123127
•
20 分で読めます
•


このチェックリストには、理論から実践まで、技術現場監査の基本的な事項がすべて記載されています。
どのような技術ファイルが存在するのか、SEO の問題が発生する理由、および突然のランキングの低下から常に安全に過ごせるように、将来的に問題を修正および防止する方法を学びます。
その過程で、手間をかけずに技術的な Web サイトの監査を実行できる、人気のあるものとあまり知られていないものの両方の SEO 監査ツールをいくつか紹介します。
技術的な SEO チェックリストのステップ数は、目的と調査するサイトの種類によって異なります。私たちは、このチェックリストを普遍的なものにし、技術的な SEO 監査のすべての重要なステップを網羅することを目指しました。
1. サイト分析とウェブマスター ツールにアクセスする
サイトの技術監査を実施するには、分析ツールとウェブマスター ツールが必要です。これらのツールがすでに Web サイトに設定されていると便利です。 Google Analytics 、 Google Search Console 、 Bing ウェブマスター ツールなどを使用すると、基本的なサイト チェックに必要な大量のデータがすでに存在します。
2. ドメインの安全性を確認する
ランキングから落ちた既存の Web サイトを監査している場合は、何よりもまず、そのドメインが検索エンジンによる制裁の対象となっている可能性を排除してください。
これを行うには、Google Search Console を参照してください。サイトがブラックハット リンク構築でペナルティを受けた場合、またはサイトがハッキングされた場合は、コンソールの [セキュリティと手動アクション] タブに対応する通知が表示されます。サイトの技術監査を続行する前に、このタブに表示される警告に必ず対処してください。サポートが必要な場合は、手動ペナルティとアルゴ ペナルティの処理方法に関するガイドを確認してください。
立ち上げ予定の新しいサイトを監査している場合は、ドメインが侵害されていないことを必ず確認してください。詳細については、期限切れのドメインを選択する方法と、Web サイトの公開中に Google サンドボックスに閉じ込められないようにする方法に関するガイドを参照してください。
準備作業が完了したので、Web サイトの技術的な SEO 監査に段階的に進みましょう。
一般に、インデックス作成の問題には 2 つのタイプがあります。 1 つは、URL がインデックスに登録されているはずなのに登録されていない場合です。もう 1 つは、URL がインデックスに登録されるはずがないにもかかわらず、インデックスに登録されてしまう場合です。では、サイトのインデックスに登録された URL の数を確認するにはどうすればよいでしょうか?
実際にウェブサイトのどれだけが検索インデックスに登録されているかを確認するには、 Google Search Consoleのカバレッジレポートを確認してください。このレポートには、現在インデックスされているページの数、除外されているページの数、Web サイトのインデックス作成の問題の一部が表示されます。
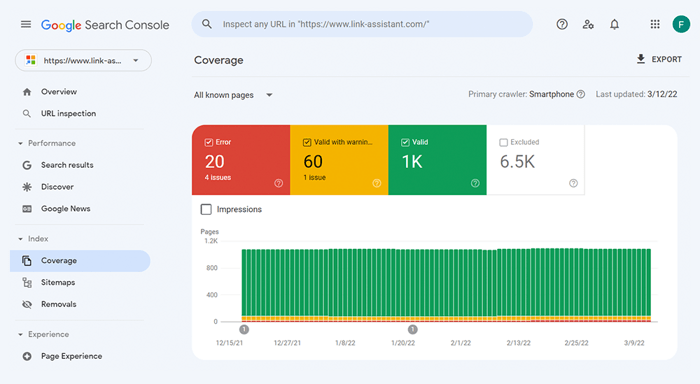

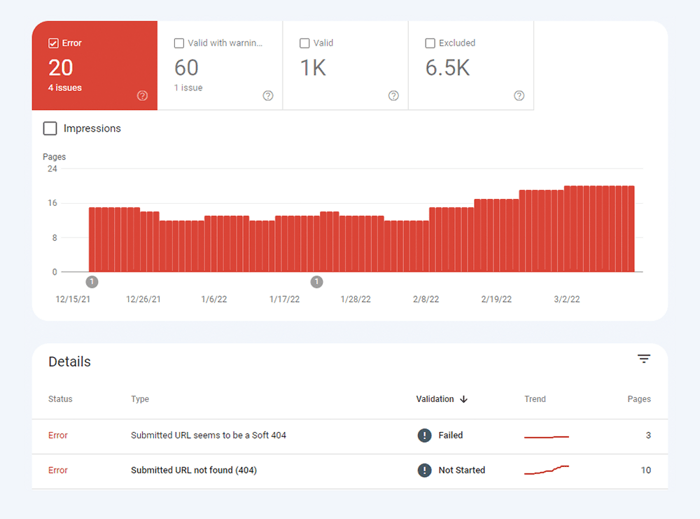
最初のタイプのインデックス作成の問題は、通常、エラーとしてマークされます。インデックス作成エラーは、Google にページのインデックス作成を依頼したにもかかわらずブロックされた場合に発生します。たとえば、ページがサイトマップに追加されましたが、 noindexタグでマークされているか、robots.txt でブロックされているとします。
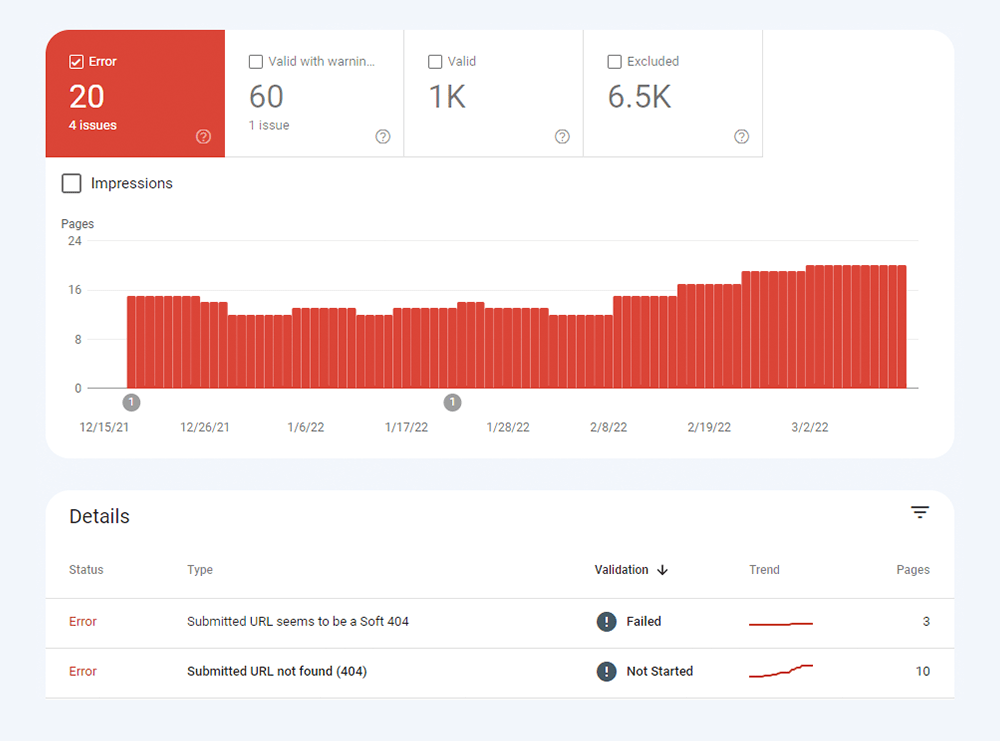
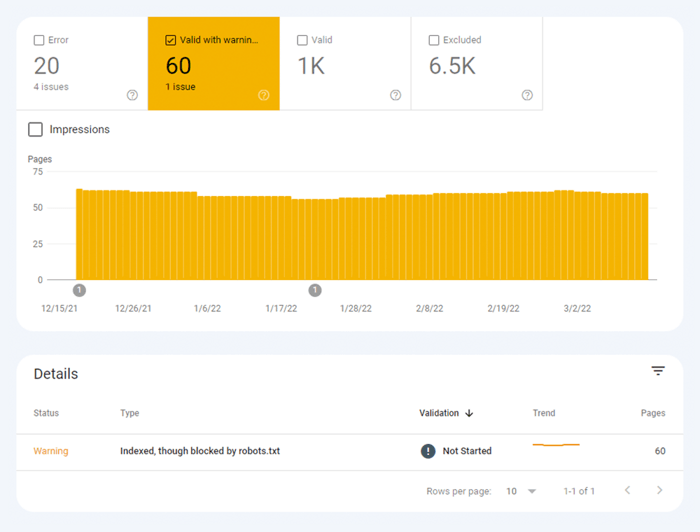
もう 1 つのタイプのインデックスの問題は、ページがインデックスに登録されているが、Google がそのページがインデックスに登録されるべきだったのかどうかを確信していない場合です。 Google Search Console では、これらのページは通常、警告付きで有効としてマークされます。

個々のページについては、Search Console でURL 検査ツールを実行して、Google の検索ボットがページをどのように認識しているかを確認します。それぞれのタブをクリックするか、上部の検索バーに完全な URL を貼り付けると、URL に関するすべての情報、つまり検索ボットによる前回のスキャン方法が取得されます。
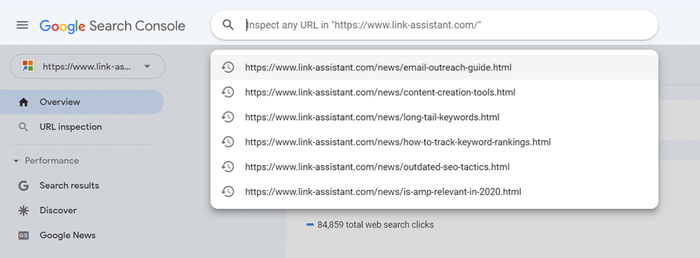
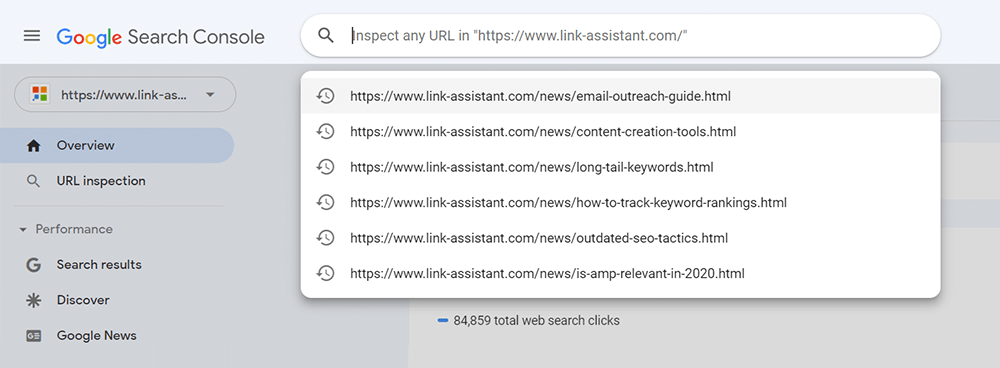
次に、 [ライブ URL のテスト]をクリックすると、応答コード、HTML タグ、最初の画面のスクリーンショットなど、ページに関するさらに詳細な情報を確認できます。
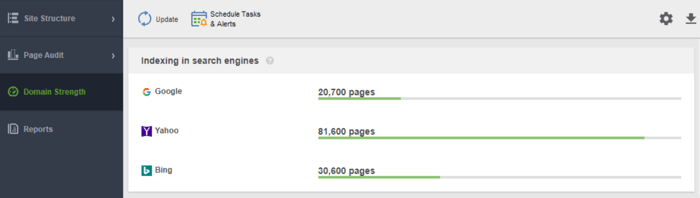
インデックス作成を監視するもう 1 つのツールは、 WebSite Auditorです。ソフトウェアを起動し、Web サイトの URL を貼り付けて新しいプロジェクトを作成し、サイトの監査に進みます。クロールが終了すると、WebSite Auditor のサイト構造モジュールにすべての問題と警告が表示されます。ドメイン強度レポートでは、Google だけでなく他の検索エンジンでもインデックスされたページの数を確認します。
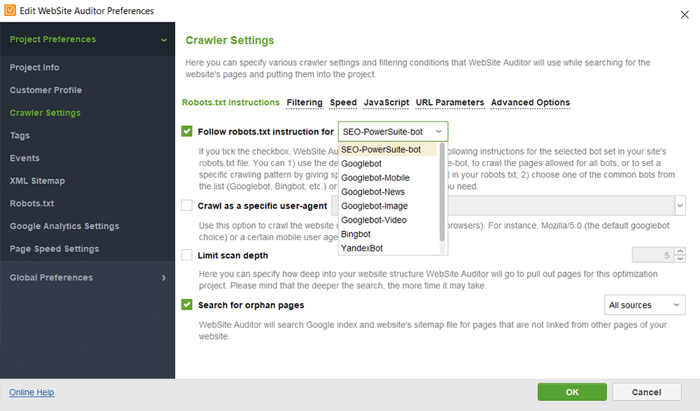
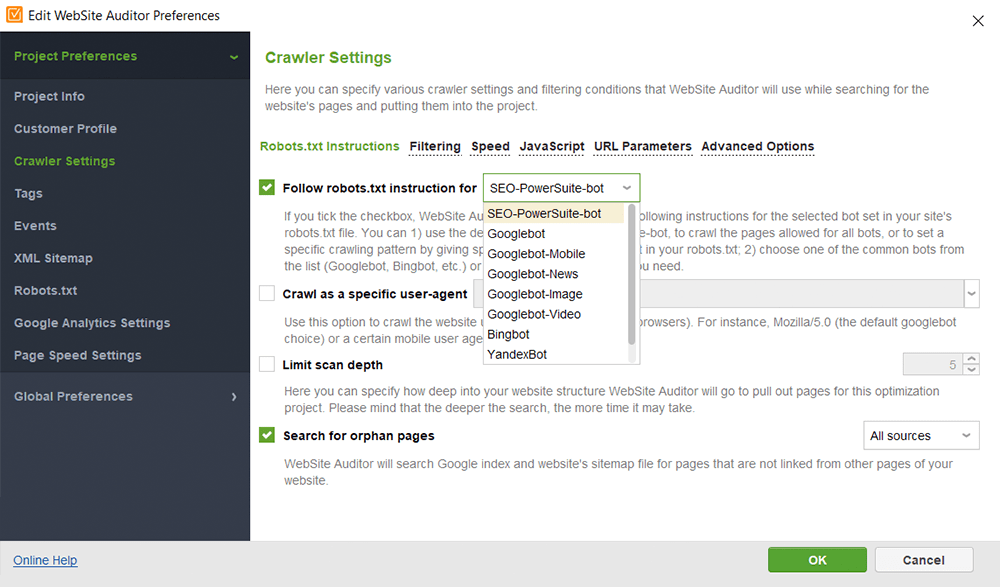
WebSite Auditor では、別の検索ボットを選択し、クロール設定を指定して、サイト スキャンをカスタマイズできます。 SEO スパイダーの [プロジェクト設定]で、検索エンジン ボットと特定のユーザー エージェントを定義します。クロール中に検査する (または逆にスキャンをスキップする) リソースの種類を選択します。また、サブドメインやパスワードで保護されたサイトを監査したり、特別な URL パラメーターを無視したりするようにクローラーに指示することもできます。
ユーザーまたは検索ボットが Web サイトのデータを運ぶサーバーにリクエストを送信するたびに、ログ ファイルにそれに関するエントリが記録されます。これは、サイトのクローラーと訪問者、インデックス作成エラー、クロール予算の無駄、一時的なリダイレクトなどに関する最も正確で有効な情報です。ログ ファイルを手動で分析するのは難しい場合があるため、ログ ファイル アナライザー プログラムが必要になります。
どのツールを使用する場合でも、インデックス付けされたページの数は Web サイト上の実際のページ数に近い必要があります。
それでは、Web サイトのクロールとインデックス作成を制御する方法に移りましょう。
デフォルトでは、クロール制御を備えた技術的な SEO ファイルがない場合でも、検索ボットはサイトを訪問し、そのままクロールします。ただし、テクニカル ファイルを使用すると、検索エンジン ボットがページをクロールしてインデックスを作成する方法を制御できるため、サイトが大規模な場合はテクニカル ファイルを使用することを強くお勧めします。以下に、インデックス作成/クロール ルールを変更するいくつかの方法を示します。
では、それぞれの機能を使用して、Google がサイトのインデックスをより速く作成するにはどうすればよいでしょうか?
サイトマップは、サイト上のすべてのページ、ビデオ、その他のリソースとそれらの間の関係をリストする技術的な SEO ファイルです。このファイルは、サイトをより効率的にクロールする方法を検索エンジンに指示し、Web サイトのアクセシビリティにおいて重要な役割を果たします。
Web サイトには次のような場合にサイトマップが必要です。
サイトに追加できるサイトマップにはさまざまな種類があり、主に管理している Web サイトの種類に応じて異なります。
HTML サイトマップは人間の読者を対象としており、Web サイトの下部にあります。ただし、SEO としての価値はほとんどありません。 HTML サイトマップはユーザーに主要なナビゲーションを示し、通常はサイト ヘッダー内のリンクを複製します。一方、HTML サイトマップを使用すると、メイン メニューに含まれていないページのアクセシビリティを向上させることができます。
HTML サイトマップとは異なり、XML サイトマップは特別な構文のおかげで機械可読です。 XML サイトマップはルート ドメイン (例: https://www.link-assistant.com/sitemap.xml) にあります。さらに以下では、正しい XML サイトマップを作成するための要件とマークアップ タグについて説明します。
これは、検索エンジン ボットで使用できる別の種類のサイトマップです。 TXT サイトマップには、すべての Web サイトの URL がリストされているだけであり、コンテンツに関するその他の情報は提供されていません。
このタイプのサイトマップは、膨大な画像ライブラリや大きなサイズの画像を Google 画像検索でランク付けするのに役立ちます。画像サイトマップでは、地理的位置、タイトル、ライセンスなど、画像に関する追加情報を提供できます。各ページに最大 1,000 枚の画像をリストできます。
動画サイトマップは、Google ビデオ検索でのランクを高めるために、ページでホストされているビデオ コンテンツに必要です。 Google は動画に構造化データを使用することを推奨していますが、特にページ上に多くの動画コンテンツがある場合には、サイトマップも有益です。ビデオ サイトマップでは、タイトル、説明、再生時間、サムネイル、セーフ サーチ向けのファミリー向けかどうかなど、ビデオに関する追加情報を追加できます。
多言語および複数地域の Web サイトの場合、検索エンジンが特定の場所でどの言語バージョンを提供するかを決定する方法がいくつかあります。 Hreflang は、ローカライズされたページを提供するいくつかの方法の 1 つであり、そのために特別な hreflang サイトマップを使用できます。 hreflang サイトマップには、URL 自体とそのページの言語/地域コードを示す子要素がリストされます。
ニュース ブログを運営している場合、News-XML サイトマップを追加すると、Google ニュースでのランキングにプラスの影響を与える可能性があります。ここでは、タイトル、言語、発行日に関する情報を追加します。ニュース サイトマップには最大 1,000 個の URL を追加できます。 URL は 2 日以内に保存する必要があり、その後は削除できますが、インデックスには 30 日間残ります。
Web サイトに RSS フィードがある場合は、フィード URL をサイトマップとして送信できます。ほとんどのブログ ソフトウェアはフィードを作成できますが、この情報は最近の URL をすばやく見つける場合にのみ役に立ちます。
現在、最も頻繁に使用されているのは XML サイトマップです。そのため、XML サイトマップ生成の主な要件を簡単に見直してみましょう。
XML サイトマップは UTF-8 でエンコードされており、XML 要素の必須タグが含まれています。
1 エントリの XML サイトマップの簡単な例は次のようになります。
ページ クロールの優先順位と頻度を示すオプションのタグがあります。 <priority>、<changefreq> (Google は現在これらを無視します)、および<lastmod>の値が正確な場合 (たとえば、ページの最後の変更と比較した場合) 。
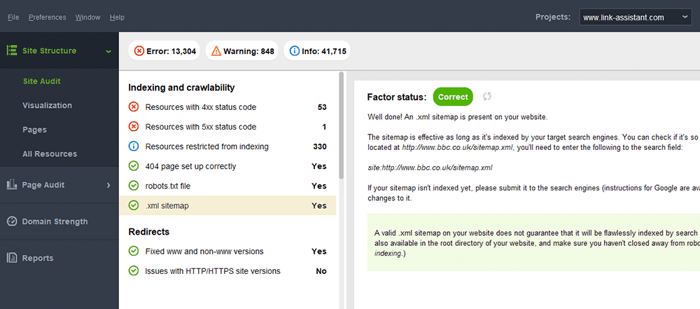
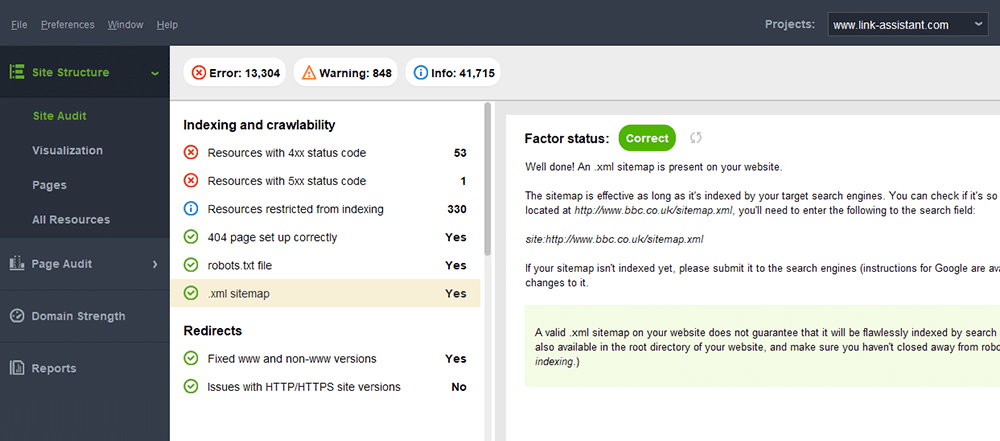
サイトマップに関する一般的なエラーは、大規模なドメインに有効な XML サイトマップがないことです。 WebSite Auditorを使用して、サイトマップの存在を確認できます。 [サイト監査] > [インデックス作成とクロール可能性]セクションで結果を見つけます。
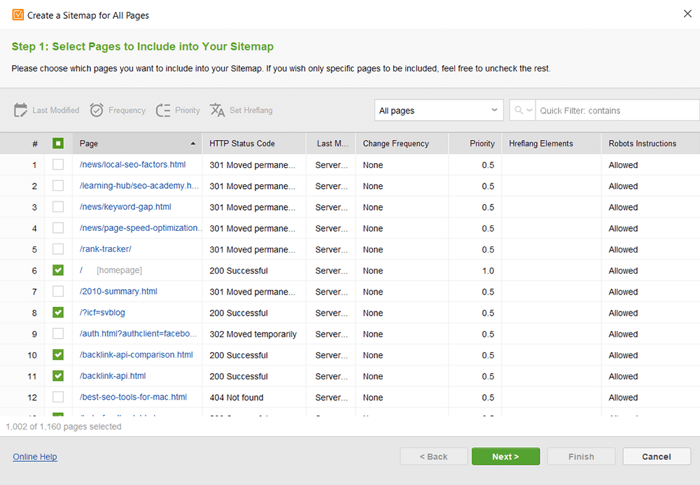
サイトマップをお持ちでない場合は、今すぐ作成してください。 「ページ」セクションに切り替えると、WebSite Auditor のWeb サイト ツールを使用してサイトマップをすばやく生成できます。
そしてサイトマップについて Google に知らせてください。これを行うには、次のことができます
実際のところ、 Web サイトにサイトマップがあるからといって、すべてのページがインデックスに登録されるか、さらにはクロールされることが保証されるわけではありません。サイトのインデックス付けを改善することを目的とした、その他の技術的な SEO リソースがいくつかあります。次のステップでそれらを確認します。
robots.txt ファイルは、クローラーがサイト上でアクセスできる URL を検索エンジンに伝えます。このファイルは、リクエストによるサーバーの過負荷を回避し、クロール トラフィックを管理するために役立ちます。このファイルは通常、次の目的で使用されます。
Robots.txt はドメインのルートに配置され、各サブドメインには独自の個別のファイルが必要です。 500kB を超えてはならず、200 コードで応答する必要があることに注意してください。
robots.txt ファイルには、許可ルールと禁止ルールを含む構文もあります。
検索エンジンが異なれば、ディレクティブに従う方法も異なる場合があります。たとえば、Google はディレクティブの使用を放棄しました。 robots.txt からのnoindex、crawl-lay、およびnofollow 。さらに、Googlebot-Image、Bingbot、Baiduspider-image、DuckDuckBot、AhrefsBot などの特別なクローラーもあります。そのため、すべての検索ボットに対してルールを定義したり、一部の検索ボットに対してのみ個別のルールを定義したりできます。
robots.txt に指示を書くのは非常に難しい場合があるため、ここでのルールは指示の数を減らし、より常識的なものにすることです。以下に、robots.txt 命令の設定例をいくつか示します。
ドメインへのフルアクセス。この場合、不許可ルールは入力されません。
ホストを完全にブロックします。
この命令では、ドメイン名の後のアップロードで始まるすべての URL のクロールを禁止します。
この命令により、Googlebot-News がニュース フォルダー内のすべての GIF ファイルをクロールすることが禁止されます。
すべての検索エンジンに一般的な命令 A を設定し、特定のボットに 1 つの限定的な命令 B を設定すると、特定のボットはその限定的な命令に従い、ボットにデフォルトで設定されている他のすべての一般的なルールを実行する可能性があることに注意してください。ルール A による制限はありません。たとえば、次のルールのようになります。
ここで、AdsBot-Google-Mobile は、ワイルドカード * マークを使用した指示にもかかわらず、tmp フォルダー内のファイルをクロールする場合があります。
robots.txt ファイルの一般的な用途の 1 つは、サイトマップの場所を示すことです。この場合、ルールはすべてのクローラーに適用されるため、ユーザー エージェントについて言及する必要はありません。サイトマップは大文字の S で始まる必要があり (robots.txt ファイルでは大文字と小文字が区別されることに注意してください)、URL は絶対である必要があります (つまり、完全なドメイン名で始まる必要があります)。
矛盾する命令を設定した場合、クローラー ボットは長い命令を優先することに注意してください。例えば:
ここでは、最初の指示にもかかわらず、スクリプト /admin/js/global.js は引き続きクローラーに対して許可されます。 admin フォルダー内の他のすべてのファイルは引き続き許可されません。
robots.txt ファイルが利用可能かどうかは、WebSite Auditor で確認できます。また、 robots.txt 生成ツールを使用してファイルを生成し、さらに保存したり、FTP 経由で Web サイトに直接アップロードしたりすることもできます。
robots.txt ファイルは公開されており、一部のページが非表示にならずに公開される可能性があることに注意してください。一部のプライベート フォルダーを非表示にしたい場合は、パスワードで保護します。
最後に、 robots.txt ファイルは、許可されていないページがクロールされない、またはインデックスが作成されないことを保証しません。 Google によるページのクロールをブロックすると、そのページは Google のインデックスから削除される可能性がありますが、検索ボットは、そのページを指すバックリンクをたどってそのページをクロールする可能性があります。そこで、ページのクロールとインデックス作成をブロックする別の方法、メタ ロボットを紹介します。
メタ ロボット タグは、クローラーに個々のページの処理方法を指示する優れた方法です。メタ ロボット タグは HTML ページの <head> セクションに追加されるため、この手順はページ全体に適用されます。ロボットのメタ タグ ディレクティブをカンマで結合するか、複数のメタ タグを使用することにより、複数の命令を作成できます。次のようになります。
さまざまなクローラーのメタ ロボット タグを指定できます。たとえば、
Google は次のようなタグを理解します。
反対のタグのインデックス/フォロー/アーカイブは、対応する禁止ディレクティブをオーバーライドします。他にも、snippet / nosnippet / notranslate / nopagereadaloud / noimageindexなど、検索結果にページがどのように表示されるかを示すタグがいくつかあります。
他の検索エンジンでは有効だが Google には認識されていない他のタグを使用した場合、Googlebot はそれらを無視します。
メタ タグの代わりに、PDF、ビデオ、画像ファイルなどの非 HTML リソースに応答ヘッダーを使用できます。応答で noindex または none の値を持つ X-Robots-Tag ヘッダーを返すように設定します。
ディレクティブの組み合わせを使用して、検索結果でスニペットがどのように表示されるかを定義することもできます (例: max-image-preview: [setting] 、 nosnippet またはmax-snippet: [number]など)。
サイトの Web サーバー ソフトウェアの構成ファイルを介して、X-Robots-Tag を Web サイトの HTTP 応答に追加できます。クロール ディレクティブは、サイト全体のすべてのファイルにグローバルに適用できます。また、正確な名前を定義した場合は個々のファイルにも適用できます。
WebSite Auditorを使用すると、すべてのロボットの指示をすぐに確認できます。 [サイト構造] > [すべてのリソース] > [内部リソース]に移動し、 [ロボットの指示]列を確認します。ここでは、許可されていないページと、robots.txt、メタ タグ、または X-Robots-tag のどの方法が適用されているかがわかります。
サイトをホストするサーバーは、クライアント、ブラウザー、またはクローラーからのリクエストに応答するときに HTTP ステータス コードを生成します。サーバーが 2xx ステータス コードで応答した場合、受信したコンテンツはインデックス付けの対象となる可能性があります。 3xx から 5xx までの他の応答は、コンテンツのレンダリングに問題があることを示しています。 HTTP ステータス コード応答の意味をいくつか示します。
301 リダイレクトは次の場合に使用されます。
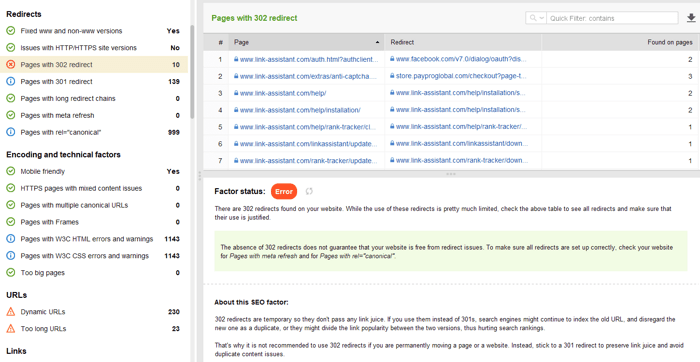
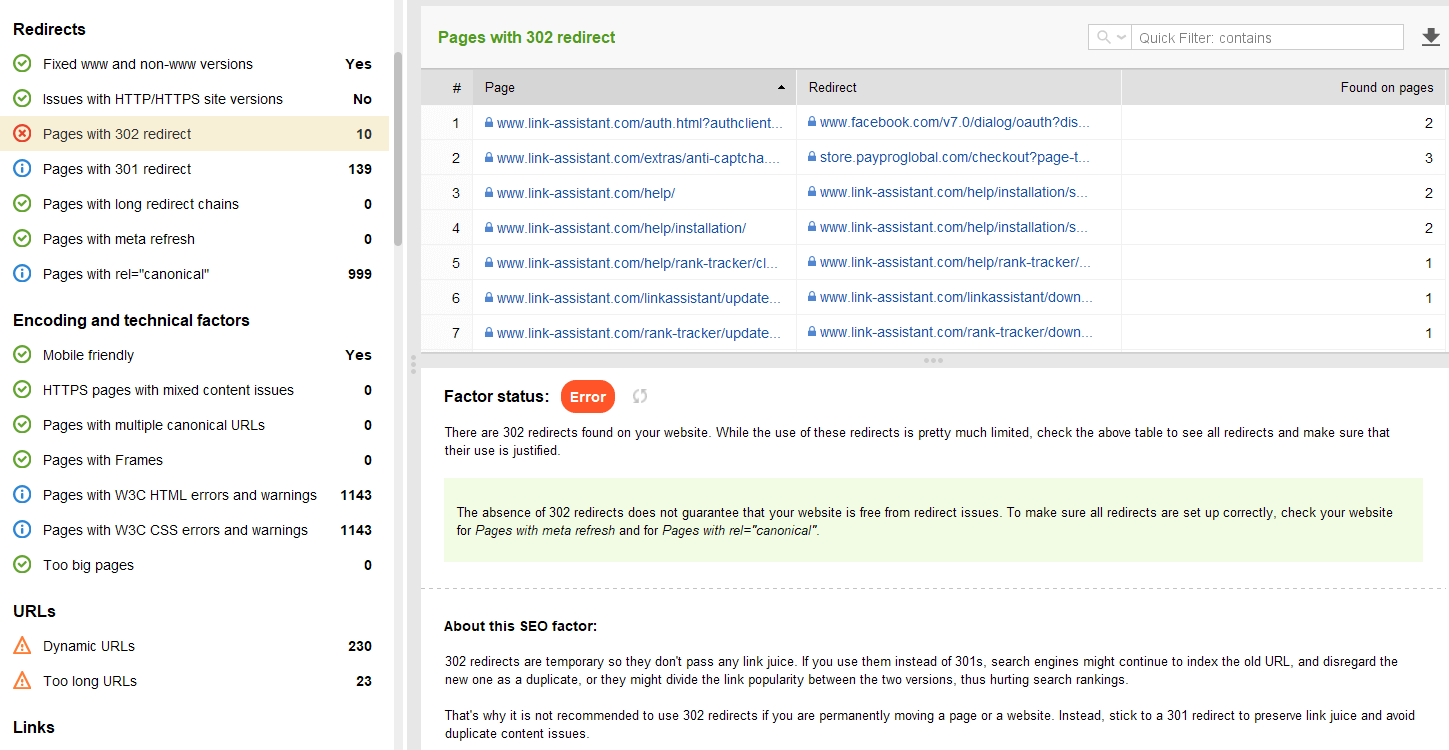
302 一時リダイレクト
一時 302 リダイレクトは一時ページでのみ使用してください。たとえば、ページを再デザインしたり、新しいページをテストしてフィードバックを収集しているが、その URL をランキングから落としたくない場合です。
304 キャッシュをチェックする
304 応答コードは、Google、Bing、Baidu、Yandex など、最も一般的な検索エンジンすべてでサポートされています。304 応答コードを正しく設定すると、ボットが最後のクロール以降にページで何が変更されたかを理解するのに役立ちます。ボットは HTTP リクエスト If-Modified-Since を送信します。前回のクロール日以降に変更が検出されなかった場合、検索ボットはページを再クロールする必要はありません。ユーザーにとって、これはページが完全に再ロードされず、そのコンテンツがブラウザーのキャッシュから取得されることを意味します。
304 コードは次のことにも役立ちます。
ページのコンテンツだけでなく、画像や CSS スタイルなどの静的ファイルのキャッシュを確認することが重要です。 304 応答コードをチェックするための、このような特別なツールがあります。


ほとんどの場合、サーバー応答コードの問題は、クローラーが削除または移動されたページへの内部および外部リンクをたどり続け、3xx および 4xx 応答を取得したときに発生します。
404 エラーは、ページが利用できないことを示し、サーバーはブラウザに正しい HTTP ステータス コード (404 Not Found) を送信します。
ただし、サーバーが 200 OK 応答コードを送信すると、ソフト 404 エラーが発生しますが、Google ではこれは 404 であるべきであると考えています。これは、次の理由で発生する可能性があります。
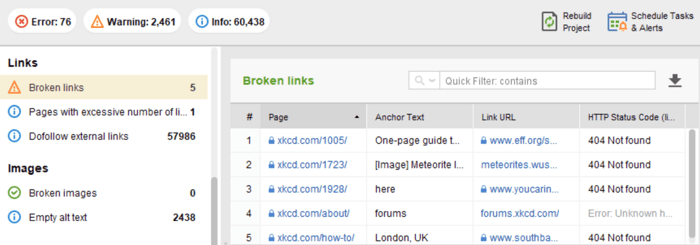
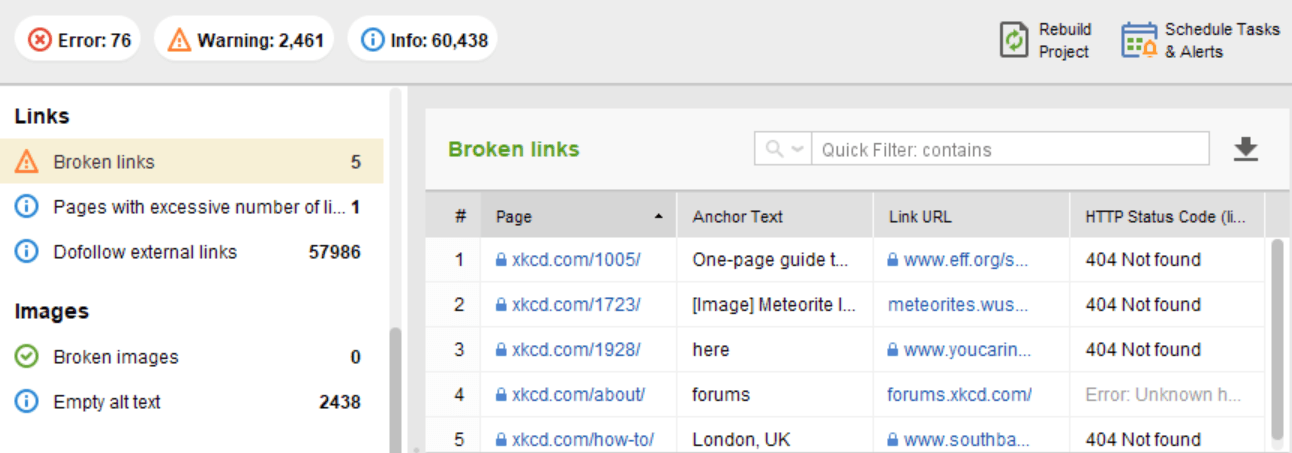
WebSite Auditor のサイト監査モジュールでは、 [インデックス作成とクロール可能性]タブで 4xx、5xx 応答コードを含むリソースを確認し、 [リンク]タブで壊れたリンクについては別のセクションを確認します。
301/302 応答に関連するその他の一般的なリダイレクトの問題:
WebSite Auditor の[Site Audit] > [Redirects]セクションで、301 および 302 リダイレクトを含むすべてのページを確認できます。
重複は、Web サイトのクロールにとって重大な問題になる可能性があります。 Google が重複 URL を見つけた場合、どちらがプライマリ ページであるかを決定し、より頻繁にクロールしますが、重複した URL はクロールの頻度が低くなり、検索インデックスから外れる可能性があります。確実な解決策は、重複したページの 1 つを正規のページ、つまりメインのページとして示すことです。これは、ページの HTML コードまたはサイトの HTTP ヘッダー応答に配置されたrel=”canonical”属性を利用して実行できます。
Google は正規ページを使用してコンテンツと品質を評価し、非正規ページの方がユーザーに適していると検索エンジンが明確に識別しない限り(モバイル ユーザーやモバイル ユーザー、特定の場所にいる検索者)。
したがって、関連ページの正規化は次のことに役立ちます。
重複した問題とは、同一または類似のコンテンツが複数の URL に表示されることを意味します。多くの場合、Web サイトでの技術データの処理により、重複が自動的に表示されます。
一部の CMS では、設定が間違っているために重複した問題が自動的に生成される場合があります。たとえば、さまざまな Web サイトのディレクトリに複数の URL が生成される場合があり、これらは重複します。
ページネーションが正しく実装されていない場合、重複の問題が発生する可能性もあります。たとえば、カテゴリ ページとページ 1 の URL は同じコンテンツを示しているため、重複として扱われます。このような組み合わせは存在しないようにするか、カテゴリ ページを正規としてマークする必要があります。
並べ替えとフィルタリングの結果が重複して表示される場合があります。これは、サイトで検索またはフィルタリング クエリ用の動的 URL を作成するときに発生します。クエリ文字列または URL 変数のエイリアスを表すURL パラメーターを取得します。これらは URL の疑問符に続く部分です。
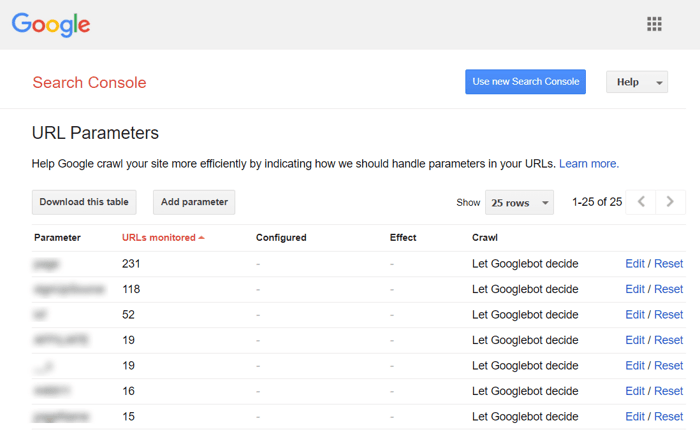
Google がほぼ同一のページを大量にクロールしないようにするには、特定の URL パラメータを無視するように設定します。これを行うには、Google Search Console を起動し、 [従来のツールとレポート] > [URL パラメーター]に移動します。右側の「編集」をクリックして、どのパラメータを無視するかを Google に指示します。ルールはサイト全体に適用されます。 パラメータ ツールは上級ユーザー向けであるため、正確に扱う必要があることに注意してください。
重複の問題は、検索を 3 つ、4 つなどの条件に絞り込むファセット フィルター ナビゲーションを許可する電子商取引 Web サイトでよく発生します。ここでは、電子商取引サイトのクロール ルールを設定する方法の例を示します。より長く、より狭い検索結果を含む URL を特定のフォルダーに保存し、robots.txt ルールによって禁止します。
Web サイトの構造に論理的な問題があるため、重複が発生する可能性があります。製品を販売していて、1 つの製品が異なるカテゴリに属している場合がこれに該当します。
この場合、製品には 1 つの URL のみからアクセスできる必要があります。 URL は完全な重複とみなされ、SEO に悪影響を及ぼします。 URL は CMS の正しい設定によって割り当てられ、1 つのページに対して一意の単一 URL が生成される必要があります。
WordPress CMSではタグを使用する場合などに部分重複がよく起こります。タグによってサイト検索とユーザー ナビゲーションが向上する一方で、WP Web サイトでは、カテゴリ名と一致し、記事スニペットのプレビューからの同様のコンテンツを表すタグページが生成されます。解決策は、タグを賢明に使用し、追加するタグの数を制限することです。または、タグ ページにメタ ロボットの noindex dofollow を追加することもできます。
ウェブサイトの別個のモバイル バージョンを提供することを選択し、特にモバイル検索用に AMP ページを生成する場合、この種の重複が発生する可能性があります。
ページが重複していることを示すには、HTML の head セクションで <link> タグを使用します。モバイル バージョンの場合、これは次のように rel=“alternate” 値を持つリンク タグになります。
同じことが AMP ページにも当てはまります (トレンドではありませんが、モバイルの結果をレンダリングするために依然として使用できます) 。AMP ページの実装に関するガイドをご覧ください。
ローカライズされたコンテンツを表示するにはさまざまな方法があります。コンテンツを異なる言語/ロケールのバリアントで表示し、サイトのヘッダー/フッター/ナビゲーションのみを翻訳しても、コンテンツが同じ言語のままである場合、URL は重複として扱われます。
hreflangタグを使用して多言語および複数地域のサイトを表示するように設定し、サポートされている言語/地域コードを HTML、HTTP 応答コード、またはサイトマップに追加します。
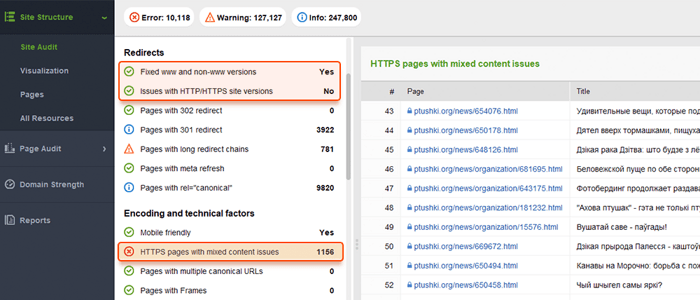
Web サイトは通常、ドメイン名に「www」が含まれている場合と含まれていない場合があります。この問題は非常に一般的であり、www バージョンと非 www バージョンの両方にリンクする人がいます。これを修正すると、検索エンジンが Web サイトの 2 つのバージョンのインデックスを作成するのを防ぐことができます。このようなインデックス作成によるペナルティは発生しませんが、1 つのバージョンを優先順位として設定することがベスト プラクティスです。
ほとんどの Web サイトでは安全な暗号化が強く推奨されているため、Google は HTTP よりも HTTPS を好みます (特に、トランザクションを実行したり機密のユーザー情報を収集する場合)。Web マスターは、SSL 証明書をインストールし、Web サイトの HTTP/HTTPS バージョンを設定するときに技術的な問題に直面することがあります。サイトに無効な SSL 証明書 (信頼できない証明書、または期限切れの証明書) がある場合、ほとんどの Web ブラウザは、「安全でない接続」を通知してユーザーがサイトにアクセスできないようにします。
Web サイトの HTTP バージョンと HTTPS バージョンが適切に設定されていない場合、どちらも検索エンジンによってインデックスに登録され、重複コンテンツの問題が発生して Web サイトのランキングが低下する可能性があります。
サイトが既に HTTPS を (部分的または全体的に) 使用している場合は、SEO サイト監査の一環として、一般的な HTTPS の問題を排除することが重要です。特に、 [サイト監査] > [エンコーディングと技術的要素]セクションで混合コンテンツがないか必ず確認してください。
混合コンテンツの問題は、安全なページがそのコンテンツの一部 (画像、ビデオ、スクリプト、CSS ファイル) を安全でない HTTP 接続経由で読み込むときに発生します。これによりセキュリティが弱まり、ブラウザが安全でないコンテンツやページ全体を読み込めなくなる可能性があります。
これらの問題を回避するには、 .htaccess ファイルでサイトのプライマリ www または非 www バージョンを設定して表示できます。また、Google Search Console で優先ドメインを設定し、HTTPS ページを正規として指定します。
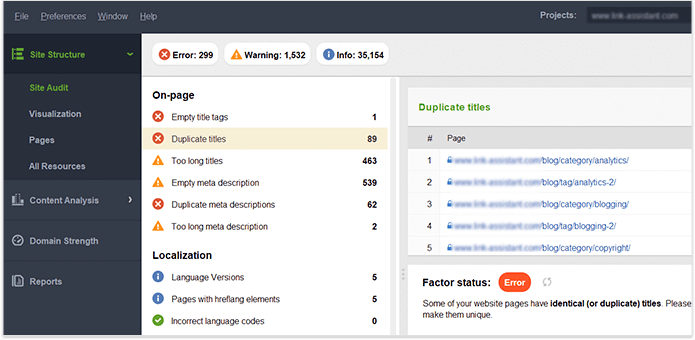
自分の Web サイト上のコンテンツを完全に管理できるようになったら、タイトル、見出し、説明、画像などが重複していないことを確認してください。サイト全体の重複コンテンツに関するヒントについては、 Website Auditorのサイト監査」の「ページ上のセクション」を参照してください。ダッシュボード。タイトルとメタ ディスクリプション タグが重複しているページには、コンテンツもほぼ同一である可能性があります。
インデックス作成の問題を発見して修正する方法をまとめてみましょう。上記のヒントをすべて実行しても、一部のページがまだインデックスに登録されていない場合は、この問題が発生した理由を以下にまとめます。
インデックスされるべきではないページがインデックスされるのはなぜですか?
robots.txt ファイルでページをブロックし、サイトマップから削除しても、そのページがインデックスに登録されなくなるという保証はないことに注意してください。ページのインデックス作成を正しく制限する方法については、詳細なガイドを参照してください。
浅くて論理的なサイト アーキテクチャは、ユーザーと検索エンジン ボットの両方にとって重要です。綿密に計画されたサイト構造も、次の理由からランキングに大きな役割を果たします。
サイトの構造と内部リンクを検討するときは、次の要素に注意してください。
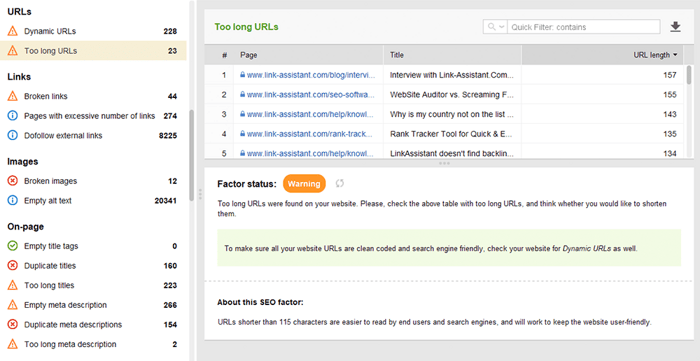
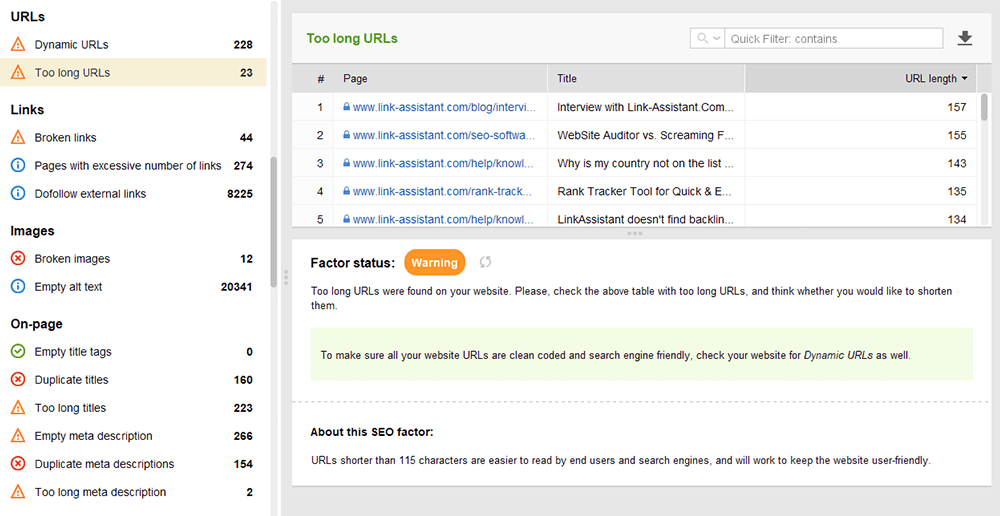
最適化された URL は 2 つの理由から重要です。まず、Google にとってはランキング要素としては重要ではありません。次に、長すぎる URL や不格好な URL によってユーザーが混乱する可能性があります。 URL 構造を考慮して、次のベスト プラクティスに従ってください。
WebSite Auditor の[サイト監査] > [URL]セクションで URL を確認できます。
リンクの種類はたくさんありますが、その中には Web サイトの SEO に多かれ少なかれ有益なものもあります。たとえば、 dofollow コンテキスト リンクはリンク ジュースを渡し、そのリンクが何に関するものであるかを検索エンジンに示す追加の指標として機能します。次の場合、リンクは高品質であるとみなされます (これは内部リンクと外部リンクの両方を指します)。
ヘッダーやサイドバーのナビゲーション リンクは、ユーザーや検索エンジンがページ内を移動するのに役立つため、Web サイトの SEO にとっても重要です。
他のリンクにはランキング価値がなかったり、サイトの権威に損害を与えたりする可能性があります。たとえば、テンプレート内のサイト全体にわたる大規模な発信リンク (無料の WP テンプレートには以前はこれがたくさんありました)。 SEO におけるリンクの種類に関するこのガイドでは、価値のあるリンクを正しい方法で構築する方法について説明します。
WebSite Auditorツールを使用すると、内部リンクとその品質を徹底的に検査できます。
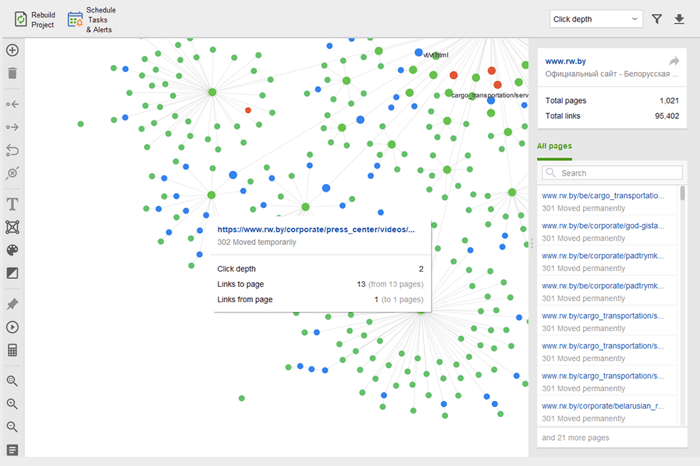
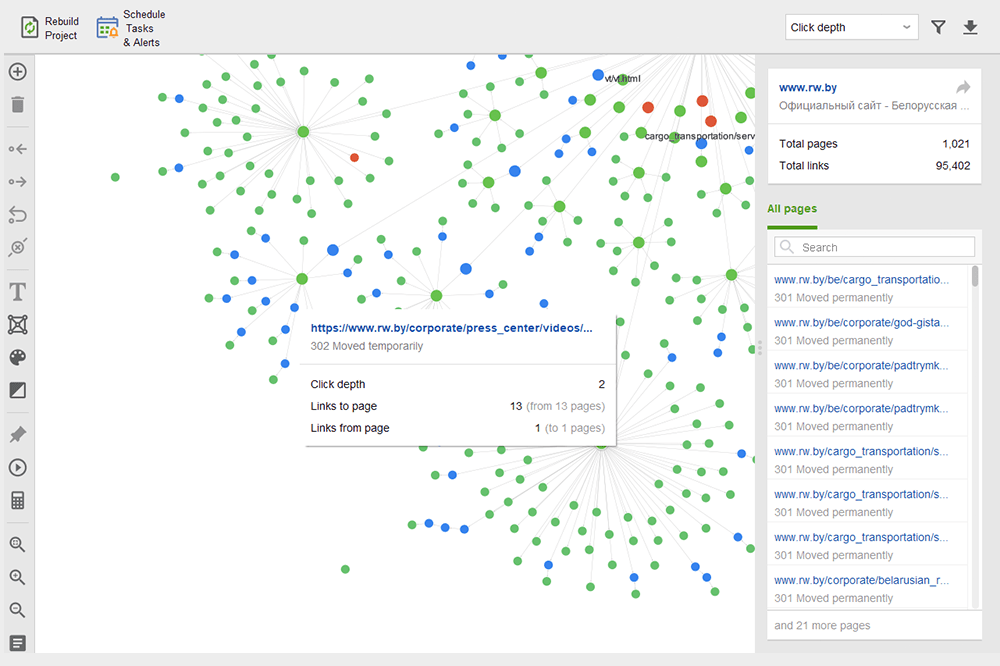
孤立ページとは、リンクされていないページであり、気付かれずに最終的には検索インデックスから外される可能性があります。孤立したページを見つけるには、 [サイト監査] > [視覚化]に移動し、 ビジュアル サイトマップを確認します。ここでは、リンクされていないすべてのページと長いリダイレクト チェーンが簡単に表示されます (301 および 302 リダイレクトは青色でマークされています)。
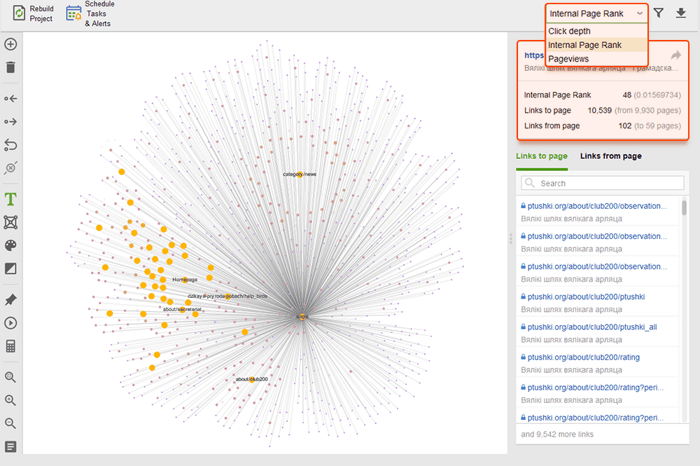
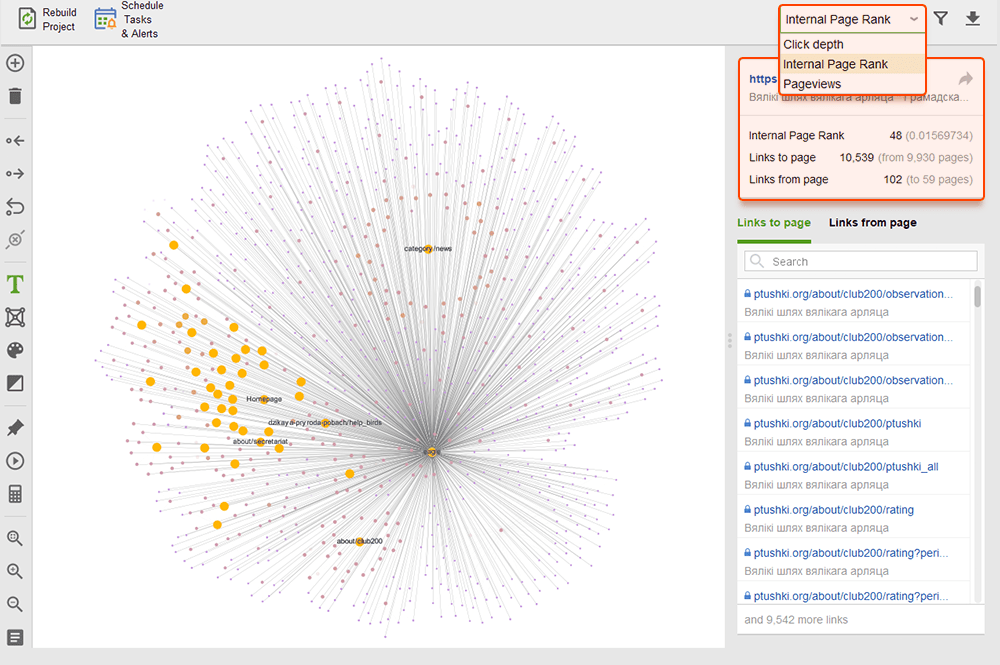
ページビュー (Google Analytics から統合)、PageRank、受信リンクと送信リンクから得られるリンク ジュースをチェックすることで、サイト全体の構造を概観し、メイン ページの重みを調べることができます。リンクを追加および削除し、プロジェクトを再構築して、各ページのプロミネンスを再計算できます。
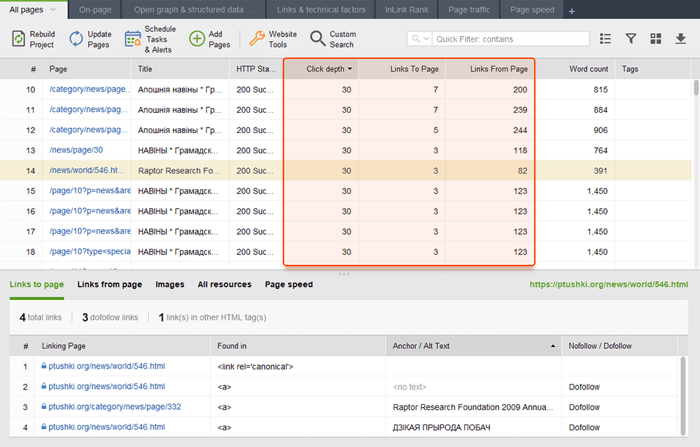
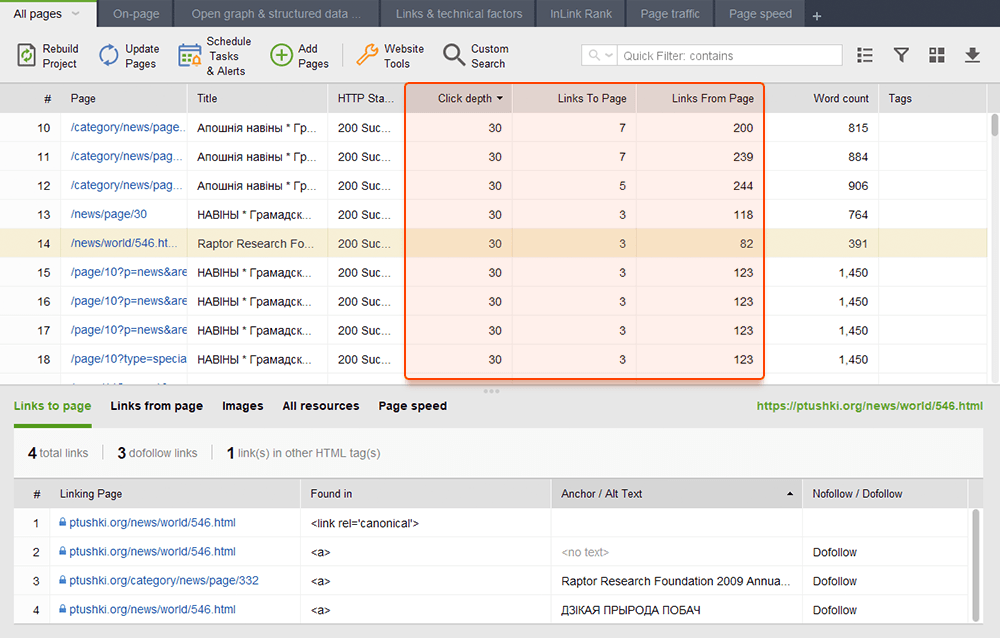
内部リンクを監査するときは、クリックの深さを確認してください。サイトの重要なページがホームページから 3 回以上クリックしないようにしてください。 WebSite Auditor でクリックの深さを確認するには、[サイト構造] > [ページ]に移動することもできます。次に、列のヘッダーを 2 回クリックして、URL をクリック深さの降順に並べ替えます。
ブログ ページのページネーションは検索エンジンで見つけやすくするために必要ですが、クリック深度は増加します。シンプルな構造と実用的なサイト検索を使用して、ユーザーがリソースを見つけやすくします。
詳細については、 SEO に配慮したページネーションの詳細ガイドを参照してください。
ブレッドクラムは、検索でリッチな結果を作成するのに役立つマークアップ タイプで、サイトの構造内のページへのパスを示します。ブレッドクラムは、内部リンク上の最適化されたアンカーと正しく実装された構造化データによる適切なリンクのおかげで表示されます (後者については、以下の数段落で説明します)。

実際、内部リンクはサイトのランキングや検索での各ページの表示方法に影響を与える可能性があります。詳細については、内部リンク戦略に関する SEO ガイドを参照してください。
サイトの速度とページエクスペリエンスは、オーガニックポジションに直接影響します。一度にアクセスするユーザーが多すぎると、サーバーの応答がサイトのパフォーマンスに問題になる可能性があります。ページ速度に関しては、Google は最大のページ コンテンツが 2.5 秒以内にビューポート内に読み込まれることを期待しており、最終的にはより良い結果をもたらしたページに報酬を与えます。そのため、サーバー側とクライアント側の両方で速度をテストし、改善する必要があります。
負荷速度テストでは、 Web サイトに同時にアクセスするユーザーが多すぎる場合にサーバー側の問題を発見します。この問題はサーバー設定に関連していますが、SEO 担当者は大規模な SEO キャンペーンや広告キャンペーンを計画する前にこの問題を考慮する必要があります。訪問者の急増が予想される場合は、サーバー負荷の最大容量をテストしてください。訪問者の増加とサーバーの応答時間の相関関係に注目してください。多数の分散アクセスをシミュレートし、サーバー容量のクラッシュ テストを可能にする負荷テスト ツールがあります。
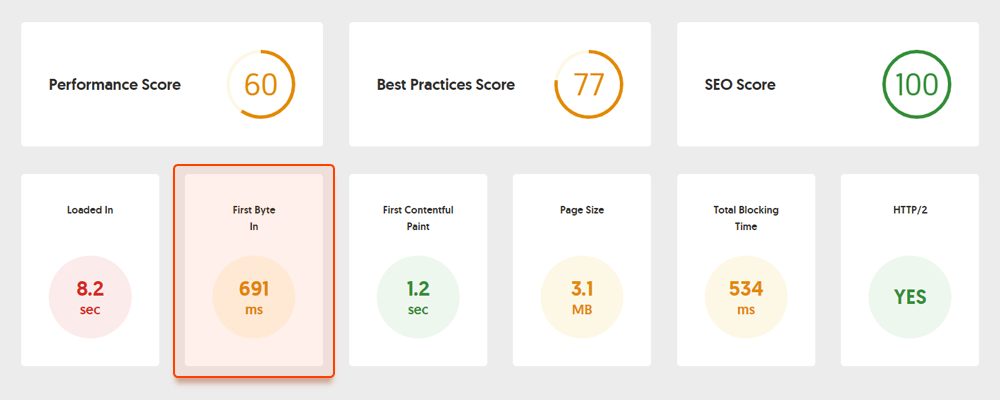
サーバー側では、最も重要なメトリクスの 1 つはTTFB測定、つまり最初のバイトまでの時間です。 TTFB は、ユーザーが HTTP リクエストを行ってから、クライアントのブラウザがページの最初のバイトを受信するまでの時間を測定します。サーバーの応答時間は、Web ページのパフォーマンスに影響します。ブラウザがサーバーの応答を 600 ミリ秒を超えて待機すると、TTFB 監査は失敗します。 TTFB を改善する最も簡単な方法は、共有ホスティングから管理ホスティングに切り替えることです。この場合、サイト専用のサーバーが必要になるためです。
たとえば、これはサイトのパフォーマンスをチェックする無料ツールである Geekflare を使用して作成されたページ テストです。ご覧のとおり、ツールはこのページの TTFB が 600 ミリ秒を超えていることを示しているため、改善する必要があります。

ただし、クライアント側ではページ速度を測定するのは簡単ではなく、Google はこの指標に長い間苦労してきました。最後に、特定のページの知覚速度を測定するために設計された 3 つの指標である Core Web Vitals に到達しました。これらのメトリクスは、最大コンテンツフル ペイン (LCP)、最初の入力遅延 (FID)、および累積レイアウト シフト (CLS) です。これらは、Web ページの読み込み速度、対話性、視覚的な安定性に関する Web サイトのパフォーマンスを示します。各 CWV メトリクスの詳細が必要な場合は、 Core Web Vitals に関するガイドをご覧ください。
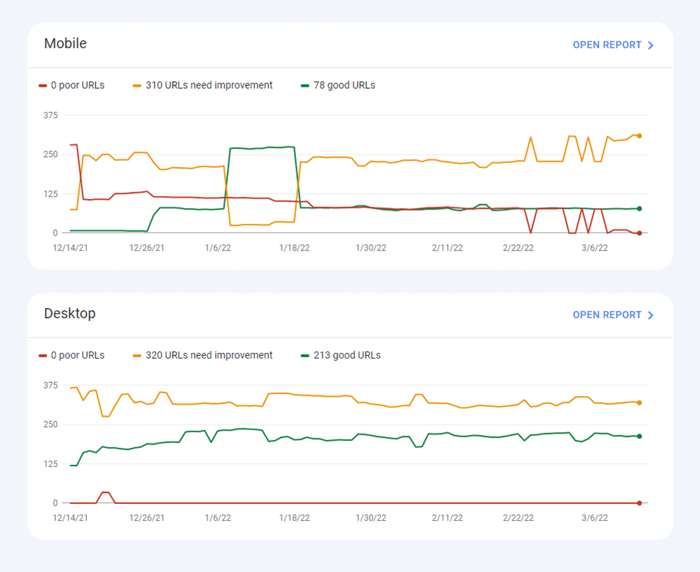
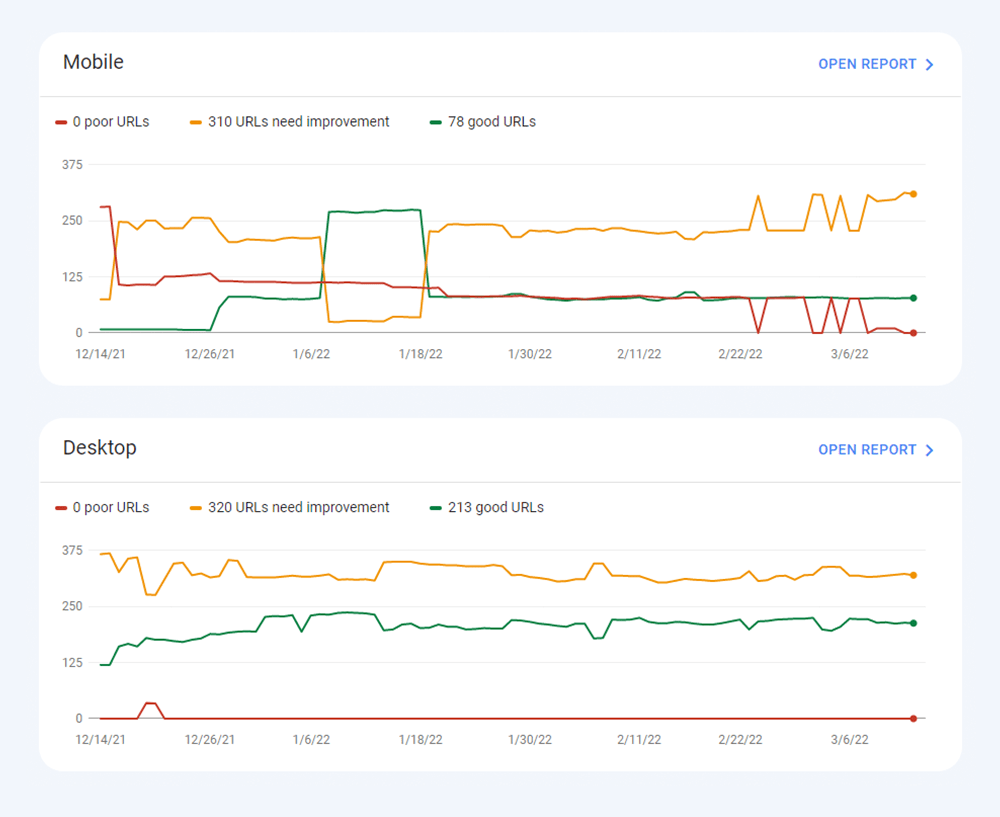
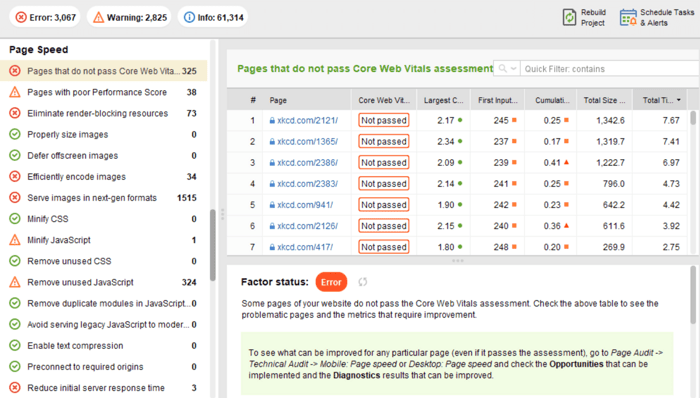
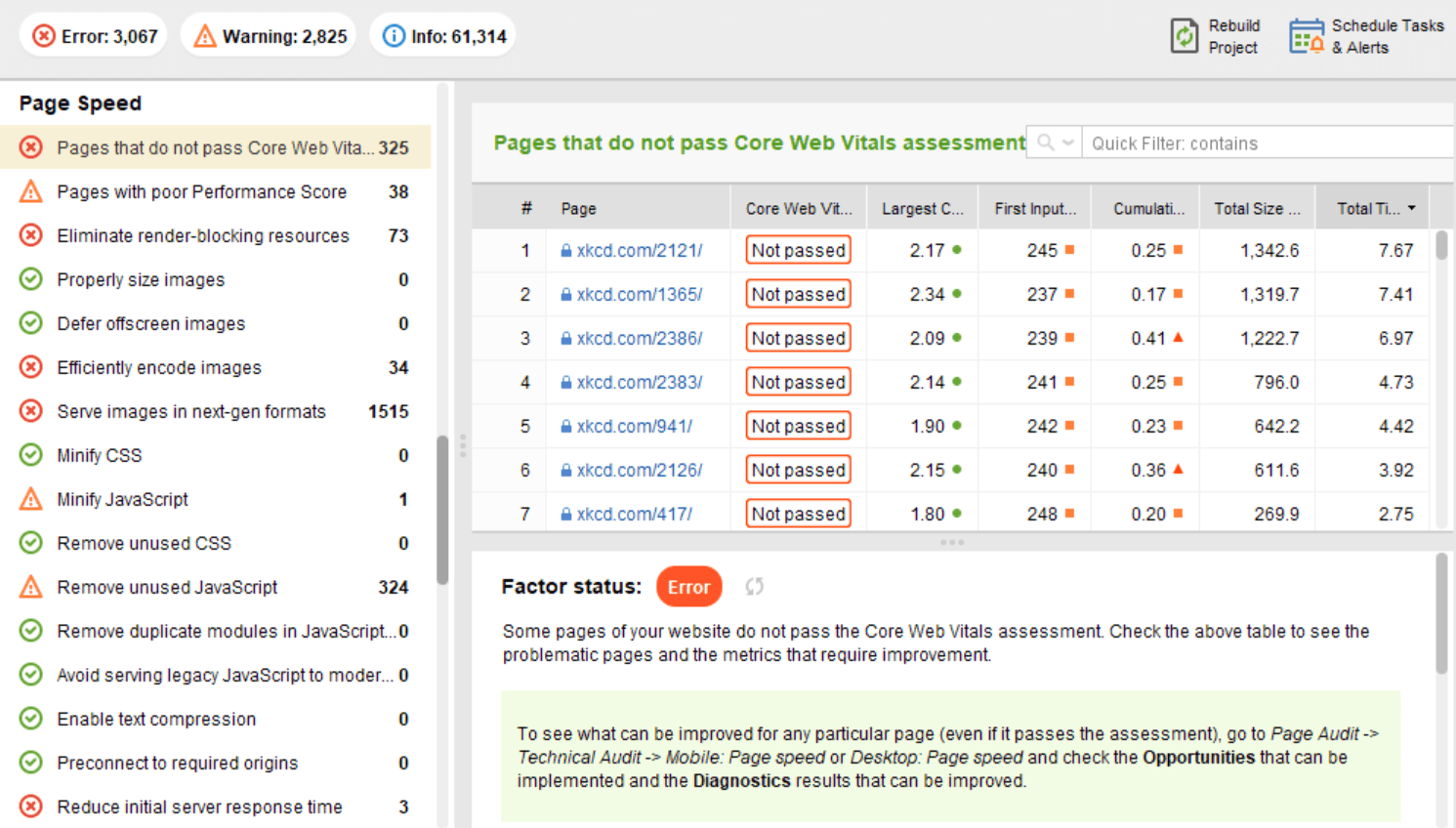
最近、3 つのコア Web Vitals メトリクスがすべてWebSite Auditor に追加されました。したがって、このツールを使用している場合は、各指標スコア、Web サイト上のページ速度の問題のリスト、影響を受けるページまたはリソースのリストを確認できます。データは、無料で生成できるPageSpeed API キーを介して分析されます。
WebSite Auditor を使用して CWV を監査する利点は、一度にすべてのページの一括チェックを実行できることです。同じ問題の影響を受けるページが多数ある場合は、問題がサイト全体に及ぶ可能性があり、1 つの修正で解決できる可能性があります。したがって、実際には、見た目ほど大した仕事ではありません。右側の推奨事項に従うだけで、ページの速度がすぐに向上します。
現在、モバイル検索者の数はデスクトップからの検索者数を上回っています。 2019 年、Google は モバイル ファースト インデックスを実装し、Googlebot デスクトップよりも先にスマートフォン エージェントが Web サイトを巡回しました。したがって、モバイルフレンドリー性はオーガニックランキングにとって最も重要です。
驚くべきことに、モバイル フレンドリーな Web サイトを作成するにはさまざまなアプローチがあります。
各ソリューションの長所と短所は、Web サイトをモバイル対応にする方法に関する詳細ガイドで説明されています。さらに、 AMP ページをブラッシュアップすることもできます。これは最先端のテクノロジーではありませんが、ニュースなど、一部の種類のページでは依然としてうまく機能します。
デスクトップとモバイルの両方に 1 つの URL を提供する Web サイトにとって、モバイル フレンドリー性は依然として重要な要素です。さらに、邪魔なインタースティシャルがないなど、ユーザビリティに関するシグナルの一部は、デスクトップとモバイルの両方のランキングに関連する要素であり続けます。そのため、Web 開発者は、あらゆる種類のデバイスで最高のユーザー エクスペリエンスを保証する必要があります。
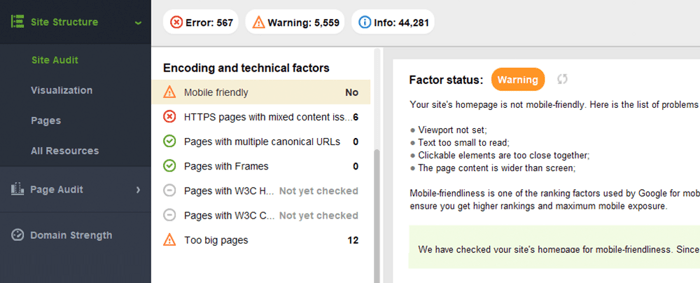
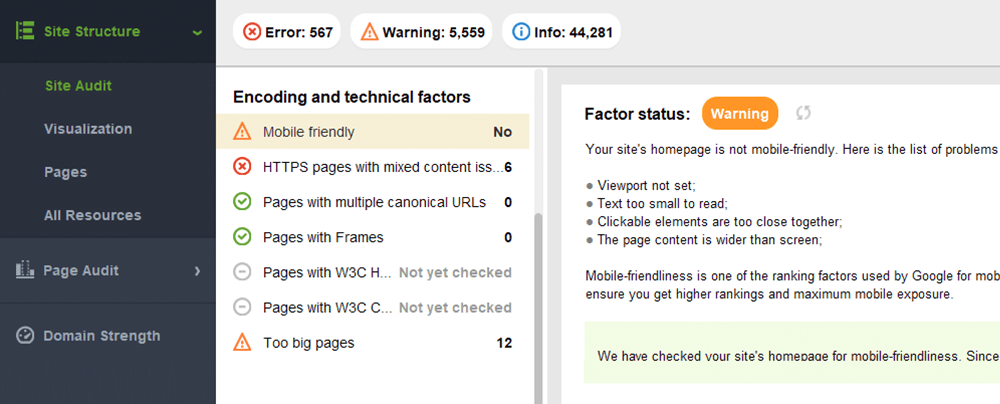
Google のモバイル フレンドリー テストには、ビューポートの構成、プラグインの使用、テキストとクリック可能な要素のサイズなど、一連のユーザビリティ基準が含まれています。モバイル フレンドリーかどうかはページごとに評価されるため、各ランディング ページのモバイル フレンドリー性を一度に 1 つずつ個別に確認する必要があることを覚えておくことも重要です。
ウェブサイト全体を評価するには、Google Search Console に切り替えます。 [エクスペリエンス]タブに移動し、 [モバイル ユーザビリティ]レポートをクリックして、すべてのページの統計を確認します。グラフの下には、モバイル ページに影響を与える最も一般的な問題を示す表が表示されます。ダッシュボードの下にある問題をクリックすると、影響を受けるすべての URL のリストが表示されます。
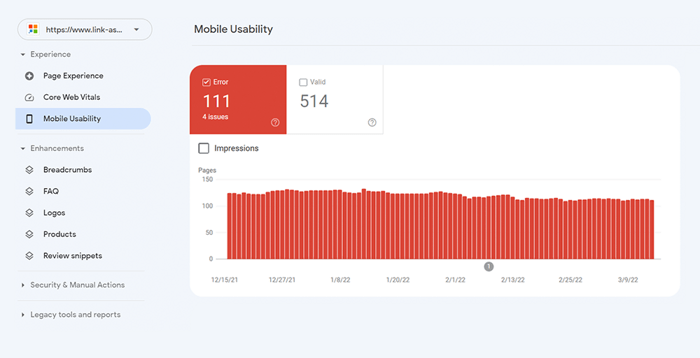

モバイル フレンドリーに関する一般的な問題は次のとおりです。
WebSite Auditor は、ホームページのモバイル フレンドリー性もレビューし、モバイル ユーザー エクスペリエンスの問題を指摘します。 [サイト監査] > [エンコーディングと技術的要素]に移動します。このツールは、サイトがモバイル フレンドリーかどうかを表示し、問題がある場合はそのリストを表示します。
ページ上のシグナルは直接的なランキング要素であり、Web サイトの技術的健全性がどれほど優れていても、適切なHTML タグの最適化がなければ、ページは検索に表示されません。したがって、あなたの目標は、Web サイト全体のコンテンツのタイトル、メタディスクリプション、H1 ~ H3 見出しをチェックして整理することです。
タイトルとメタ ディスクリプションは、検索エンジンによって検索結果のスニペットを形成するために使用されます。このスニペットはユーザーが最初に目にするものであるため、オーガニック クリックスルー率に大きな影響を与えます。
見出しは、段落、箇条書きリスト、その他の Web ページ構造要素と合わせて、Google で充実した検索結果を作成するのに役立ちます。さらに、ページの読みやすさとユーザーのインタラクションが自然に向上し、検索エンジンにとってポジティブなシグナルとして機能する可能性があります。目を離さない:
サイト全体でタイトル、見出し、説明が重複しています。ページごとに固有のタイトル、見出し、説明を記述して修正します。
検索エンジン向けのタイトル、見出し、説明の最適化 (長さ、キーワードなど)
コンテンツが薄い — コンテンツがほとんどないページはランク付けされることがほとんどなく、(パンダ アルゴリズムのせいで) サイトの権威を損なう可能性さえあるため、ページで主題を徹底的にカバーしていることを確認してください。
画像とマルチメディア ファイルの最適化 — SEO に適した形式を使用し、遅延読み込みを適用し、ファイルのサイズを変更して軽量化するなどします。詳細については、画像の最適化に関するガイドを参照してください。
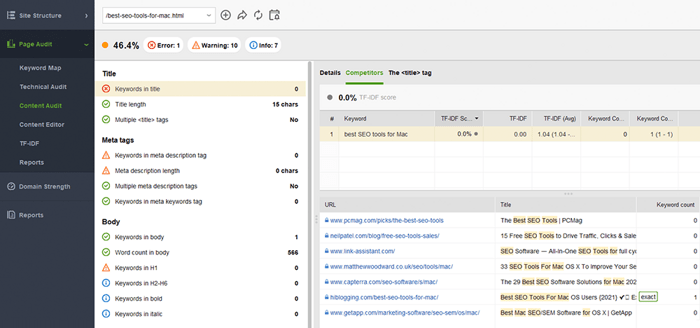
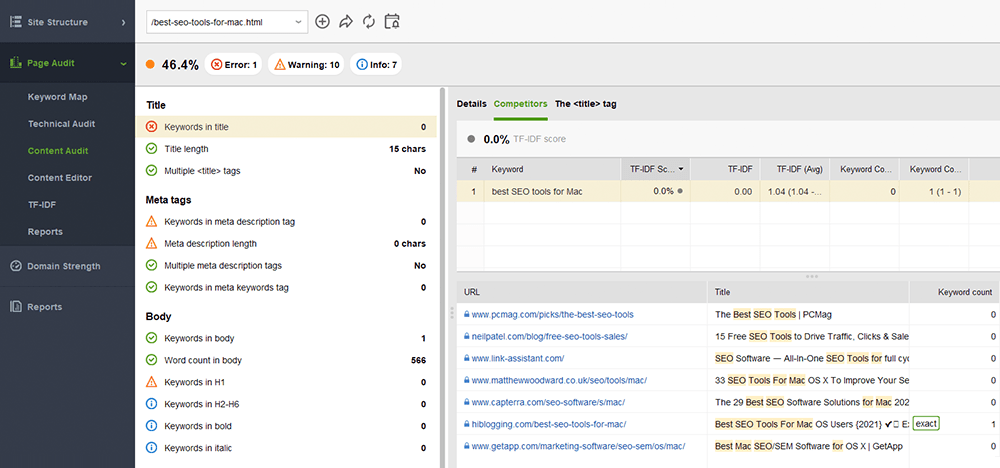
WebSite Auditor は、このタスクに大いに役立ちます。 [サイト構造] > [サイト監査]セクションでは、Web サイト全体のメタ タグの問題を一括でチェックできます。個々のページのコンテンツをより詳細に監査する必要がある場合は、 「ページ監査」セクションに移動してください。このアプリには、SERP の上位競合他社に基づいてページを書き直す方法についての提案を提供する、 書き込みツールのコンテンツ エディターも組み込まれています。外出先でページを編集したり、コピーライターのタスクとして推奨事項をダウンロードしたりできます。
詳細については、ページ上の SEO 最適化ガイドをご覧ください。
構造化データは、検索ボットがページのコンテンツをよりよく理解できるようにするセマンティック マークアップです。たとえば、ページにアップルパイのレシピが掲載されている場合、構造化データを使用して、どのテキストが材料、調理時間、カロリー数などであるかを Google に伝えることができます。 Google はマークアップを使用して、SERP 内のページのリッチ スニペットを作成します。
構造化データには 2 つの一般的な標準があります。1 つはソーシャル メディアでの美しい共有のためのOpenGraph 、もう 1 つは検索エンジンのためのSchemaです。マークアップ実装のバリエーションは次のとおりです: Microdata、RDFa、およびJSON-LD 。 Microdata と RDFa はページの HTML に追加されますが、JSON-LD は JavaScript コードです。後者はGoogleによって推奨されています。
ページのコンテンツ タイプが以下のいずれかの場合は、マークアップが特に推奨されます。
構造化データを操作すると、検索エンジンからペナルティを受ける可能性があることに注意してください。たとえば、マークアップは、ユーザーから隠されているコンテンツ (つまり、ページの HTML に含まれていないコンテンツ) を記述すべきではありません。実装前に構造化データ テスト ツールを使用してマークアップをテストします。
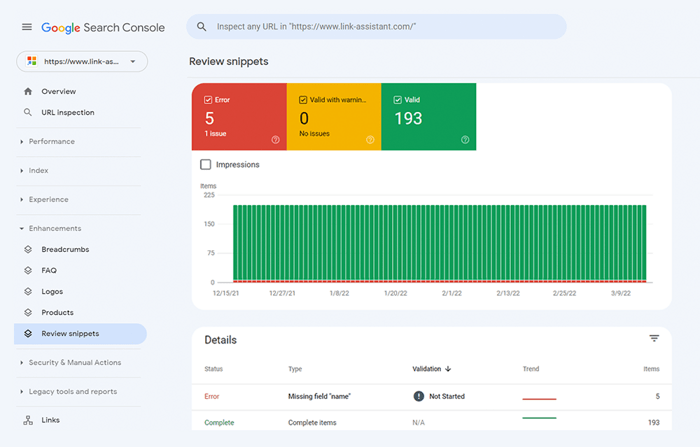
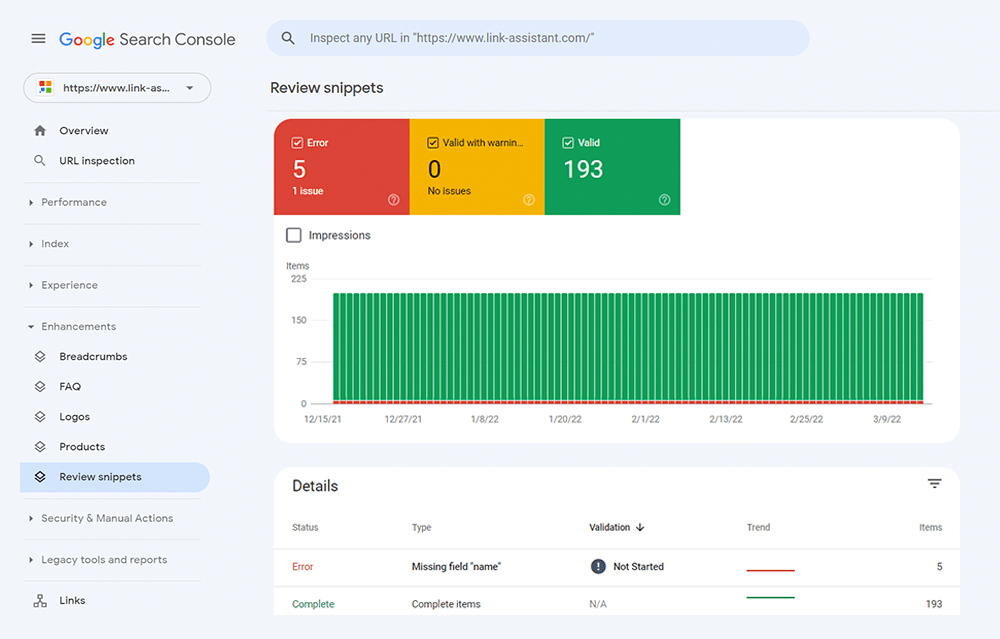
Google Search Console の[拡張機能]タブでマークアップを確認することもできます。 GSC は、Web サイトに実装しようとした機能拡張を表示し、成功したかどうかを通知します。
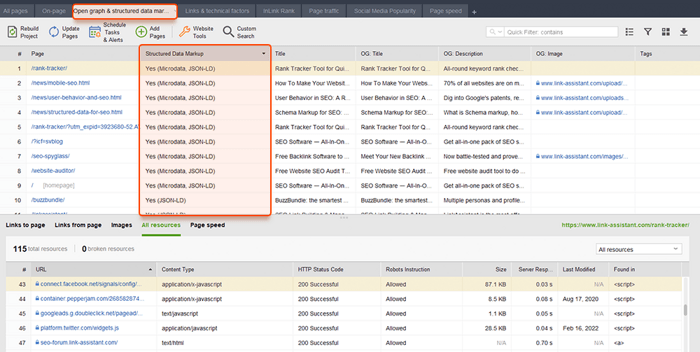
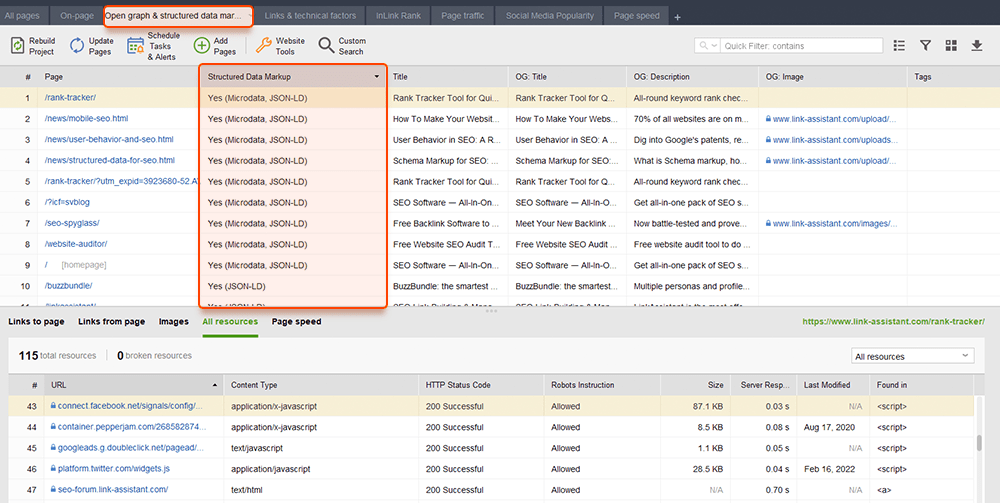
WebSite Auditorもここで役立ちます。このツールはすべてのページをレビューし、ページ上の構造化データの存在、そのタイプ、タイトル、説明、OpenGraph ファイルの URL を表示できます。
スキーマ マークアップをまだ実装していない場合は、構造化データに関するこの SEO ガイドを確認してください。 Web サイトが CMS を使用している場合、構造化データがデフォルトで実装されているか、プラグインをインストールすることによって構造化データを追加できることに注意してください (とにかくプラグインを使いすぎないでください)。
Web サイトを監査し、発見された問題をすべて修正したら、変更をより早く確認できるように Google にページの再クロールを依頼できます。
Google Search Console で、更新された URL を URL 検査ツールに送信し、 [インデックス登録をリクエスト]をクリックします。また、ライブ URL のテスト機能 (以前はFetch as Google機能と呼ばれていました) を利用して、ページを現在の形式で表示し、インデックス作成をリクエストすることもできます。
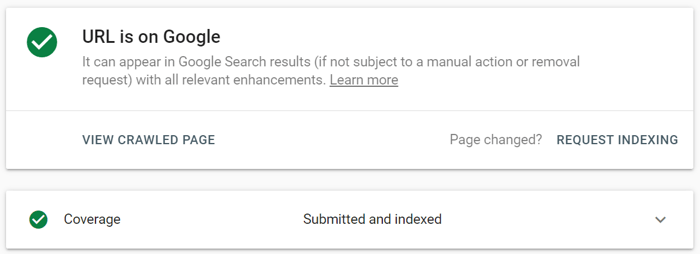
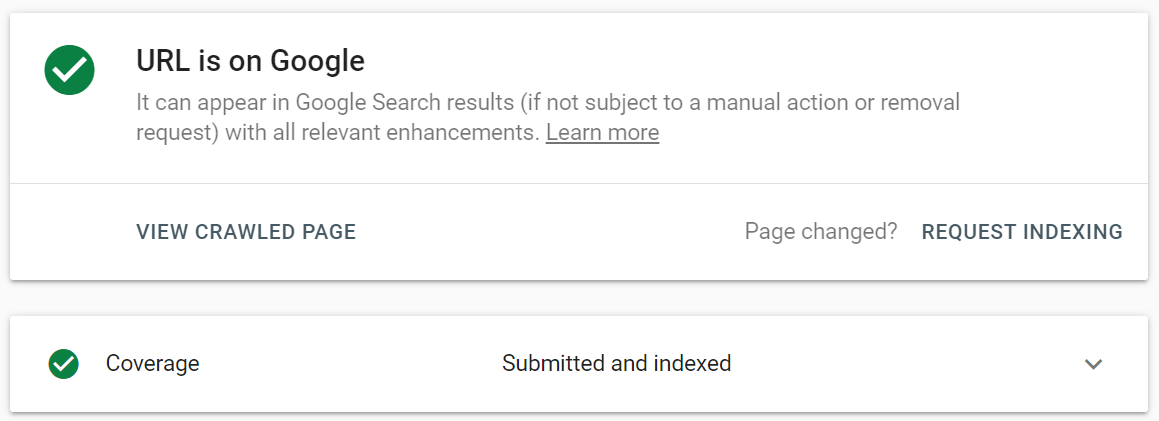
URL 検査ツールを使用すると、レポートを展開して詳細を確認したり、ライブ URL をテストしたり、インデックス作成をリクエストしたりできます。
Web サイトで何かを変更するたびに、実際には再クロールを強制する必要はないことに注意してください。変更が深刻な場合は、再クロールを検討してください。たとえば、サイトを http から https に移動した、構造化データを追加したり、コンテンツの最適化を行ったり、Google に早く掲載したい緊急のブログ投稿を公開したりした場合などです。Google には制限があることに注意してください。月あたりの再クロール アクションの数に応じて変化するため、乱用しないでください。さらに、ほとんどの CMS は変更を加えるとすぐに Google に送信するため、CMS (Shopify や WordPress など) を使用している場合は再クロールする必要がない場合があります。
クローラーがページにアクセスする頻度に応じて、再クロールには数日から数週間かかる場合があります。再クロールを複数回リクエストしてもプロセスは高速化されません。大量の URL を再クロールする必要がある場合は、URL 検査ツールに各 URL を手動で追加するのではなく、サイトマップを送信してください。
同じオプションが Bing ウェブマスター ツールでも利用できます。ダッシュボードで[個人用サイトの構成]セクションを選択し、 [URL の送信]をクリックするだけです。インデックスを再作成する必要がある URL を入力すると、Bing が数分以内にその URL をクロールします。このツールを使用すると、ウェブマスターはほとんどのサイトで 1 日あたり最大 10,000 件の URL を送信できます。
ウェブ上では多くのことが起こる可能性があり、そのほとんどがランキングに良くも悪くも影響を与える可能性があります。そのため、Web サイトの定期的な技術監査は SEO 戦略の重要な部分である必要があります。
たとえば、 WebSite Auditorで技術的な SEO 監査を自動化できます。プロジェクトの再構築タスクを作成し、スケジュール設定 (たとえば月に 1 回) を設定するだけで、ツールによって Web サイトが自動的に再クロールされ、最新のデータが取得されます。
監査の結果をクライアントや同僚と共有する必要がある場合は、WebSite Auditor のダウンロード可能な SEO レポート テンプレートの 1 つを選択するか、カスタム レポート テンプレートを作成します。
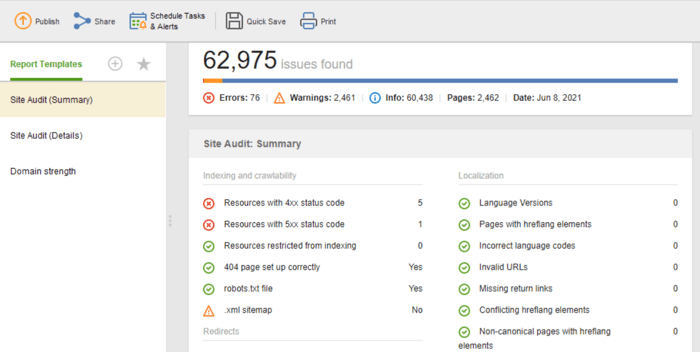
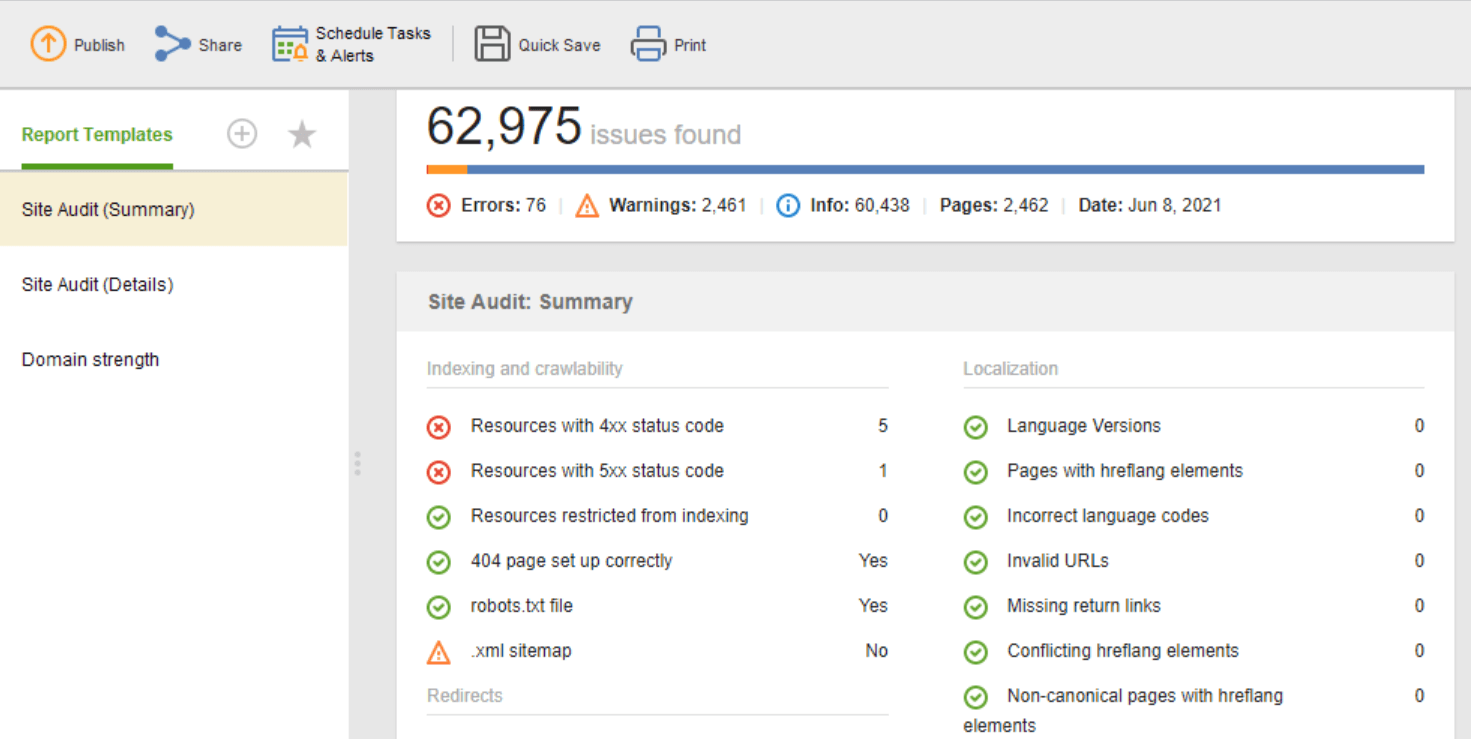
サイト監査 (概要)テンプレートは、Web サイト編集者が最適化作業の範囲を確認するのに最適です。サイト監査 (詳細)テンプレートはより説明的で、各問題とそれを修正することが重要な理由が説明されています。 Website Auditor では、サイト監査レポートをカスタマイズして、定期的に監視する必要があるデータ (インデックス作成、リンク切れ、ページ上など) を取得できます。その後、CSV/PDF としてエクスポートするか、データをスプレッドシートにコピーペーストして手元に用意できます。開発者に修正を依頼します。
さらに、WebSite Auditor のサイト監査レポートに自動的に収集された、Web サイト上の技術的な SEO 問題の完全なリストを取得できます。さらに、詳細なレポートでは、各問題とその修正方法についての説明が提供されます。
これらは、定期的な技術サイト監査の基本的な手順です。このガイドでは、徹底したサイト監査を実施するためにどのようなツールが必要か、SEO のどの側面に注意すべきか、Web サイトの SEO の健全性を維持するためにどのような予防策を講じるべきかが最良の形で説明されることを願っています。
テクニカルSEOとは何ですか?
テクニカル SEO は、検索ボットがより効果的にページにアクセスできるようにする、Web サイトの技術的側面の最適化を扱います。テクニカル SEO では、クロール、インデックス作成、サーバー側の問題、ページ エクスペリエンス、メタ タグの生成、サイト構造を扱います。
技術的な SEO 監査はどのように実施しますか?
テクニカル SEO 監査は、すべての URL を収集し、Web サイトの全体的な構造を分析することから始まります。次に、ページのアクセシビリティ、読み込み速度、タグ、ページ上の詳細などをチェックします。技術的な SEO 監査ツールは、無料のウェブマスター ツールから SEO スパイダー、ログ ファイル アナライザーなどまで多岐にわたります。
サイトをいつ監査する必要がありますか?
技術的な SEO 監査では、さまざまな目標を追求する場合があります。 Web サイトを公開する前、または進行中の最適化プロセス中に監査することが必要な場合があります。また、サイトの移行を実施したり、Google の制裁を解除したい場合もあります。それぞれのケースにおいて、技術監査の範囲と方法は異なります。





![WebSite Auditor の [すべてのリソース] > [内部リソース] タブでブロック ルールを確認します。](https://cdn1.link-assistant.com/thumbs/w700-c1/upload/news/posts/261/X-Robots-tag.png)
![WebSite Auditor の [すべてのリソース] > [内部リソース] タブでブロック ルールを確認します。](https://cdn1.link-assistant.com/upload/news/posts/261/X-Robots-tag.png)