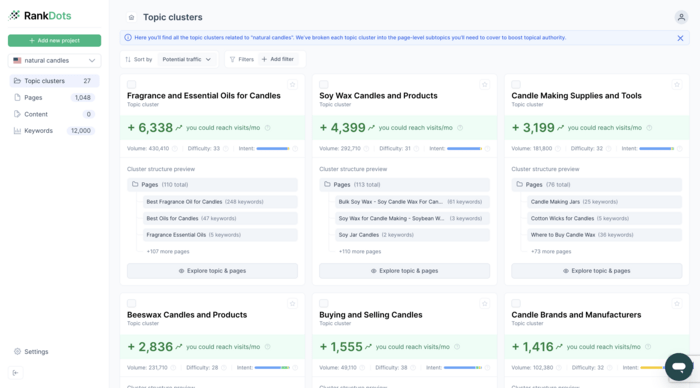
3
•
12-minute read


What would you do if Google published an official guide explaining exactly how its AI systems decide what content to surface — and the answer turned out to be something you already knew?
That's roughly what happened a week ago, when Google quietly dropped its Guide to Optimizing for Generative AI Features on Google Search inside the Search Central documentation.
The timing was striking. Google I/O had just wrapped with announcements that were anything but quiet — AI Overviews reaching billions of users, Search becoming more interactive inside the results page, and AI agents watching the web for you 24/7.
Google Search is changing. It no longer just wants to send people to other websites. It wants to become the place where everything happens.
At the same time, click rates were dropping. Publishers were worried. And a whole new consulting market had appeared around AEO frameworks, GEO audits, and llms.txt as the new “must-have” SEO fixes.
Then Google published a guide that sounded surprisingly calm: do good SEO, create helpful content, and don’t panic about every new trend.
That contrast is what makes the guide interesting. On the surface, it feels reassuring. But if you read it closely, it shows which content strategies are likely to survive this shift — and which ones are not.
Here’s what it actually says.
The first important thing about Google’s guide is not what it says, but where it appears.
The guide is part of Search Central’s SEO Fundamentals section, right next to the SEO Starter Guide and the helpful content guide. It is not in a separate AI section. It is not treated as a new discipline.
That placement sends a clear message: optimizing for generative AI search is still SEO.
Google says this directly. It mentions terms like AEO and GEO, but then brings them back under SEO. From Google’s point of view, there is no separate practice.
This matters. Since AI Overviews became widely available, a whole consulting market has grown around the idea that AI search needs completely new strategies, frameworks, and deliverables. Google is now pushing back against that idea in its official documentation.
Whether that feels reassuring or annoying probably depends on how much of your current strategy is based on the idea that AI search is a totally different game.


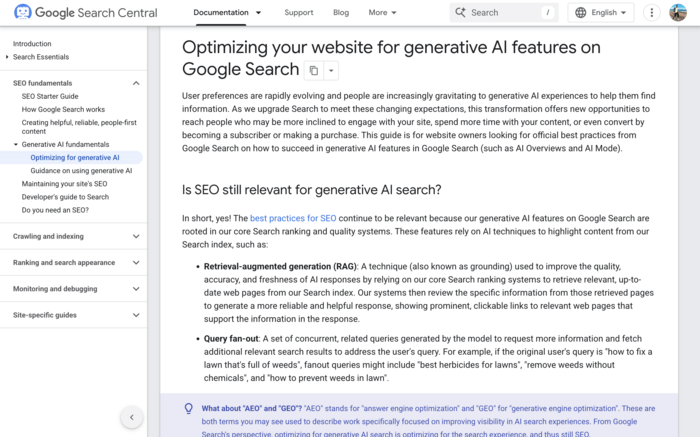
Google’s “just do SEO” message makes more sense once you understand two ideas from the guide: RAG and query fan-out.
RAG means AI Overviews are built from real pages in Google’s index. The system retrieves relevant content from Search and uses it to generate answers. So if your page is indexed, ranks well, and is technically eligible, it can also be used in AI Overviews.
Query fan-out means Google does not rely on one search query. For a complex question, it runs several related searches at once and combines the results into one answer.
That means your page does not need to match the exact wording of the user’s query. A deep, useful page can appear because it answers one of the related sub-questions.
The takeaway: depth and semantic relevance matter more than exact-match keyword targeting.
One small technical detail in Google’s guide is easy to miss but important:
To appear in generative AI features, a page must be indexed and eligible to show a snippet in Google Search.


That means pages with a nosnippet tag cannot appear in AI Overviews, even if the content is strong and ranks well.
For many teams, nosnippet has been treated as a minor technical setting. But now, a wrongly applied nosnippet tag could quietly block important pages from showing up in AI results.
So before chasing new AI SEO tactics, audit your important pages for nosnippet tags.
Most coverage of Google's guide will focus on what it recommends. That's the wrong place to look.
The more interesting half of the document is the section titled "What you don't need to do" — a list of specific tactics that Google explicitly says you can ignore for generative AI search. It's worth reading slowly, because the existence of this list tells you almost as much as the list itself.
Google doesn't publish mythbusting sections preemptively. When it takes the time to name and dismiss specific practices in official documentation, it's because those practices have spread far enough to warrant a public response. This section is Google acknowledging, in the driest possible language, that a significant portion of what's currently being sold as AI search optimization is noise.
Here's what made the list — and what each dismissal actually means.
Google's position is unambiguous: you don't need to create llms.txt files or any other machine-readable AI markup to appear in generative AI search. Google may crawl and index the file like any other, but it receives no special treatment.
This is a pointed call. llms.txt has real momentum — it originated from fast.ai and has been adopted across a meaningful number of publisher and SaaS sites, often on the recommendation of consultants positioning it as a necessary step for AI visibility.
For instance, here’s an example of the actual llms.txt file from Anthropic’s website:
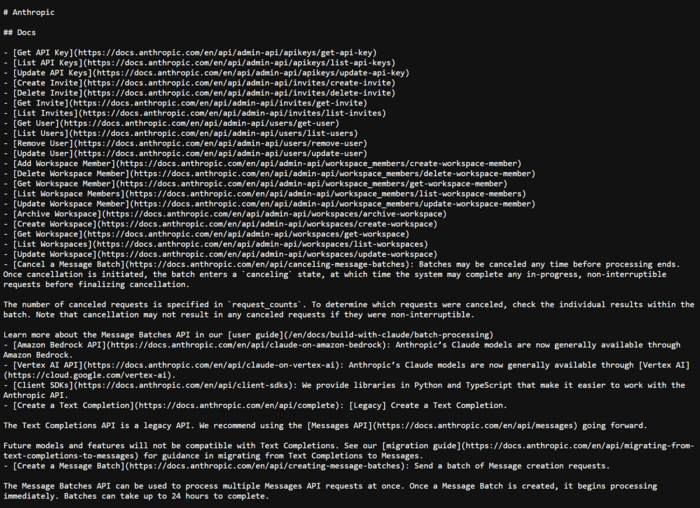
For Google Search specifically, that work produced nothing. The file doesn't influence how Googlebot crawls your site, how your content is weighted in AI Overviews, or whether you're cited in AI Mode.
The recommendation to break content into short, discrete, AI-digestible paragraphs — often framed as making it easier for AI systems to "parse" your pages — is debunked outright. Google's systems understand context across multi-topic pages and can surface the relevant section to users without the content being pre-segmented for them.
This one matters because "chunking" has quietly become a default content formatting recommendation in a lot of AEO guides. The premise was reasonable-sounding but incorrect: AI retrieval systems don't need your help with chunking. That's their job. Reorganizing your content architecture around this assumption isn't just unnecessary — it risks creating pages that feel choppy and fragmented to human readers for no ranking benefit.
You don't need to rewrite copy in a specific way to be understood by generative AI search. Google's systems handle synonyms, semantic variants, and general meaning. This means you don't need to obsessively cover every long-tail variation of a query, and you don't need to audit your copy against a checklist of "AI-friendly" phrasing.
The underlying point is about semantic understanding: a page about fixing a lawn doesn't need to contain the exact string "how to fix a lawn full of weeds" to be cited for that query. The model understands relevance at a conceptual level, not a lexical one.
This point is about a common AI SEO tactic: trying to plant brand mentions across forums, blogs, roundups, and discussions so AI systems start seeing your brand as more authoritative.
Google’s message is simple: fake mentions do not help. The same spam rules that apply to regular search also apply to AI Overviews.
That does not mean brand mentions are useless. Real third-party coverage still matters — reviews, editorial mentions, citations, and genuine discussions.
The difference is simple: earn your place in the conversation instead of trying to fake it.
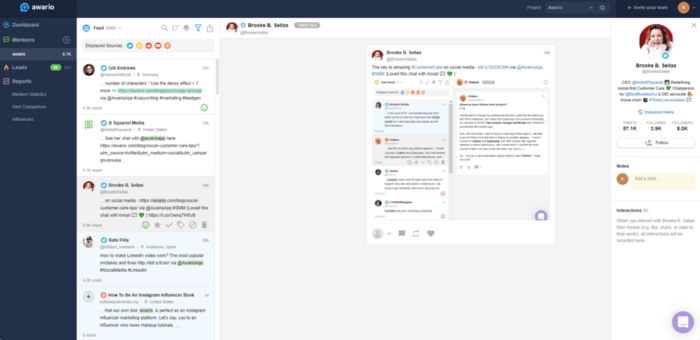
Awario helps you track real brand mentions across the web, social media, YouTube, and other online conversations. Instead of trying to manufacture mentions, you can use it to see where your brand is already being discussed, find genuine conversations worth joining, and understand which third-party mentions are actually shaping your visibility.
Structured data isn't required for generative AI search, and there's no special schema.org markup that unlocks AI Overview eligibility.
Continue using it as part of your broader SEO strategy for rich results — but don't treat it as an AI Overviews lever, because it isn't one.
Buried inside Google's recommendations for content quality is a distinction that most readers will skim past. It deserves more attention than anything else in the document.
Google draws a line between two types of content — commodity and non-commodity — and uses plain examples to illustrate the difference:
Commodity content: "7 Tips for First-Time Homebuyers" — common knowledge, available from anyone, adds no unique insight.
Non-commodity content: "Why We Waived the Inspection and Saved Money: A Look Inside the Sewer Line" — a specific, experienced perspective that goes beyond what's common knowledge, and that only someone who actually did this could write.
On the surface, this looks like a restatement of the helpful content guidance Google has been publishing for years. It isn't. The commodity/non-commodity frame is meaningfully sharper — because it introduces a test that helpful content doesn't.
The test is this: could a generative AI model produce an equally useful version of this page?
If the answer is yes, that page is commodity content. And commodity content is precisely what AI Overviews are best at synthesizing and replacing.
"Helpful" is a quality judgment — it asks whether the content serves the reader. "Non-commodity" is an origin judgment — it asks whether the content could have come from anywhere, or whether it could only have come from you.
A well-researched, clearly written guide to first-time homebuying can be genuinely helpful. It can pass a content quality audit. It can rank. It can also be produced by AI in seconds, at scale, with comparable accuracy. That's the problem. The content type, not the execution quality, determines whether it's replaceable.
Non-commodity content, by contrast, has irreplaceability built into its structure. A first-hand account of waiving a home inspection — with the specific reasoning, the specific outcome, the specific dollar figure — cannot be generated. It can only be experienced and then written down. That's the moat.
Google is telling you, in careful language, that the content most at risk in the AI era is not bad content. It's generic content. Content that was always drawing on the same pool of publicly available information that AI models were trained on.
The examples Google uses are consumer-facing, but the principle extends across every content category. There's also a photo from the Google Search Central event in Toronto, which took place in April, and gives us a hint on what Google considers non-commodity content.


A comparison article that ranks "best CRMs for small business" by aggregating feature lists is commodity content. A comparison that documents exactly how a specific team migrated from HubSpot to Pipedrive, what broke during the transition, and what they'd do differently is not.
A how-to guide explaining the steps to set up Google Search Console is commodity content. A guide that walks through what GSC data actually revealed about a specific site's traffic collapse — with annotated screenshots and a real diagnosis — is not.
An industry trends piece summarizing what AI means for content marketing is commodity content. An opinionated analysis from someone running content operations at scale, drawing on their own performance data and making specific predictions they're willing to be wrong about, is not.
The differentiator is always the same: specificity, experience, and a perspective that requires having actually done the thing.
For teams running high-volume content operations — particularly those that have integrated AI writing tools into production workflows — this framing lands awkwardly.
A significant portion of what gets published at scale is, by Google's own definition, commodity content. Not because it's low quality, but because the content type inherently draws on common knowledge and produces outputs that are structurally similar regardless of who or what wrote them.
The guide doesn't say AI-assisted content is penalized. It says commodity content is at a structural disadvantage in the AI search era — because AI Overviews can synthesize and serve that type of content directly, without routing users to your page.
That makes research and content selection much more important. Before creating another generic article, teams need to understand where there is real search demand, where competitors are already strong, and where their site can still add something useful.
This is where tools like SEO PowerSuite can help: use Rank Tracker to evaluate keyword opportunities and competitor visibility, WebSite Auditor to strengthen the pages you already have, and SEO SpyGlass to understand the authority signals behind competing content.
The point is no longer just to publish more. It is to publish where your content has a real reason to exist.
Query fan-out sounds like an opportunity at first.
If Google’s AI breaks one complex question into several related searches, the obvious SEO response is: find those variations, create pages for each one, and increase your chances of being pulled into AI Overviews.
But Google warns against exactly that.
The guide says creating separate pages for every possible fan-out variation — mainly to influence rankings or generative AI responses — can violate its scaled content abuse policy.


In other words, query fan-out is not an invitation to publish dozens of thin pages around the same topic.
What it rewards is depth. A strong, comprehensive page can naturally match several related angles because it covers the topic properly. Ten shallow pages targeting slight query variations usually do the opposite: they fragment the topic and create the kind of low-value content footprint Google is trying to filter out.
This changes how content teams should think about topic clusters.
The old model often pushed teams to create a pillar page plus many supporting pages for every long-tail variation.
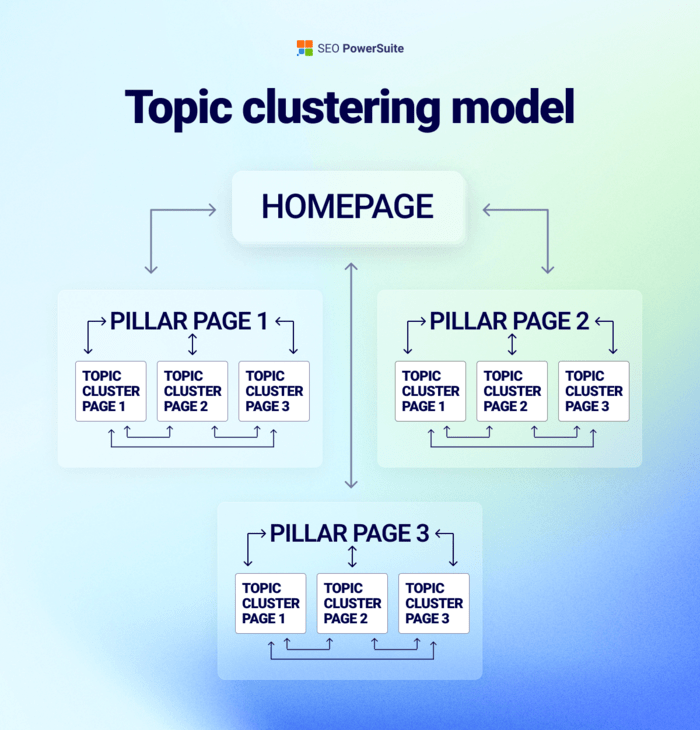
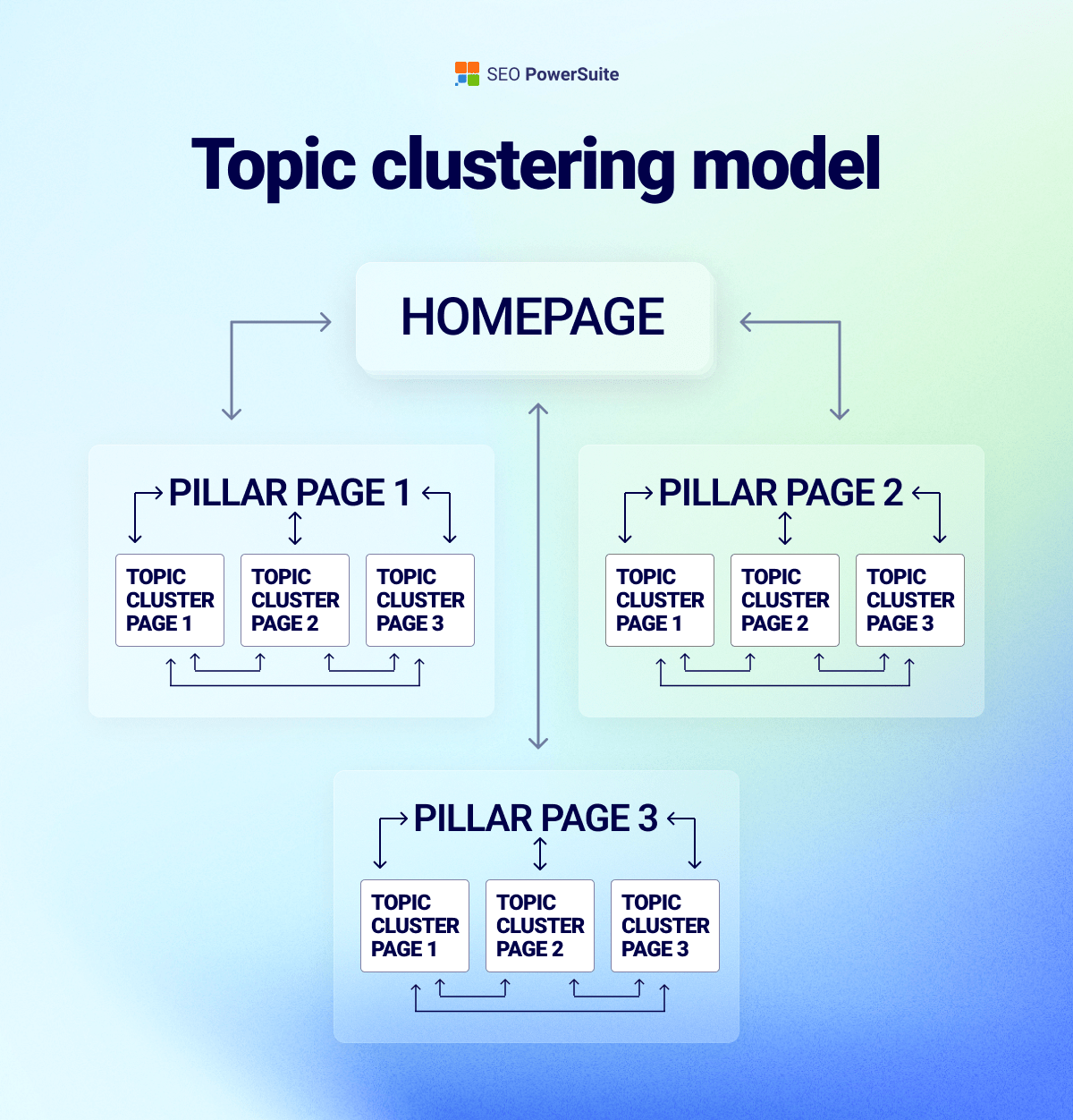
That made sense when each query had its own SERP.
But in AI search, Google can synthesize across related queries internally. So the value of having a separate page for every variation drops.
In many cases, consolidation will beat expansion. One authoritative, well-developed page is more useful than ten derivative pages covering tiny slices of the same topic.
This is where RankDots fits naturally into the workflow: not as a way to generate more pages for every keyword variation, but as a way to see which topics actually deserve separate pages, which ones should be grouped together, and how to structure content around real topical depth instead of keyword duplication.
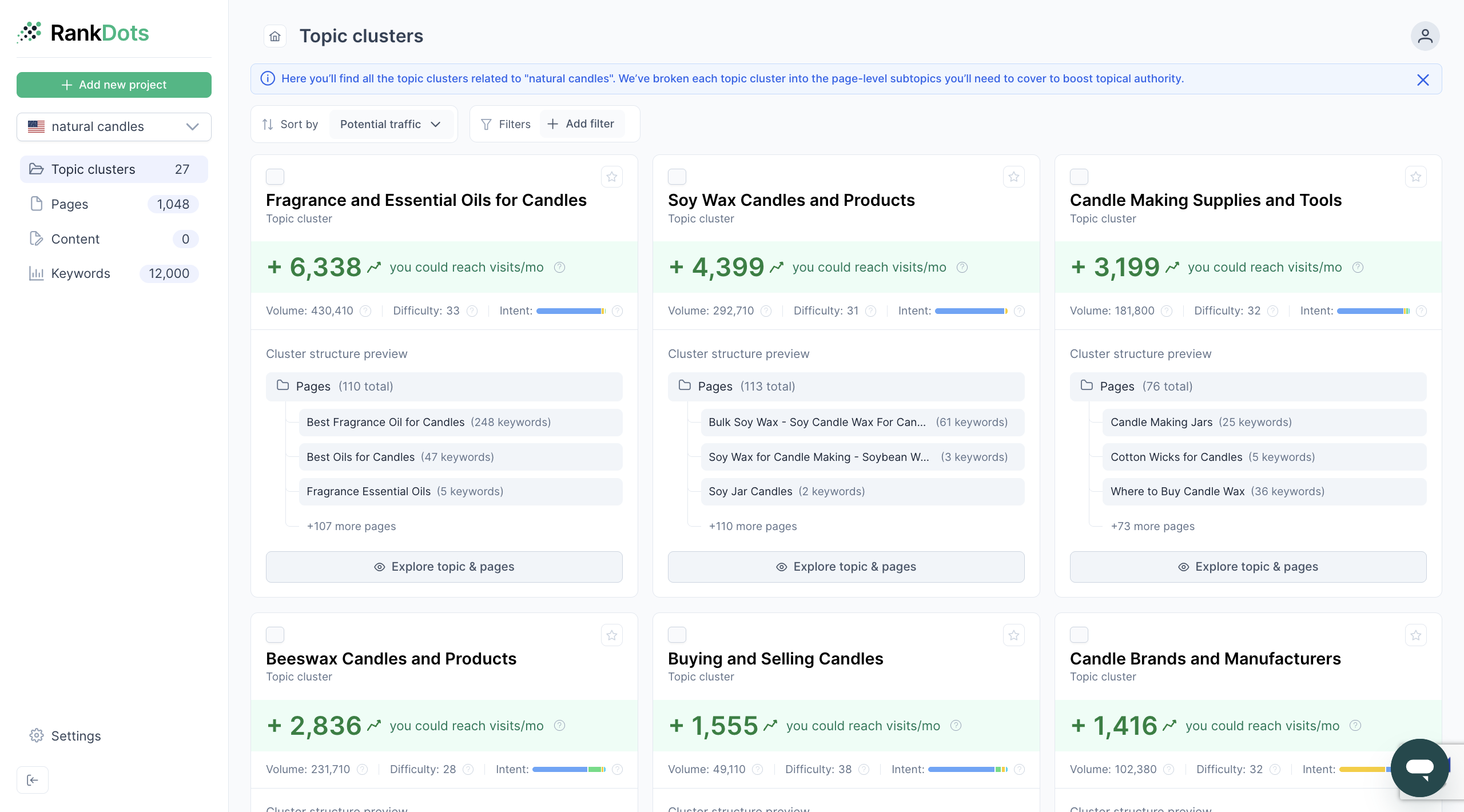
The goal is not to cover every variation with a separate URL. It is to build a cleaner topic map where each page has a clear reason to exist.
This is especially important for teams using AI to scale content production.
If your workflow is built around generating lots of similar pages from keyword clusters, the risk is clear. Even if the pages are technically unique, they may still be thin, repetitive, and easy for AI Overviews to replace.
Google is not saying AI-assisted content is bad. It is saying that volume alone is not enough.
The real question is whether your content adds expertise, original perspective, or genuine usefulness — or whether it simply repackages information Google’s AI can already summarize on its own.
Google also brings up crawl budget, especially for large or frequently updated sites.
For most small sites, this is not the main issue. But for publishers, ecommerce sites, and SaaS platforms with thousands of URLs, it matters.
If Google spends too much time crawling low-value pages, your stronger content may get discovered or refreshed less efficiently. In an AI search context, that can affect whether your best pages are available for retrieval and citation.
The practical takeaway: keep your crawl footprint clean. Remove, consolidate, or deindex low-value pages so Google can focus on the content that actually matters.
The final part of Google’s guide is easy to skip, but it points to where Search may be going next.
Google talks about AI agents that do more than read pages. These agents may interact with websites, compare products, gather pricing, or complete tasks for users.
That means they need more than crawlable text. They need clean page structure, clear buttons, readable layouts, useful headings, semantic HTML, and accessible labels.
In other words, accessibility and technical structure are becoming more important for AI visibility too.
This does not mean you need a separate “AI agent optimization” strategy. It means the basics matter more: clean HTML, logical headings, well-labeled interactive elements, and pages that are easy for both humans and machines to understand.


Everything covered so far points in a consistent direction. The question is how to translate it into prioritized work without getting lost in the wrong details.
What follows isn't an exhaustive optimization checklist. It's a short list of specific moves with clear rationale — ordered roughly by how much leverage each one carries relative to the effort required.
Start with your highest-impression pages in Google Search Console. These are the pages most exposed to the AI Overview shift because they already sit close to real search demand.
For each page, ask the uncomfortable question:
Could ChatGPT write this article in 90 seconds and produce something essentially identical in information value?
Not similar. Identical in usefulness, depth, examples, and conclusions.
If the answer is yes, the page is at structural risk. Not because it is badly written, but because it relies on the same publicly available knowledge that generative AI can already summarize directly.
A better way to run this audit is to use a simple 5-question test:
As a rule of thumb, if a page gets fewer than three “yes” answers, treat it as a warning signal.
The goal of this audit is not to delete every page that fails. It is to see where your content is most exposed and where it still has a real reason to exist.
Pages that fail the test are good candidates for a deeper upgrade. Add something AI cannot easily recreate: original data, first-hand experience, screenshots, expert commentary, internal examples, customer insights, or a specific case study.
That kind of update takes more effort than a standard content refresh. But it is also the kind of work that moves a page from commodity content to something more defensible in AI search.
Identify every page carrying a nosnippet or max-snippet:0 directive and cross-reference it against your highest-authority, highest-impression pages. Any overlap represents a page that is categorically excluded from AI Overviews — not penalized, not deprioritized, but structurally ineligible regardless of quality or ranking position.
Some of those directives will be intentional and worth keeping. Others will be legacy tags applied at scale — through CMS templates, blanket robots configurations, or decisions made years ago under different strategic assumptions. The ones that fall into the second category are quick wins: remove the directive, restore snippet eligibility, reopen the page to the AI Overview pool.
If your site has many small pages targeting slight variations of the same topic, it may be better to merge them.
In AI search, one strong, in-depth page is more likely to be useful than ten thin pages covering tiny parts of the same subject.
Start by finding weak cluster pages: pages with little unique content, low engagement, and declining visibility. Then move their useful sections into a stronger cornerstone page instead of keeping them as separate URLs.
This also makes your site cleaner and easier for Google to crawl.
Reallocate any time being spent on llms.txt implementation, AI-specific schema research, or content "chunking" audits toward something that actually influences visibility. For Google Search specifically, none of these deliver a return. The guide is unambiguous on this.
If your site operates in an environment where other AI crawlers — Anthropic, Perplexity, OpenAI — matter for your traffic or brand exposure, llms.txt may still be worth maintaining for those systems. But keep that decision separate from your Google optimization work. Conflating them leads to misallocated effort.
Original research, proprietary data, case studies, and first-hand expert insights are the strongest forms of non-commodity content because they contain information AI cannot pull from the public web.
This does not mean every article needs a full research project. Even a small original dataset can help: customer survey results, product usage insights, internal benchmarks, or a documented client outcome.
For content teams, the shift is simple: stop only summarizing what already exists online. Start building workflows that capture what your team, customers, and product data uniquely know.
Google's guide explicitly names Merchant Center and Google Business Profile as input channels into AI responses — not just traditional search results. For product listings, local businesses, and service providers, these feeds are part of the AI visibility stack now.
Incomplete, outdated, or poorly structured product feeds and business profiles represent a gap that's worth closing before investing more in content.
You do not need to redesign your site for AI agents yet. But Google’s direction is clear: future agents will need to understand your site’s structure, buttons, headings, and content layout.
So the practical work is simple: keep your HTML clean, use a logical heading structure, label interactive elements properly, and make sure your pages are easy to understand beyond just visual design.
This is not only for AI. It also helps users, accessibility tools, and traditional crawlers.
Done now, it is basic technical hygiene. Left for later, it can become an expensive cleanup.
Many SEOs will read Google’s guide as reassurance: SEO still works, the fundamentals still matter, don’t panic.
That is true — but it is not the whole message.
Google is not saying nothing has changed. It is saying the weak parts of old SEO are becoming harder to hide. Thin, generic, technically optimized content is much easier for AI to summarize and replace.
Across the guide, Google keeps pointing to the same idea: content needs to contain something that could not have come from anywhere else. First-hand experience. Original data. A real opinion. A perspective based on actually doing the work.
That has always been good content. The difference is that, in AI search, it is becoming the only content with a durable future.
The real question is not: “What do we add to optimize for AI?”
It is: “Are we creating something useful enough that people — and AI systems — would miss it if it disappeared?”


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

