Free Robots.txt generator tool making your robots.txt file instantly
Enter your e-mail to start the download. We will also send the download links to
your email.
Easily create a smart robots.txt file for your website, so that
you can always control the way search engines crawl your site. Instruct
crawlers which areas they are allowed to visit and index and thus:
- Eliminate any duplicate content issues.
- Hide temporary, outdated and no longer relevant content.
- Cover up your site's technical nuts-and-bolts that may not seem friendly to search engines.
- Optimize the way your site gets crawled and indexed.
Any of us SEOs is striving for full control of what content of your site falls under search engines eyes. With a suite of webmaster tools in WebSite Auditor, this task turns into nothing more than a cakewalk!
A robots.txt file lets you keep certain pages of your site away from search engines' bot. WebSite Auditor allows creating your robots text file and managing its updates with only a few clicks right from the tool. You can easily add allow / disallow instructions without fears for syntax, set different directives for a variety of website crawlers and user-agents, easily manage updates, and upload the robots text file via FTP right from the robots.txt generator.
Making a robots.txt has never been so easy
To try the robots.txt file generator in WebSite Auditor, just start the tool, paste the URL of your site to create a project, and proceed to Pages > Website Tools.
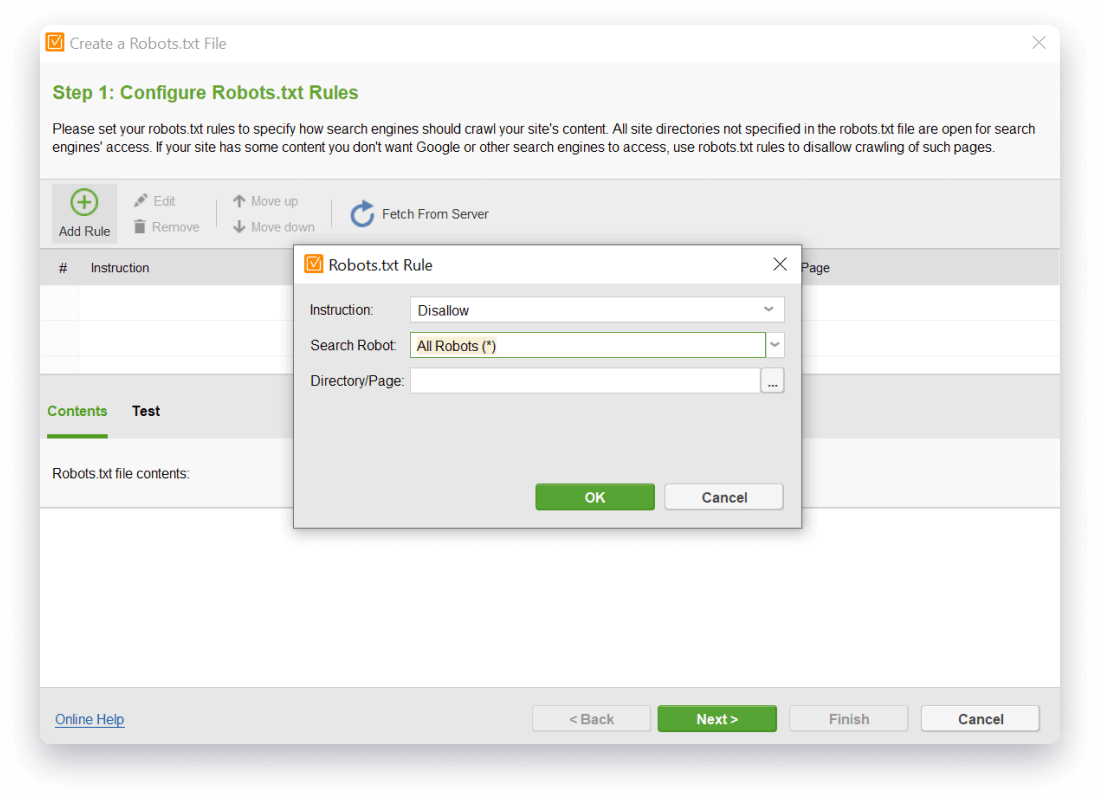
Step 1. Select search engines whose robots you want to prevent from visiting some of your
pages.
Step 2. Select your site's directories and pages that you don't want to be indexed.
Step 3. Let the robots.txt generator compile your file and instantly upload it onto a website via FTP or save it on your computer.
What's robots.txt file and why your site needs it?
Most webmasters have an idea of what a robots.txt file is and why it's crucial for any website, but let's summarize the main points.
A robots.txt file is a way for you to tell search engines which areas of your site they should or should not visit and index. In fact, robots.txt file is not compulsory, website crawlers will be able to scan your website without it. However, it can be helpful when you have plenty of resources and want to optimize the way crawlers go through your pages.
A robot.txt file includes a list of directives for search engines to crawl or not to crawl certain pages on your website. The robots.txt file should be located in the root directory of your website. For example, you can type in yourdomainname.com/robots.txt and see whether you have it on the site.
The syntax is pretty simple. Usually, robots.txt file contains Allow and Disallow rules and specifies the user-agent to which the directive applies. Also, you can indicate the path to your XML Sitemap.
User-agent: *
Allow: /
All website crawlers are allowed to crawl all pages.
User-agent: Bingbot
Disallow: /sitepoint-special-offer.html$
Bing bot is not allowed to crawl this URL.
The wildcard * next to User-agent means that the directive applies to all search engines. The slash / means the path after the mark to which the rule applies. The $ sign means the end of the URL. By using # symbol you can leave comments inside the text file. By the way, robots.txt file is case-sensitive, so make sure to write it with starting lowercase and check the URLs inside, as well. Only valid lines are implemented by a crawler. In case of conflicting rules, the least restrictive rule is applied.
You can create a robots.txt file using a plain-text editing tool, like Notepad. Some hosting platforms allow creating robots.txt files right in the admin panel.
Alternatively, create and edit such files with a special robots.txt file generator even without in-depth technical knowledge.
Try it free today!
Unwrap full functionality of Website Auditor SEO spider in Professional and Enterprise editions.
Control your website's crawling with robots.txt
- Load your current robots.txt into WebSite Auditor right from the server to view it and edit.
If you want to know your current robots.txt instructions to test it or edit further, do this with a single mouse click in the robots.txt file generator. Just hit Fetch From Server, and in an instant, the tool will collect all the information in the workspace. Hit Next, and the text file will be saved to the hard drive (or any location you define from your Preferences > Publishing Options).
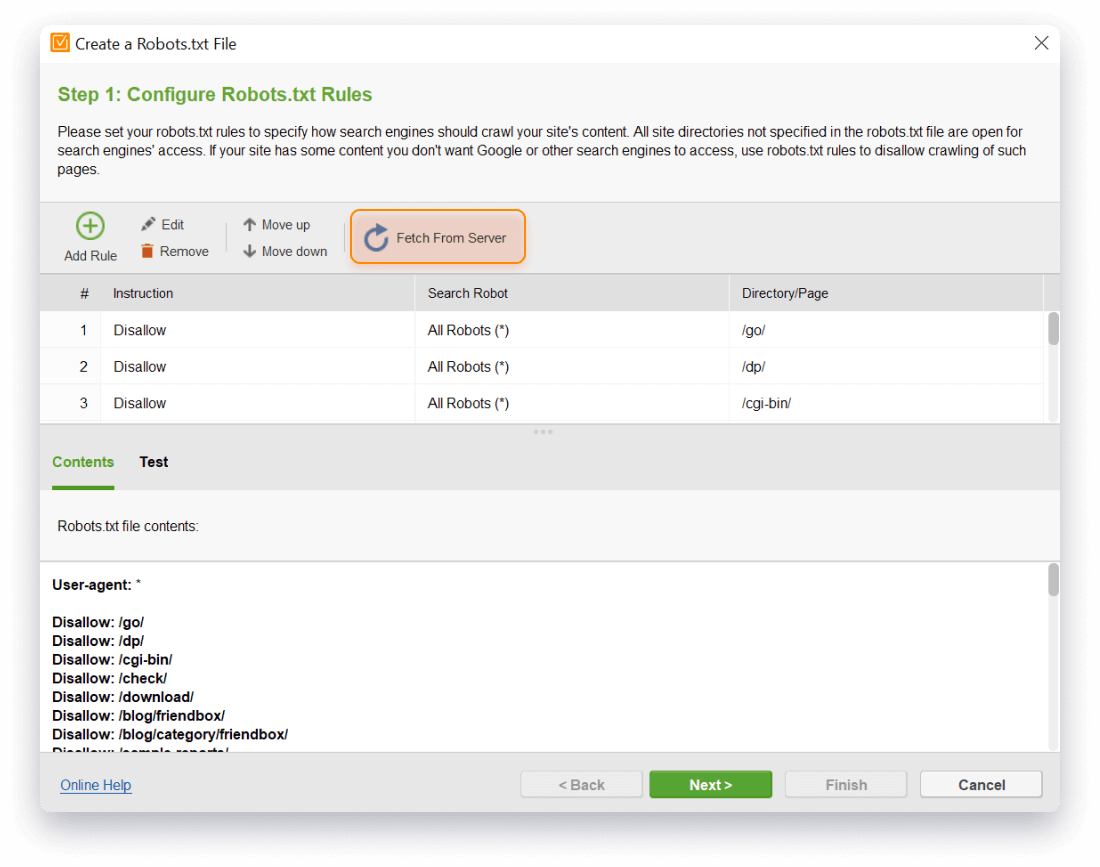
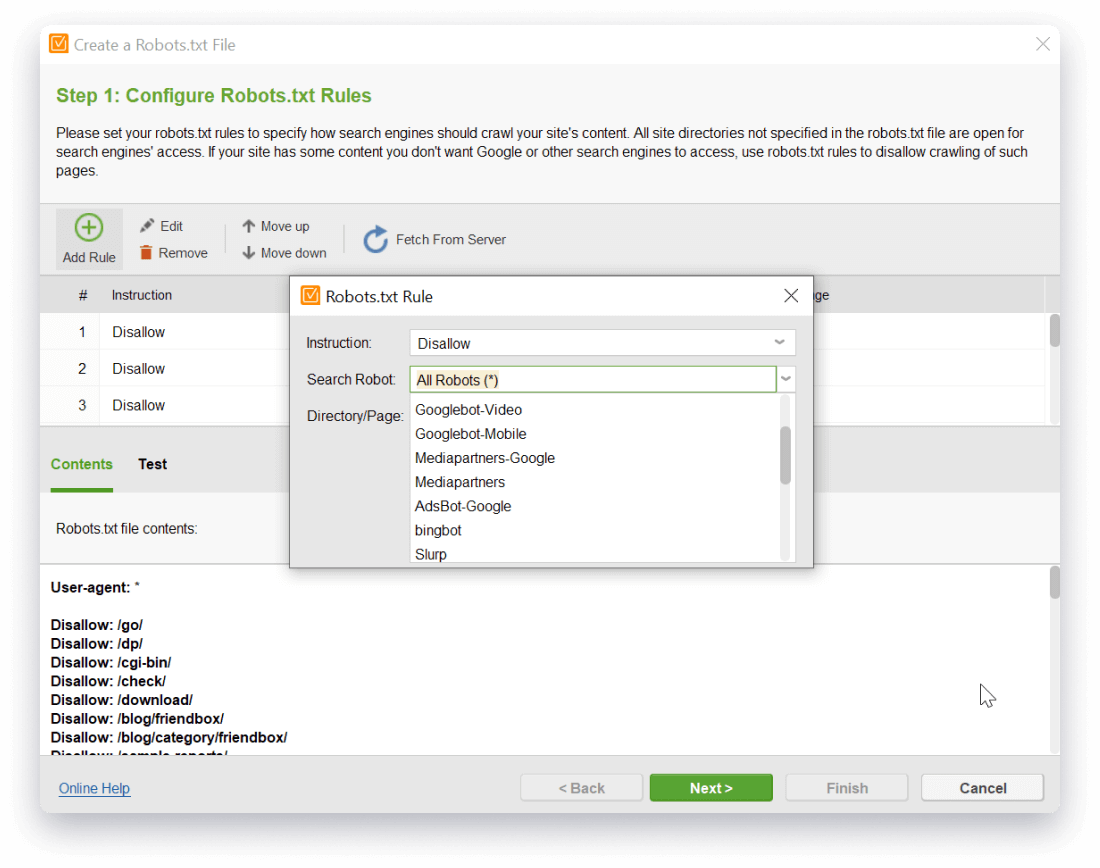
- Keep your robots.txt 100% compatible with Google, Yahoo, Bing and other website crawlers.
Sometimes, you need to leave your pages available to only specific search bots. For example, you may want to leave a page open only to Mediapartners bot to render ads relevant to visitors' search history. So, in the robots.txt generator, specify the settings for the specific search bot only. Select the Instruction and the Search Bot from the drop-down arrow menu and complete to add the rule. You will see the directive and the respective user-agent below in the robots.txt file contents.
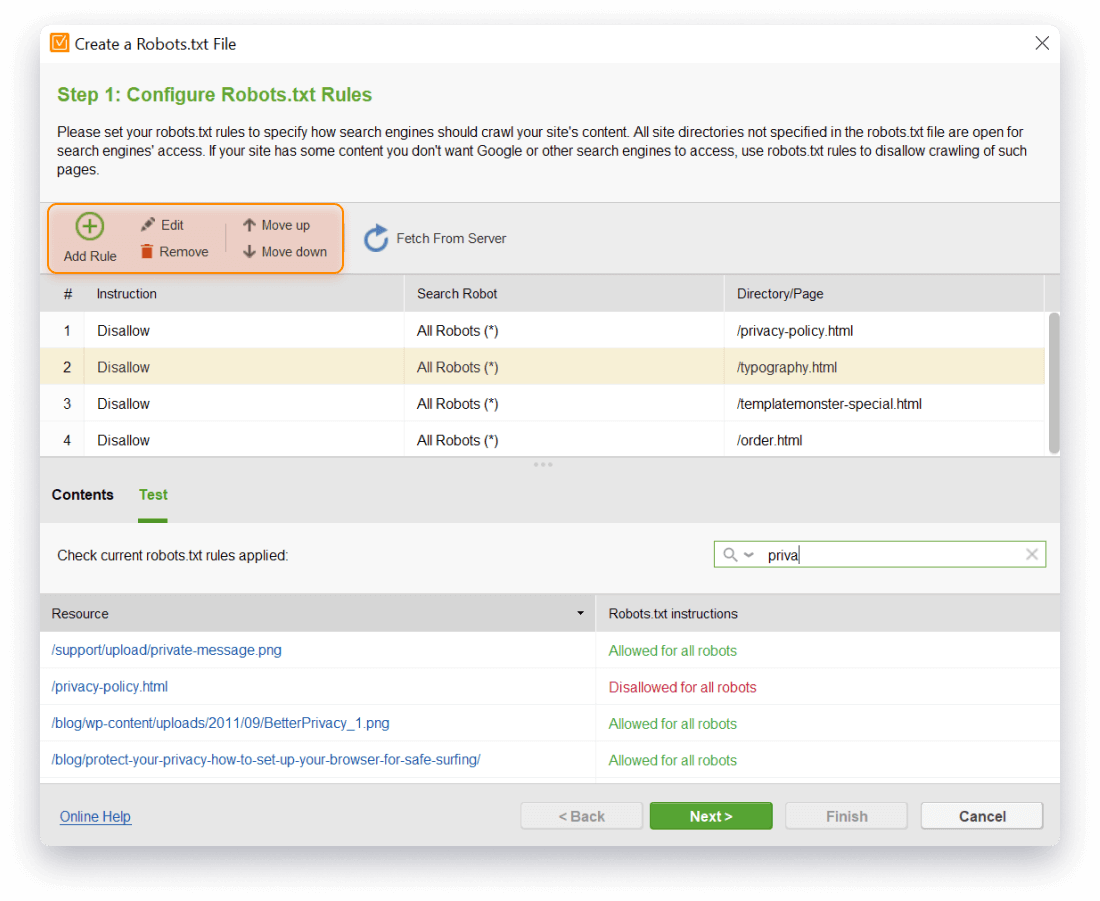
- Edit and check your robots.txt file before uploading it onto a website, to make sure it works just as you want it to.
Keep track of all the changes on your website and modify your robots.txt files in an instant. You can edit, remove, move the rule up or down your text file using the menu buttons. In your robots.txt generator, switch to Test to see which directive is applied to a particular URL.
Note. Although robots.txt file is aimed to instruct user-agents how to crawl your website, it does not guarantee that a disallowed web page will not appear in search results. The page might be crawled and appear in the index when it is linked from other pages, even if it's been disallowed in your robots.txt file. If you want to be 100% sure that a page is restricted from index, use the noindex meta tag.
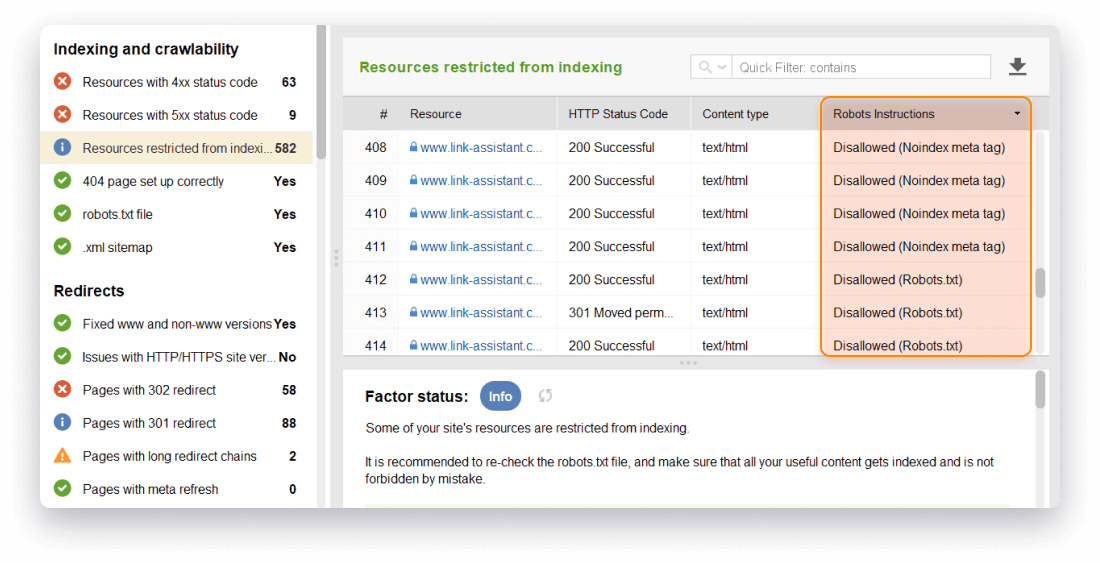
The tool allows checking which URLs and resources have been restricted from indexing by different
methods. Go to Site Audit > Crawling and Indexing, and check the Resources restricted from
indexing to see whether it's been disallowed by a robots directive or by a noindex meta tag.
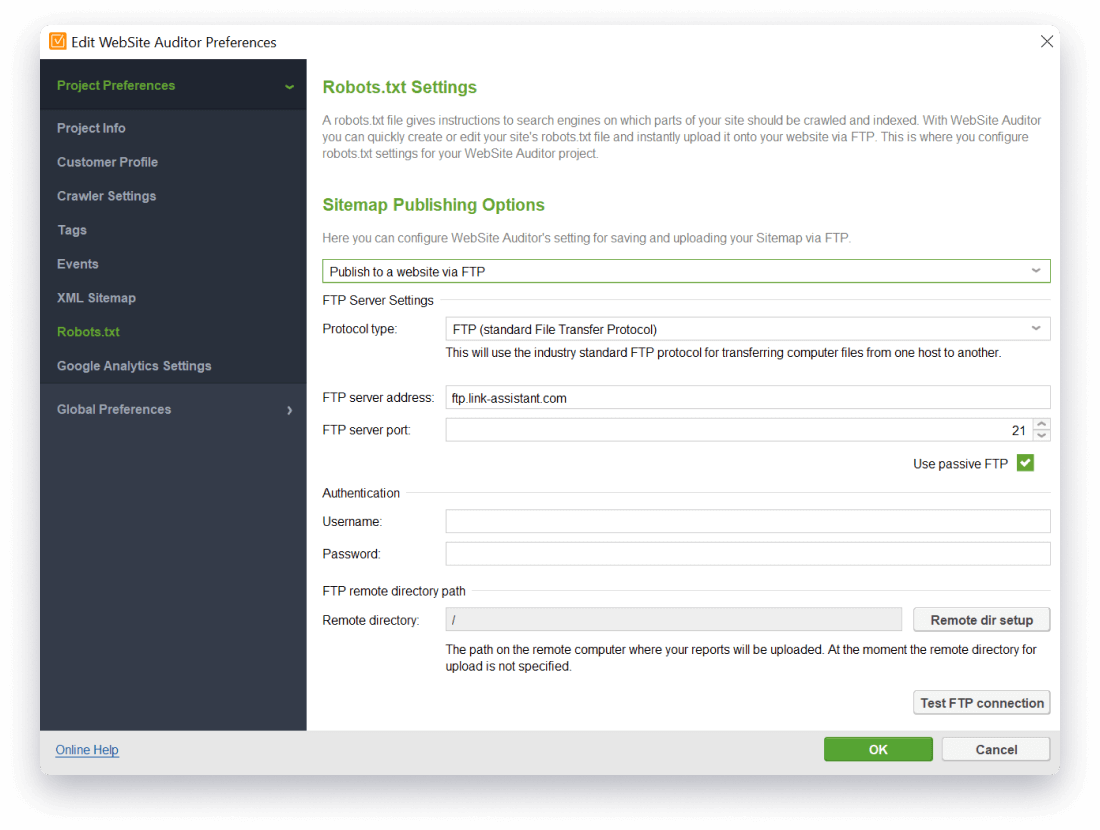
- Automatically upload your robots.txt file onto a website via FTP without switching to any other tools.
To upload your robots.txt file to the site, first configure the FTP settings in Project Preferences > Robots.txt settings.
Simple robots.txt generation in a single workflow
With robots.txt generator from WebSite Auditor, you will apply easy-to-use desktop software instead of installing complicated robots.txt generating tools on your server. Besides, the tool lets you scale your tasks in an SEO agency or for cross-domain services: create an unlimited number of robots.txt files for multiple websites with unique settings for each of them.
WebSite Auditor is a full-cycle suite of SEO and webmaster tools to keep your website up-to-date and
well-optimized:
- Fine-tunes your website's structure and HTML-coding.
- Creates compelling, search engine friendly content for your pages.
- Builds a comprehensive XML Sitemap for your site.

Try it free today!
Unwrap full functionality of Website Auditor SEO spider in Professional and Enterprise editions.