37355
•
12-minute read
•


Indexing issues may render your SEO efforts null — a page may be perfectly optimized and have a great UX, but it is worth nothing if Google doesn’t see it. Unindexed pages will not get into SERPs and will not bring traffic and conversions.
Vice versa, if Google occasionally sees and indexes a page that was not meant to be indexed, then you’re at risk of private information leakage, Google penalties for low-quality content, and other hardly satisfying consequences.
In this guide, I’m going to share what kinds of indexing issues exist and how to fix them so that they won't cause sudden ranking drops. But first, let’s see how to check if you have any indexing issues on your website.
Google Search Console can give you a basic but still sufficient understanding of what indexing issues your site has. Consult the Index > Pages report to see them.
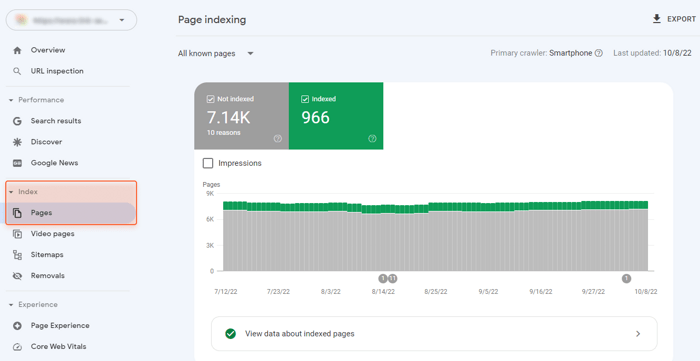
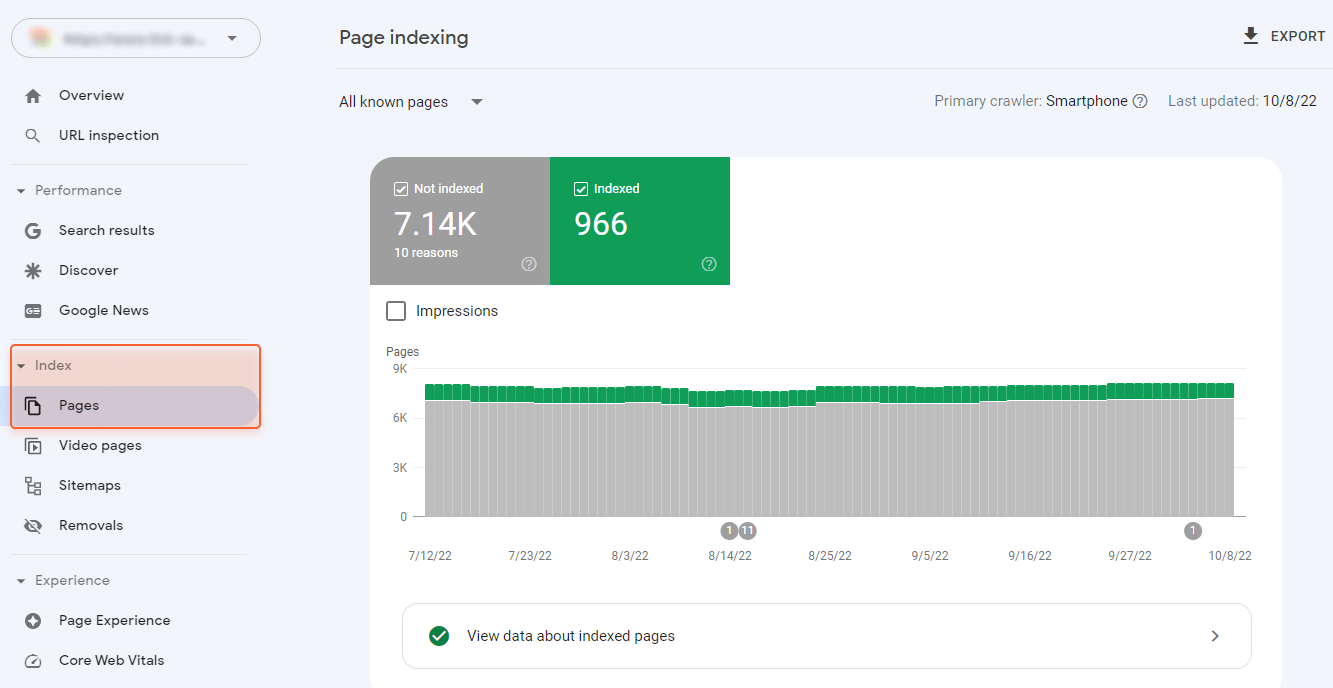
Pages not indexed for no matter what reason are placed under one section, Not Indexed. Pages that have been indexed but still have any issues and require your attention can be found at the bottom of the page in the Improve page appearance section:
To further investigate any issue, click the error line and then the lens icon near the URL you want to check:
Search Console will show you the details and help identify what’s wrong with the page.
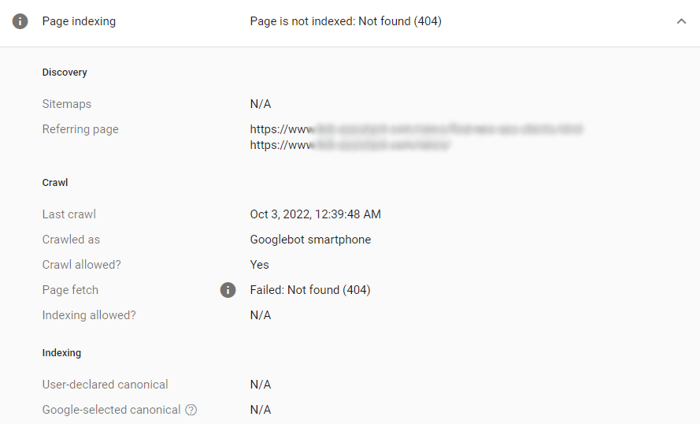
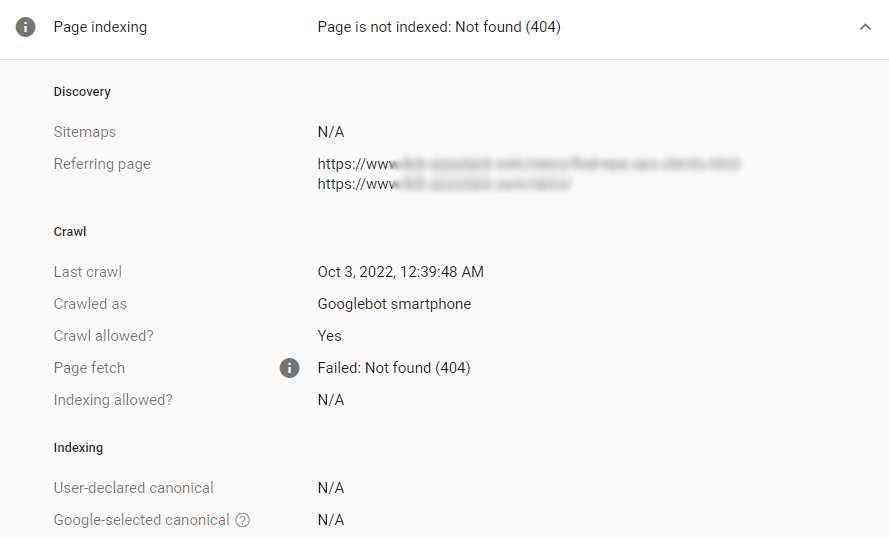
Once you need to dig deeper and get recommendations on what to fix to make a page sound, consult WebSite Auditor’s Indexing and crawlability section:
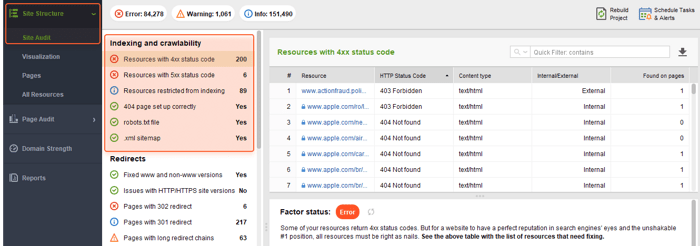
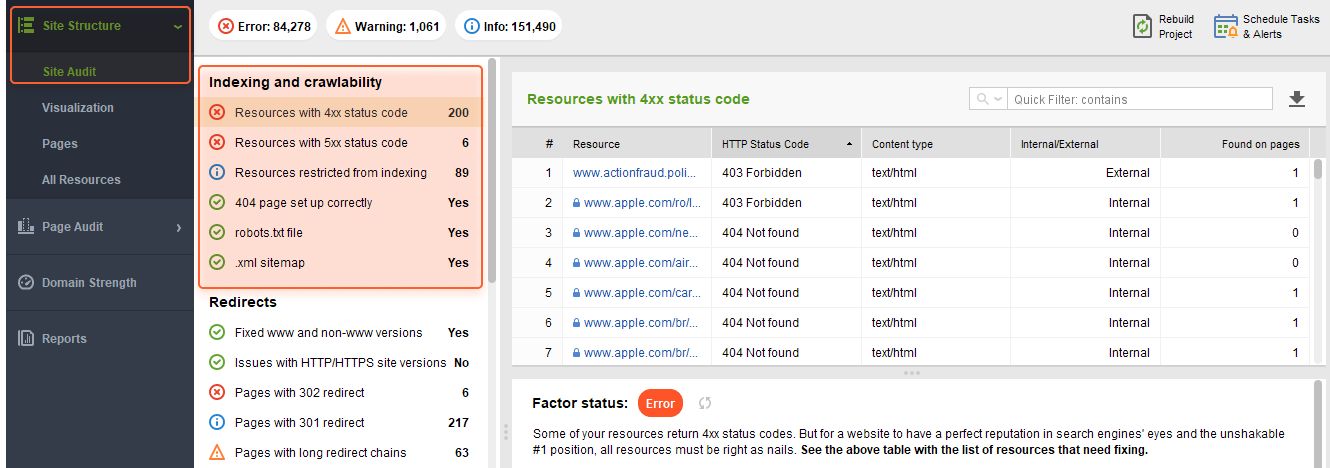
The tool will collect all URLs with errors so you will not need to manually check each page separately.
Well, now we’re done with the “where to find” part. Now it’s time to look at what types of indexing issues you can find and how to fix them to keep your website crawled and indexed.
Not found (404), or a broken URL, is probably one of the most common indexing issues. A page may have a 404 status code for many reasons. Say, you have deleted the URL but did not remove the page from the sitemap, written the URL incorrectly, etc.
As Google says, 404s themselves do not harm your site performance until these are submitted URLs (i.e. those you explicitly asked Google to index).
If you see 404 URLs in your indexing reports, here are possible options for how to fix them if they were not intended to happen:
Note that GSC does not differentiate 404 (not found) from 410 (gone) and puts them together under the 404 report. These used to be different types of response codes: 404 meant ‘not found but could be found later’, while 410 used to stand for ‘not found and will not be as it’s gone for good’.
As for today, Google says they treat both 404 and 410 the same, so you probably do not need to bother if you find a 410 page in the 404 report. The only thing I’d suggest you do is set a custom 404 page instead of an empty 410 in order to save traffic and prevent users from bouncing off your site.
Many SEOs and site owners have a habit to redirect 404s to the homepage, but the truth is that it’s not the best practice. Doing so is confusing for Google and results in soft 404 issues. Well, let’s look at what these soft 404s are.
Soft 404 issues happen when a page has a 200 OK response but Google cannot find its content and considers it a 404. Soft 404s may occur for many reasons, and some of them may not even depend on you, like errors in users’ browsers. Here are some more reasons:
A missing server-side include file
A broken connection to the database
An empty internal search results page
An unloaded or otherwise missing JavaScript file
Too little content
Page cloaking
These issues are actually not that hard to fix. Here are some common scenarios:
If the content has moved, and the page is actually 200 OK but empty, then set up a 301 redirect to the new address;
If the deleted content has no alternative, then mark it as 404 and remove it from the sitemap;
If the page is meant to exist, then add some content and check that all scripts on it are rendered and displayed correctly (not blocked by robots.txt, supported by browsers, etc.);
If the error occurs because the server is down when Googlebot tries to fetch the page, check if the server works fine. If it does, then request this page’s reindexing.
401 error occurs when Googlebot tries to reach a page that requires authorization, and your server blocks Googlebot from doing so.
If you want that page indexed, grant Googlebot the relevant permission, or remove the authorization request.
This type of error happens when the user agent provided credentials to enter the page (login, password), but was not granted access to actually do that. Googlebot, though, never provides credentials, so the server returns 403 instead of the intended page.
If a page has been blocked by mistake and you actually need it indexed, allow access for non-signed-in users, or explicitly allow Googlebot to enter the page to read and index it.
As it’s clear from the name, this error occurs when you explicitly ask Google to index a page (i.e. add it to the sitemap or manually request indexing), but that page has a noindex tag.
The fix is quite simple — remove the noindex tag so that Google can access the page.
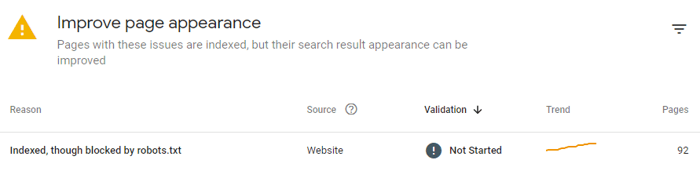
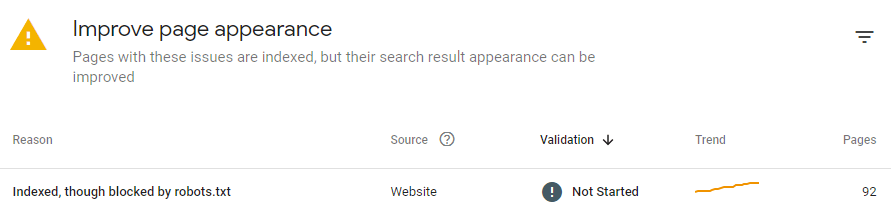
If you block a page with the help of robots.txt, then Google will not crawl it. Remove the restrictions to have the page indexed.
Note: Robots.txt is not a guarantee that the page will not be indexed. That’s why sometimes Google Search Console may show you something like this:
Issues like that may bring you more problems than unindexed pages, as Google may access and reveal the information that was not intended to ever appear in SERPs (like carts, private data, etc.).
If you come across an issue like that, decide whether you need the page indexed or not. If so, remove the URL from the robots.txt file. If not, also remove it from robots.txt but apply the noindex tag, or limit access for non-authorized users. Once you apply new restrictions, you can also ask Google to remove the page from the index through GSC (Index > Removals > New request).
This is another type of issue that can harm your site’s performance worse than unindexed pages. Google doesn’t favor empty pages and will most likely lower your positions, as empty pages are a signal of spammy sites and low-quality content.
If you notice that some of your pages have the Indexed without content status, manually check the URL to find out the reason. For example:
The page may have too little content;
The page may have some render-blocking content, which doesn’t load properly;
The content is cloaked.
Take measures depending on what you see.
For instance, if the page is way too empty, add more content. Here you can check your SERP competitors and follow their best practices with the help of WebSite Auditor’s Content Editor section.
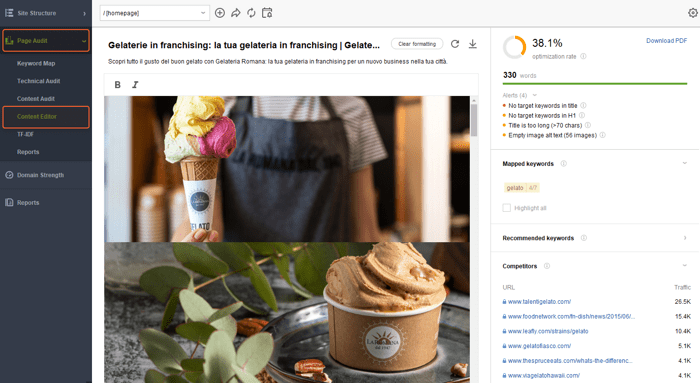
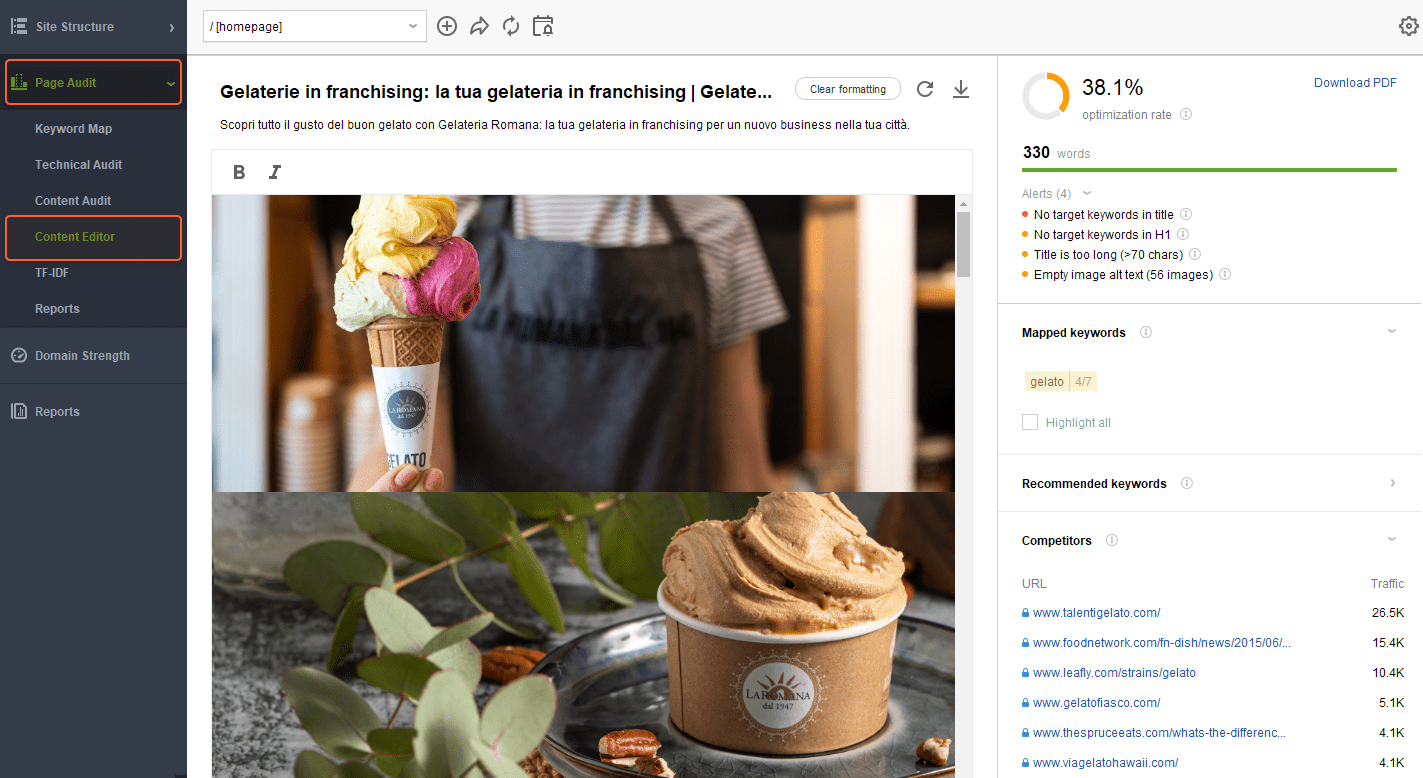
If you suspect there might be some render-blocking content on the affected page, check the pop-ups that utilize third-party scripts and make sure they work correctly and are actually readable by Google. All in all, Google should see your pages’ content the same way users see it.
If your page’s content is cloaked, check that all scripts or images are accessible to Google.
SEO community has spoken a lot about URL redirects. Still, SEOs keep making mistakes that lead to redirect errors and corrupted indexing. Here are some common reasons why Google cannot read redirects correctly:
A redirect chain is too long
A redirect results in an endless loop of redirects (redirect loop)
A redirect URL exceeds the max URL length (2 MB for Google Chrome)
A redirect chain contains a bad or empty URL
The only way to fix redirect errors boils down to one phrase: set up redirects correctly. Avoid long redirect chains that only waste seo crawl budget and drain link juice, make sure there are no 404 or 410 URLs in the chain and always redirect URLs to relevant pages.
Server errors may occur because the server may have crashed, timed out, or been down when Googlebot came around.
The first thing to do here is to check the affected URL. Go to the Inspect URL tool in GSC and see if it still shows an error. If it’s fine, then the only thing you can do is request reindexing.
If there’s still an error, you have the following options depending on the error nature:
Reduce excessive page loading for dynamic page requests
Make sure your site's hosting server is not down, overloaded, or misconfigured
Check that you are not accidentally blocking Google
Control site crawling and indexing wisely
After you have fixed everything, request reindexing to make Google fetch the page faster.
Duplicate without user-selected canonical is a common issue for multi-language and/or ecommerce sites that have many pages with identical or very similar content designed for different purposes. In this case, you should mark one page as canonical to prevent duplicate content issues.
This one is an interesting thing. It may happen that you have indicated a certain page as canonical, but Google decided to choose another version of that page as canonical thus indexing it instead.
The easiest way to fix such errors is to put a canonical tag on the page that was chosen by Google so as not to confuse it in the future. If you want to keep canonical on the page that you chose, you can redirect the page chosen by Google to the URL you need.
Google does not index a page because it is a duplicate of a canonical page. Just leave it as it is.
If a page has the Discovered status, then Google has already discovered it but hasn’t crawled and indexed it yet. The only thing you can do here is to check the page’s indexing instructions in case of any doubts. If it’s all fine (i.e. the way you meant it to be), then let Google do the rest later.
Logically, this description means that Google has crawled your page but hasn’t indexed it. The page will be indexed if indexing instructions do not state the opposite. You needn’t ask for reindexing — Googlebot is aware that the page is waiting its turn to be indexed.
Google Search Console can help you a lot when it comes to spotting and fixing indexing issues. But it would be too good if there were no buts. The thing is that Search Console only shows issues when Google tries to fetch a page and fails for any reason. If such a page is not even discovered by Google, there will be no notion of the indexing issue in GSC. Although the issue may be important, and there may actually be many of them.
WebSite Auditor can help you find and fix issues like that. Go to Site Structure > Pages, and enable the Cache date in Google column in the workspace you need.
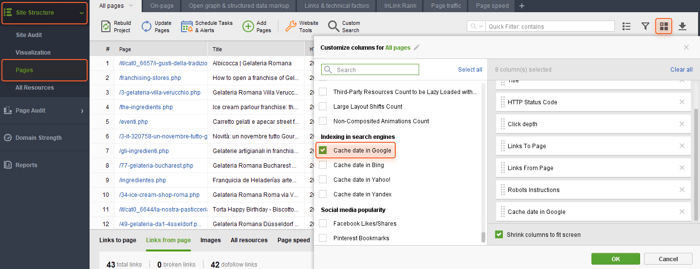
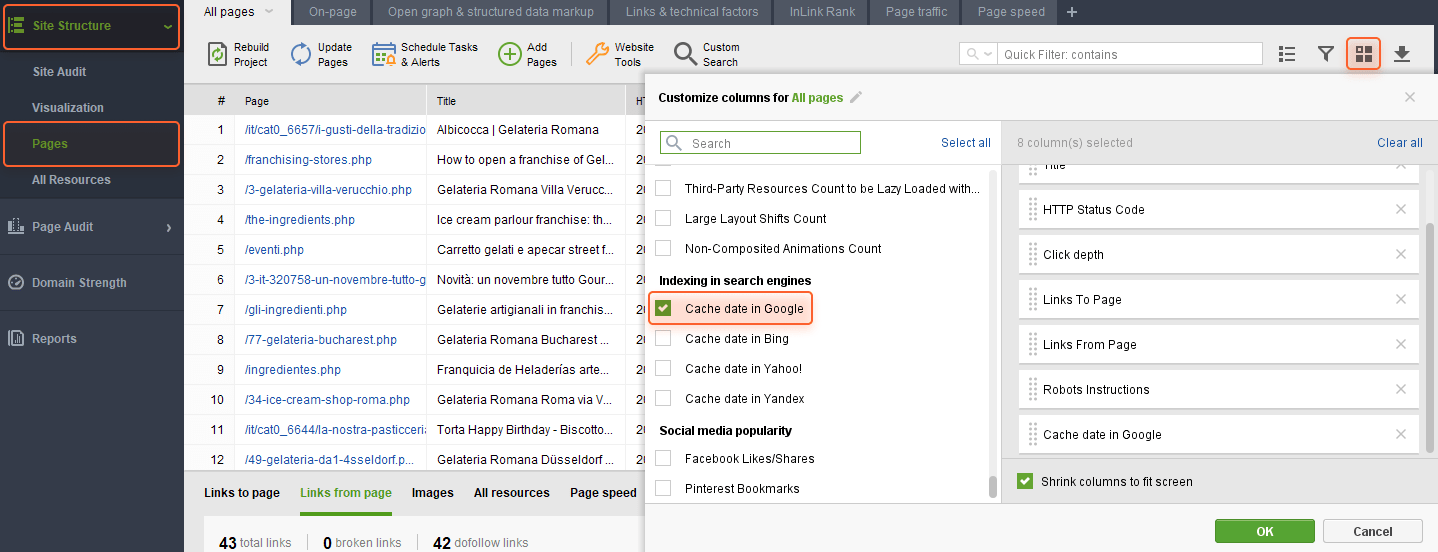
Doing so will let you see the date when a page was cached in Google.
Now have a look at the cache date.
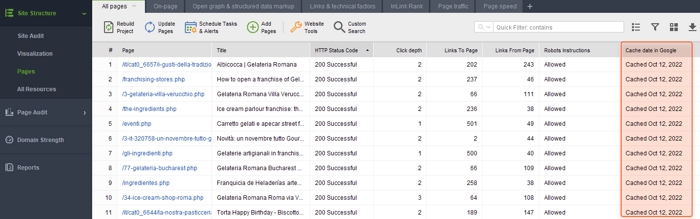
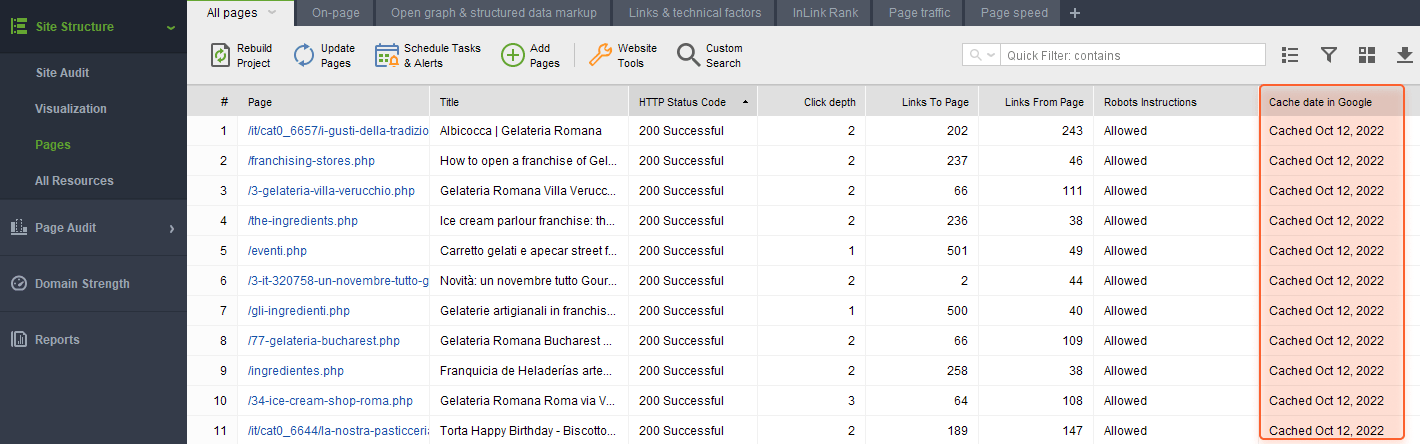
If the date is somewhat too far (more than a year ago) or is missing at all — then Google most likely doesn’t know the page exists. And you have to find out why.
First, have a look at the Links To Page column in the same workspace. If there are no links, this means this is an orphan page and Google cannot find it by crawling your website. If you want the page indexed, then link to it from the relevant and traffic-rich pages.
Also, check the Robots Instructions column and dig deeper into the pages marked as Not allowed. It may be that you have mistakenly blocked the pages meant to be indexed.
Visualization is one more helpful module for finding indexing issues
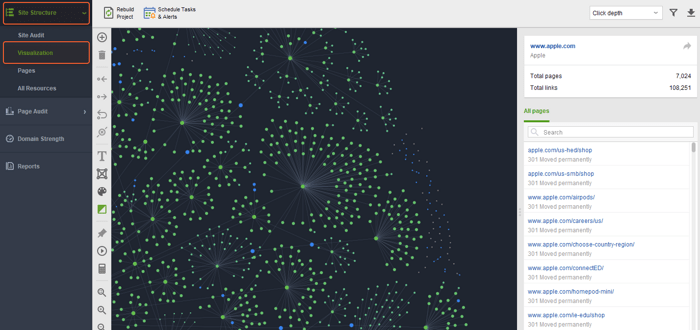
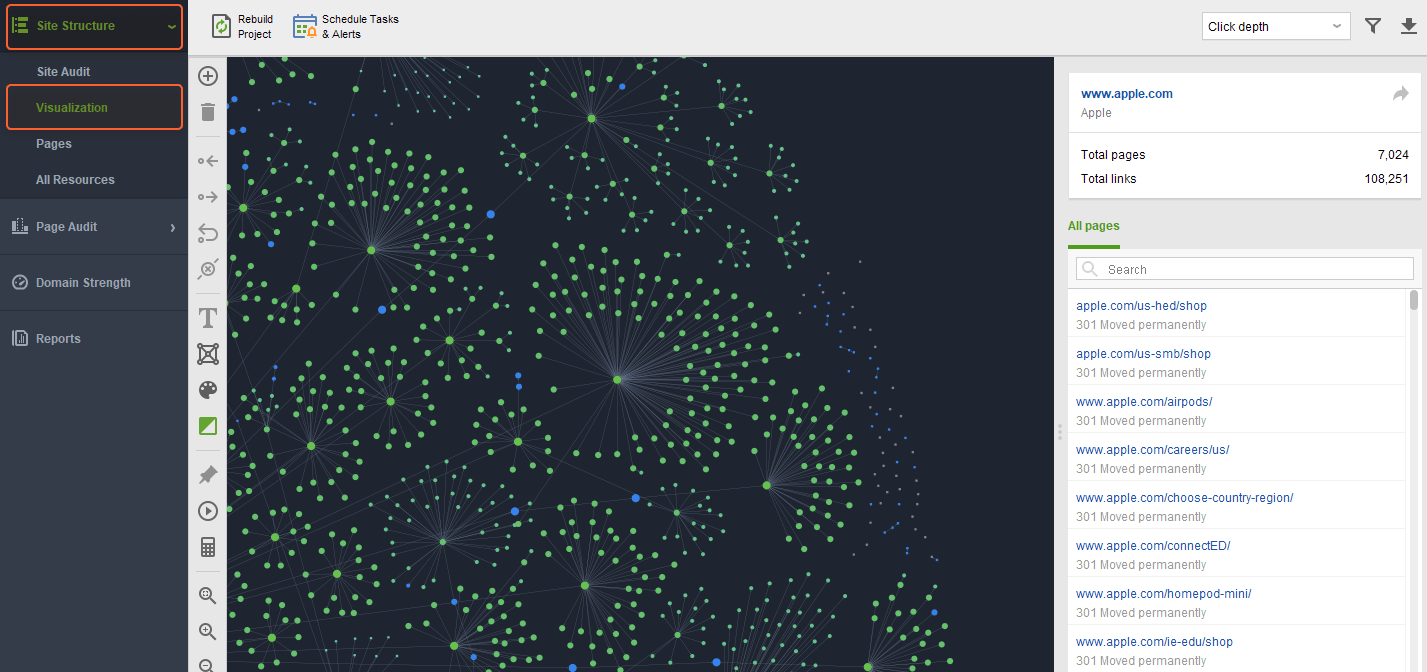
Here you will easily spot orphan pages (those that have no connections to other pages), broken pages (highlighted in red), and long redirect chains, which can also be the reason why some pages are not being indexed.
Once you’ve spotted and fixed all the issues, ask the tool to generate a new sitemap (and a robots.txt file if needed), which will be further sent to Google so it can discover all the pages you need.
If you need fixed URLs to be indexed asap, you can manually request reindexing in Google Search Console.
Regularly audit how your pages are indexed, as errors may occur anytime. And for any reason: from hosting provider issues to Google bugs and Google updates that may impact how Google algorithms treat things.
What are the indexing issues you face most often? Share your experience in our Facebook SEO community.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

