237556
•
11 minuten gelezen
•


Hoe vind je alle bestaande pagina's op een website? Het eerste idee dat in je opkomt is om de domeinnaam van de site te googlen.
Maar hoe zit het met URL's die niet worden geïndexeerd? Of weespagina's? Of webcache?
Het vinden van alle pagina's op een website is vrij eenvoudig; Het vereist echter wat extra aandacht, aangezien er pagina's zijn die verborgen zijn voor de ogen van bezoekers of zoekbots. Deze gids toont 8 verschillende methoden om alle pagina's van de site te vinden, samen met de tools die u kunt gebruiken.
Zo kunt u alle pagina's op een website vinden:
Er zijn talloze redenen waarom u mogelijk alle pagina's op een website moet vinden. Om er een paar te noemen:
1. Om de website van een nieuwe klant te controleren en indexeringsproblemen op te sporen.
Technische problemen zoals verbroken links, serverfouten, lage paginasnelheid of slechte mobiele bruikbaarheid zorgen ervoor dat Google de pagina's niet kan indexeren. Site-audits laten dus zien hoeveel URL's een site heeft en welke daarvan problematisch zijn. Uiteindelijk helpt het SEO's om de omvang van toekomstige werkzaamheden in het project in te schatten.
2. Om de pagina's van uw eigen site te detecteren die niet per ongeluk zijn geïndexeerd.
Als uw website dubbele inhoud bevat, kan Google mogelijk niet alle dubbele inhoud indexeren. Hetzelfde geldt voor lange redirect-ketens en 404-URL’s: als er veel op een site staan, wordt het crawlbudget tevergeefs uitgegeven. Als gevolg hiervan bezoeken de zoekbots de site minder vaak en wordt deze over het algemeen slechter geïndexeerd. Daarom zijn regelmatige audits nodig, zelfs als iets er over het algemeen normaal uitziet.
3. Om geïndexeerde pagina's te herkennen die niet bedoeld zijn voor indexering door Google.
Sommige pagina's zijn niet nodig in de zoekindex, bijvoorbeeld inlogpagina's voor beheerders, pagina's in ontwikkeling of winkelwagentjes. Toch kunnen deze pagina's tegen uw wil worden geïndexeerd vanwege tegenstrijdige regels of fouten in uw technische bestanden. Als u bijvoorbeeld uitsluitend op robots.txt vertrouwt om een pagina niet toe te staan, kan de URL nog steeds worden gecrawld en in de zoekresultaten worden weergegeven.
4. Om verouderde pagina's te vinden en een volledige inhoudsrevisie te plannen.
Google streeft ernaar zijn gebruikers de best mogelijke resultaten te bieden, dus als uw inhoud van slechte kwaliteit, dun of dubbel is, kan het zijn dat deze niet wordt geïndexeerd. Het is goed om een lijst te hebben van al uw pagina's, zodat u weet welke onderwerpen u nog niet heeft behandeld. Met al uw contentinventaris bij de hand, kunt u uw contentstrategie effectiever plannen.
5. Om weespagina's te vinden en koppelingsstrategieën te plannen.
Orphans zijn pagina's zonder inkomende links, waardoor gebruikers en zoekbots ze zelden of helemaal niet bezoeken. Weespagina's kunnen in Google worden geïndexeerd en onbedoelde gebruikers aantrekken. Een groot aantal verweesde pagina's op een website doet echter afbreuk aan zijn autoriteit: de structuur van de site is niet kristalhelder, de pagina's kunnen er nutteloos of onbelangrijk uitzien, en al het dode hout zal de totale zichtbaarheid van de website aantasten.
6. Om een website opnieuw te ontwerpen en de architectuur ervan te veranderen.
Om het herontwerp van een website te plannen en de gebruikerservaring te verbeteren, moet u eerst alle pagina's en relevante statistieken vinden.
Een duidelijke en georganiseerde structuur met een logische hiërarchie van alle pagina's kan zoekmachines helpen uw inhoud gemakkelijker te vinden. Alle belangrijke URL's moeten dus binnen één, twee of drie klikken vanaf de startpagina bereikbaar zijn.
Hoewel de gebruikerservaring geen invloed heeft op het crawlen en de ranking, is deze wel van belang voor de kwaliteitssignalen van uw website: succesvolle aankopen, het aantal terugkerende bezoekers, paginaweergaven per bezoeker en nog veel meer andere statistieken laten zien hoeveel uw website nuttig is voor de bezoekers.
7. Om websites van concurrenten te analyseren.
Door de pagina's van uw concurrenten te controleren, kunt u dieper ingaan op hun SEO-strategieën: onthul hun pagina's met het meeste verkeer, de meest gelinkte pagina's, de beste verwijzingsbronnen, enz. Op deze manier krijgt u waardevolle inzichten en leert u dat dit goed werkt voor uw concurrenten.. U kunt hun technieken lenen en de resultaten vergelijken om te zien hoe u uw eigen website kunt verbeteren.
Er zijn veel manieren om alle pagina's op een website te vinden, maar voor elk geval kunt u daarvoor een andere methode gebruiken. Laten we dus eens kijken naar de voor- en nadelen van elke methode en hoe u deze zonder gedoe kunt toepassen.
Met Google Zoeken kunt u snel alle pagina's van een website vinden. Voer eenvoudigweg "site: uw domein" in de zoekbalk in en Google toont u alle pagina's van de website die het heeft geïndexeerd.
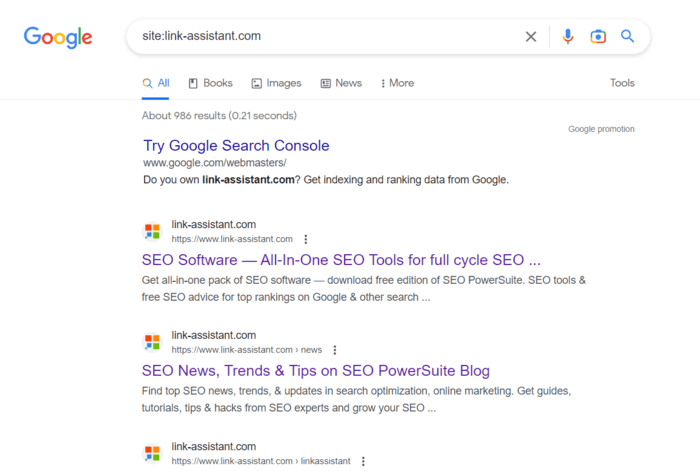
Het is echter belangrijk om te onthouden dat de zoekresultaten die worden weergegeven door de operator 'site:' niet noodzakelijkerwijs het exacte aantal geïndexeerde pagina's van uw site weerspiegelen.
Ten eerste is er geen garantie dat Google elke pagina direct nadat deze is gecrawld, zal indexeren. Het kan om verschillende redenen bepaalde pagina's uitsluiten van de index: het beschouwt sommige pagina's bijvoorbeeld als dubbel of van lage kwaliteit.
Ten tweede kan de zoekoperator 'site:' ook pagina's weergeven die van uw website zijn verwijderd, maar deze worden bewaard als in het cachegeheugen opgeslagen of gearchiveerde pagina's op Google.
Daarom is de zoekopdracht 'site:' een goed begin om een globaal beeld te krijgen van hoe groot uw site is. Maar om de rest van de pagina's te vinden die mogelijk ontbreken in de index, hebt u een aantal andere hulpmiddelen nodig.
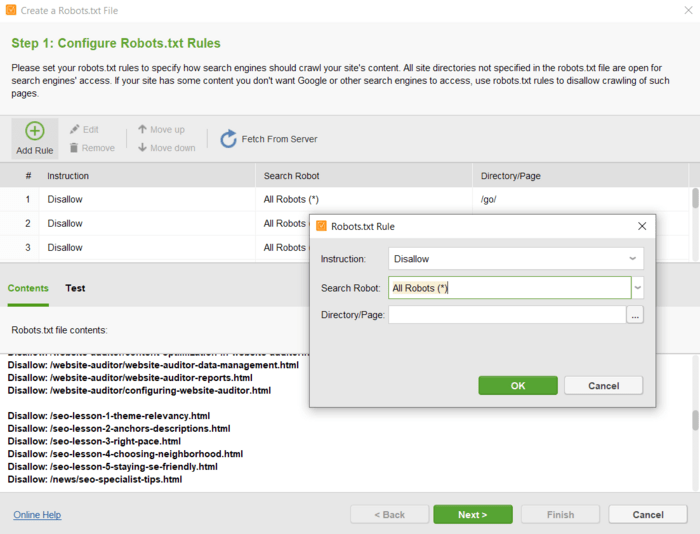
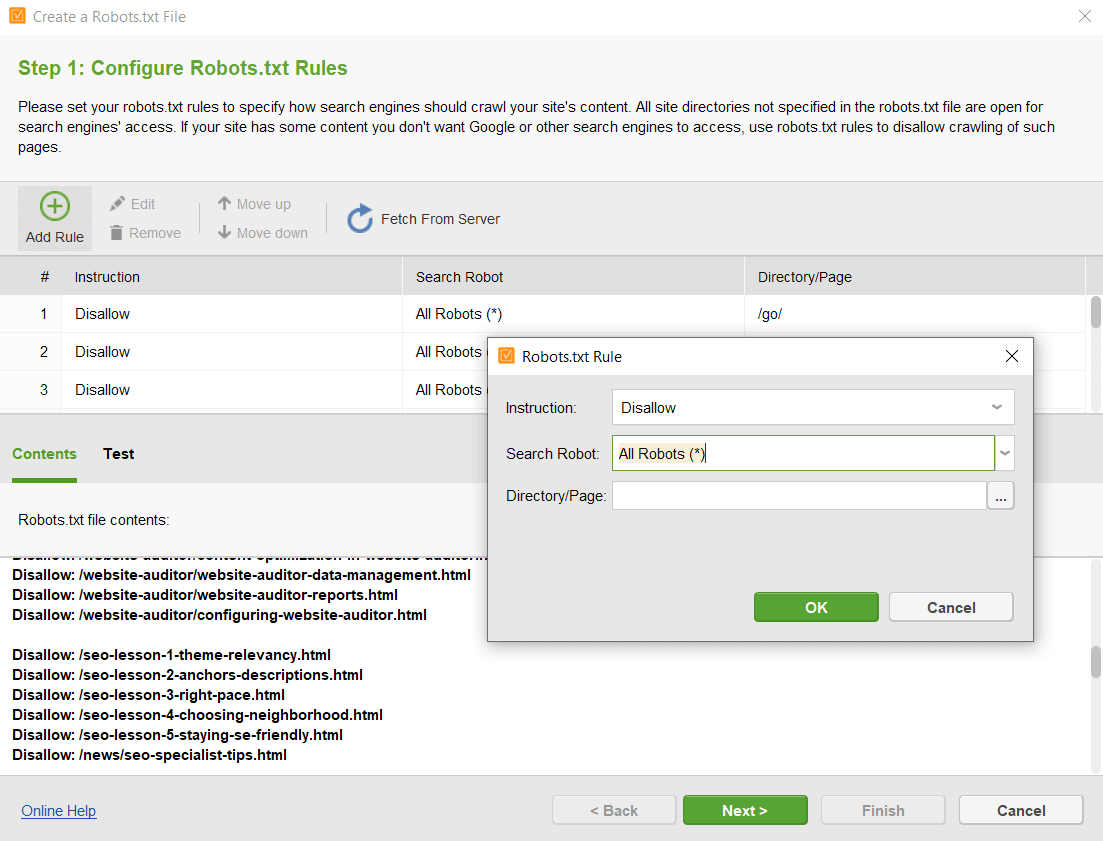
Robots.txt is een technisch bestand dat zoekbots instrueert hoe ze uw website moeten crawlen, met behulp van de regels voor toestaan/niet toestaan voor individuele pagina's of hele mappen.
Het bestand toont dus niet alle pagina's op uw site. Het kan u echter helpen pagina's te vinden die niet toegankelijk zijn voor zoekbots.
Hoe
Hier volgen de stappen voor het vinden van de beperkte pagina's met behulp van robots.txt:
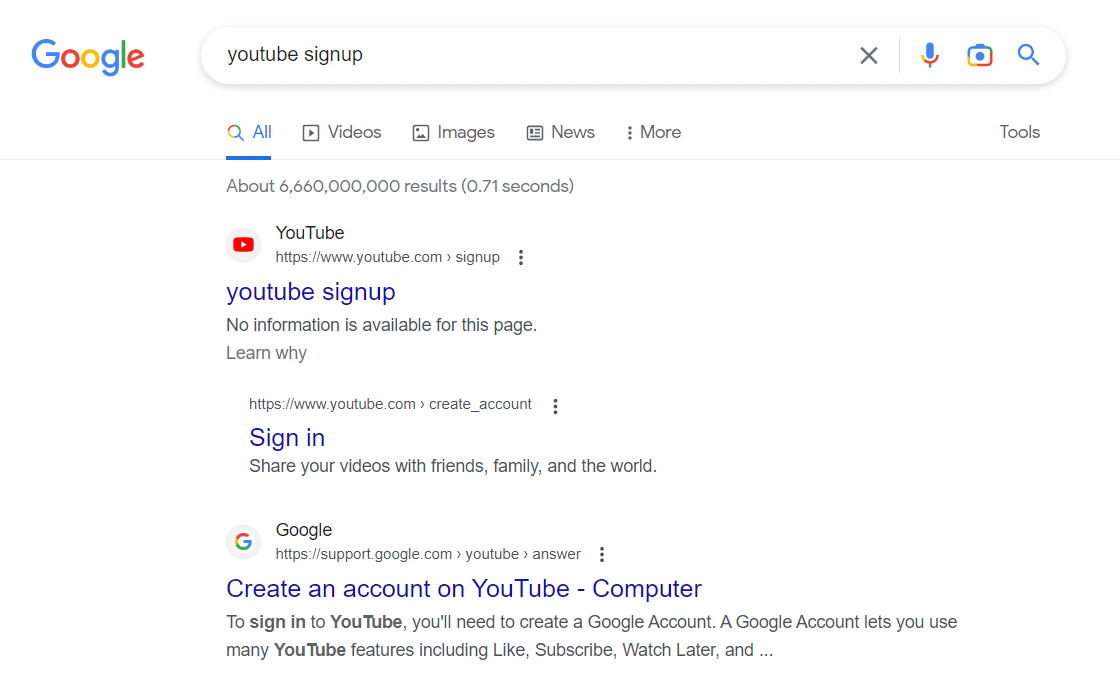
Hier is een voorbeeld van robotsrichtlijnen voor YouTube.
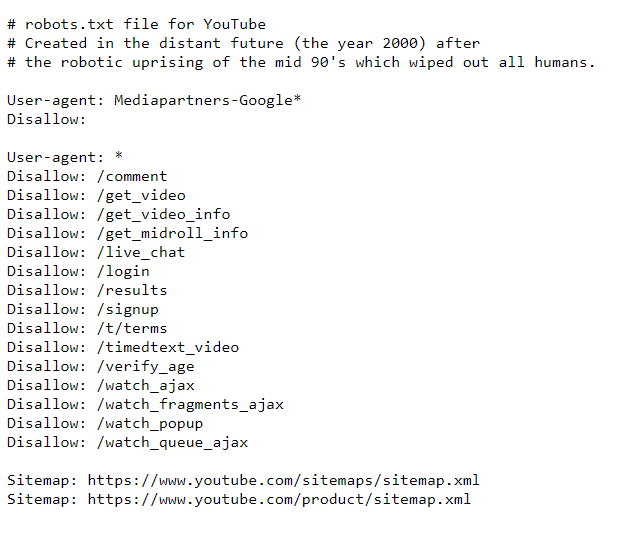
Controleer hoe het werkt. De aanmeldingspagina is bijvoorbeeld niet toegestaan. U kunt deze echter nog steeds krijgen wanneer u op Google zoekt. Merk op dat er geen beschrijvende informatie beschikbaar is voor de pagina.
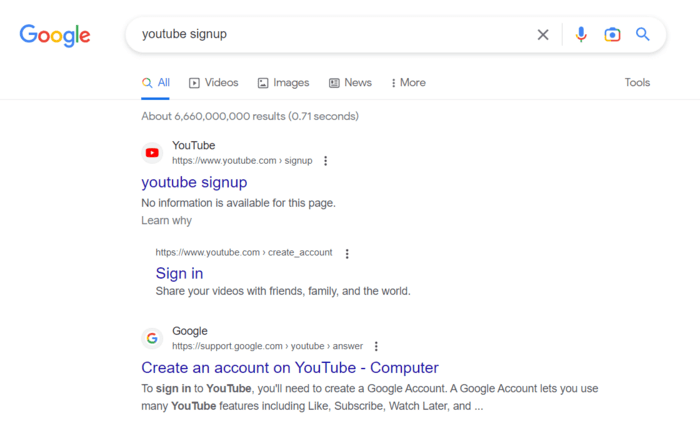
Het is noodzakelijk om uw robots.txt-regels opnieuw te controleren om er zeker van te zijn dat al uw pagina's correct worden gecrawld. Mogelijk hebt u dus een tool zoals Google Search Console of een sitecrawler nodig om deze te beoordelen. Ik zal er zo even bij stilstaan.
En als je tot nu toe meer wilt weten over het doel van het bestand, lees dan deze handleiding over het verbergen van webpagina's voor indexering.
Een sitemap is een ander technisch bestand dat webmasters gebruiken voor een goede site-indexering. Dit document, vaak in XML-formaat, vermeldt alle URL's op een website die geïndexeerd moeten worden. Een sitemap is een waardevolle bron van informatie over de structuur en inhoud van een website.
Grote websites kunnen meerdere sitemaps hebben: aangezien het bestand qua grootte beperkt is tot 50.000 URL's en 50 MB, kan het in meerdere worden opgesplitst en een aparte sitemap bevatten voor mappen, afbeeldingen, video's, enz. E-commerceplatforms zoals Shopify of Wix automatisch sitemaps genereren. Voor anderen zijn er plug-ins of sitemapgeneratortools om de bestanden te maken.
Hoe
Met de sitemap van een website kunt u bijvoorbeeld gemakkelijk alle pagina's vinden en ervoor zorgen dat ze worden geïndexeerd:


Je moet ook zo nu en dan de juistheid van je sitemap opnieuw controleren, omdat deze ook problemen kan hebben: deze kan leeg zijn, reageren met een 404-code, lang geleden in de cache zijn opgeslagen, of het kan eenvoudigweg de verkeerde URL's bevatten die je niet wilt. in de index verschijnen.
Een goede methode om uw sitemap te valideren is door een website-crawltool te gebruiken. Er zijn verschillende websitecrawlertools online beschikbaar, en een daarvan is WebSite Auditor, een krachtige SEO-tool voor sitebrede audits. Laten we eens kijken hoe u hiermee alle pagina's op een website kunt vinden en technische bestanden kunt valideren.
Hoe
Zo kunt u WebSite Auditor gebruiken om alle pagina's op uw website te vinden:
U kunt de instructies voor een bepaalde zoekbot of user-agent opgeven; vertel de crawler dat hij URL-parameters moet negeren, een met een wachtwoord beveiligde site moet crawlen, een domein alleen of samen met subdomeinen moet crawlen, enz.
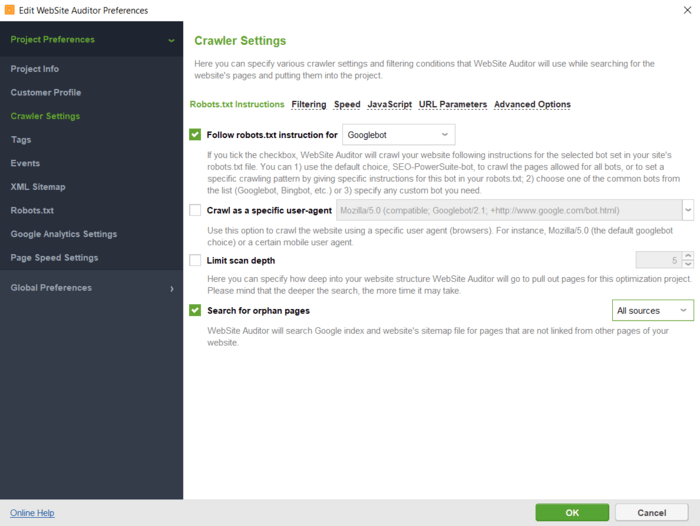
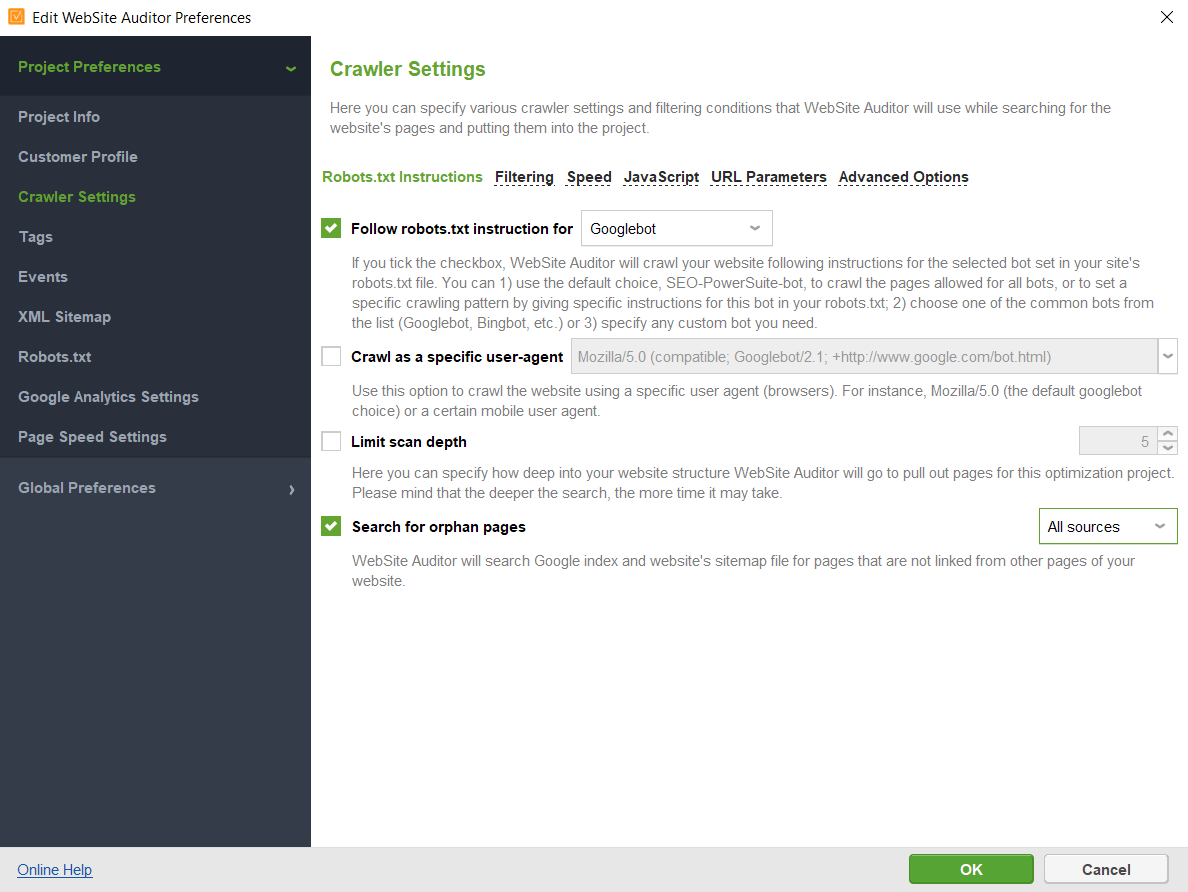
Nadat u op OK hebt geklikt, controleert de tool uw site en verzamelt alle pagina's in de sectie Sitestructuur > Pagina's.
WebSite Auditor helpt u opnieuw te controleren of de URL's correct zijn geoptimaliseerd voor zoekmachines. U zult de tool binnen een paar minuten leren kennen, omdat de installatie snel is en de interface behoorlijk intuïtief is.
Hier is een korte videohandleiding voor u:
Laten we eens kijken wat u kunt bereiken met de websitecrawltool.
Op het tabblad Alle pagina's kunt u de lijst sorteren op URL, titel of een andere kolom door op de kolomkop te klikken.
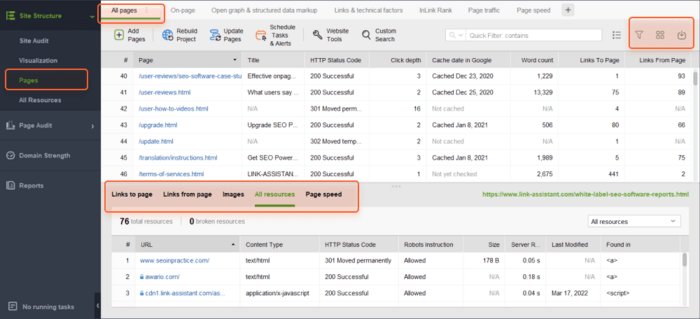
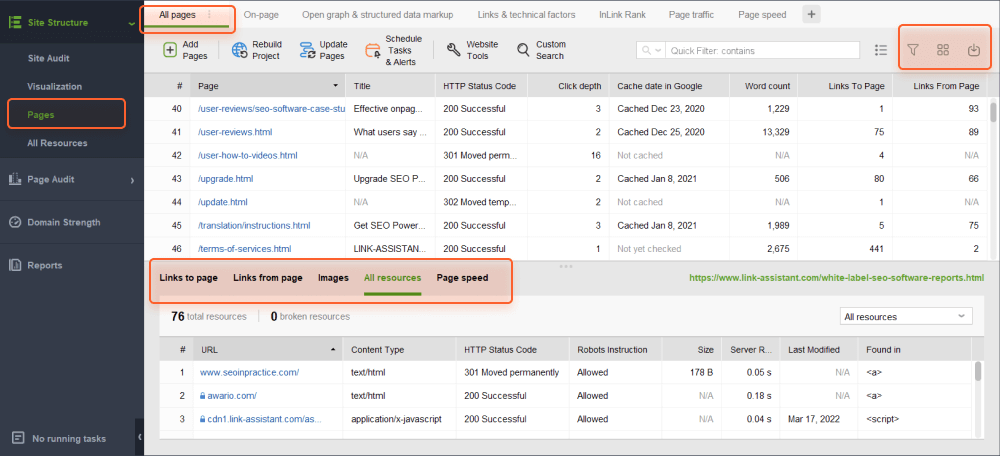
U kunt het zoekvak gebruiken om de lijst met pagina's te filteren op trefwoord of pagina-URL. Dit kan handig zijn als u naar een specifieke pagina of een groep pagina's zoekt.
Bovendien kunt u zichtbare kolommen toevoegen om meer informatie over deze pagina weer te geven, zoals metatags, koppen, trefwoorden, omleidingen of andere SEO-elementen op de pagina.
Ten slotte kunt u op een willekeurige URL klikken om alle bronnen op de pagina in de onderste helft van de werkruimte te bekijken.
Alle gegevens kunnen in de tool worden verwerkt of worden gekopieerd/geëxporteerd in CSV- of Excel-formaat.
In het gedeelte Sitecontrole worden lijsten met pagina's weergegeven, opgesplitst op type fouten, zoals:
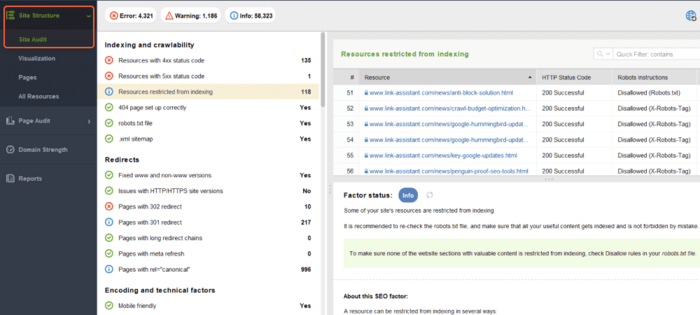
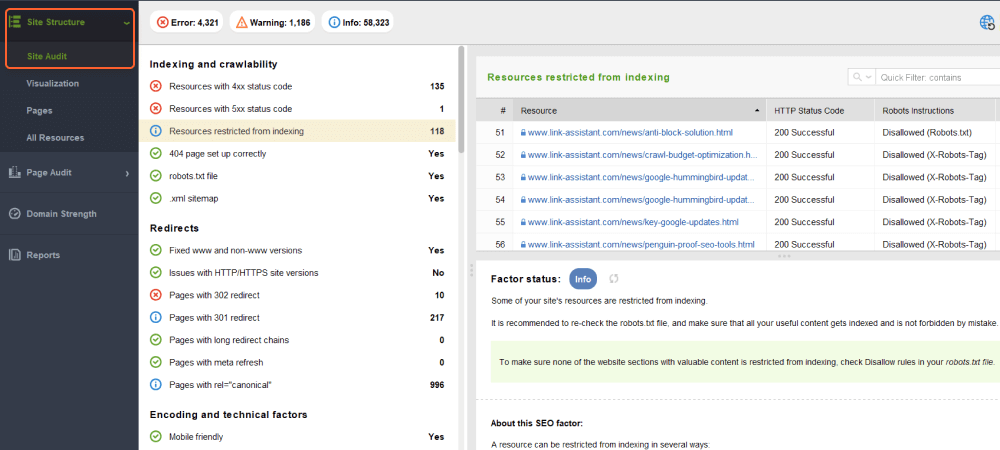
Onder elk type probleem ziet u een uitleg waarom deze factor belangrijk is en enkele suggesties voor het oplossen ervan.
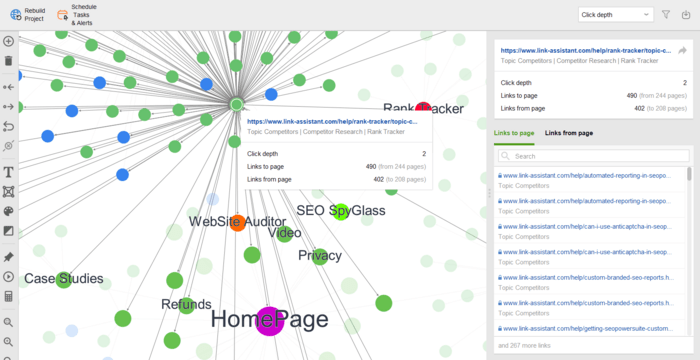
Bovendien kunt u uw visuele sitemap bekijken in Sitestructuur > Visualisatie, waarin de relaties tussen al uw URL’s worden weergegeven. Met de interactieve kaart kunt u pagina's en links toevoegen of verwijderen om de structuur van uw site aan te passen. U kunt de interne PageRank-waarde opnieuw berekenen en de paginaweergaven controleren (zoals bijgehouden door Google Analytics).
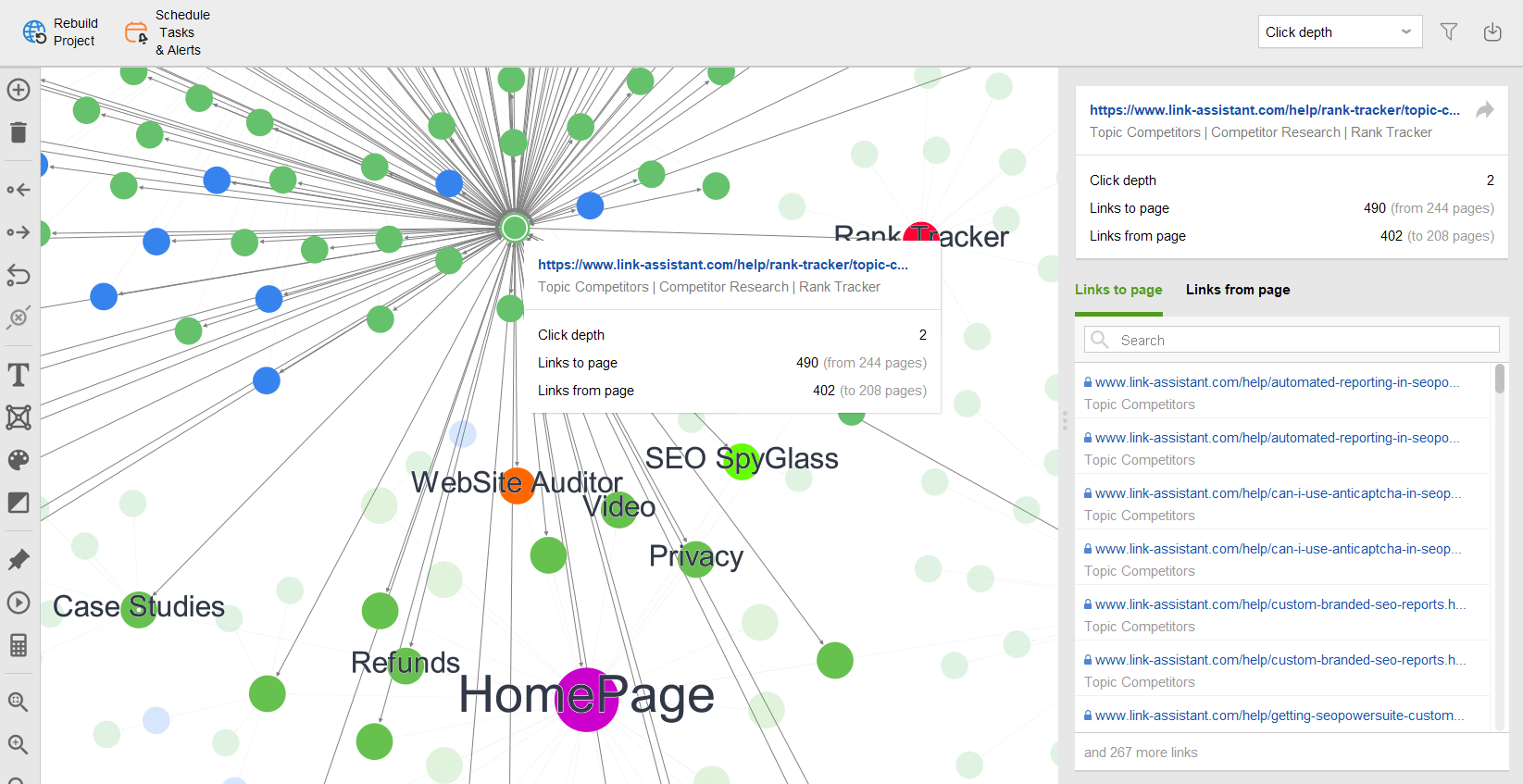
Bovendien controleert WebSite Auditor ook de beschikbaarheid van zowel uw robots.txt-bestand als de sitemap.
Hiermee kunt u de technische bestanden in de websitetools bewerken en deze met de juiste instellingen rechtstreeks naar uw site uploaden.
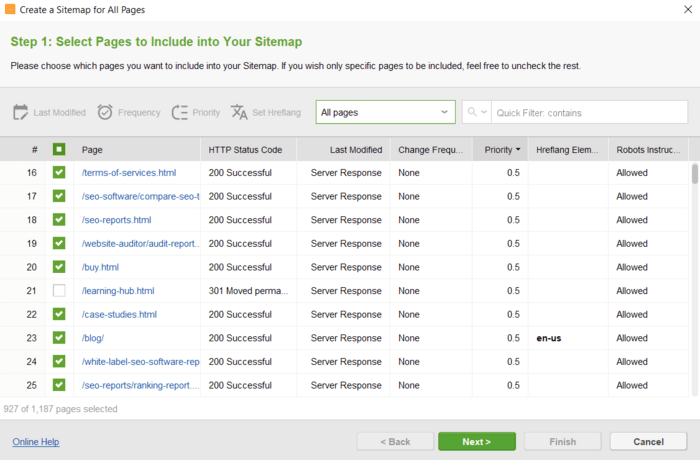
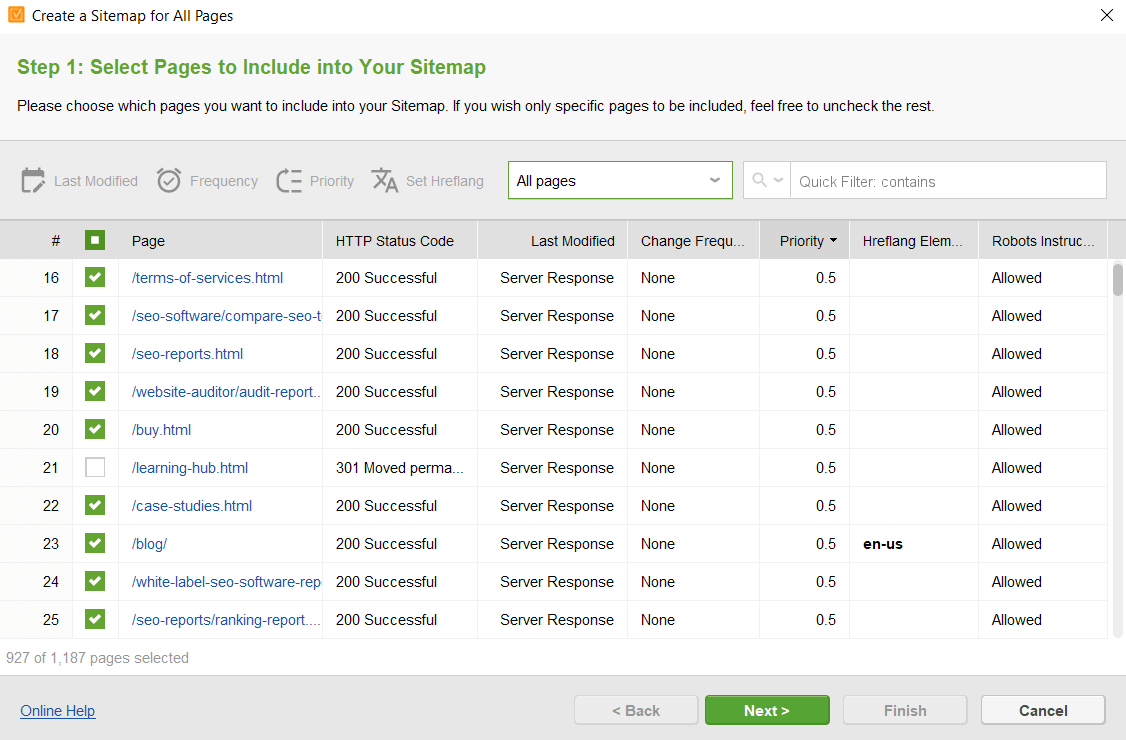
U hoeft geen speciale syntaxis in acht te nemen bij het bewerken van de bestanden; selecteer gewoon de vereiste URL's en pas de noodzakelijke regels toe. Klik vervolgens om de bestanden te genereren en ze op uw computer op te slaan of via FTP naar de site te uploaden.
Nog een geweldig hulpmiddel om alle pagina's van uw site te ontdekken is Google Search Console. Het zal u helpen de indexering van de pagina's te controleren en de problemen aan het licht te brengen die zoekbots belemmeren deze URL's correct te indexeren.
Hoe
U kunt een overzicht krijgen van al uw pagina's op basis van hun indexeringsstatus, inclusief de pagina's die nog niet zijn geïndexeerd.
U kunt als volgt alle pagina's van uw site vinden met Search Console:
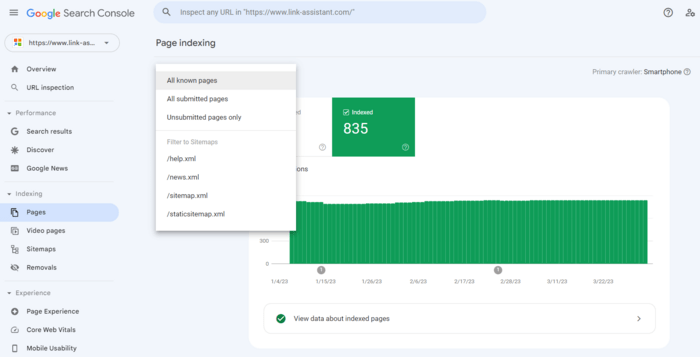
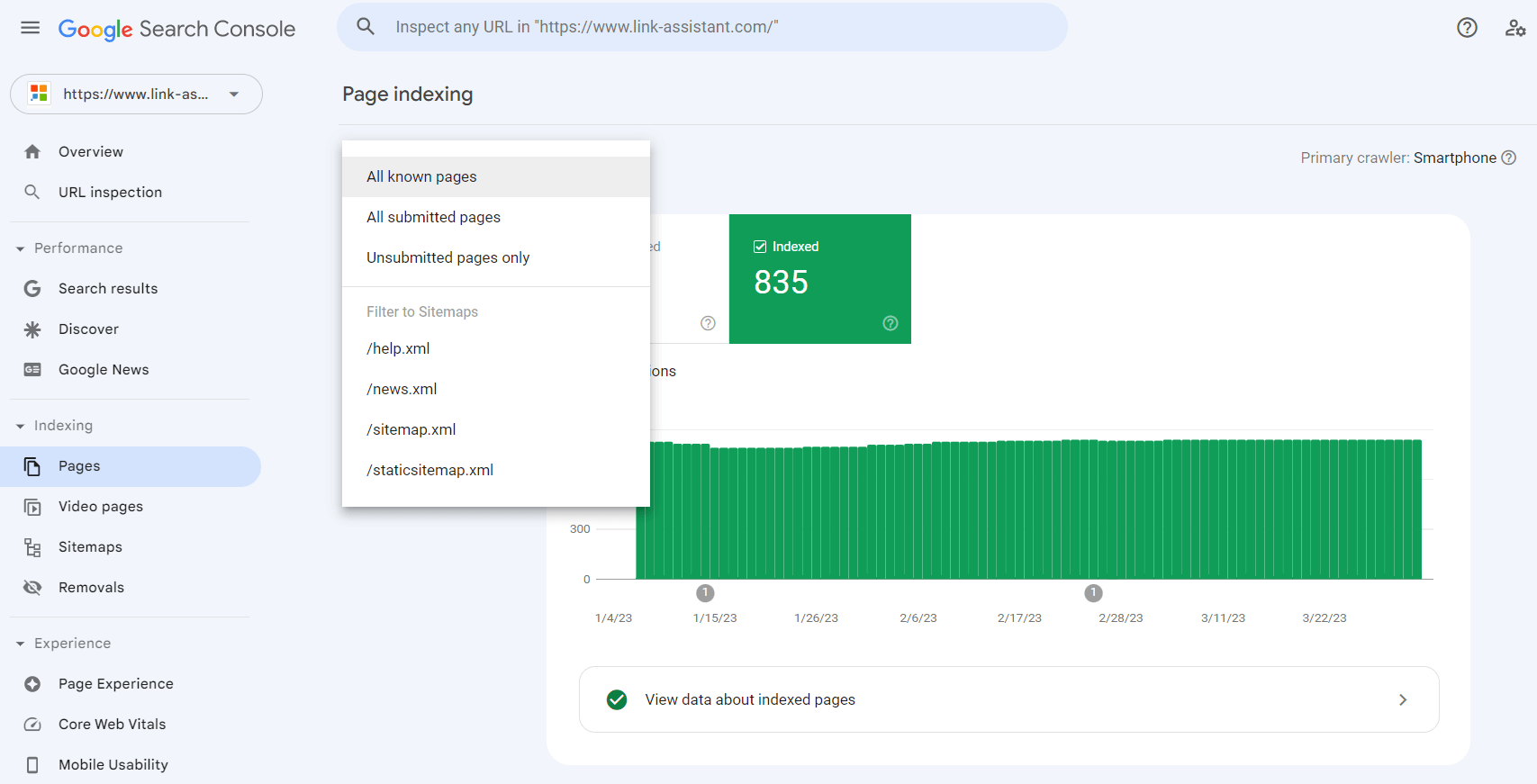
1. Ga naar het Indexeringsrapport en klik op Gegevens over geïndexeerde pagina's bekijken. U ziet alle pagina's die de zoekbot het laatst op uw website heeft gecrawld. Houd er echter rekening mee dat er een limiet in de tabel geldt van maximaal 1.000 URL's. Er is een snelfilter om alle bekende pagina's van alle ingediende URL's te sorteren, enz.
2. Schakel het tabblad Niet geïndexeerd in. Hieronder geeft de tool u details over waarom elke URL niet wordt geïndexeerd.
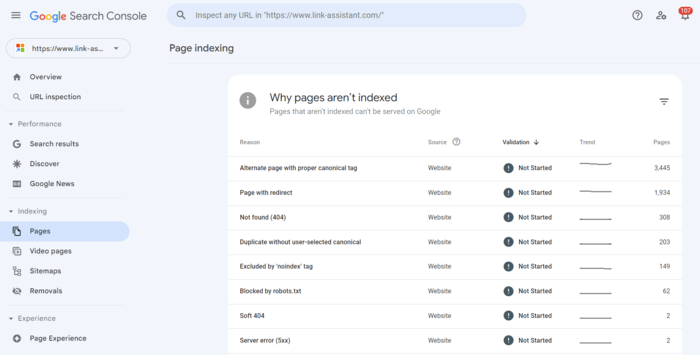
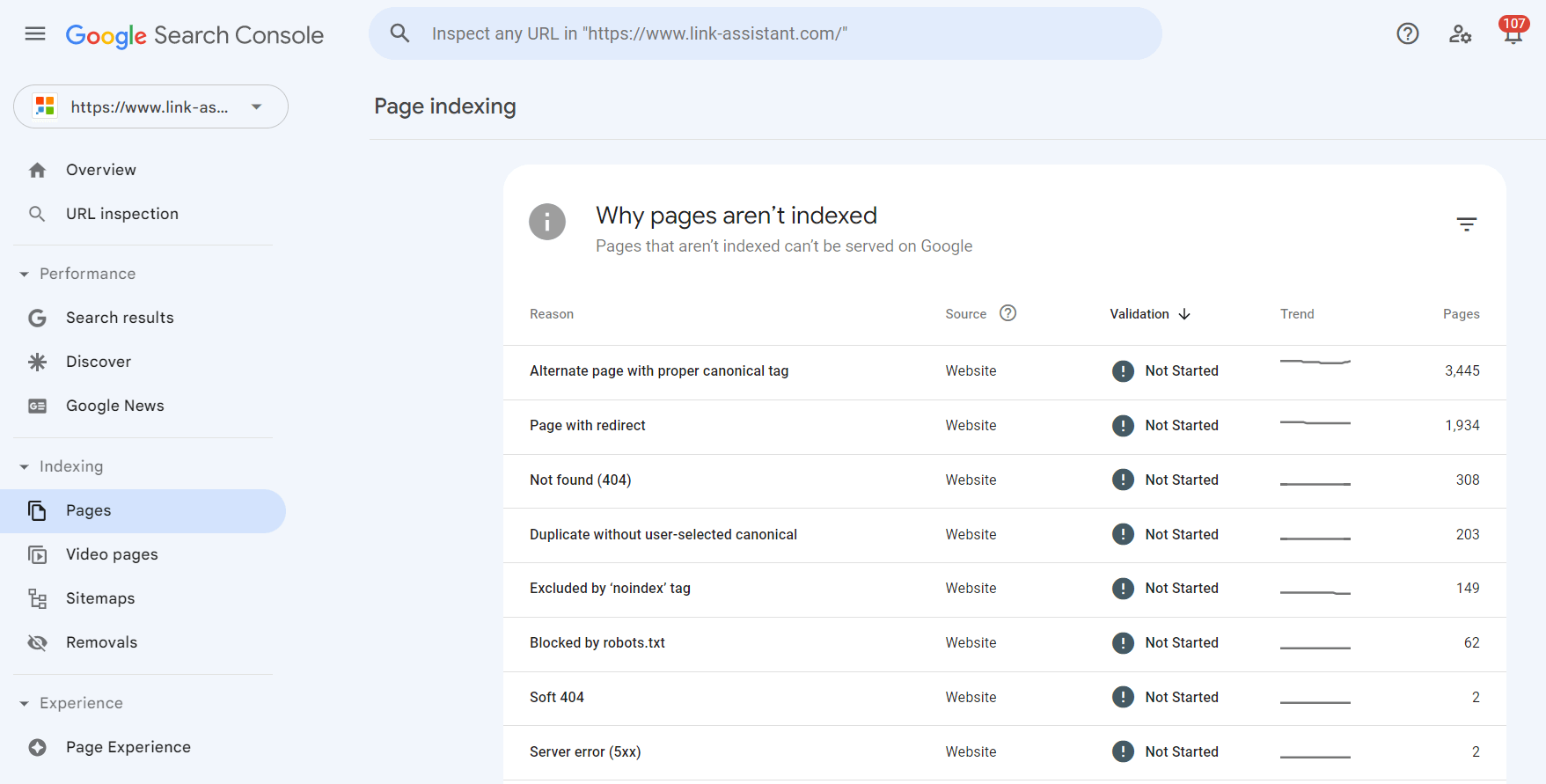
Klik op elke reden en bekijk de URL's waarop het probleem betrekking heeft.
De moeilijkheid is dat u niet alleen de hoofd-URL's van uw pagina's te zien krijgt, maar ook ankerlinks, pagineringspagina's, URL-parameters en ander afval dat handmatig moet worden gesorteerd. En de lijst is mogelijk onvolledig vanwege de limiet van 1.000 vermeldingen in de tabel.
Houd er onder andere rekening mee dat verschillende zoekmachines andere indexeringsregels kunnen hebben, en dat u hun webmasterhulpprogramma's moet gebruiken om dergelijke problemen op te sporen en op te lossen. Gebruik bijvoorbeeld Bing Webmaster- tools, Yandex Webmaster, Naver Webmaster en anderen om de indexering in de betreffende zoekmachines te controleren.
Ik denk dat Google Analytics een van de meest gebruikte analyseplatforms is, dus elke website-eigenaar of redacteur is ermee bekend. Het goede oude Universal Analytics wordt binnenkort vervangen door Google Analytics 4. Laten we dus beide versies van de tool bekijken.
Hoe
Volg deze stappen om de pagina's van uw site in Universal Analytics van Google te verzamelen:
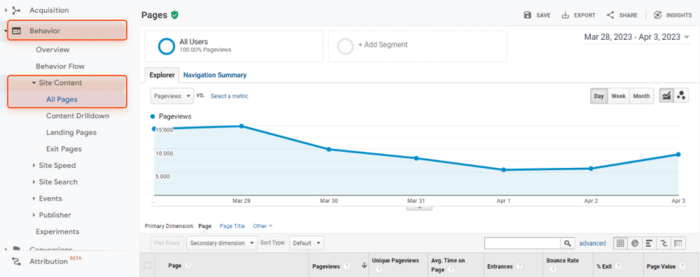
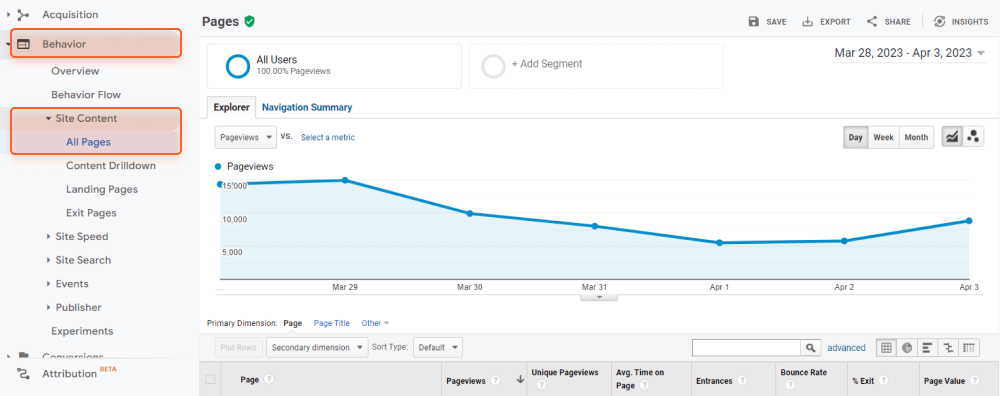
U ziet de pagina's met hun gebruikersgedragsstatistieken, zoals paginaweergaven, bouncepercentage, gemiddelde tijd op de pagina, enz. Let op pagina's met het minste aantal paginaweergaven aller tijden; waarschijnlijk zijn dit verweesde pagina's.
Om een soortgelijke stroom opnieuw te creëren in Google Analytics 4:
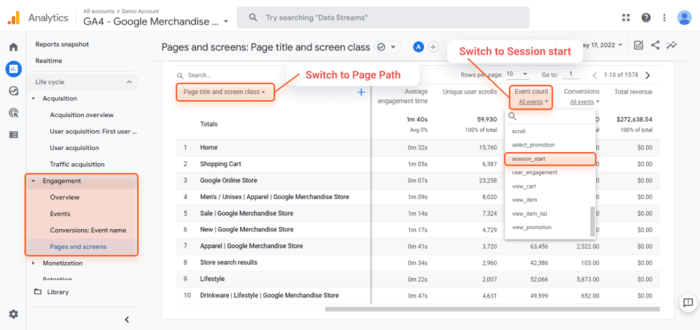
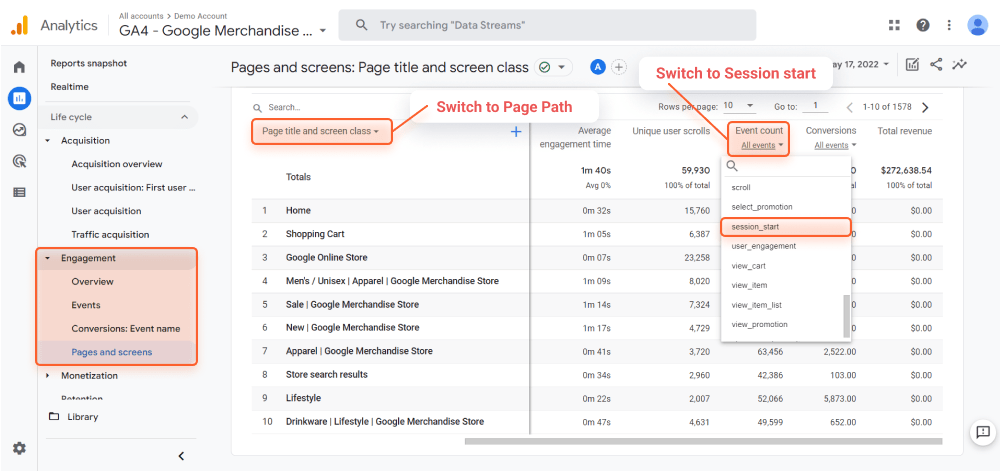
Net als bij de console bevat het URL-parameters en dergelijke. U kunt de lijst met pagina's exporteren als CSV- of Excel-blad door op de knop Exporteren bovenaan de pagina te klikken.
Sommige websites zijn erg groot, en zelfs krachtige SEO-spiders kunnen moeite hebben om al hun pagina's te doorzoeken. Loganalyse is een goede optie voor het vinden en onderzoeken van alle pagina's op grote websites.
Door het logbestand van uw website te analyseren, kunt u alle pagina's identificeren die bezoekers van internet ontvangen, hun HTTP-reacties, hoe vaak crawlers de pagina's bezoeken, enzovoort.
Logbestanden bevinden zich op uw server en u hebt het vereiste toegangsniveau nodig om deze op te halen, evenals een loganalysetool. Deze methode is dus meer geschikt voor technisch onderlegde mensen, webmasters of ontwikkelaars.
Hoe
Hier volgen de stappen om alle pagina's van uw site te vinden met behulp van loganalyse:
Een andere manier om alle pagina's op een website te vinden is door naar uw Content Management Systeem (CMS) te verwijzen, aangezien dit alle URL's bevat van de website die u ooit heeft gemaakt. Een voorbeeld van CMS'en is Wordpress of Squarespace, die tools voor het bouwen van websites bevatten voor het bewerken van inhoud in verschillende domeinen: nieuws en bloggen, e-commerce, bedrijfssites en dergelijke.
Hoe
Hoewel CMS'en qua uiterlijk nogal verschillen, zijn de algemene stappen op de meeste van hen van toepassing:
Houd er rekening mee dat er categorieën, blogposts of landingspagina's kunnen zijn. Dit zijn verschillende soorten pagina's die tot verschillende secties in het CMS kunnen behoren.
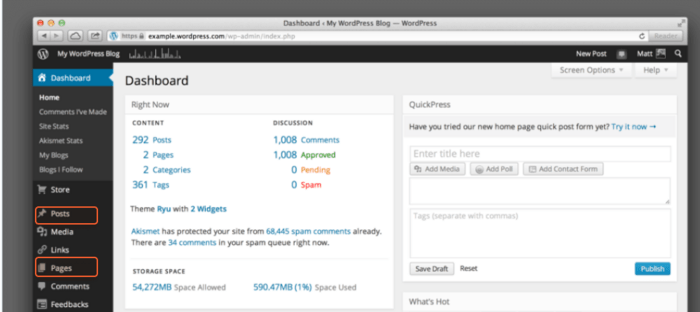
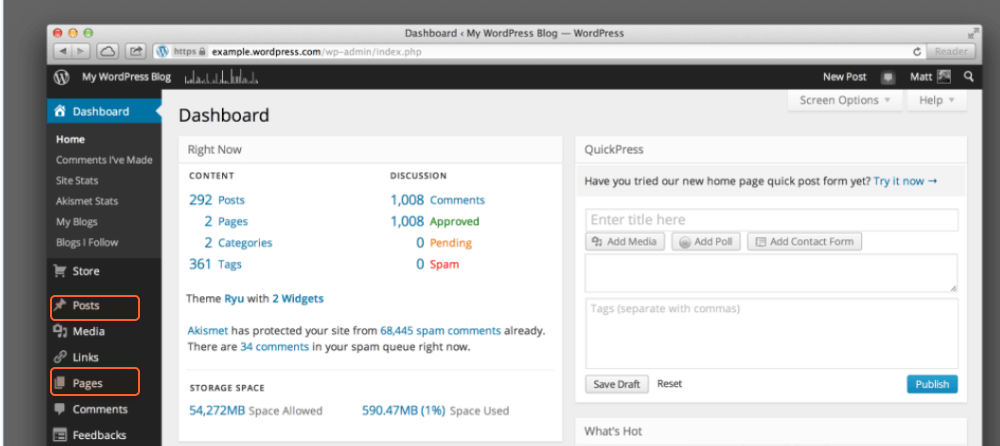
Bij de meeste CMS'en kunt u de URL's sorteren op datum van creatie, auteur, categorie of andere criteria. U kunt ook het zoekvak gebruiken om de lijst met pagina's te filteren op trefwoorden of titels.
Om alle pagina's op een website te vinden, is er een groot aantal methoden en hulpmiddelen. Welke u kiest, hangt af van het doel en de omvang van het werk dat u moet doen.
Ik hoop dat u deze lijst nuttig heeft gevonden en dat u nu gemakkelijk alle pagina's van uw site kunt verzamelen, zelfs als u nog niet bekend bent met SEO.
Als je een vraag hebt die nog niet beantwoord is, stel deze dan gerust in onze gebruikersgroep op Facebook.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

