16110
•
15-minute read


Would you ever sit at a chess board without knowing how to play? I would at least doubt the success of this endeavor. The same is true for SEO – you can’t nail it if you don’t know how Google works.
After reading this article, you’ll understand how Google chooses what pages to show first and how you can help it choose in your favor.
Notionally, Google work starts with crawling.
As there’s no central registry of all web resources in the world, Google somehow needs to explore the whole web itself on a regular basis. To do this, Google uses automated software known as a web crawler, or simply Googlebot.
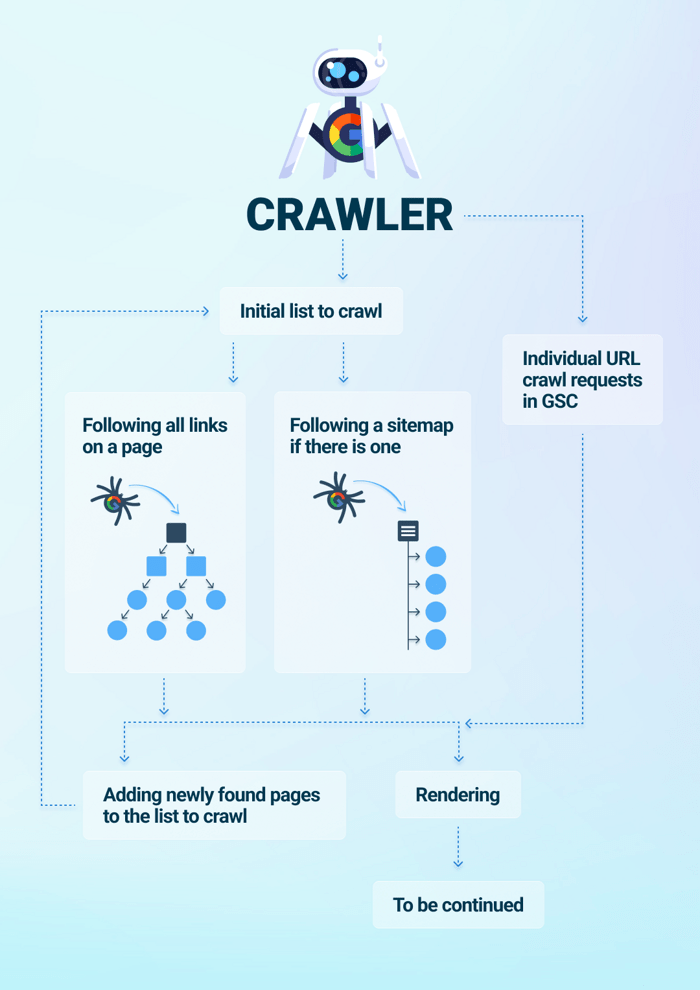
Googlebot regularly wanders through the Internet and searches for new or recently updated webpages. This process is called crawling. As a rule, it is done in a few ways.
First, Googlebot visits the pages it's already discovered during previous crawls. Here it follows either all links found there or the XML sitemap if there is one submitted. All the newly found pages are then added to the list of pages to crawl later.
Second, Googlebot crawls the pages that are submitted by site owners via Google Search Console. There, the crawler gets another portion of webpages to add to its crawling queue.

Normally, Googlebot will crawl all the new pages it finds. However, a page will not be crawled if:
If a page is a duplicate of another page, Googlebot will visit it less frequently to make crawling more efficient.
Apart from finding new pages on the web, the crawling stage also includes the rendering (visualization) of a newly discovered page. Googlebot uses the Chrome browser to load the page’s HTML, third-party code, JavaScript, and CSS.
If you feel the need to study the topic in-depth, there is our cool guide on how Google crawler works to read.
After Googlebot finds a new page, it then tries to understand what this page is about. The process is known as indexing. It includes a thorough analysis of all page elements such as text content, meta tags and attributes, images, and videos, etc.
As a rule, all newly discovered and crawled pages are then getting indexed. The only exception is if the page has the noindex directive in a tag or header. In this case, Googlebot won’t index the page.
When indexing is done, the crawler catalogs the page in the Google index – the database of Google Search. For now, the Google index counts hundreds of billions of webpages.


Once this new page is indexed, it is ready to be served to searchers.
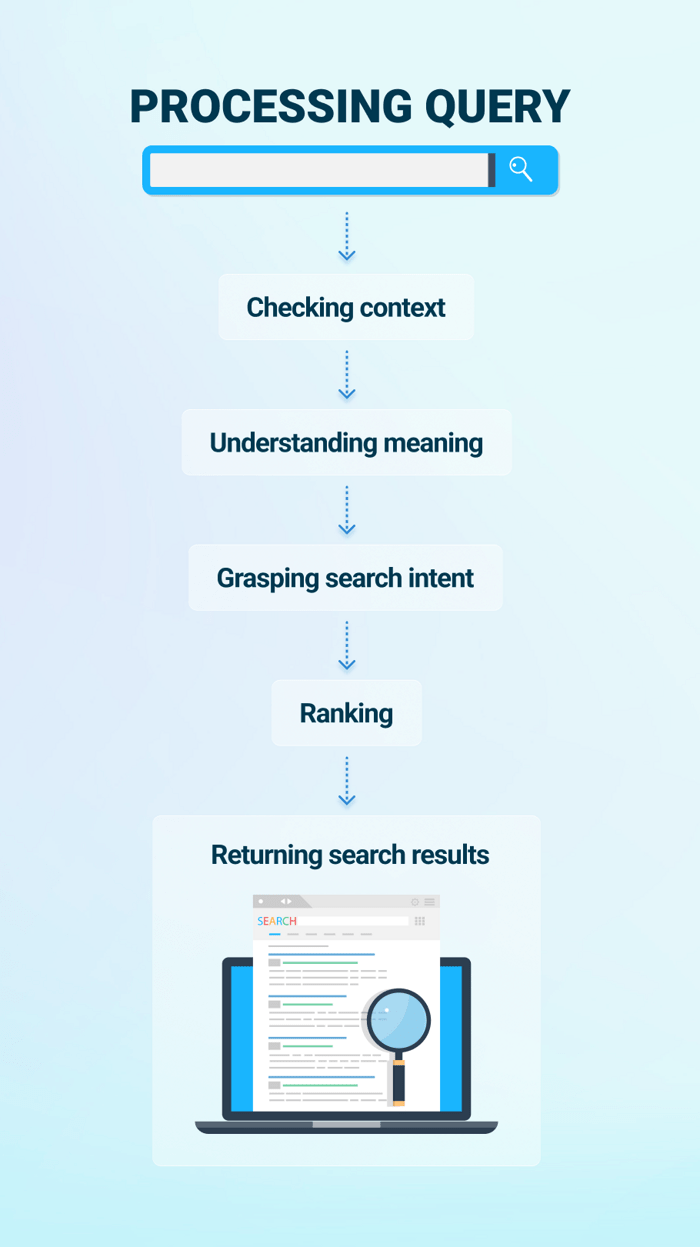
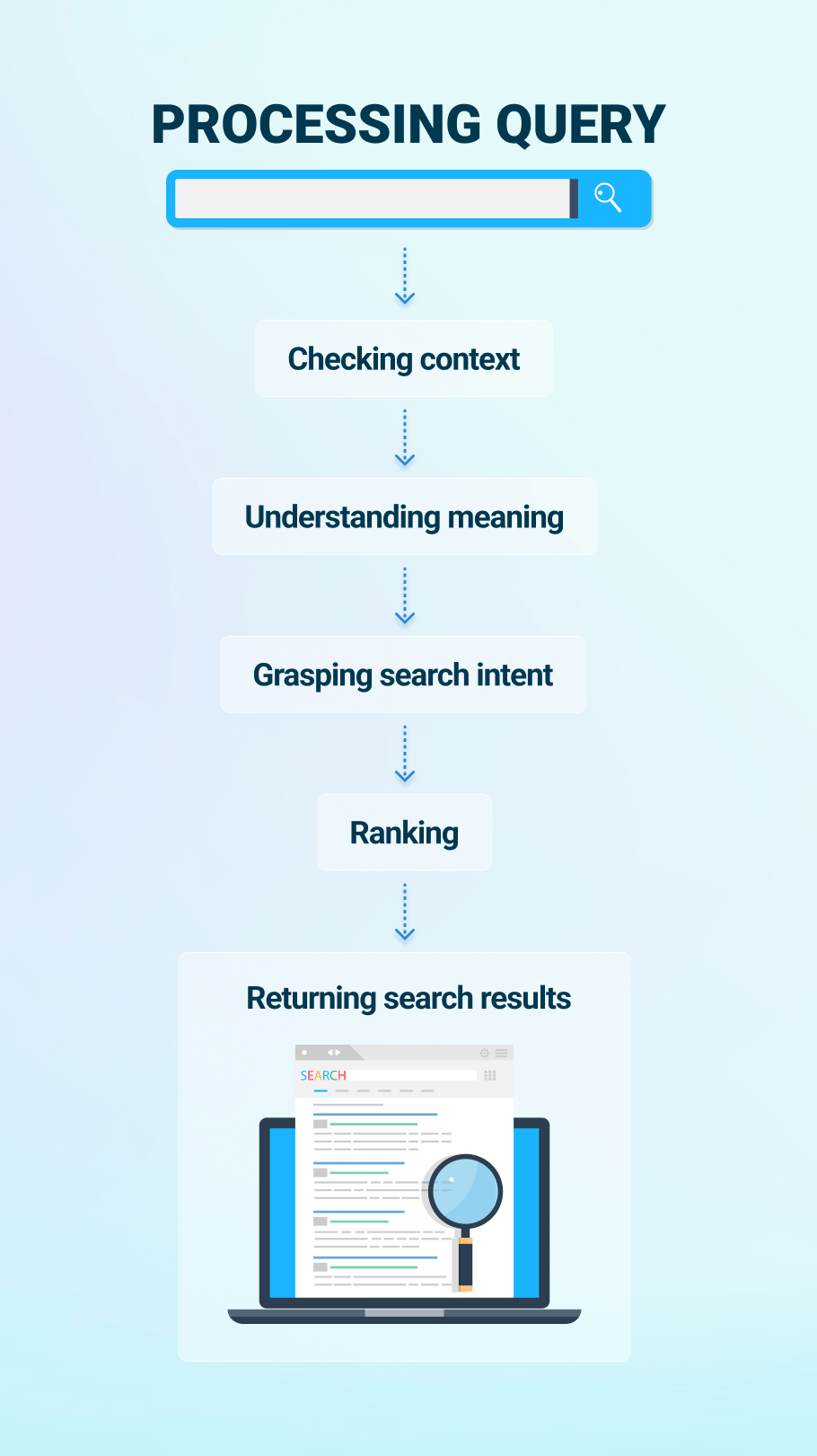
Every time a user enters a query into the Search box, Google turns to its index to find and serve the most relevant results. The process is called “serving” and includes eight steps.
By the moment you submit your search request, Google will already factor in a few things that will help it narrow down the index, and filter out irrelevant results.
Here’s what Google checks even before you hit Enter:
After you’ve submitted your search request to Google, it then has to understand the actual meaning behind your query. It’s not always that users know how to spell something correctly or phrase the query the way webmasters do.
The first thing Google does for that matter is recognize new words and correct spelling mistakes. Google uses natural language understanding models to decipher unknown words, slip-of-finger and conceptual mistakes. This is mainly achieved by looking at the entire query instead of focusing on one word.
Then Google identifies the meaning and intent of the query. Earlier, Google was matching words in queries to words on pages without understanding their meaning. Everything changed with the Hummingbird algorithm introduction in 2013. That’s when Google stepped into a new era of semantic search and developed its capabilities of understanding the meaning of the query rather than individual keywords. This update is the forerunner of the Artificial Intelligence systems that became the biggest breakthrough in natural language processing.
I’ll be honest with you. SEOs around the globe are trying to figure out AI algorithms Google uses, but the topic is anything but clear. Maybe, it’s because Google doesn’t want to share its trade secrets. Or maybe it’s Google spokesmen that aren’t in the know enough. Anyway, the most authoritative and clearly-worded reading on the topic is this Barry Schwartz’s post.
There are 3 semantic processing systems Barry makes emphasis on: RankBrain, Neural Matching, and BERT. They were launched gradually, and their aims overlap. So, I divided their spheres of influence to simplify this for you:
By applying these three AI algorithms and enhancing the process with some dark art, Google understands the meaning of the query and moves on to the next stage.
Once Google grasps the meaning and intent of your search query, it then checks if you're looking for something that requires the most recent and up-to-date information (news, politics, events, etc.).
To detect if you are looking for current information, Google applies the Query Deserves Freshness (QDF) mathematical model to your query. First, the model identifies that the topic is hot if news sites or blog posts are actively posting about it. Or simply if the volume of searches on a topic increases. When Google concludes it is the topic you want to get the freshest information on, it then rewards up-to-date content with higher rankings.
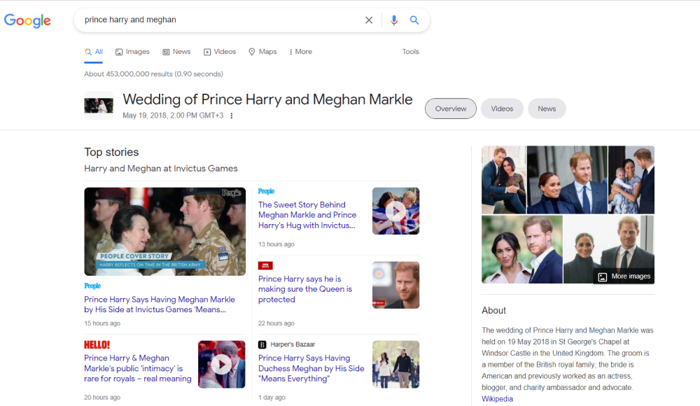
For example, when you search for “prince harry and meghan”, you probably expect to see some news about them. So, Google shows Top Stories with the latest news about the couple at the top of the SERP.
Along with QDF check, Google examines your query to see if it is the one for which Google considers unacceptable to return unreliable content. Such queries and pages are called Your Money or Your Life (YMYL). As a rule, these are health, safety, financial, etc., topics.
It's become possible to distinguish Your Money or Your Life queries and match them to the right content with the Medic update. Now, in YMYL SEO, you have to take into account the expertise, authoritativeness, and trustworthiness (E-A-T) of the relevant pages, their creators, and the websites in general, as these are the signals Google evaluates. Pages with a higher E-A-T score will be eventually ranked higher.
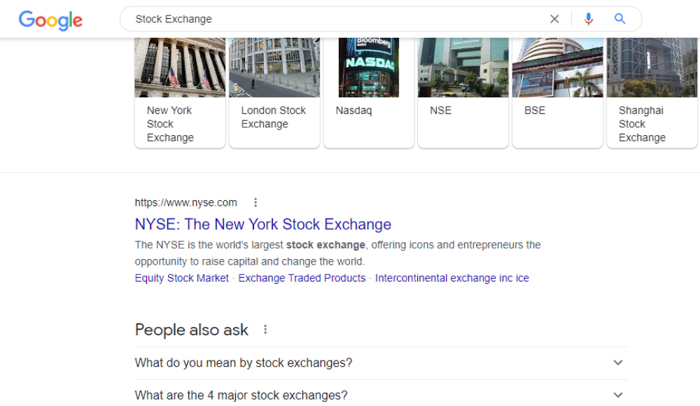
For example, if you search for “stock exchange”, the first SERP will mainly consist of highly trusted pages like Nasdaq, London Stock Exchange, New York Stock Exchange, etc.
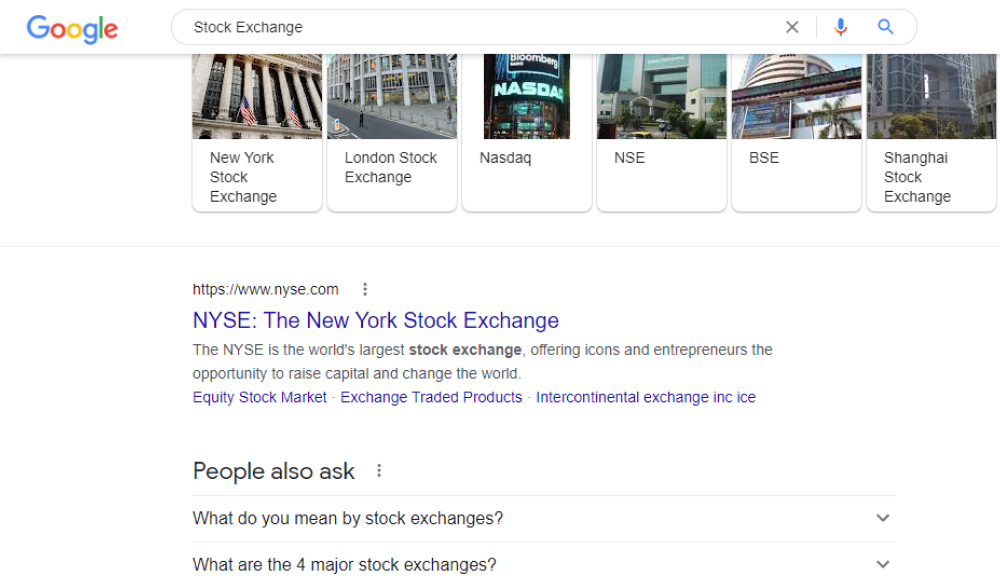
Depending on the type of query you enter, SERP may look different. For example, along with ten blue links, it may show a bunch of ads, Knowledge Graph results, a map, and so on.
So, before Google returns its final SERP, it decides what type of search results will be the most suitable. As practice shows, the SERP structure highly depends on search intent:
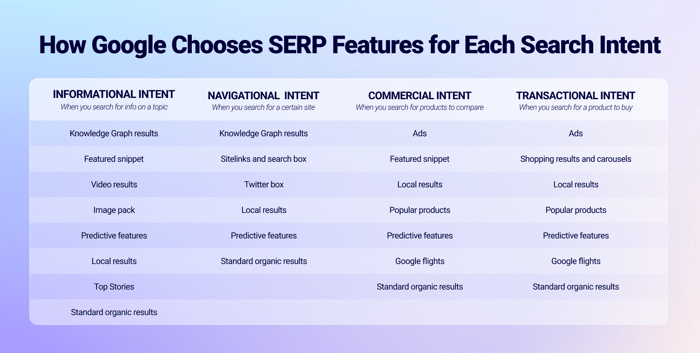

There is also a noticeable difference between how Google chooses what SERP features to show for mobile and desktop search.
For example, mobile SERP possesses the following unique features: Broaden this search and Refine this search (Predictive features), Knowledge Panel with the View in 3D feature, Short Videos, and Web Stories.
Meanwhile, there are some features that are shown more often on desktops, e.g., ads and featured snippets. Here is an example of how different the first SERP for the same query may look like:
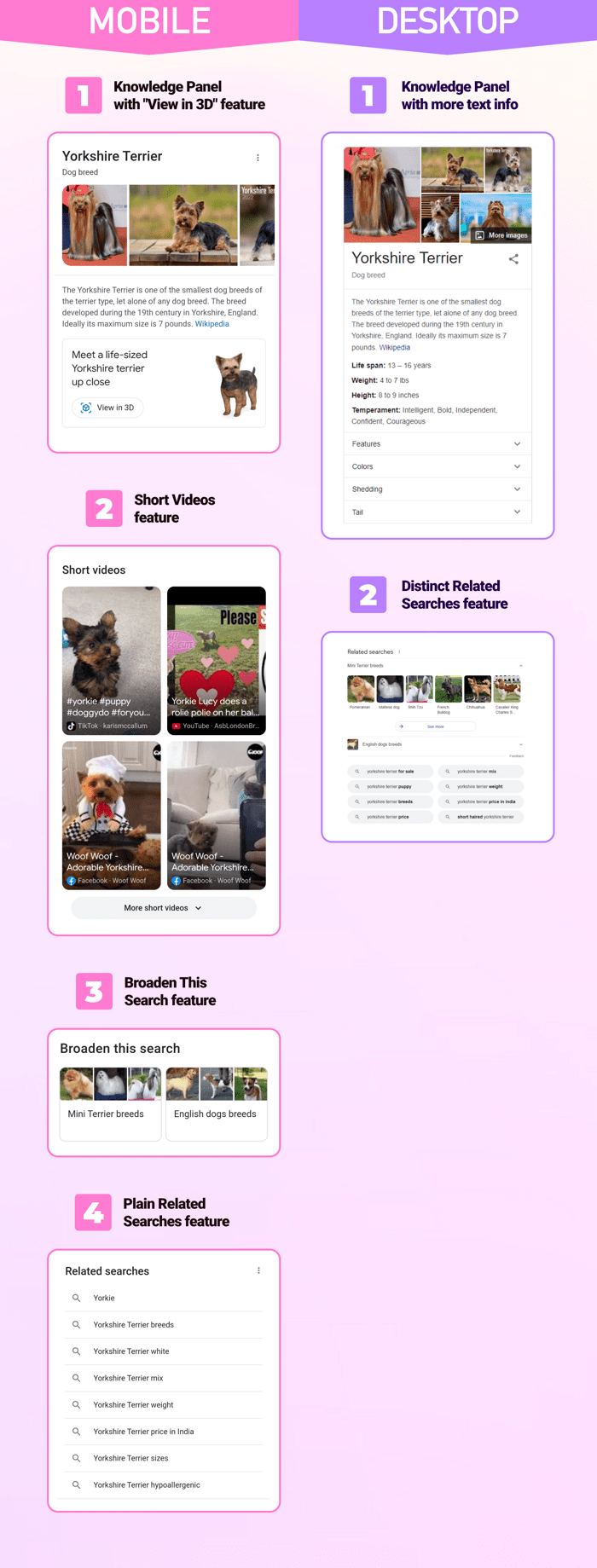
The logic behind such a difference lies in the way we use these two types of devices. While at the desktop, we have more time to study text content. When we use our phones, on the contrary, we expect to find the information as quickly as possible. So, Google “equips” the SERP with more predictive and visual features.
After Google grasps the concepts in the query and pages, it looks at how well the information on a website corresponds to the search query. To assess the content relevance, Google analyzes text, images and videos, as well as all the meta elements like title, meta description and alt tags.
Those pages that are more relevant, i.e. meet user requirements best, will be ranked higher. That said, you should remember that content relevance, though vital, is not the only ranking factor. It’s the combination of many factors that can guarantee high positions on the SERP.
Google ranks pages prioritizing the most reliable and quality content. In fact, it tries to achieve the right balance of information relevance and authoritativeness at this stage.
The first thing Google does for this purpose is assess the quality of the page’s content. So, it identifies the signals that demonstrate expertise, authoritativeness, and trustworthiness on a given topic. This process includes the following:
And as Google places user experience above all, it also checks if the page is easy to navigate and use – the page’s usability. The process is also rather complicated and includes the following:
Obviously, pages that provide both quality and usability tend to rank higher in search results.
When your query is analyzed from all angles, and the AI algorithms have done their job, Google finally returns the most relevant search results. Just look at the image below – this whole process takes a fraction of a second.
Fun fact #1: The amount of time you've spent on reading this guide up to this point would suffice for Google to process 38 million queries.
Fun fact #2: You may think that you've just figured the Google algorithm out. But it's too early to break out the champagne – the algorithm can change tomorrow.
Google can't change specific search results manually to make search better. Instead, it constantly changes and adapts its algorithms. For example, in 2020, Google introduced around 4 500 improvements to Search. On average, it's around 12 changes per day – we can say Google is a real hard worker.
I tried to break down Google's efforts in this regard below.
For Google, fighting spam is a pain in the neck. In 2020 alone, Google claimed they were finding around 40 billion spammy pages daily.
From Google’s perspective, anything that deceives users and goes against Google Quality Guidelines is considered spam. These are:
In fact, spam fighting is a multistep process, which involves both Google AI algorithms and manual review by the spam removal team.
A huge portion of spam webpages is filtered out between the crawling and indexing stage. The remainder that slips through is caught by the filters later during the ranking and serving stage.
Despite the perfection of current anti-spam algorithms, some webpages still make it to SERPs. This is when Google’s spam removal team comes into play. They review spam reports submitted by searchers and take manual actions against the sites that violate Google. As a result, spammy websites get downranked or even excluded from search results.
In the unlikely event you receive a manual action from Google, don’t panic. First, you’ll see a corresponding notification in your Search Console. Then, it’s crucial to eliminate all the issues that might have led to this. Once everything is fixed, your site is likely to get rankings back.
Naturally, it’s impossible to perfect search without tests and experiments. Each new idea that comes to Google minds is tested rigorously before it’s launched.
Thus, to improve search quality, Google works with Search Quality Raters – a group of independent reviewers from all over the world. The raters assess how efficient the search is and if the provided search results are satisfying the search intent of a user. Additionally, they evaluate the quality of search results based on the Expertise, Authoritativeness and Trustworthiness of the content. What’s important, they do all that strictly following Quality Rating Guidelines.
Besides search quality tests, Google also runs side-by-side experiments, again with the help of Quality Raters. Google shows Raters two different sets of search results: one with the proposed change and one without. Then they ask Raters which results they prefer and why.
The ratings provided by Quality Raters don’t directly impact the rankings of a page. Instead, this information is taken in aggregate to help Google measure how well their search algorithms perform.
More to that, Google runs live traffic experiments to see how real people interact with a feature under test. It enables the feature for a small group of users and then compares the results with a control group. If the result isn’t satisfying enough, the feature isn’t approved for further integration.
To complete the picture, let’s dive into the latest Google updates.
Google updates can be basically divided into two groups.
The first group is the minor updates. As a rule, they go unnoticed by searchers, and result in mild ranking fluctuations for SEOs. Google typically doesn’t provide any details on such changes.
The second group includes Google’s major (core) algorithm updates, which are of particular interest because sometimes they significantly change the game for both users and SEOs. Below, I’ve put together some of the most prominent updates for the last 7 years.
Google Search algorithm will always be surrounded by mystery, no matter how hard the global SEO community tries to hack it. The reason is that Google wants to prevent any manipulation of search results from third parties and therefore discloses just a fraction of how it really works.
I hope that my article lifted the shroud of secrecy and helped you understand some basics of how Google and its algorithm work. If you have any questions, welcome to the comments.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

