13273
•
10-minute read


Canonical URLs are an important part of SEO if they are implemented correctly. If not, they can become an issue and cause chaos in your site structure.
Today, I’m going to share in detail what canonical URLs are, why they are important, and how to find them on your website to keep them groomed.
Hey! Watch our new video about canonical tags and how to find them on your site.
A canonical URL, or a canonical link, is like the "boss" page when you have other pages that are very similar or the same. It is the URL that Google indexes and displays in search results.
A canonical tag — rel=”canonical” — is an HTML element that is used to define the canonical page. A canonical tag is put in the HTML of a duplicate page to point to the “main” version.
Example
On your site, you have the two following URLs:
As the content of these pages is identical, you need to specify which version is preferred for indexation. To do this, you need to add the rel="canonical" tag to the duplicate page’s HTML, like this:
<link rel="canonical" href="www.site.com/shoes-with-roses.html"/>
Canonical URLs are necessary to prevent duplicate content issues and, consequently, avoid Google sanctions that may follow. That’s why rel="canonical" is applied to pages with UTM parameters, printed versions, pages with additional filters, dynamic URLs, and language versions.
Duplicate content issues are especially common for ecommerce websites. That’s why many content management systems, automatically canonicalize the “main” page to prevent possible problems.
This is how Shopify, Wix, and WordPress work, for example. The CMSs automatically mark “clean” URLs as canonicals, so the dynamic URL structure that is common for ecommerce websites does not harm SEO.
Other CMSs including Joomla! and Adobe Ecommerce (ex. Magento) require plugins to set up canonicals.
To find canonical URLs on your site, you need to conduct a website audit. You can use any site audit tool you are used to but make sure it is capable of finding canonicals. I’ll describe a couple of handy ways below.
For starters, you can use Google Search Console. While the tool may seem pretty basic, it can give you a lot of useful insights and field data right from Google.
So, to find canonicals with GSC, go to the Indexing > Pages report, and look at the reasons why some of your pages are not indexed. You need the lines stating
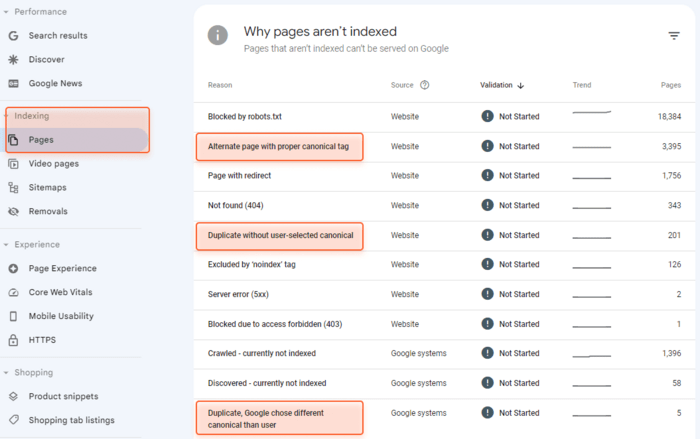
URLs under the Alternate page with proper canonical tag section are the pages that have specified canonical tags. In this case, Google serves the page that you specified as a canonical one. To see what page it is, inspect the URL under consideration:


The Duplicate without user-selected canonical section contains the list of duplicate URLs without specified canonical tags. In this case, Google chooses what pages to serve on its own.
Inspect the necessary URL to see what page has been indexed by Google:


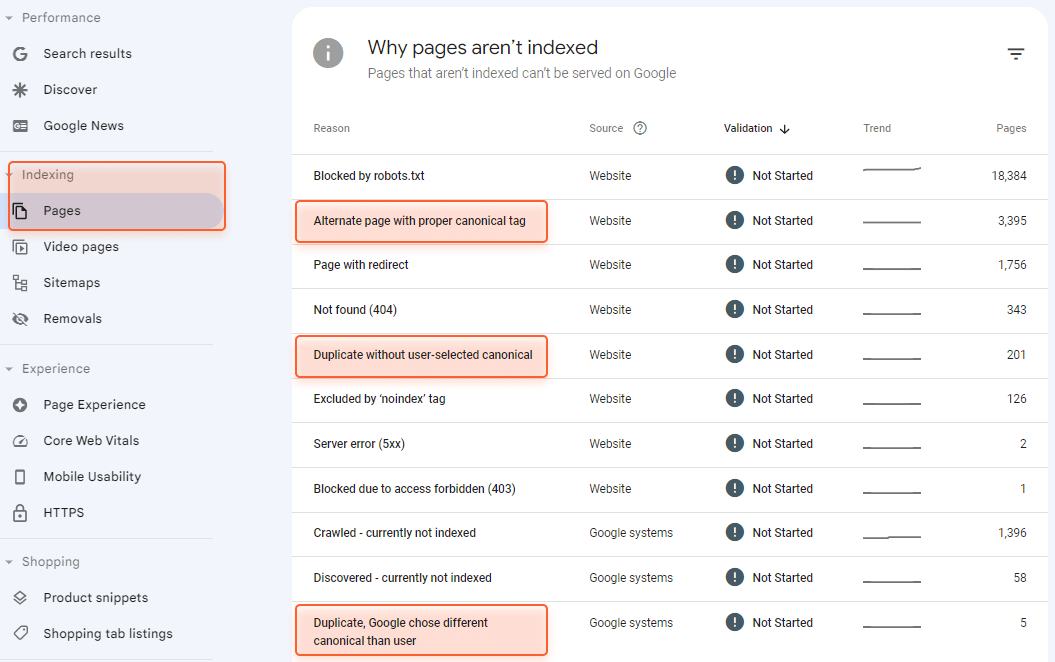
Still, keep in mind that Google treats rel=”canonical” as a hint, not a directive. That’s why Google can sometimes choose to serve a different canonical page instead of the page you have specified. In Search Console, these pages are listed under the Duplicate, Google chose different canonical than user section:


While GSC does help you in spotting pages with the canonical tag, you still need to manually inspect each URL in order to see the page that is treated as a canonical one. That’s why I recommend using more sophisticated SEO tools.
WebSite Auditor is a powerful SEO audit tool that covers literally any aspect of a site’s SEO health. And, sure thing, the tool is capable of finding pages with canonical tags in bulk.
To find canonical URLs using WebSite Auditor, launch the tool and create a project for your website (in case you haven’t used the tool before).
Then go to the Site Structure > Site Audit section and scroll down to Redirects. Click the Pages with rel=“canonical” line, and here you are:
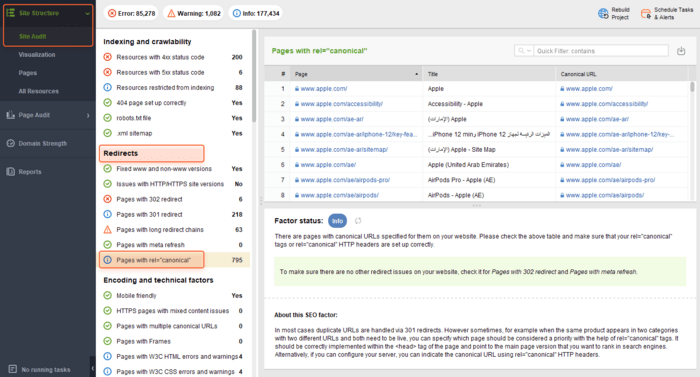
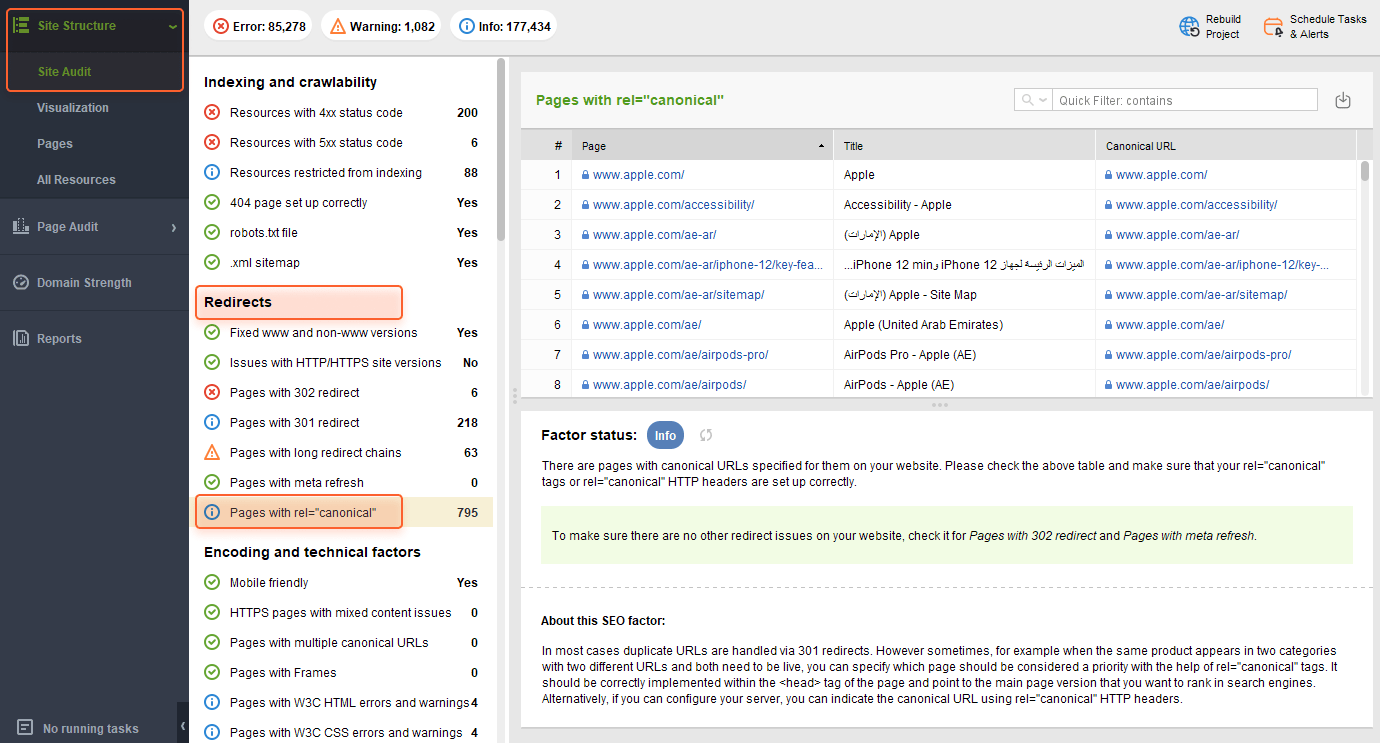
Unlike GSC, WebSite Auditor lets you see all the pages with canonical tags at a glance. Plus, the tool instantly gives you URLs stated as canonicals for each page in the list.
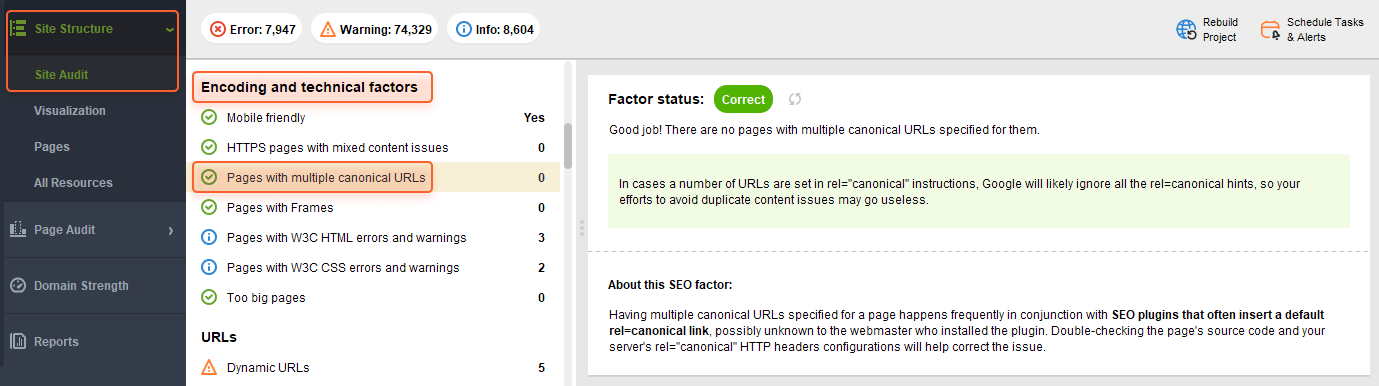
Another section to look at in search of issues related to canonical URLs is Encoding and technical factors > Pages with multiple canonical URLs. Here you can find the pages for which multiple canonical URLs are specified. If there are no issues, the section will look like this:
Implementing canonical tags is easy. You just need to add the rel=“canonical” tag to the <head> section of a duplicate page. The href link should point to the “main” page.
<link rel="canonical" href="https://www.site.com/shoes-with-roses.html"/>
To specify canonical for non-HTML pages like PDF files, add a rel=“canonical” HTTP header response right on your site server:
HTTP/1.1 200 OK
Content-Length: 19
...
Link: https://www.site.com/shoes-with-roses.pdf>; rel="canonical"
Although canonical tag implementation should not cause problems, make sure you follow the best practices. This way, you’ll surely avoid problems with indexation and content duplicate issues.


Much has been said about the importance of proper canonical tag implementation. But mistakes still happen. Look at the below-listed flaws and never repeat them, at least intentionally.
The main mistake related to canonical URLs is — a paradox — the absence of the rel=“canonical” tag.
People often forget to place canonical tags on pages with UTM parameters or printed versions, thinking that Google will choose the better version itself. Like, if Google can choose different versions despite the stated canonical ones, why care?
The truth is that Google may also restrain from choosing anything at all and index all the URLs it discovers. This will only result in content duplicate issues.
Although duplicate content itself does not cause any manual penalties from Google, it may decrease the overall site authority. Besides, content duplicate issues slow down indexation, as the crawl budget is wasted on each duplicate URL.
Broken links do not bring you clicks, traffic, and SEO effort payoff. The same is true when it comes to canonical URLs.
When a duplicate page with a canonical tag responds 404 not found, Google will not be able to crawl it, see the tag, and, consequently, the canonical URL you have stated. This works pretty much like blocking a page with robots.txt or using a noindex tag.
If a canonical URL is broken, then Google will pass all the link equity to nowhere.
Specifying a canonical link that redirects to some other page will only confuse Google and may result in indexing issues and link juice loss.
Using 301 redirects is only needed when you want to permanently replace a page with a new, more relevant one with better content. These will not be duplicate pages but two different ones.
As redirect makes the old page version unavailable, indicate the destination page as canonical everywhere the previous one was used.
Feel free to read our guide on redirects to choose the best solutions for your site.
Finding and inspecting canonical URLs is an important part of any SEO audit. Do it regularly, avoid mistakes, and fix everything timely to make your site rank and prosper.
By the way, what canonical URL tactics and best practices do you use in your SEO routine? Share your experience in our Facebook community.

