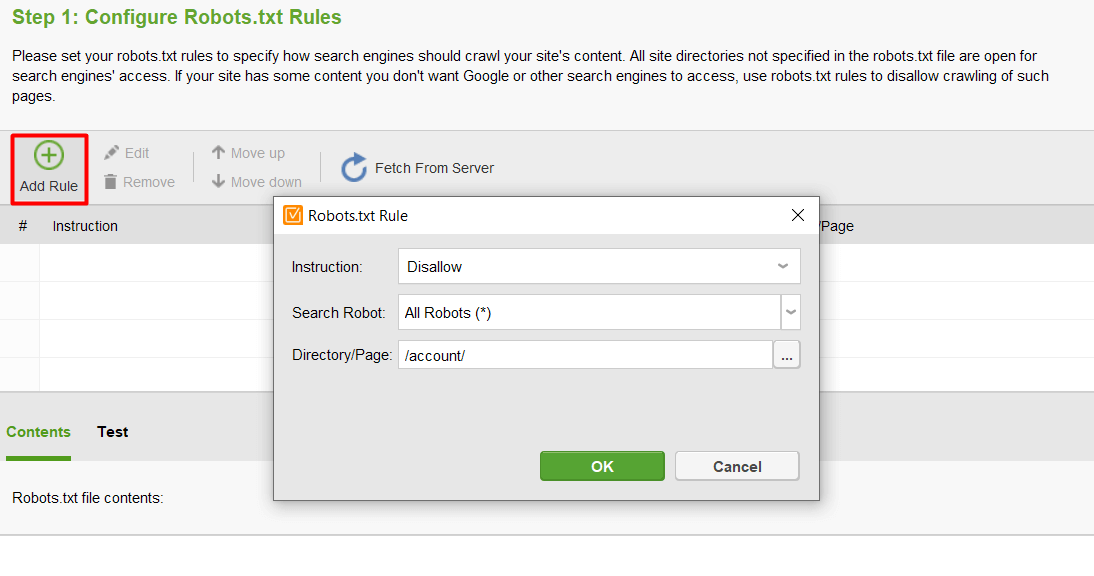
Once you’re done with all your settings, click Next to let the tool generate a robots.txt file you can then upload to your website.
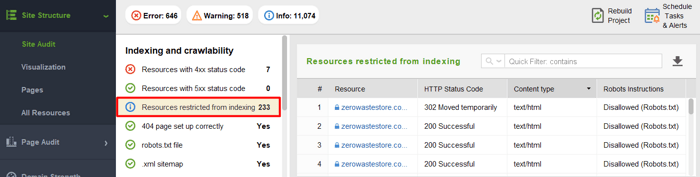
To see the resources blocked from crawling and make sure you haven’t disallowed anything that should be crawled, go to Site Structure > Site Audit and check the section Resources restricted from indexing:

Also, mind that the robots.txt protocol is purely advisory. It is not a lock on your site pages but more like a "Private - keep out". Robots.txt can prevent "law-abiding" bots (e.g. Google, Yahoo!, and Bing bots) from accessing your content. However, malicious bots simply ignore it and go through your content anyway. So there's a risk that your private data may be scraped, compiled, and re-utilized under the guise of fair use. If you want to keep your content 100% safe, you should introduce more secure measures (e.g. adding registration on a site, hiding content under a password, etc.).
Here are the most common mistakes people make when creating robots.txt files. Read this part carefully.
1) Using uppercase in the file name. The file’s name is robots.txt. Period. Not Robots.txt, and not ROBOTS.txt
2) Not placing robots.txt file to the main directory
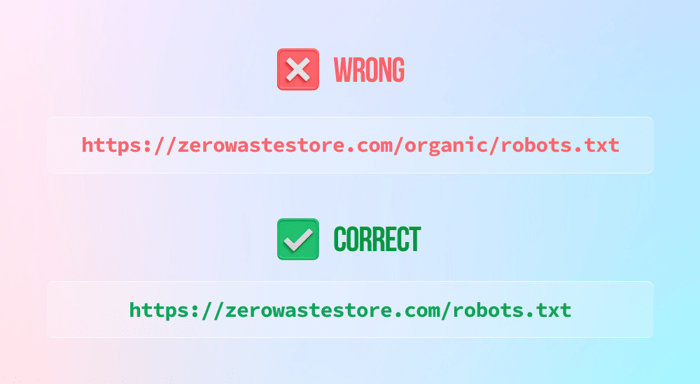

3) Blocking your entire website (unless you want to) by leaving the disallow instruction the following way


4) Incorrectly specifying the user-agent


5) Mentioning several catalogs per one disallow line. Each page or directory needs a separate line


6) Leaving the user-agent line empty
7) Listing all the files within a directory. If it’s the whole directory you’re hiding, you don’t need to bother with listing every single file


8) Not mentioning the disallow instructions line at all


9) Not stating the sitemap at the bottom of the robots.txt file
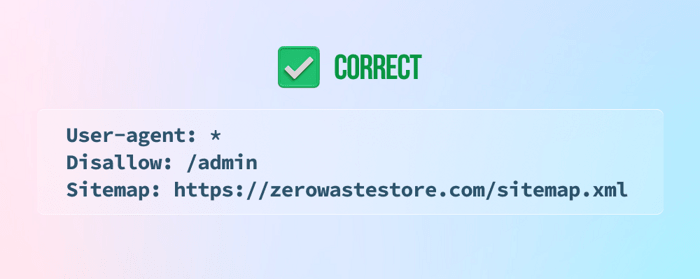

10) Adding noindex instructions to the file
Using a robots noindex meta tag or the X-Robots-tag will let search engine bots crawl and access your page, but prevent the page from getting into the index, i.e. from appearing in search results.
Now let’s look closer at each option.
A robots noindex meta tag is placed in the HTML source of your page (<head> section). The process of creating these tags requires only a tiny bit of technical know-how and can be easily done even by a junior SEO.
When Google bot fetches the page, it sees a noindex meta tag and doesn’t include this page in the web index. The page is still crawled and exists at the given URL, but will not appear in search results no matter how often it is linked to from any other page.
<meta name="robots" content="index, follow">
Adding this meta tag into the HTML source of your page tells a search engine bot to index this page and all the links going from that page.
<meta name="robots" content="index, nofollow">
By changing 'follow' to 'nofollow' you influence the behavior of a search engine bot. The above-mentioned tag configuration instructs a search engine to index a page but not to follow any links that are placed on it.
<meta name="robots" content="noindex, follow">
This meta tag tells a search engine bot to ignore the page it’s placed on, but to follow all the links placed on it.
<meta name="robots" content="noindex, nofollow">
This tag placed on a page means that neither the page nor the links this page contains will be followed or indexed.
Besides a robots noindex meta tag, you can hide a page by setting up an HTTP header response with an X-Robots-Tag with a noindex or none value.
In addition to pages and HTML elements, X-Robots-Tag lets you noindex separate PDF files, videos, images, or any other non-HTML files where using robots meta tags is not possible.
The mechanism is pretty much like that of a noindex tag. Once a search bot comes to a page, the HTTP response returns an X-Robots-Tag header with noindex instructions. A page or a file is still crawled, but will not appear in search results.
This is the most common example of the HTTP response with the instruction not to index a page.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
You can specify the type of search bot if you need to hide your page from certain bots. The example below shows how to hide a page from any other search engine but Google and restrict all the bots from following the links on that page:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
If you don’t specify the robot type, the instructions will be valid for all types of crawlers.
To restrict indexing of certain types of files across your entire website, you can add the X-Robots-Tag response instructions to the configuration files of your site's web server software.
This is how you restrict all PDF files on an Apache-based server:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
And these are the same instructions for NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
To restrict indexing of one single element, the pattern is the following for Apache:
# the htaccess file must be placed in the directory of the matched file.
<Files "unicorn.pdf">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
And this is how you restrict indexing of one element for NGINX:
location = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Although a robots noindex tag seems an easier solution to restrict your pages from indexing, there are some cases when using an X-Robots-Tag for pages is a better option:
Still, remember that it’s only Google who follows X-Robots-Tag instructions for sure. As for the rest of the search engines, there’s no guarantee that they will interpret the tag correctly. For example, Seznam doesn’t support x‑robots-tags at all. So if you’re planning your website to appear across various search engines, you’ll need to use a robots noindex tag in the HTML snippets.
The most common mistakes users make when working with the noindex tags are the following:
1) Adding a noindexed page or element to the robots.txt file. Robots.txt restricts crawling, thus search bots will not come to the page and see the noindex directives. This means your page may get indexed without content and still appear in search results.
To check if any of your papes with a noindex tag got into the robots.txt file, check the Robots instructions column in the Site Structure > Pages section of WebSite Auditor.
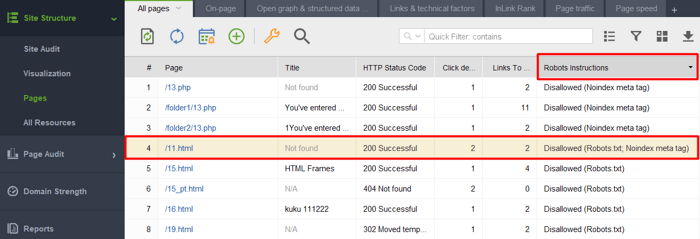
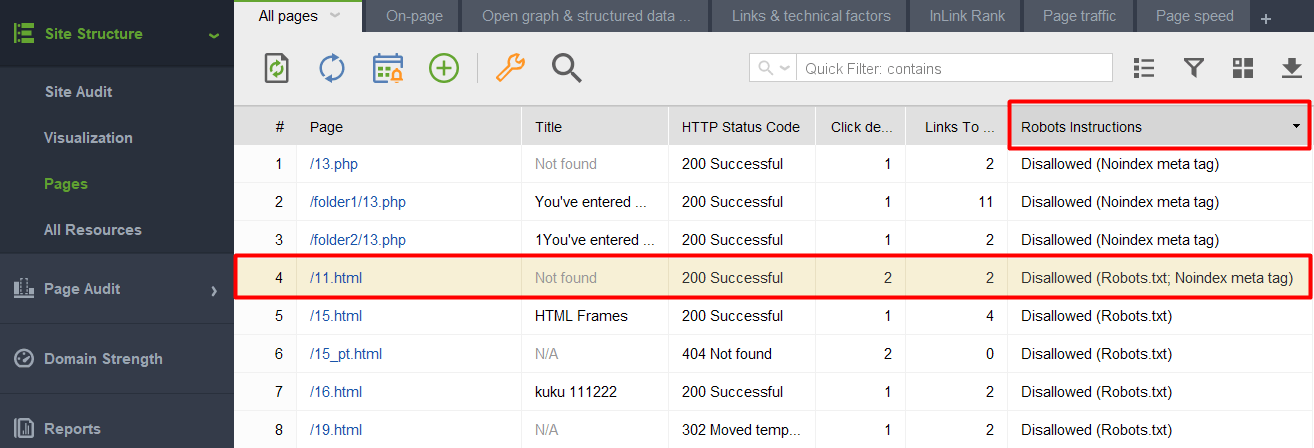
Note: Don’t forget to enable expert options and untick the Follow robots.txt instruction option when assembling your project to make the tool see the instructions but not to follow them.
2) Using uppercase in tag directives. According to Google, all the directives are case-sensitive, so be careful.
Now that everything is more or less clear with the main content indexing issues, let’s move on to several non-standard cases that deserve special mention.
1) Make sure that the pages you don’t want to be indexed are not included in your sitemap. A sitemap is actually the way to tell search engines where to go first when crawling your website. And there’s no reason to ask search bots to visit the pages you don’t want them to see.
2) Still, if you need to deindex a page that is already present in the sitemap, don’t remove a page from the sitemap until it is recrawled and deindexed by search robots. Otherwise, deindexation may take more time than expected.
3) Protect the pages that contain private data with passwords. Password protection is the most reliable way to hide sensitive content even from those bots that don’t follow the robots.txt instructions. Search engines don’t know your passwords, thus they will not get to the page, see the sensitive content, and bring the page to a SERP. Using an open source password manager can simplify the process of creating and managing strong, unique passwords for all your protected pages.
4) To make search bots noindex the page itself but follow all the links a page has and index the content at those URLs, set up the following directive
<meta name="robots" content="noindex, follow">
This is a common practice for internal search results pages, which contain a lot of useful links but don’t carry any value themselves.
5) Indexing restrictions may be specified for a specific robot. For example, you can lock your page from news bots, image bots, etc. The bots’ names can be specified for any type of instructions, be that a robots.txt file, robots meta tag, or X-Robots-Tag.
For example, you can hide your pages specifically from ChatGPT bot with robots.txt. Since the announcement of ChatGPT plugins and GPT-4 (which means OpenAI can now get info from the web), website owners have been concerned about the usage of their content. The issues of citation, plagiarism, and copyright became acute for many sites.
Now the SEO world is split: some say we should block GPTBot from accessing our sites, others say the opposite, and the third say we need to wait until something becomes clearer. In any case, you have a choice.
And if you firmly believe you need to block GPTBot, here is how you can do that:
If you want to close your whole site.
User-agent: GPTBot
Disallow: /
If you want to close only a particular part of your site.
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/
6) Do not use a noindex tag in A/B tests when a part of your users is redirected from page A to page B. As if noindex is combined with 301 (permanent) redirect, then search engines will get the following signals:
In the result, both pages A and B disappear from the index.
To set up your A/B test correctly, use a 302 redirect (which is temporary) instead of 301. This will let search engines keep the old page in index and bring it back as you finish the test. If you’re testing several versions of a page (A/B/C/D etc.), then use rel=canonical tag to mark the canonical version of a page that should get into SERPs.
7) Use a noindex tag to hide temporary landing pages. If you’re hiding pages with special offers, ad pages, discounts, or any type of content that should not leak, then disallowing this content with a robots.txt file is not the best idea. As super-curious users can still view these pages in your robots.txt file. Using noindex is better in this case, so as not to accidentally compromise the “secret” URL in public.
Now you know the basics of how to find and hide certain pages of your website from the attention of search engines' bots. And, as you see, the process is actually easy. Just don’t mix several types of instructions on a single page and be careful so as not to hide the pages that do have to appear in search.
Have I missed anything? Share your questions in the comments.








