237553
•
11 分で読めます
•


Web サイト上に存在するすべてのページをどのようにして見つけますか?最初に思い浮かぶのは、サイトのドメイン名を Google で検索することです。
しかし、インデックスに登録されなかった URL はどうなるでしょうか?それとも孤立したページでしょうか?それともWebキャッシュでしょうか?
Web サイト上のすべてのページを見つけるのは非常に簡単です。ただし、訪問者や検索ボットの目から隠されているページがあることを考慮すると、特別な注意が必要です。このガイドでは、サイトのすべてのページを検索する 8 つの異なる方法と使用するツールを示します。
Web サイト上のすべてのページを検索する方法は次のとおりです。
Web サイト上のすべてのページを検索する必要がある理由はたくさんあります。いくつか例を挙げると、
1. 新しいクライアントの Web サイトを監査し、インデックス作成の問題を見つけるため。
リンク切れ、サーバーエラー、ページ速度の遅さ、モバイルの使いやすさの悪さなどの技術的な問題により、Google はページをインデックスに登録できません。したがって、サイト監査により、サイトにいくつの URL があるのか、そしてそれらのどれに問題があるのかが明らかになります。最終的には、SEO がプロジェクトの将来の作業範囲を見積もるのに役立ちます。
2. 誤ってインデックスに登録されていない自分のサイトのページを検出するため。
ウェブサイトに重複コンテンツがある場合、Google は重複コンテンツをすべてインデックスに登録できない可能性があります。長いリダイレクト チェーンや 404 URL についても同様です。サイト上にリダイレクト チェーンが多数存在すると、クロール バジェットが無駄に消費されます。その結果、検索ボットがサイトを訪問する頻度が減り、全体的にインデックス付けが悪くなります。そのため、一般的には正常に見える場合でも、定期的な監査が必要です。
3. Google インデックス対象外のインデックス付きページを特定する。
管理者用のログイン ページ、開発中のページ、ショッピング カートなど、一部のページは検索インデックスに必要ありません。ただし、技術ファイル内のルールの矛盾やエラーにより、これらのページはユーザーの意志に反してインデックスに登録される可能性があります。たとえば、robots.txt のみに依存してページを禁止している場合でも、URL がクロールされて検索に表示される可能性があります。
4. 古くなったページを見つけて、コンテンツの完全な見直しを計画する。
Google はユーザーに可能な限り最高の結果を提供することを目指しているため、コンテンツの品質が低かったり、内容が薄かったり重複していたりすると、インデックスに登録されない可能性があります。まだ取り上げていないトピックを知るために、すべてのページのリストを用意しておくとよいでしょう。すべてのコンテンツ インベントリを手元に置くことで、コンテンツ戦略をより効果的に計画できるようになります。
5. 孤立したページを見つけてリンク戦略を計画する。
孤立したページは、受信リンクがないページです。そのため、ユーザーや検索ボットはめったにアクセスしないか、まったくアクセスしません。孤立したページは Google でインデックスに登録され、偶発的なユーザーを引き寄せる可能性があります。しかし、Web サイト上に多数の孤立したページがあると、Web サイトの権威が損なわれます。サイトの構造は明確ではなく、ページは役に立たない、または重要ではないように見える可能性があり、すべての枯れ木が Web サイト全体の可視性を低下させます。
6. Web サイトを再設計し、アーキテクチャを変更する。
Web サイトの再設計を計画し、ユーザー エクスペリエンスを向上させるには、まずすべてのページと関連する指標を見つける必要があります。
すべてのページの論理階層を含む明確で整理された構造は、検索エンジンがコンテンツを見つけやすくするのに役立ちます。したがって、すべての重要な URL は、ホームページから 1、2、または 3 回クリックするだけでアクセスできる必要があります。
ユーザー エクスペリエンスはクロールやランキングには影響しませんが、Web サイトの品質シグナルにとっては重要です。購入の成功、再訪問者の数、訪問者あたりのページビュー、その他の多数の指標は、Web サイトが訪問者にとってどれだけ役立つかを示します。
7. 競合他社のウェブサイトを分析するため。
競合他社のページを監査することで、競合他社の SEO 戦略をより深く掘り下げることができます。つまり、トラフィックの多いページ、最もリンクされているページ、最適な参照元などを明らかにすることができます。このようにして、貴重な洞察を得ることができ、競合他社にとってうまく機能することを学ぶことができます。 。彼らのテクニックを借りて結果を比較し、自分の Web サイトを改善する方法を確認できます。
Web サイト上のすべてのページを検索する方法はたくさんありますが、ケースごとに異なる方法を使用できます。それでは、それぞれの方法の長所と短所、そしてそれを手間なく使用する方法を見てみましょう。
Google 検索を使用すると、Web サイトのすべてのページをすばやく見つけることができます。検索バーに「サイト: ドメイン」と入力するだけで、Google がインデックスに登録した Web サイトのすべてのページを表示します。
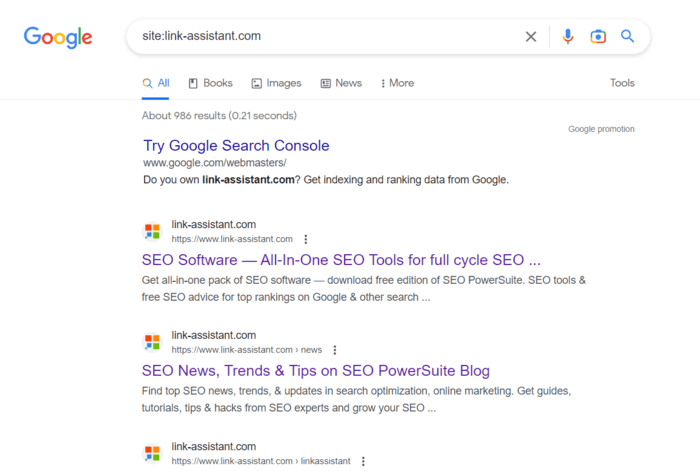
ただし、「site:」演算子によって表示される検索結果は、サイトのインデックス付けされたページの正確な数を必ずしも反映しているわけではないことに注意することが重要です。
まず、Google がすべてのページをクロールした直後にすべてのページをインデックスに登録するという保証はありません。さまざまな理由で特定のページをインデックスから除外する場合があります。たとえば、一部のページを重複または低品質と見なします。
次に、「site:」検索演算子には、Web サイトから削除されたページも表示される場合がありますが、それらは Google 上でキャッシュまたはアーカイブされたページとして保持されます。
したがって、「site:」検索クエリは、サイトの規模をおおよそ把握するのに適した開始点です。ただし、インデックスから欠落している可能性のある残りのページを見つけるには、他のツールが必要になります。
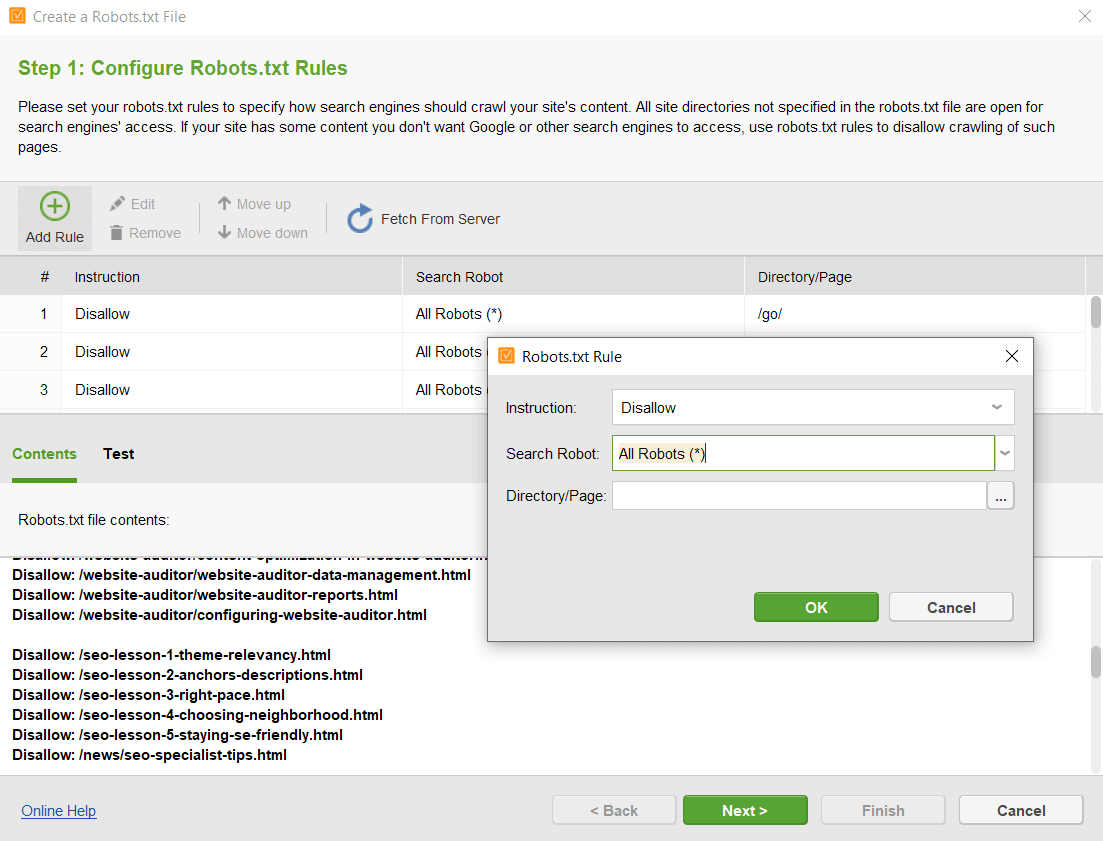
Robots.txt は、個々のページまたはディレクトリ全体の許可/不許可ルールを利用して、Web サイトをクロールする方法を検索ボットに指示する技術ファイルです。
したがって、このファイルにはサイト上のすべてのページが表示されるわけではありません。ただし、検索ボットによるアクセスが禁止されているページを見つけるのには役立ちます。
方法
robots.txt を使用して制限されたページを見つける方法の手順は次のとおりです。
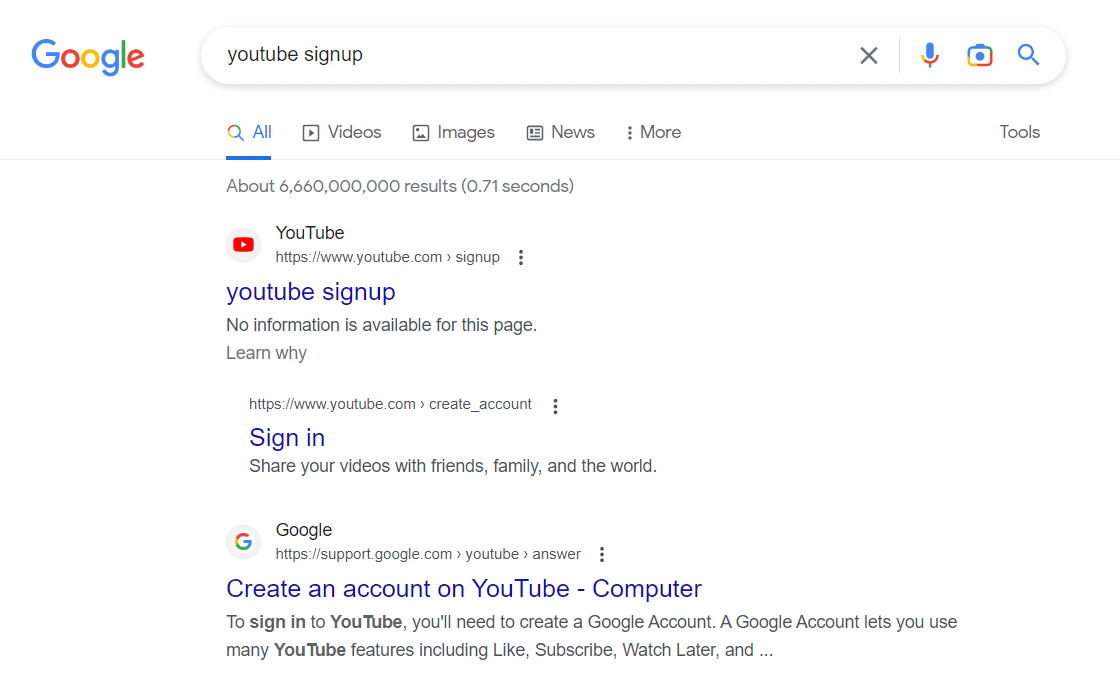
以下は YouTube のロボット ディレクティブの例です。
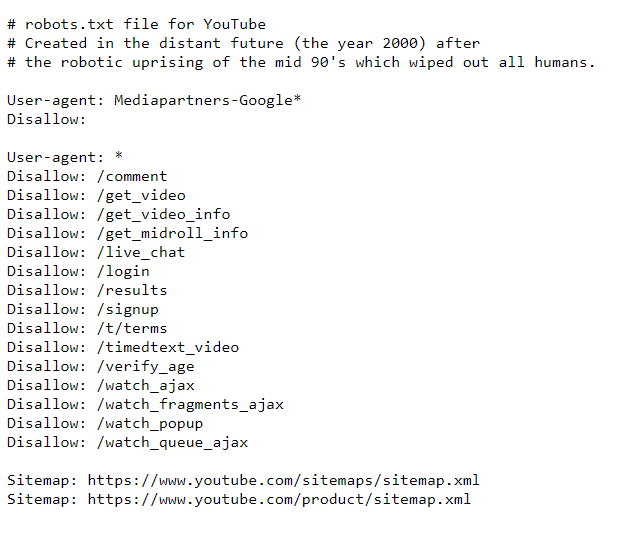
どのように動作するかを確認してください。たとえば、サインアップ ページは許可されません。ただし、Google で検索するとこの情報を取得できます。このページには説明的な情報がないことに注意してください。
robots.txt ルールを再チェックして、すべてのページが適切にクロールされていることを確認する必要があります。したがって、 それを確認するには、Google Search Console やサイト クローラーなどのツールが必要になる場合があります。それについては後ほど説明します。
これまでのところ、ファイルの目的について詳しく知りたい場合は、 Web ページをインデックスから非表示にするこのガイドをお読みください。
サイトマップは、Web マスターがサイトのインデックスを適切に作成するために使用するもう 1 つの技術ファイルです。このドキュメントは、多くの場合 XML 形式で、インデックスを作成する必要がある Web サイト上のすべての URL をリストします。サイトマップは、Web サイトの構造とコンテンツに関する貴重な情報源です。
大規模な Web サイトには複数のサイトマップがある場合があります。ファイルのサイズは 50,000 URL および 50 MB に制限されているため、ファイルをいくつかに分割して、ディレクトリ、画像、ビデオなどの個別のサイトマップを含めることができます。 ShopifyやWixなどの電子商取引プラットフォームサイトマップを自動的に生成します。その他の場合は、ファイルを作成するためのプラグインまたはサイトマップ ジェネレーター ツールがあります。
方法
とりわけ、 Web サイトのサイトマップを使用すると、その Web サイト上のすべてのページを簡単に見つけて、それらがインデックスに登録されていることを確認できます。


また、サイトマップにも問題がある可能性があるため、サイトマップが正しいかどうかを時々再確認する必要があります。サイトマップが空白であるか、404 コードで応答しているか、ずっと前にキャッシュされているか、単純に望ましくない間違った URL が含まれている可能性があります。インデックスに表示されます。
サイトマップを検証する良い方法は、Web サイト クロール ツールを使用することです。オンラインで利用できる Web サイト クローラー ツールはいくつかありますが、その 1 つであるWebSite Auditor は、サイト全体の監査のための強力な SEO ツールです。 Web サイト上のすべてのページを検索し、技術ファイルを検証するのにどのように役立つかを見てみましょう。
方法
WebSite Auditor を使用して Web サイト上のすべてのページを検索する方法は次のとおりです。
特定の検索ボットまたはユーザー エージェントの指示を指定できます。 URL パラメータを無視する、パスワードで保護されたサイトをクロールする、ドメインを単独でクロールするかサブドメインと一緒にクロールするなどをクローラーに指示します。
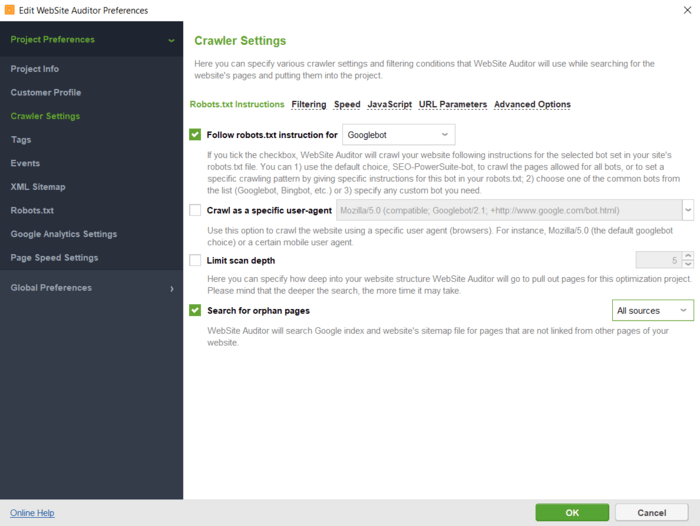
[OK]をクリックすると、ツールがサイトを監査し、 [サイト構造] > [ページ]セクションのすべてのページを収集します。
WebSite Auditor は、 URL が検索エンジンに対して適切に最適化されているかどうかを再チェックするのに役立ちます。セットアップは迅速で、インターフェースは非常に直感的であるため、数分でこのツールを理解できるようになります。
ここに短いビデオガイドがあります:
Web サイト クローリング ツールから何が得られるかを見てみましょう。
[すべてのページ]タブで、列ヘッダーをクリックすると、URL、タイトル、またはその他の列でリストを並べ替えることができます。
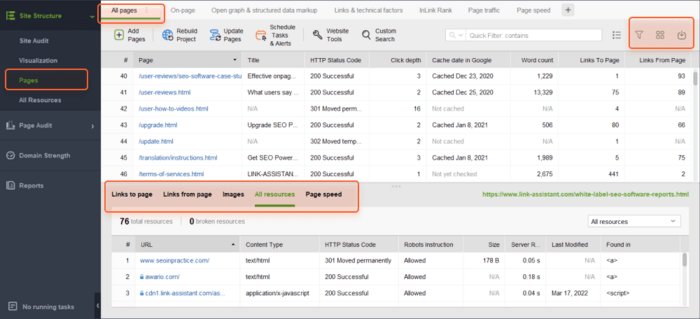
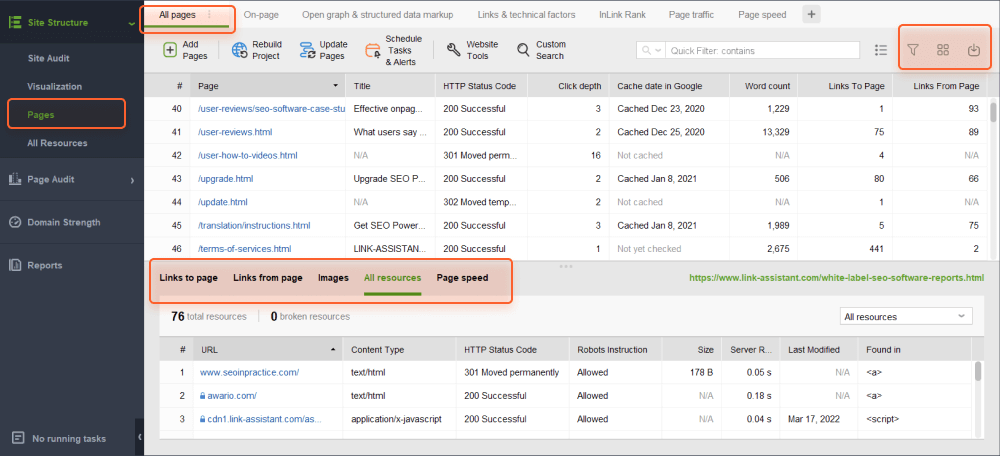
検索ボックスを使用して、キーワードまたはページ URL でページのリストをフィルタリングできます。これは、特定のページまたはページのグループを探している場合に役立ちます。
さらに、表示可能な列を追加して、メタ タグ、見出し、キーワード、リダイレクト、その他のページ上の SEO 要素など、このページに関する詳細情報を表示できます。
最後に、任意の URL をクリックして、ワークスペースの下半分にあるページ上のすべてのリソースを調べることができます。
すべてのデータはツール内で処理することも、CSV または Excel 形式でコピー/エクスポートすることもできます。
[サイト監査]セクションには、次のようなエラーの種類ごとに分割されたページのリストが表示されます。
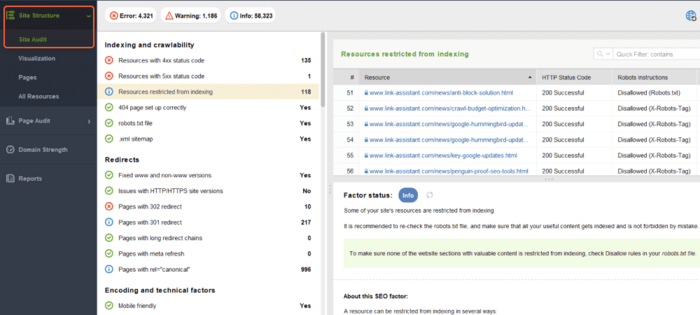
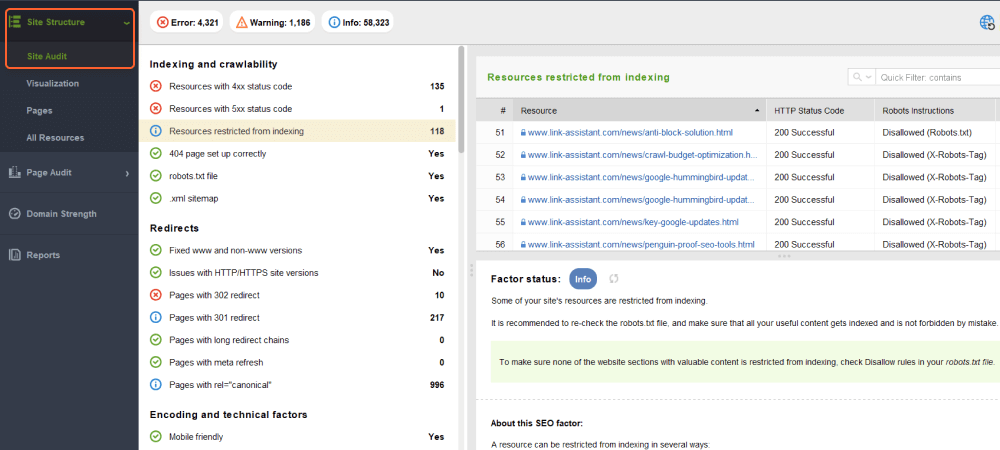
問題の種類ごとに、この要素が重要である理由の説明と、それを修正する方法に関するいくつかの提案が表示されます。
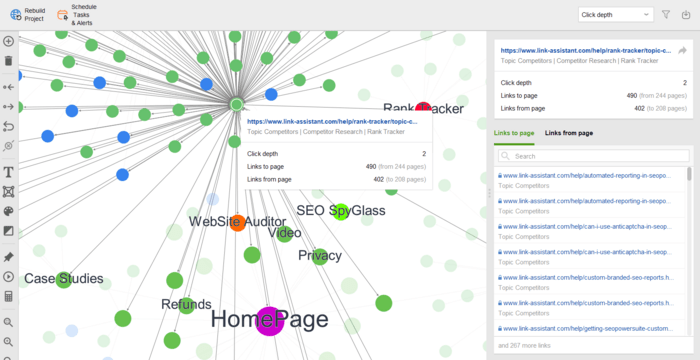
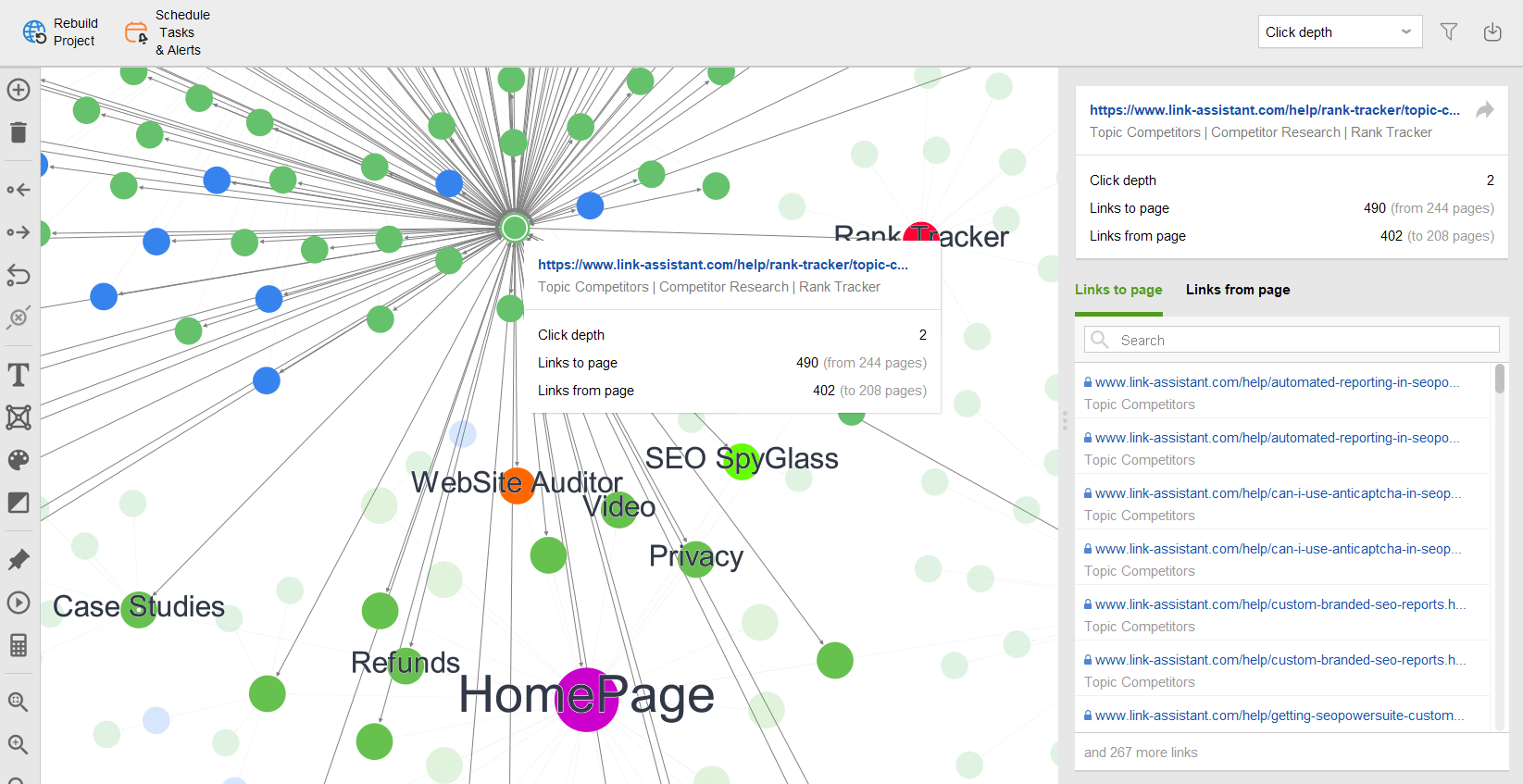
さらに、 [サイト構造] > [視覚化]でビジュアル サイトマップを調べることができ、すべての URL 間の関係が表示されます。インタラクティブなマップを使用すると、ページやリンクを追加または削除して、サイトの構造を調整できます。内部 PageRank 値を再計算し、ページビュー (Google Analytics によって追跡される) を確認できます。
それに加えて、 WebSite Auditor はrobots.txt ファイルとサイトマップの両方が利用可能かどうかもチェックします。
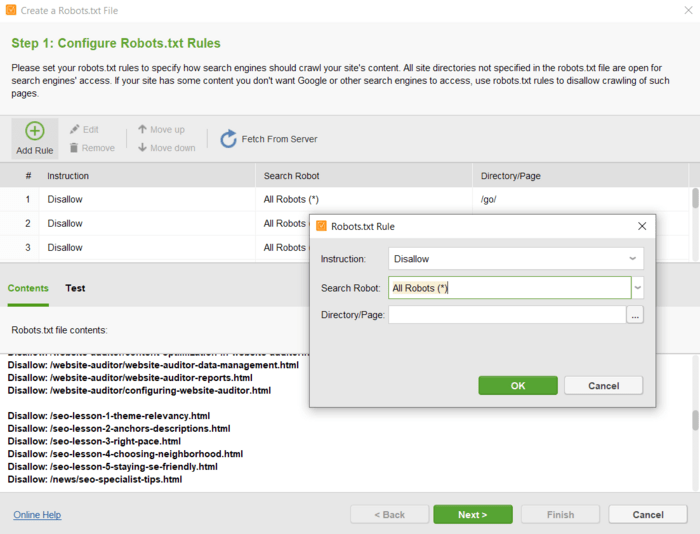
これにより、 Web サイト ツールで技術ファイルを編集し、適切な設定でサイトに直接アップロードできます。
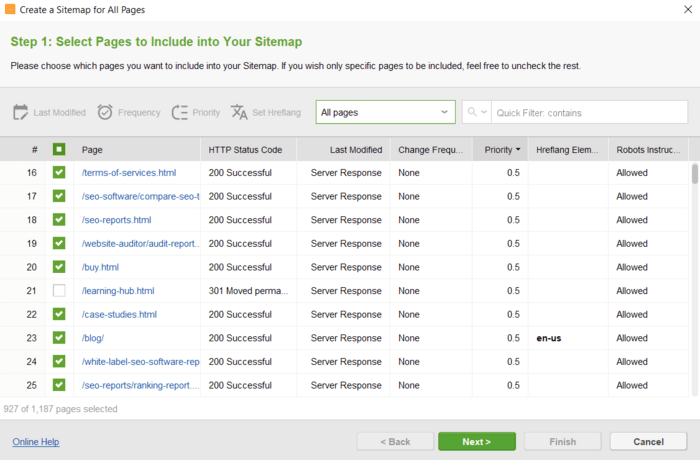
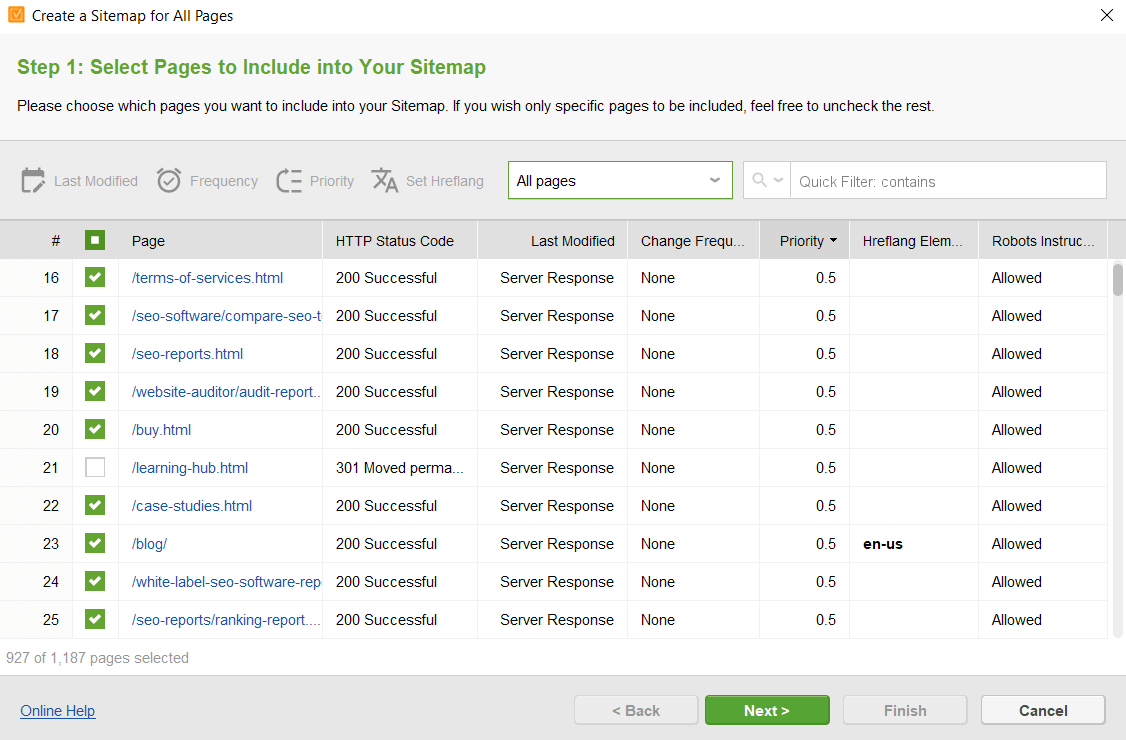
ファイルを編集するときに特別な構文に従う必要はありません。必要な URL を選択し、必要なルールを適用するだけです。次に、クリックしてファイルを生成し、コンピュータに保存するか、FTP 経由でサイトにアップロードします。
サイトのすべてのページを検索できるもう 1 つの優れたツールは、Google Search Console です。これは、ページのインデックス付けをチェックし、検索ボットがこれらの URL を正しくインデックス付けするのを妨げている問題を明らかにするのに役立ちます。
方法
まだインデックスが作成されていないページも含め、インデックス作成ステータスごとにすべてのページの内訳を取得できます。
Search Console でサイトのすべてのページを検索する方法は次のとおりです。
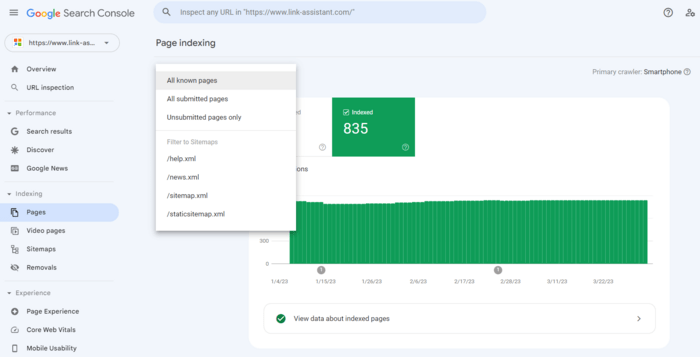
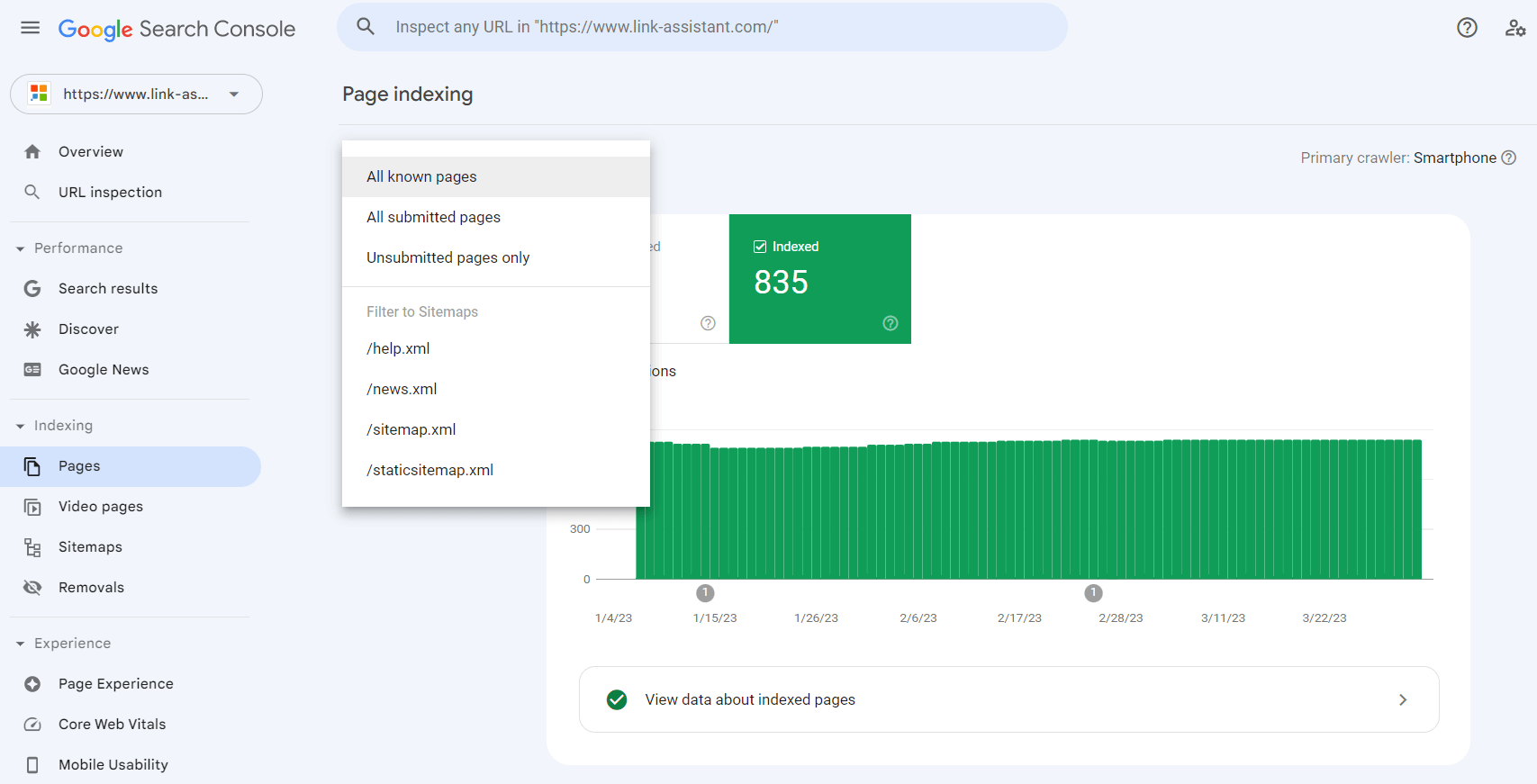
1.インデックス作成レポートに移動し、 [インデックス付けされたページに関するデータの表示]をクリックします。検索ボットが Web サイト上で最後にクロールしたすべてのページが表示されます。ただし、テーブルには最大 1,000 個の URL という制限があることに注意してください。送信されたすべての URL などからすべての既知のページを並べ替えるクイック フィルターがあります。
2. [インデックスなし]タブを有効にします。以下のツールは、各 URL がインデックスに登録されない理由の詳細を示します。
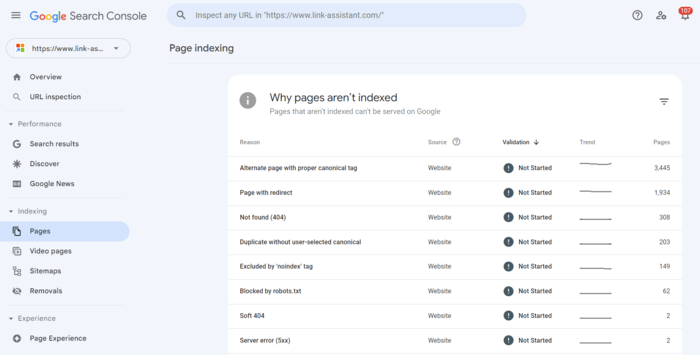
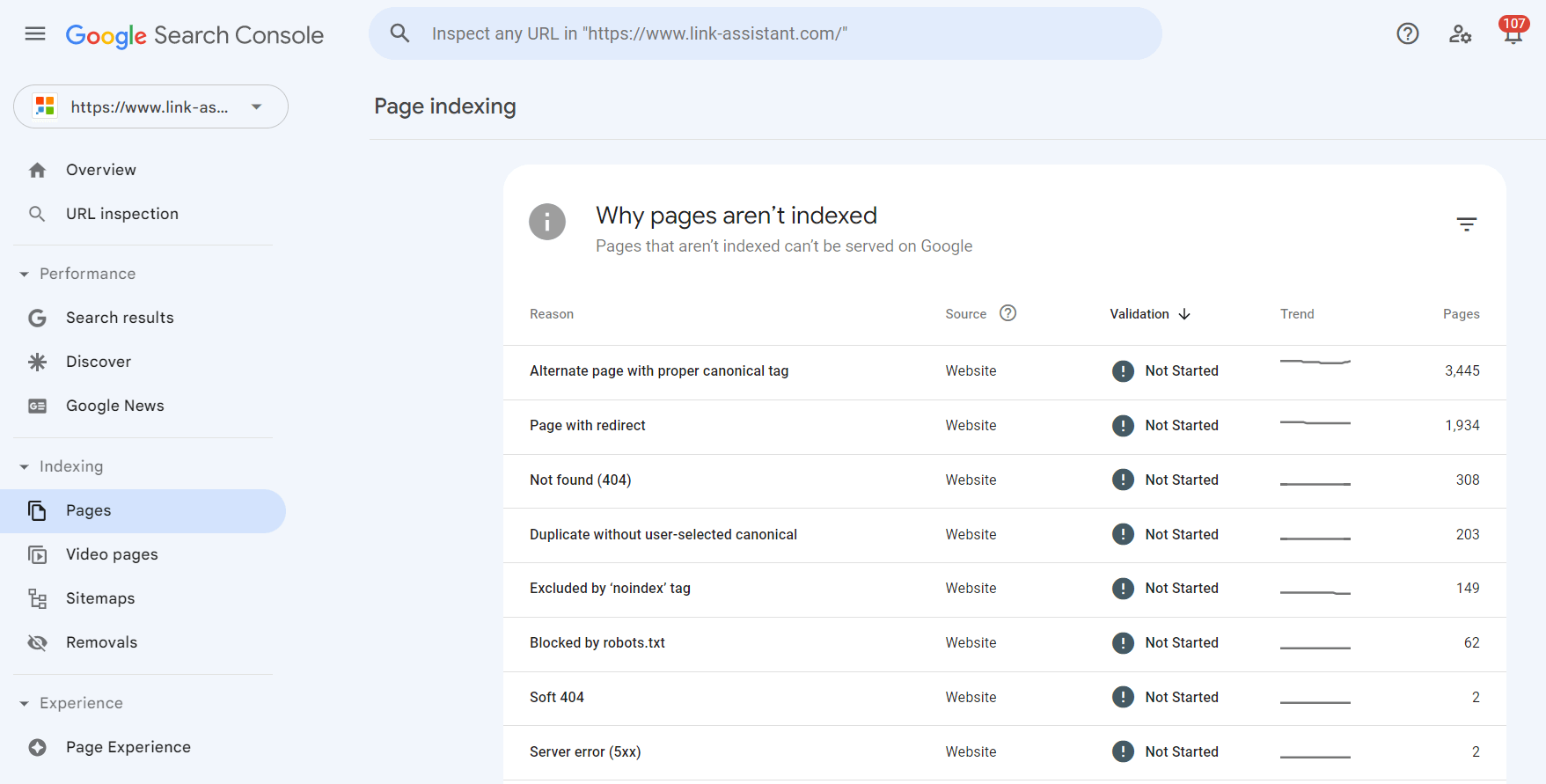
各理由をクリックすると、問題の影響を受ける URL が表示されます。
問題は、ページのメイン URL だけでなく、アンカー リンク、ページネーション ページ、URL パラメーター、および手動での並べ替えが必要なその他のゴミも取得してしまうことです。また、テーブルのエントリ数は 1,000 に制限されているため、リストは不完全になる可能性があります。
とりわけ、さまざまな検索エンジンには他のインデックス作成ルールがある可能性があり、そのような問題を見つけて処理するには、そのウェブマスター ツールを使用する必要があることに注意してください。たとえば、 Bing Webmasterツール、 Yandex Webmaster 、 Naver Webmasterなどを使用して、それぞれの検索エンジンのインデックス作成をチェックします。
Google Analytics は最も広く使用されている分析プラットフォームの 1 つであるため、Web サイトの所有者や編集者なら誰でもよく知っていると思います。古き良きユニバーサル アナリティクスは間もなく Google アナリティクス 4 に置き換えられます。そこで、ツールの両方のバージョンを見てみましょう。
方法
Google のユニバーサル アナリティクスでサイトのページを収集するには、次の手順に従います。
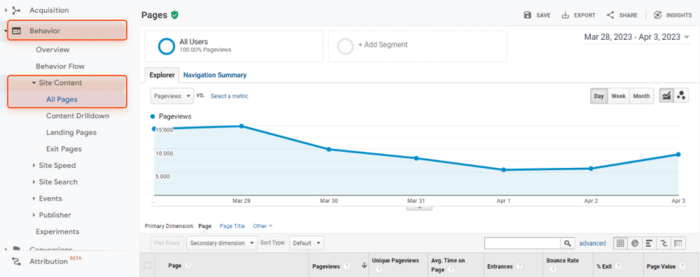
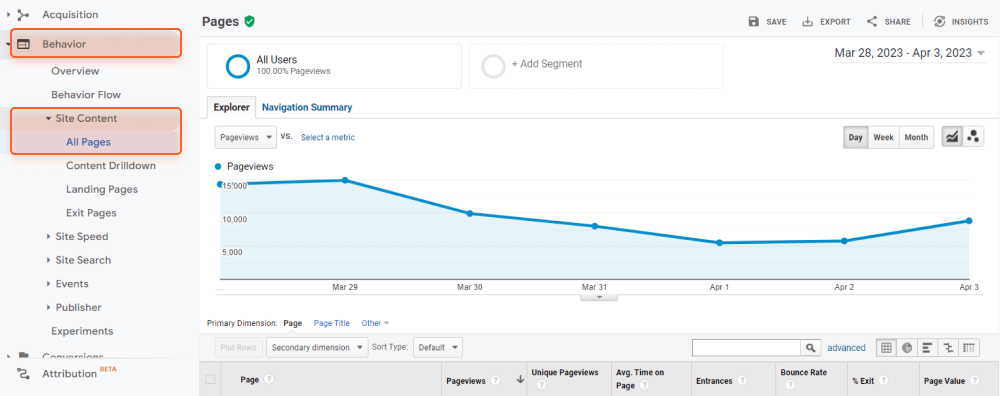
ページビュー、直帰率、ページの平均滞在時間などのユーザー行動統計を含むページが表示されます。常にページビュー数が最も少ないページに注目してください。おそらく、それらは孤立したページです。
Google アナリティクス 4で同様のフローを再作成するには:
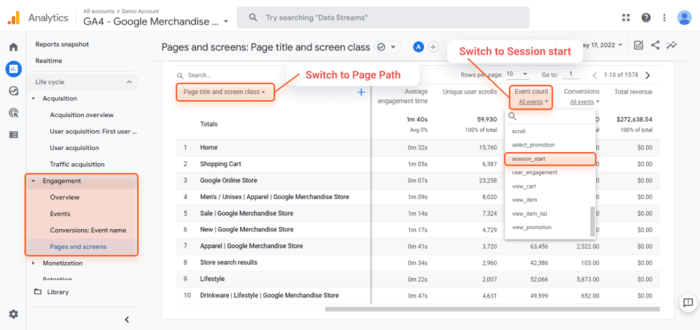
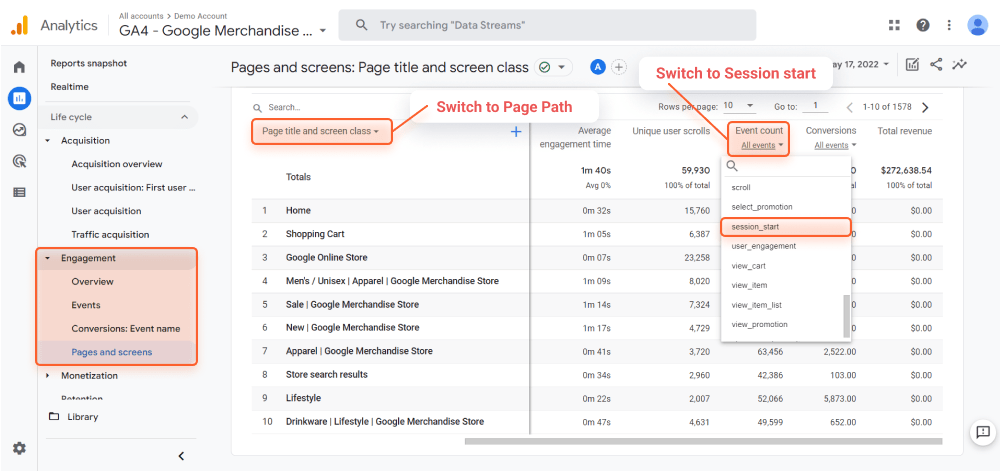
コンソールと同様に、URL パラメーターなどが含まれます。ページの上部にある[エクスポート]ボタンをクリックすると、ページのリストを CSV または Excel シートとしてエクスポートできます。
一部の Web サイトは非常に巨大で、強力な SEO スパイダーでもすべてのページをクロールするのは難しい場合があります。ログ分析は、大規模な Web サイト上のすべてのページを検索して調査する場合に適したオプションです。
Web サイトのログ ファイルを分析すると、Web からの訪問者を獲得したすべてのページ、その HTTP 応答、クローラーがページを訪問する頻度などを特定できます。
ログ ファイルはサーバー上に保存されるため、ログ ファイルを取得するには必要なレベルのアクセス権とログ アナライザー ツールが必要です。したがって、この方法は、技術に精通した人、ウェブマスター、開発者により適しています。
方法
ログ分析を使用してサイトのすべてのページを検索する手順は次のとおりです。
Web サイト上のすべてのページを検索するもう 1 つの方法は、コンテンツ管理システム (CMS)を参照することです。CMS には、一度作成した Web サイト上のすべての URLが含まれています。 CMS の例としては、ニュースやブログ、電子商取引、企業サイトなど、さまざまなドメインでコンテンツを編集するための Web サイト構築ツールが含まれるWordpressや Squarespace があります。
方法
CMS は外観によって大きく異なりますが、一般的な手順はほとんどの CMS に適用されます。
カテゴリ、ブログ投稿、ランディング ページなど、CMS のさまざまなセクションに属するさまざまな種類のページが存在する可能性があることに注意してください。
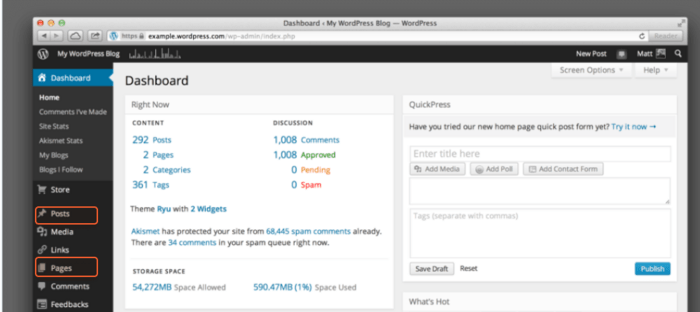
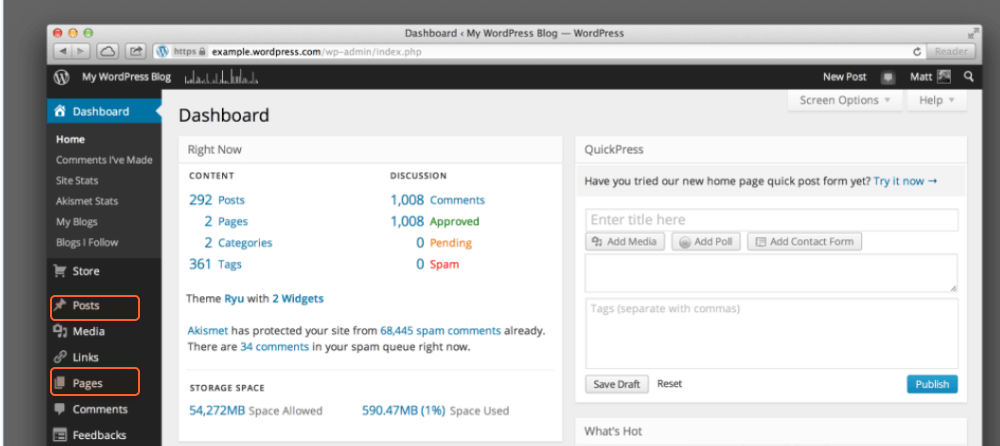
ほとんどの CMS では、作成日、作成者、カテゴリ、またはその他の基準で URL を並べ替えることができます。検索ボックスを使用して、キーワードまたはタイトルでページのリストをフィルタリングすることもできます。
Web サイト上のすべてのページを検索するには、さまざまな方法とツールがあります。どちらを選択するかは、目的と行う作業の範囲によって異なります。
このリストがお役に立てば、SEO の初心者でもサイトのすべてのページを簡単に収集できるようになります。
まだ答えられていない質問がある場合は、 Facebook のユーザー グループでお気軽に質問してください。



