12219
•
15-minute read


"Rose is a rose is a rose is a rose."
Gertrude Stein
The famous quote by Gertrude Stein is a fine example that shows how complicated human language can be. The phrase is ambiguous and allows for multiple interpretations. Stein explained the meaning as follows "the poet could use the name of the thing and the thing was really there." A curious human reader can come to a similar conclusion. But can we create a smart algorithm which is really capable of understanding the meaning of human language?
In this article, I will try to shed some light on the way search engines find documents related to a user's query. I will also show some approaches that can be used to extract semantic meaning from a proposition.
Before Google introduced RankBrain, semantic search and all things machine learning, the life of SEOs seemed to be easier. Now we are exposed to a flood of speculative information from industry influencers. To make things worse, Google's spokespersons share obscure bits of information about the quality signals and repeat the "Content is king" mantra. Is there a way to tell assumptions from real facts about the algorithms? The answer is "yes". There are two fields of computer science, which are natural language processing and information retrieval, that address a huge set of problems related to SEO. There exist well-documented algorithms for text classification and retrieval of relevant documents in response to a user query. No guess-work – just pure science.
If you are interested to learn slightly more academic concepts behind "semantic search", "SEO keyword research", "content optimization", and other SEO buzzwords – read on! However, be aware that this article is not going to give you any magic recipe for on-page SEO but rather answer some of the "why" questions you probably have.
Word is the smallest building block of meaning and a logical starting point of our journey. Let's try to find out how words are represented in computer programs. Along the way, I am going to highlight some strengths and weaknesses of these approaches.
In the simplest case, a computer program sees a text as a sequence of alphanumeric characters and punctuation. This is a so-called raw representation .
"The programmer's programs had been programmed."
Separate words can be delimited by spaces or punctuation. As a result, we get a list of tokens . Note that at this point we consider punctuation characters as distinct tokens as well.
The very first token in the list below poses a dilemma. How should we treat capitalized characters? Should we change all the characters to lowercase? It seems reasonable to go for this choice. After all, "The" and "the" obviously represent the same word, namely, the definite article. But what about "Smith" and "smith"? It can be a proper name, a noun with a meaning "someone who makes and repairs things made of iron", or the same noun at the beginning of a sentence.
Unprocessed tokens preserve all the linguistic information, but simultaneously we get more noise in the input. Further post-processing can be used to get rid of unnecessary information.
the programmer 's programs had been programmed.
Words may have different forms. For example, the token "programs" from our example is actually a plural form of the noun "program". "Programmed" is the past simple of the verb "program". The initial forms of words or the forms that represent words in a dictionary are called lemmas . And a further logical step is to represent words by their respective lemmas.
the programmer 's program have be program.
So far, so good. You have probably heard that search engines use the lists of stop words in order to preprocess input texts. A stop word list is a set of tokens that are removed from a text. Stop words may include functional words and punctuation. Functional words are words that do not have independent meaning, for example, auxiliary verbs or pronouns.
Let's strip off functional words from the sentence. As a result, the initial utterance includes only content words (the words that have semantic meaning). However, there is no way to tell that the program in question is somehow related to the programmer.
programmer program program
I can imagine you are getting bored. But wait for it! We have not finished yet! A word can be represented by its stem . A stem is a part of a word to which we normally attach affixes. For example, we can attach the suffix "-er" (with a meaning of someone performing an action) to the stem "program".
Have a look at the input sentence after replacing the lemmas with the stems.
program program program
We managed to truncate the initial input into a not so informative sequence. The lesson here is: there are 3 typical ways to represent words:
Additionally, we can strip off functional words or convert words to lowercase.
These representations and their combinations are used depending on the actual language processing task. For example, it is unreasonable to strip off functional words if we need to differentiate texts in English and French. If we need to detect proper names in a text, it is reasonable to preserve the original character case and so on.
The linguistic units discussed above are the building blocks for bigger structures such as documents that we will discuss later.

The bag-of-words is a model used in natural language processing to represent a text (anything from a search query to a full-scale book). Although the concept dates back to the 1950s, it is still used for text classification and information retrieval (i.e. search engines).
I will use it in order to show how search engines can find a relevant document from a collection in response to a search query.
If we want to represent a text as the bag-of-words, we just count the number of times each distinct word appears in the text and list these counts (in mathematical terms, it is a vector). Before counting, one can apply preprocessing techniques described in the previous part of the article.
As a result, one loses all the information about text structure, syntax, and grammar of the text.
the programmer 's programs had been programmed
{the: 1, programmer: 1, 's: 1, programs: 1, had: 1, been: 1, programmed: 1 } or
[1, 1, 1, 1, 1, 1, 1]
programmer program program
{programmer: 1, program: 2} or
[1, 2]
There is not much practical use in representing a separate text as a list of digits. However, if we have a collection of documents (e.g. all the webpages indexed by a certain search engine), we can build a so-called vector space model out of the available texts.
The term may sound scary but in fact, the idea is rather simple. Imagine a spreadsheet where each column represents the bag-of-words of a text (text vector), and each row represents a word from the collection of these texts (word vector). The number of columns equals the number of documents in the collection. The number of rows equals the number of unique words that are found across the whole collection of documents.
The value in the intersection of each row and column is the number of times the corresponding word appears in the corresponding text. The spreadsheet below represents vector space for some plays by Shakespeare. For the sake of simplicity, we are using just four words.
| As You Like It | Twelfth Night | Julius Caesar | Henry V | |
|---|---|---|---|---|
| battle | 1 | 0 | 7 | 13 |
| good | 114 | 80 | 62 | 89 |
| fool | 36 | 58 | 1 | 4 |
| wit | 20 | 15 | 2 | 3 |
Remember, I've mentioned earlier that the bag-of-words is actually a vector. A cool thing about vectors is that we can measure the distance or angle between them. The smaller the distance or angle – the more "similar" are vectors and the documents that they represent. This can be achieved using cosine similarity metric. The resulting value ranges from 0 to 1. The higher the value, the more similar documents are.
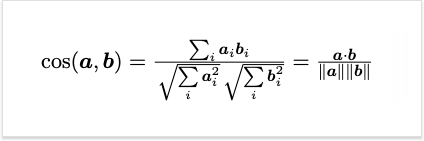
Now we have enough information to explain how one can find a document in the collection that is relevant to a search query.
Let's say a user is searching for "battle of Agincourt". This is a short document that can be embedded in the vector space from the example above. The respective vector is [1, 0, 0, 0]. "good', "fool", and "wit" have zero counts. We can then calculate the similarity of the search query to each document in the collection. The results are in the table below. One can notice that Henry V is the best match for the query. It's no surprise since the word "battle" appears in this text most often and thus the document can be considered more relevant to the query. Also, note that it is not necessary that all the words in a search query are present in the text.
| Similarity | |
|---|---|
| As You Like It | 0.008249825 |
| Twelfth Night | 0 |
| Julius Caesar | 0.11211846 |
| Henry V | 0.144310885 |
There are several obvious drawbacks of such an over-simplistic approach:
Zipf's Law states that given a large sample of words used, the frequency of any word is inversely proportional to its rank in the frequency table. So the word number N has a frequency proportional to 1/N. As a result, there holds an interesting pattern in natural languages. The most frequently used 18% (approximately) of words account for over 80% of word occurrences. It means that a few words are used often and many words are used rarely.
Frequent words will show up in many texts across a collection. As a result, such words make it more difficult to differentiate texts represented as the bag-of-words. Furthermore, the most frequent words are often functional words with no semantic meaning. They cannot describe the topic of a text.
These are the top 10 most frequent words in English.
We can apply the TF-IDF (term frequency – inverse document frequency) weighting in order to decrease the weight of words that are used frequently across the collection of texts. The TF-IDF score is calculated using the following formula:

Where the first component is the term frequency — the frequency of the word in the document. And the second component is the inverse document frequency. It is the number of documents in a collection divided by the document frequency of a word, which is the total number of documents the word appears in. The second component is used to give a higher weight to words that occur only in a few documents across the collection.
In the table below are some IDF values for some words in the Shakespeare plays, ranging from extremely informative words which occur in only one play like Romeo, to those which are so common as to be completely non-discriminative since they occur in all 37 plays like "good" or "sweet".
| Word | DF | IDF |
|---|---|---|
| Romeo | 1 | 1.57 |
| salad | 2 | 1.27 |
| Falstaff | 4 | 0.967 |
| forest | 12 | 0.489 |
| battle | 21 | 0.074 |
| fool | 36 | 0.012 |
| good | 37 | 0 |
| sweet | 37 | 0 |
IDF of very common words equals 0, as a result, their frequencies in the bag-of-words model will also equal 0. The frequencies of rare words will be increased.
TF-IDF weighting is integrated into the content optimization module of Website Auditor. You can learn more about the feature from this blog post.

Semantic search has been a buzzword in the SEO community since 2013. Semantic search denotes search with meaning, as distinguished from lexical search where the search engine looks for literal matches of the query words or variants of them, without understanding the overall meaning of the query.
But how can a search engine learn the meaning of a word? There is even a more difficult high-level problem. How should we represent the meaning so that a computer program can understand and practically use it?
The key concept that helps answer these questions is the distributional hypothesis that was first formulated as early as in the 1950s. Linguists noticed that words with similar meaning tended to occur in the same environment (i.e. near the same words) with the amount of difference in the meaning between two words corresponding roughly to the amount of difference in their environments.
Here is a simple example. Let's say you encounter the following sentences and you have no idea what a langoustine is:
And you also encounter the following. I assume that most of the readers know what a shrimp is:
The fact that langoustine occurs with words like delicacy, meat, and pasta might suggest that langoustine is a sort of edible crustacean similar in some way to a shrimp. Thus one can define a word by the environment it occurs in language use, such as the set of contexts in which it occurs, the neighboring words.
How can we transform these observations into something meaningful for a computer program? We can build a model similar to the bag-of-words. But instead of documents, we are going to label the columns by words. It is common to use small contexts about four words around a target word. In this case, each cell in the model represents the number of times the column word occurs in a context window (e.g. plus-minus four words) around the row word. Let's consider these four-word windows (the example from the book Jurafsky & Martin, Speech and Language Processing):
| Context | Target | Context |
|---|---|---|
| sugar, a sliced lemon, a tablespoonful of | apricot | jam, a pinch each of, |
| their enjoyment. Cautiously she sampled her first | pineapple | and another fruit whose taste she likened |
| well suited to programming on the digital | computer | In finding the optimal R-stage policy from |
| for the purpose of gathering data and | information | necessary for the study authorized in the |
For each word, we collect the counts (from the windows around each occurrence) of the occurrences of context words. And we get the word-word co-occurrence matrix similar to the one we have already seen previously. You can notice that "digital" and "information" are more similar to each other than to "apricot". Note that word counts can be substituted by other metrics such as pointwise mutual information.
| aardvark | ... | computer | data | pinch | result | sugar | ... | |
|---|---|---|---|---|---|---|---|---|
| apricot | 0 | ... | 0 | 0 | 1 | 0 | 1 | ... |
| pineapple | 0 | ... | 0 | 0 | 1 | 0 | 1 | ... |
| digital | 0 | ... | 2 | 1 | 0 | 1 | 0 | ... |
| information | 0 | ... | 1 | 6 | 0 | 4 | 0 | ... |
Each word and its semantics are represented with a vector. The semantic properties of each word are determined by its neighbors, i.e. by the typical contexts the word appears in. Such a model can easily capture synonymy and word relatedness. The vectors of two similar words will appear near each other. And the vectors of the words that appear in the same topic field will form clusters in space.
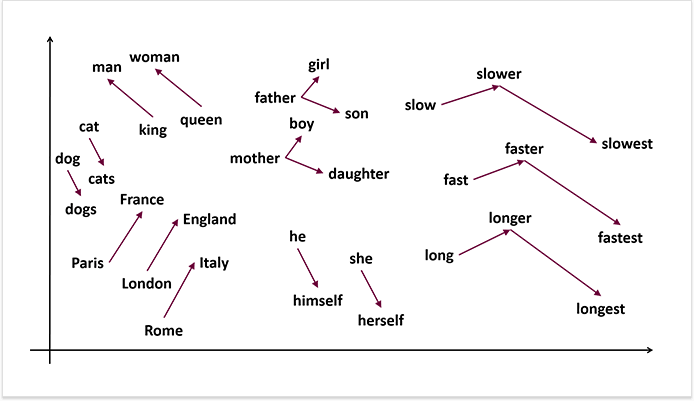
There is no magic behind semantic search. The conceptual difference is that words are represented as vector embeddings but not as lexical items (strings of characters).
Computational linguistics is an exciting and fast evolving science. The concepts presented in this article are not new or revolutionary. But they are rather simple and they help to get the basic high-level view over the problem field. If you are willing to learn more about how search engines actually work, I would recommend reading a book Introduction to Information Retrieval by Manning, Raghavan, & Schütze. It is also officially available online.
As always, questions, suggestions and critical views are very welcome in the comments section.

| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

