•
17-minute read


A few weeks ago, I was asked to throw a quick intro to search engine optimization for a couple of new members of the SEO PowerSuite team. The “basics” part had gone pretty smooth until we moved to the topic of user behavior and its influence on rankings.
Back in 2015, the hot debates on whether such user behavior metrics as search snippet click-through rate, dwell time, a page's bounce rate, average session duration, and pogo-sticking were part of Google’s ranking algorithm blew up the SEO scene. Fast forward to 2022, and this topic no longer seems to be on the agenda, leaving too many questions unanswered.
In this in-depth article, I'll dig into everything we know so far about user behavior data and its impact on rankings (could it be the reason your rankings dropped), analyze the evidence both for and against the use of behavioral metrics by Google, and eventually try to come up with the verdict if this is something that warrants an adjustment in your search engine optimization strategy.
The rumors that search engines like Google might be using user behavior data in their search algorithm have been in the air for quite a while.
Of particular interest were the testimonies made by the three former Google employees.
First was Edmond Lau, who used to work on Google Search Quality. In 2011, he said the following on Quora:

It's pretty clear that any reasonable search engine would use click data on their own results to feed back into ranking to improve the quality of search results. Infrequently clicked results should drop toward the bottom because they're less relevant, and frequently clicked results bubble toward the top.
Then, the same year, Amit Singhal, Google's top search engineer at that time, mentioned in an interview with Wall Street Journal that the major search engine had added numerous "signals", or factors into its search engine algorithm for ranking sites:

How users interact with a site is one of those signals.
The next year, in a Federal Trade Commission court case, Google's former Search Quality chief, Udi Manber, testified the following:

The ranking itself is affected by the click data. If we discover that, for a particular query, hypothetically, 80 percent of people click on Result No. 2 and only 10 percent click on Result No. 1, after a while we figure probably Result 2 is the one people want. So we'll switch it.
All these statements coming from Googlers, former and not, marked the birth of various Click Through Rate manipulation services and triggered a wave of real-life experiments. Those SEOs who were not against using blackhat SEO tactics rushed to buy bot traffic while others tried to engage real users (organic traffic) in their experiments.
The early CTR bots were oversimplified and failed to mimic real user behavior, so the first group of testers quickly realized that the major search engine could easily catch and neglect the user behavior data coming from bots. The second group, though, made a lot of buzz in the SEO community because their experiments did show some vivid results.
Back in 2014-2015, Rand Fishkin of SparkToro ran a series of experiments to see if any of the user behavior metrics had an impact on rankings. His first experiment included the CTR factor – Rand asked his Twitter followers to google a specific term and visit his website from the SERPs. After a few hours, his website was ranked first for that given query, gaining six positions as a result.
The second experiment Rand ran was aimed at testing the possible effects of pogo-sticking (a type of user behavior that occurs when a user 'jumps' across search engine results from one to another to find the most relevant one) on Google’s rankings. That time, he asked his followers to complete a few simple steps from the screenshot:
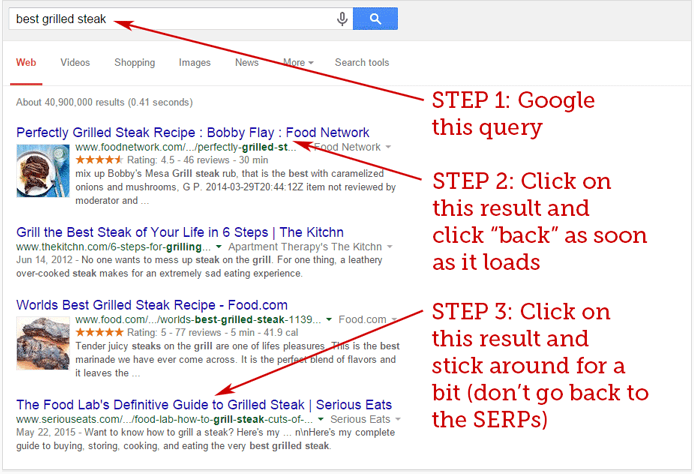
And again, in just about an hour, the search engine results page changed and result #4 turned into result #1.
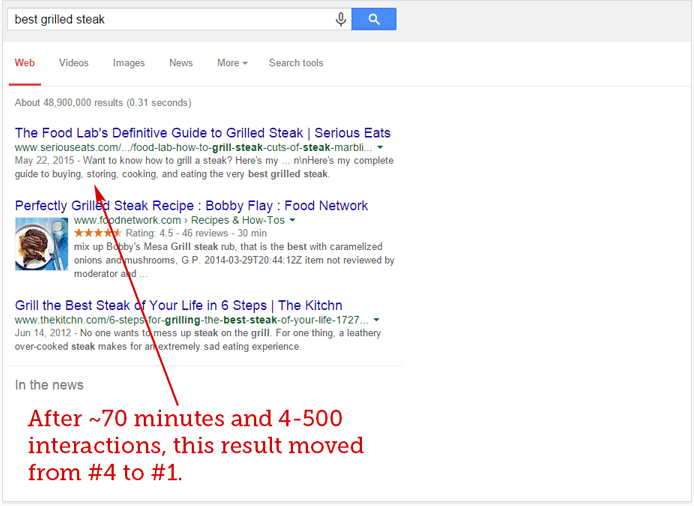
A few months later, the Italian SEO professionals Cesarino Morellato & Andrea Scarpetta conducted a similar to Rand Fishkin’s experiment. However, one thing was different. Instead of engaging real users, they built their own software, which used thousands of IP addresses within the USA and could simulate real user behavior. As opposed to the experiments with the simple CTR bots, their software did work, and the tested search snippet gained seven positions, moving from search position 10 to position 3.
Curiously, the more all these experiments were discussed in SEO circles, the more desperately Google denied the fact that user behavior data might be used in ranking algorithms.
Not so long after Rand Fishkin’s first experiment, at SMX Advanced in 2015, Gary Illyes of Google was asked if they were using clicks for ranking. Here’s what he said:

We use clicks in a few different ways. The main things that we use clicks for are the evaluation and experimentation. There are many many people who are trying to induce noise in clicks. One would be Rand Fishkin, another would be Brent Payne, and using those clicks directly in ranking, I think, doesn't make too much sense.
Interestingly, just a month after Illyes’ statement, the major search engine released a patent describing how user feedback (clicks, dwell time, average session duration, etc.) could be partially used to modify organic search rankings.
However, a newly-released patent didn’t change the rhetoric of Google’s spokespersons.
At Pubcon Las Vegas 2016, Gary Illyes said that click-through rate was still not used as a ranking factor:
If you think about it, clicks in general are incredibly noisy. People do weird things on the search result pages. They click around like crazy, and in general it’s really, really hard to clean up that data.
He was followed by John Mueller who explained that pogo-sticking as well had not been regarded as a ranking signal.

We try not to use signals like that when it comes to search. So that's something where there are lots of reasons why users might go back and forth, or look at different things in the search results, or stay just briefly on a page and move back again. I think that's really hard to refine and say "well, we could turn this into a ranking factor. So I would not worry about things like that.
Later, Gary Illyes again pointed out that user behavior data was not used for ranking:
Dwell time, CTR, whatever Fishkin's new theory is, those are generally made up crap. Search is much more simple than people think.
For the next few years, the topic of user behavior and its impact on rankings was more of a ping-pong game where SEOs kept running multiple experiments, successful and not, Googlers kept denying everything, and big names in SEO kept trying to solve the mystery of user behavior data as a ranking factor.
So, in 2015, just a month after another denial coming from Gary Illyes, Google released a patent named Modifying search result ranking based on implicit user feedback and a model of presentation bias.
The patent, which is still active and will expire only in 2029, describes the mechanisms available to Google that help collect, render and leverage user behavior data to modify search results’ rankings.
These mechanisms form the basis of the new rank modifier engine, which is incorporated into the original ranking algorithm and is responsible for re-ranking the results based on the implicit user feedback.
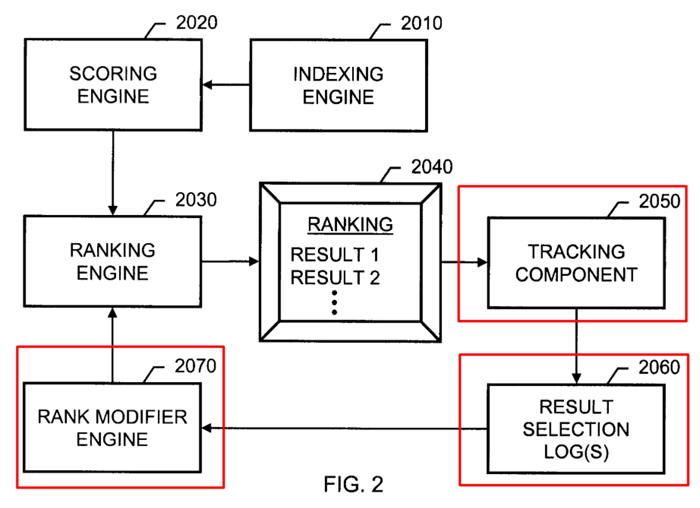
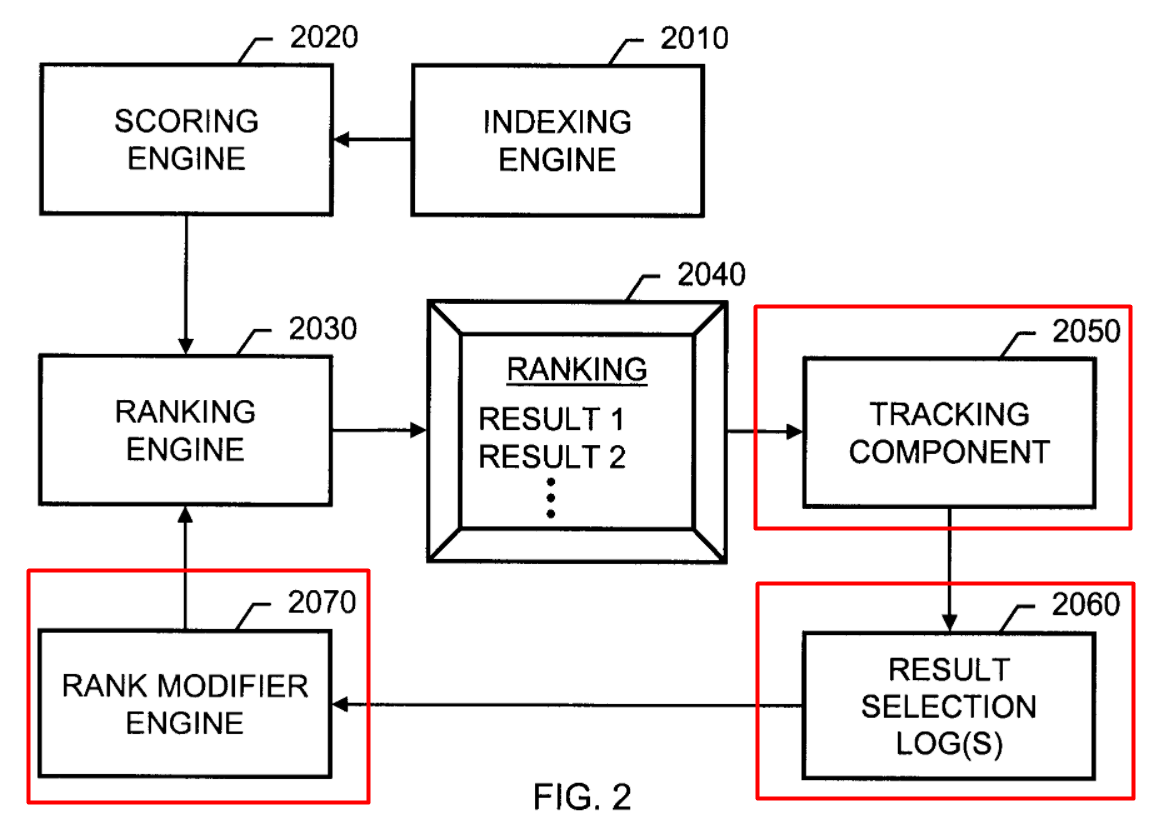
In addition to the rank modifier, there are two new components in the new algorithm – the one that tracks user behavior and the one that logs all the information.
We don’t know for sure if the tracking and logging components described in the patent are standalone solutions. But chances are it could be the Chrome browser.
Chrome's MetricsService logs everything you do on the web, including opened/closed tabs, fetched URLs, and lots more. You can check it yourself by simply entering chrome://histograms/ into the address bar.As we move further through the patent, we see the confirmation that clicks can be evaluated to re-rank search results:
User reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking.
The mechanisms described in the patent also account for the various types of presentation bias. So, for instance, if a rich snippet gets a higher click-through rate because it looks more attractive compared to other results, clicks for this result are discounted according to the patent. Vice versa, if the results from the very bottom of a SERP get lower click-through rate compared to higher positions, clicks for these results are over-counted.
Digging deeper into the patent, it appears that clicks are not the only metric the search engine can potentially capture and use for ranking. As specified in the patent, for each click the following information is gathered:
Another excerpt from the patent also makes it right to conclude that such metrics as pogo-sticking and dwell time can be potentially used as part of the ranking algorithm:
The time (T) can be measured as the time between the initial click through to the document result until the time the user comes back to the main page and clicks on another document result. Moreover, an assessment can be made about the time (T) regarding whether this time indicates a longer view of the document result or a shorter view of the document result, since longer views are generally indicative of quality for the clicked through result.
Altogether, the patent is huge, and it’s indeed spectacular just how far Google went by describing even the tiniest aspects of the user behavior signals analysis. This, in turn, leads to a logical question – why would anyone spend so much time describing such sophisticated mechanisms in detail if the whole thing won’t be implemented at any stage?
It pays to mention, though, that the patent also describes the mechanisms that were eventually implemented by Google later on. For instance, there’s a notion of mobile search, which uses geolocation to serve better search results:
For example, knowledge that a user is making a request from a mobile device, and knowledge of the location of the device, can result in much better search results for such a user.
While I tend to believe Google does use behavioral data in its algorithms somehow– as part of a complex mechanism rather than in isolation – some SEO experts think otherwise.
Here are their main concerns as to why Google would never use such metrics as click-through rate for ranking:
One of the common misconceptions I’ve been hearing every now and then is that click-through rate will never become a ranking factor since it’s extremely easy to manipulate.
However, it’s easy to render this argument invalid if we do some research.
First, if we get back to the patent we discussed earlier, we will find that Google is well aware of the possible fraudulent clicks issue. They even described the safeguards against spammers:
Note that safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn’t conform to this model, their click data can be disregarded.
Second, we must keep in mind that Google already has the mechanisms in place that help successfully detect and fight click fraud on the Google Ads platform.
And while a potential threat of CTR manipulations in the organic search is higher rankings of certain results, the aftermath of click fraud with ads would be much worse. Say, anyone would have been able to use CTR bots to drain a competitor’s ads budget. Or those who participate in Google’s AdSense would have used this opportunity to artificially boost clicks on the ads on their websites to generate more revenue.
So let’s assume for a second that Google can easily tell bots from real users, and use their click data for ranking. Why keep calling CTR a “noisy” metric then?
I suspect that though there are safeguards in place, the mechanisms are still not perfect. For instance, SEO tools are still able to collect SERP data, despite Google’s policies that forbid any automated access to their service.
On top of that, the more click fraud Google needs to fight, the more processing power it wastes.
Taking all this into account, it becomes quite evident why Googlers keep denying the fact CTR might be part of the ranking algorithm.
Another argument I hear too often is that incorporating user behavior metrics in algorithms contradicts what Google is heading to with their SERP features.
Today, we indeed see more and more SERP features taking the so-called zero position. This, in turn, leads to changes in user behavior where many searches end up with no click on organic results. Such behavior is difficult to measure and interpret, but Google seems to have mechanisms to deal with this.
I’ve found a Google research paper that has many insights on the topic. There’s also a confirmation that user behavior metrics on such SERPs are not currently captured. So basically Google knows where click data should and should not matter:
Second, the non-linear layout and visual difference of SERP items may lead to non-trivial patterns of user attention, which is not captured by existing evaluation metrics.
In addition to what we’ve learned so far, there are several cases where we can assume that user behavior plays a certain role with a high degree of probability.
Here they are:
RankBrain is Google's machine-learning algorithm, which is said to be one of the top three ranking factors.
This algorithm is used to determine the true user intent behind unfamiliar and long-tail queries to provide searchers with the most relevant results.
So when it comes to a never-before-seen query, the RankBrain algorithm first tries to match it to the already existing queries that might have a similar meaning, and then filters the results accordingly.
To work effectively and be able to predict the best results for every unknown query, RankBrain, as any machine-learning system, needs to constantly teach itself based on what worked well for past searches. To do this, RankBrain captures what results do and do not satisfy the searcher intent for all queries it processes.
We don’t know all the metrics RankBrain uses to evaluate satisfaction, but it’s right to assume that user behavior metrics play a central role here. As it’s hard to imagine a metric that would tell a machine more about the relevance of a certain search result than the number of actual clicks it received.
More to that, I found an interesting article on Wired where the world-famous author Steven Levy described how RankBrain was actually developed. As it appears from the article, Google’s AI team was discussing a metric that should have helped RankBrain see how well a certain SERP matches an unfamiliar query. And this metric was indeed CTR.
Though not so evident, there’s another clue suggesting that RankBrain accounts not only for CTR but also dwell time and pogo-sticking.
It’s a common fact that the meaning behind every search query can change over time. And Google, just like other search engines, must react fast to satisfy the true searchers’ intent and provide the most relevant results on their SERPs.
The hypothesis that user behavior metrics might be playing a certain role in adapting to user intent shifts is logical and supported by many SEO experts.
During one of the Live with Search Engine sessions, Pete Mayers of Moz commented on that the following:


The idea that what’s happening with searcher behavior is not causing these shifts means that Google is in there writing that code for every intent, every day, and I can’t believe that’s what’s happening.
During the early days of a global pandemic, such a shift in searchers’ intent happened to the queries related to Wuhan. At that time, Google quickly tweaked the SERPs, and the main focus was shifted towards the COVID-related results, rather than general information about the city.
I can assume that this might have happened due to the spike of specific search queries, which included both keywords – Wuhan and COVID-19. The shift might have been also picked up by the Google Freshness Algorithm. Still, it would be rather irrational of Google not to factor in user behavior data to catch such changes in searcher intent.
The potential impact of user behavior on search rankings in local search engines is a trending topic today.
As search engines become more entity-based, the whole idea seems very logical.
The question here is what factors are used for evaluating the relevance of this or that entity. Say, when someone is searching for places to eat nearby, how exactly do Google and other search engines build up a local pack, or how do they decide who should be ranked higher on maps?
We already know that many factors contribute to this, including proximity, local links, reviews, and many many others.
But could it be that user behavior also adds up to the chances of winning higher positions in local search?
It’s possible.
Say, if enough users choose a certain business on maps and then click on Directions, Google, just like any other search engine, might take this as a vote of confidence that this specific result is more popular than the presented alternatives.
According to the research I found, the weight of behavioral signals in local search rankings is estimated at a somewhat 10% level, but many SEO experts agree on the idea that it will only grow in the future:

I believe that we will continue to see more behavioral and review based factors gain in rankings. It’s slow, but it’s by far the most accurate indication of good businesses. As Google’s ability to detect real actions vs fake continues, this would definitely lead to the best local results.
This was where Google, the major search engine, once confirmed using behavioral data for ranking purposes did make sense.
However, the level of personalization today is very limited and Google rarely re-ranks SERPs based on this factor. Such signals as user location, search intent, and the device type play a bigger role in how SERPs are formed.
We have at least several pieces of indirect evidence for user behavior as a ranking factor. Those are Google’s patent, the results of several experiments, the statements made by former Google employees, and possible use cases I’ve just pointed out.
However, there are a few things we must keep in mind.
First, Google’s patent indeed describes user behavior analysis and usage down to the smallest detail. But at the same time, no one, except for Google engineers, can tell if any of the mechanisms were in fact implemented by Google at any stage.
Second, the majority of experiments are outdated, and it’s hard to predict if there will be any representative results if we do the same thing today. However, we must not forget that these experiments did show some results in the past, and that’s important, too.
Third, we can’t prove the statements of former Google employees true or false. More to that, what was valid at the time they worked at Google might be irrelevant today.
Finally, the possible use cases I’ve previously touched upon are logical. But we still don’t have enough research that would show a strong and evident correlation between user behavior and rankings.
What I’m certain about is that Google of today is largely powered by machine-learning algorithms, and there may be thousands of signals that indirectly support direct ranking factors. User behavior might well be on the list.
It’s difficult to measure how much actual SEO weight user behavior metrics carry, but I still strongly recommend that you optimize for these metrics. And it’s not about rankings here, it’s about the benefits your website will get from such optimization.
Think of it this way – if your search snippet has an enticing title and meta description, or if you’ve even managed to get a rich snippet, more users will click on it. Hence, you will not only get more visitors, leads, and conversions, but (potentially) you will also send a positive signal to Google that a certain web page (or web pages) of your website is relevant and awesome.
First, thank you for reading my post till the very end!
Now’s the fun part. Remember I said that the majority of CTR experiments were outdated? I want to run my own CTR experiment to further update this article with some first-hand data. So if you have a spare minute, please google “how to make website mobile friendly”, find and click on our guide and stay on the page for a while.
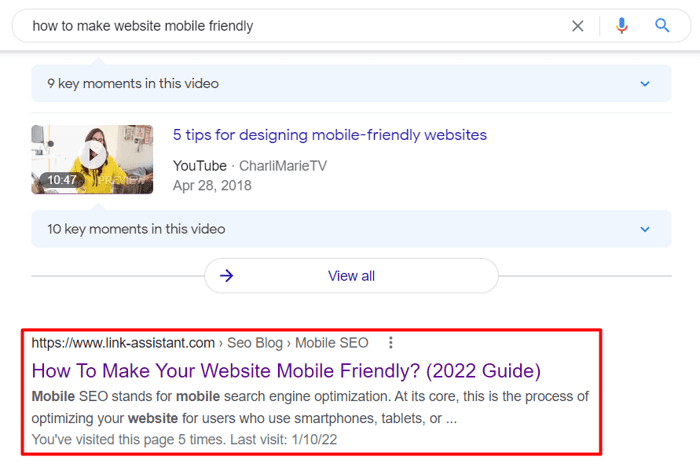
Once done, please leave + in the comments. If the experiment is successful, I’ll share the results with you on Facebook.
It's been almost two months since the start of our CTR experiment. From what I see in Google Search Console, the CTR of the query "how to make website mobile friendly" has grown by 880% in the first two days. However, this temporary spike in CTR hasn't affected the rankings at all.
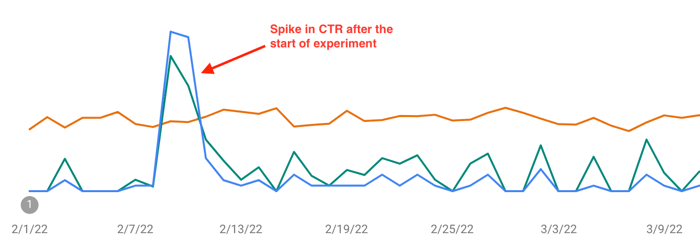
I have two logical explanations here. The first one is that the number of clicks should be much higher for Google to notice such spikes. The second one – Google's algorithms are more sophisticated today, so you can't trick them by artificially boosting your CTR. I vote for the latter.
Also, feel free to leave a comment below if you agree with my conclusion or in case I’ve missed something.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

