5058
•
11-minute read


A week ago, I came across a fascinating LinkedIn post by SEO consultant Geoff Kenyon, where he described something most content creators have never heard of — an invisible mark that Google embeds into everything its AI tools generate:
Not metadata you can strip. Not a label you can edit out. Something woven into the content itself!
Here’s an example of this hidden mark:


This mark is called SynthID and Google isn't the only one doing it.
In this guide, I've pulled together the most up-to-date information on how AI detects AI content, and what SEO can do about it.
SynthID is a watermarking technology developed by Google DeepMind. It embeds an invisible digital watermark into AI-generated content — images, video, audio, and text — at the moment the content is created. The watermark doesn't degrade quality and isn't visible to the human eye, but it is detectable by machines.


Think of it like a serial number stamped into content at birth. You can neither see nor read it, but it's there.
In early 2026, over 10 billion pieces of content have already been watermarked with SynthID.
It's embedded across Google's AI tools including:
But surely, Google isn't alone in building this infrastructure to detect AI content. Over 200 organizations (including Microsoft, Adobe, OpenAI, Meta, BBC, and Amazon) have joined a coalition called C2PA, which developed an open standard called Content Credentials: a kind of digital nutrition label that records who created a piece of content, which tools were used, and whether AI was involved.
OpenAI already embeds these credentials in images generated through ChatGPT and DALL·E.
The approaches differ technically, but the direction is the same across the industry: knowing where content came from is becoming a basic requirement, not a nice-to-have.
This is the part that surprises most people. For images, the watermark survives cropping, compression, screenshots, and common filters. For video, every frame gets individually marked, so trimming a clip doesn't help either.
The watermark isn't stored in removable metadata — it's embedded in the content itself. Geoff's post demonstrated this vividly: if you isolate the specific pixel frequencies where SynthID hides in a Gemini-generated image and crank up the contrast, a distinct pattern becomes visible. The mark was there all along; you just couldn't see it at normal settings.
Sure thing, determined users can still degrade the watermark through aggressive image manipulation — extreme color distortion, re-encoding with major adjustments — though this risks degrading the content quality too.
And for text, thoroughly rewriting or translating AI-generated content can significantly reduce the detector's confidence score. It's not impenetrable, but casual use doesn't remove it.
Yes, and this is the part that gets skipped in most conversations about AI detection.
Large language models generate text one token (roughly one word) at a time, assigning each token a probability score based on how likely it is to come next. SynthID adjusts those probability scores in subtle ways to encode a watermark, without noticeably affecting the quality or meaning of the text.
The resulting pattern of word choices, shaped by those adjusted probabilities, is the watermark. A trained detector can compare that pattern against what watermarked and unwatermarked text typically look like, and make a probabilistic judgment about the content's origin.
One important nuance: text watermarking works best on longer, more open-ended responses. It's less effective on short factual answers — like "What's the capital of France?" — because there's less room to adjust word choices without changing the meaning.
If you've been in SEO for more than a few years, you might have heard about Spintax — automated content that shuffled synonyms to create "unique" articles.
It worked for a while, but then Google got better at detecting it. Exact-match keyword stuffing worked, then it didn't. Content farms built for volume worked, then the Panda update arrived.
New to Google algorithm updates? Check out our detailed guide covering everything you need to know.


Each time, the shortcut stopped working not because Google suddenly decided to care, but because the detection infrastructure quietly caught up.
SynthID is the detection infrastructure for the AI content era. It doesn't mean AI content is penalized today. But the pattern of SEO history is consistent: the tools that enable easy abuse tend to develop the tools that eventually neutralize it.
It's tempting to assume this is about penalizing AI content in search. That's not quite the right frame, at least not yet. The more immediate reason is something researchers call model collapse.
Here's the problem in plain terms: AI models learn from data scraped from the internet. As more and more of that internet gets filled with AI-generated content, future models increasingly end up training on AI outputs rather than human writing.
Research published in Nature found that this process causes a degenerative effect: models gradually forget the true diversity of human-generated data, and their outputs become increasingly narrow and distorted over generations.
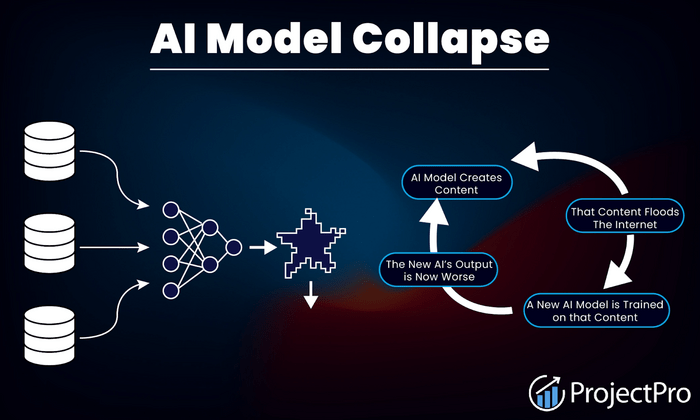
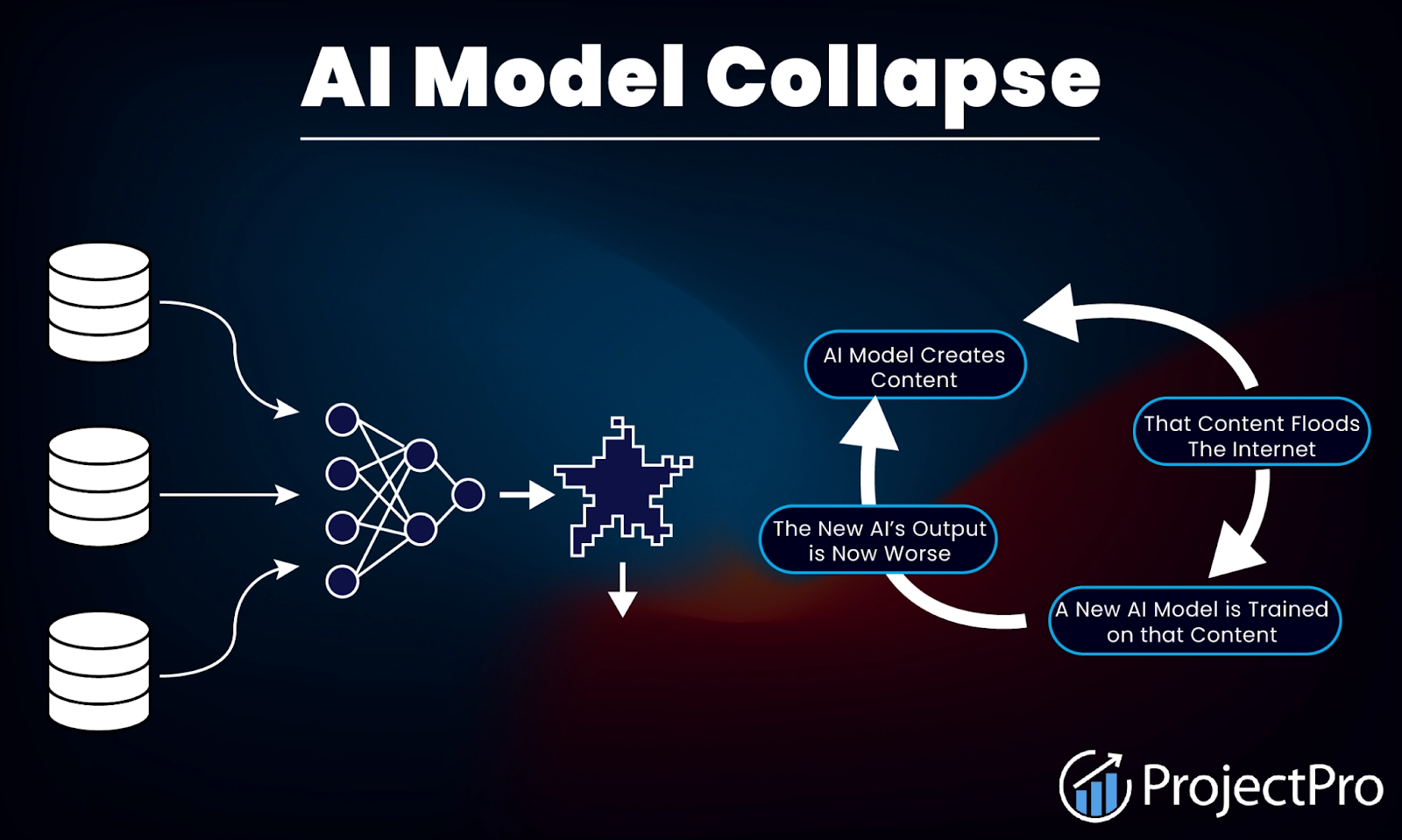
In one experiment, researchers fine-tuned a language model using only AI-generated data. By the fourth generation of retraining, a model asked about medieval architecture was producing unrelated text about jackrabbits. That's model collapse in action.


Watermarking is one of the cleanest solutions to this problem. If you can reliably identify which content was AI-generated, you can filter it out of future training data. Google has open-sourced SynthID's text watermarking so any developer can incorporate it into their own models, meaning the infrastructure for AI content detection is spreading beyond just Google's own tools.
Stop using AI for content entirely? No. That's not the takeaway.
The distinction that matters is between AI as a replacement for original thought versus AI as a tool that supports it. Content that offers genuine original insight — proprietary data, first-hand experience, a perspective that doesn't exist elsewhere — has a structural advantage in a world where AI systems are actively trying to distinguish human from machine.
Here's what that looks like in practice.
Generic content gets detected (and ignored) precisely because it could have been written about any niche by anyone. The antidote is knowing your topic landscape well enough to find the angles nobody else is covering.
RankDots is built for this: it maps the full topic structure of a niche, clusters keywords into coherent subjects, and shows you where real traffic and low competition intersect.
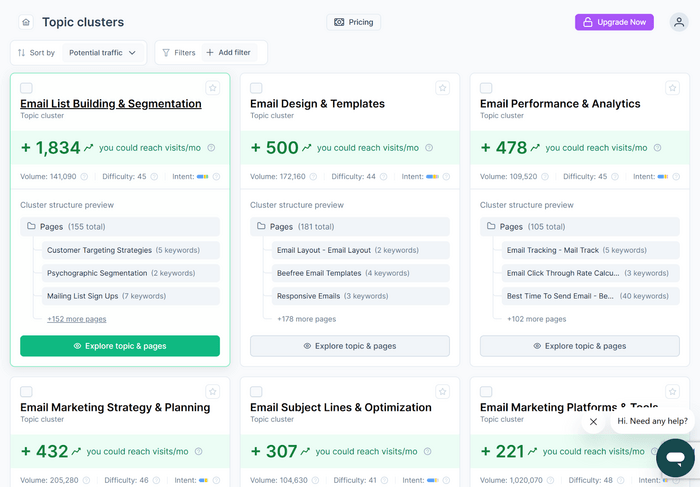
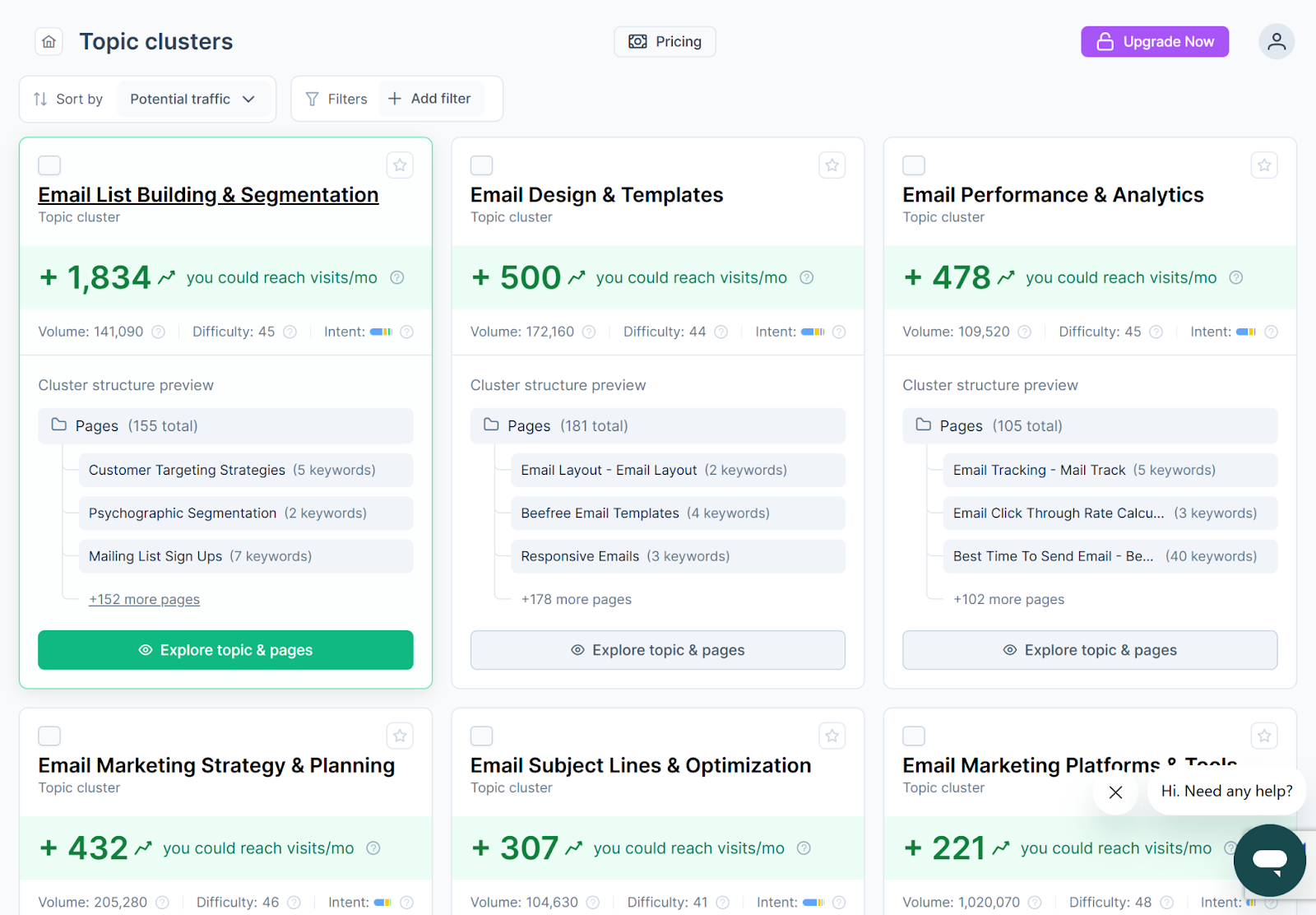
That's your editorial roadmap and it's what separates strategic content from guesswork.
Use AI to pull together background research, generate outlines, and speed up first drafts.
Then bring in what only you can provide: a contrarian take, a case study from your own experience, data you've collected, or an observation from your industry that isn't already on page one. That's the layer detection systems can't replicate, because it didn't exist before you wrote it.
Research from Princeton University found that adding original statistics and source citations to content can boost AI citation rates by 30–40%.
The logic is straightforward: AI systems are looking for extractable, verifiable facts. Generic prose gives them nothing to cite, while a proprietary survey, a client result, or even a simple data point you calculated yourself gives them exactly what they need.
What works best according to the research:
The pattern is consistent across the web: Wikipedia and Reddit are among the most cited domains in AI Overviews and ChatGPT responses, not because they rank well traditionally, but because they contain specific, concrete, human-contributed answers that AI can extract directly. Original beats derivative every time.
If you want to keep tabs on how your brand shows up in AI answers, Reddit monitoring is worth adding to your workflow. Tools like Awario let you track mentions in real time, so you catch every thread where your keyword or company comes up.
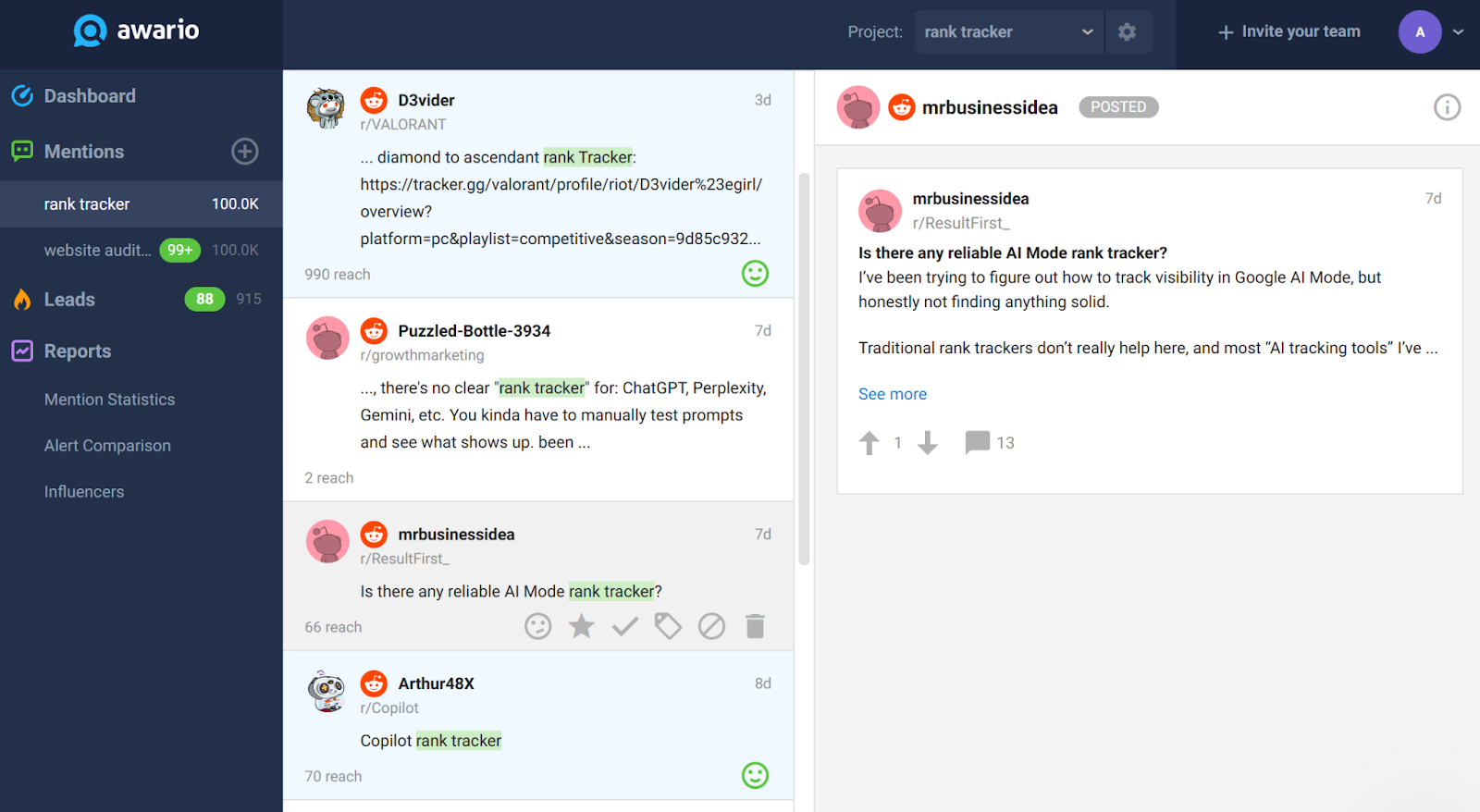
While you're thinking about all this, you might be tempted to run your content through a detector and call it done. That's not a reliable plan, to be honest.
Tools like GPTZero, Turnitin, and Originality.ai exist, but their track record isn't reassuring. In a 2023 peer-reviewed study testing 14 of the most popular detectors, not one hit 80% accuracy and several flagged human-written text as AI. OpenAI launched its own classifier and pulled it months later.
Use these tools for a rough sense-check if you want, but don't treat a passing score as clearance.
Google's E-E-A-T guidelines have always rewarded demonstrable expertise, but they matter more now. A byline attached to a real track record — published work, an author page with actual credentials, a consistent voice across multiple pieces — signals something a watermark detector can't measure: that a person with relevant experience wrote this.
The practical checklist is short:
This matters beyond Google rankings. AI systems pulling citations prefer attributable sources. A claim from "Staff Writer" carries less weight than the same claim from someone with a verifiable history in the field and that gap is only going to widen.
Some teams go beyond editing to actively reduce watermark detectability. Google's own technical documentation confirms the methods that work to varying degrees:
These tactics reduce watermark detectability. They don't make the content more citable, more useful, or more likely to earn links. Passing a detector and being worth citing are two different problems, and the second one is harder to game.
Good SEO content has always come down to one thing: a real person with a real point of view. SynthID and other AI detection methods don't change the game. They just make it easier to see who's actually playing it.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

