•
10-minute read

Google has many different tags that affect the crawler’s behavior one way or another. These tags give Google hints on how to index your pages, and if it should index them at all. And, of course, let Google properly understand your content and its value.
What’s more, Google has a habit of introducing new tags as time goes by. Still, Google’s recommendations on their usage on web pages may be kind of vague, and website owners may face some difficulties as to where to add the new tags and how.
Together with a comprehensive technical SEO audit, proper usage of Google tags helps ensure your website performs at its best and you're safe from sudden ranking drops.
In this guide, I’m going to overview what tags Google has, how they influence crawlers’ behavior, and how you can apply them on your pages. Let’s go.
Robots meta tags affect how Google shows the snippet of your page in search results. These tags are placed in the header of an HTML document. Actually, there’s only one tag — robots. All the rest (nofollow, noindex, etc.) are the directives you give Google to set a certain behavior pattern. However since Google guides also refer to these directives as tags, I’ll keep this name to keep things clear, too.
Note: To make all the robots tags work, do not include the pages they are used on into the robots.txt file. Otherwise, Google will not be able to see them.
Robots meta tags are:
The all tag is implied by default if you do not specify any other directives on your page. You may actually state it explicitly or not — nothing will change. The all tag tells Google that the page is fully available for indexation: all of its content can be crawled and indexed, and all the links on that page can be followed.
Example:
<meta name="robots" content="all">
The noindex tag prevents the page from appearing in SERPs. Google will still crawl it and follow all the links on the page if no other directives are implied.
You can use this tag to hide certain pages from indexation — these can be pages with private data, login pages, pages under development, etc.
Example:
<meta name="robots" content="noindex">
The nofollow tag does not let Google crawlers follow any links on the page. Still, Google will be able to index the page and pull it to SERPs.
Example:
<meta name="robots" content="nofollow">
If you need to both hide the page from SERPs and prevent crawling any links it has, you can combine the nofollow and noindex tags. Like this:
<meta name="robots" content="noindex, nofollow">
This tag is actually the same as nofollow and noindex combined. You can use it to prevent the page from appearing in Google SERPs and any of its links from being followed.
Example:
<meta name="robots" content="none">
Have you ever been in a situation when you click on a URL from a SERP, but then Google says that the page is unavailable and shows you the cached copy of that page from a certain date?
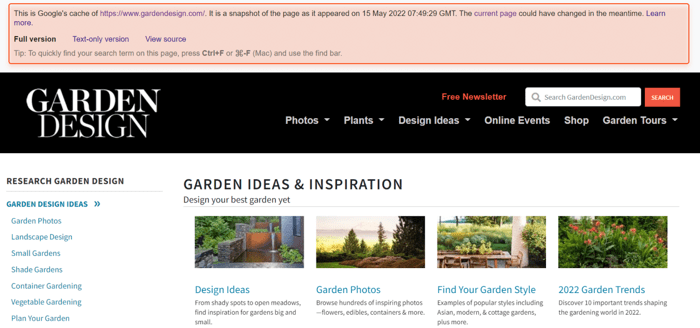
If you want to make sure Google will not show a cached copy of your page to users, add the noarchive tag.
Use this tag if you want to prevent access to a certain page in case (or after) this page is unavailable.
Example:
<meta name="robots" content="noarchive">
Google can display your internal sitelinks search box right on its SERPs. So people can do site search without directly visiting your website.
If you want users to visit your site before searching for anything on it, put the nositelinkssearchbox tag in the HTML of your homepage.
Example:
<meta name="robots" content="nositelinkssearchbox">
This is Google’s brand new thing. If you add the indexifembedded tag on your page, then the content from this page may be indexed if it is embedded on some other page through iframes or similar HTML tags.
Why may you need this tag? This is what Google says on the matter:
The indexifembedded tag addresses a common issue that especially affects media publishers: while they may want their content indexed when it's embedded on third-party pages, they don't necessarily want their media pages indexed on their own.
John Mueller dwells on the matter on Twitter:

A "common" (it's new, so there's nothing common yet :)) use-case would be widgets or embedded content, where you have a special URL for the embed that you don't want indexed, but you still want to allow the embedding page to use it for indexing. Eg, video embeds.
What does this actually mean? Say, you have page A with some sort of media with little context. This page A has a noindex tag. If you embed the content from page A to page B, this content will not be indexed, so page B will not be fully indexed, too. But if you add an indexifembedded tag on page A, then the embedded content will be indexed on page B. So page B is fully indexed.
Example:
<meta name="robots" content="noindex, indexifembedded">
The notranslate tag prevents Google from translating the snippet of your page into the language of the search query. If you don’t use this tag, Google will translate the page’s snippet and all the content of the clicked page. What’s more, Google will automatically translate all the links clicked from that page.
The thing is that all the interaction with your website in that case will be going through Google Translate. Although Google Translate is becoming more accurate day by day, and the quality of its translations is overall fine, some confusion may still happen.
So if your content is translation-sensitive, I’d suggest adding the notranslate tag to limit Google’s unpredictable creativity. In your turn, you can create several language versions of your website to make your content reach wider audiences.
Example:
<meta name="robots" content="notranslate">
This tag prevents Google from indexing any images on the page and pulling them to SERPs.
Example:
<meta name="robots" content="noimageindex">
This tag doesn’t let Google show the page in SERPs after some particular date.
You can use this tag on some event-related pages (season offers, discounts, promo campaigns, etc.), which will become irrelevant after a certain date.
Example:
<meta name="robots" content="unavailable_after: 2022-04-23">
A little of history: The nosnippet tag and the following three ones — max-snippet, max-image-preview, and max-video-preview — appeared due to the EU Copyright Directive introduced in France in 2019. The idea of this law was the following: big online platforms had to pay publishers for using extended parts of their content, and only very short extracts were allowed to use for free.


Initially, this law was only related to news publications, but later on spread across all types of content. So Google had nothing to do but let publishers specify if they did not want Google to pull much of their content into SERPs.
Apply the nosnippet tag if you do not want your page to have a text or video featured snippet. Keep in mind that the image snippet may still be shown on the SERP.
Why may you need this? Say, your page got a Google featured snippet, and if this snippet gives all the necessary information right on the SERP, then a user may not need to visit your site. For example, this is a common case if we google, say, song lyrics:
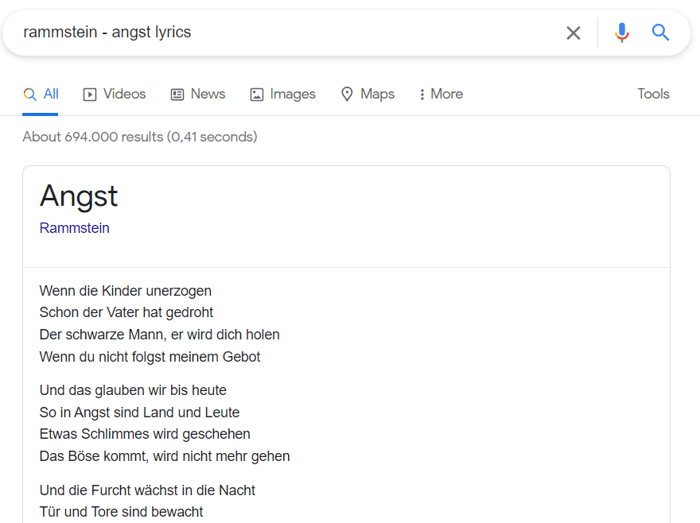
Users get your information from the SERP, so they don’t need to go anywhere else. This means that your page where the content is taken from doesn’t receive the traffic it could get. Still, using the nosnippet tag may be risky, as your competitors’ snippets may then outperform you and get more attention. Think wisely.
Example:
<meta name="robots" content="nosnippet">
This tag instructs Google on how many characters it can use in the snippet meta description. You can set the exact number, as well as:
Google will follow these tags in case it isn’t granted specific content usage permissions. This includes marking up your page with structured data or providing Google with a license agreement. Both these directives are more powerful than snippet-specific tags, so make sure you don’t apply them if you need to set up snippet limits.
Example:
<meta name="robots" content="max-snippet:20">
The max-image-preview tag lets you choose the image size to be displayed on SERPs. If you do not use this tag, then Google will use the default image size.
Three options to state here:
This tag applies to all search result types unless you've granted Google specific permissions (like when your content is an AMP or a canonical version of an article, or when you have a license agreement with Google).
Example:
<meta name="robots" content="max-image-preview:standard">
This tag lets you specify the exact length (seconds) of a video preview snippet.
Special options to state here:
Just like all the snippet-related tags, the max-video-preview applies to all types of search results.
Example:
<meta name="robots" content="max-video-preview:9">
These tags, or, to be clear, rel attributes in the <a> tag, are used to regulate link relationships between pages. Rel attributes are inline directives and are placed in the body of an HTML document in the relevant line.
As for now, Google has the following rel values:
Nofollow was initially introduced to mark paid, user-generated links, and the links you just don’t want Google to associate your site with. Links marked as nofollow did not pass PageRank and didn’t let Google crawl the linked page from your site.
The thing is that rel=”nofollow” has changed greatly since the day it was introduced. In 2019, Google confirmed that they treat nofollow links as a hint — thus Google crawlers can now decide on whether to visit these links (read as to pass PageRank) or not on their own.
So how should you use nofollow these days? Apply this value to the links to pages you don’t want to share PageRank with for any reason. These might be pages of your competitors or pages you don’t want Google to associate your website with. At the same time, it is not the best idea to link to any obviously low-quality pages even with nofollow links, as they still give Google the opportunity to visit the linked page.
Example:
<a rel="nofollow" href="https://mysite.com/my_page">my anchor</a>
Google recommends using rel="ugc" with the links to user-generated content. This is a relatively new tag (previously, nofollow was recommended for UGC).
Apply this tag if you are not sure about the quality of user-generated content. This type of content is actually hard to keep an eye on to be sure about anything, so keep your pages on the safe side.
Example:
<a rel="ugc" href="https://mysite.com/my_page">my anchor</a>
Still, SEOs have certain concerns if you should widely use the rel="ugc" attribute. One of the reasons for this is the statement of Google that says:
If you want to recognize and reward trustworthy contributors, you might remove this attribute from links posted by members or users who have consistently made high-quality contributions over time.
This implies the idea that, unlike nofollow, Google may treat rel="ugc" links as something not really valuable.


Rel="sponsored" attribute is recommended to use for paid and affiliate links.
This tag is also new; previously, Google recommended applying nofollow for this type of links.
Actually, rel="nofollow" is still acceptable for paid links, so you don’t need to manually change the attributes on your pages. Still, you’d better mark new paid links as sponsored.
Example:
<a rel="sponsored" href="https://mysite.com/my_page">my anchor</a>
A good question is actually why Google needs the new attributes when nofollow is still acceptable for all types of links. Probably the idea is that Google is going to treat these attributes (hints, as Google says) differently.
It’s also interesting that Google suggests examples of using multiple rel values at the same time. Like this:
<p>I hate <a rel="ugc nofollow" href="https://cheese.example.com/blue_cheese">Blue</a> cheese.</p>
Or like this:
<p>I hate <a rel="ugc sponsored" href="https://cheese.example.com/blue_cheese">Blue</a> cheese.</p>
This can only mean that Google will treat them differently for sure. It is still unclear what this difference is going to be (or is), but these tags do signalize something to Google.
Google likes to add new tags as time goes by or change recommendations for the old ones. So we’ll keep an eye on the world’s first search engine and get the information updated as soon as any new tag appears.
By the way, do you use any of those non-mandatory tags? If you do, please share in the comments what tags you use and in what cases.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

