121566
•
Leitura de 20 minutos
•


O algoritmo PageRank (ou PR, para abreviar) é um sistema para classificar páginas da web desenvolvido por Larry Page e Sergey Brin na Universidade de Stanford no final dos anos 90. O PageRank foi na verdade a base sobre a qual Page e Brin criaram o mecanismo de busca Google.
Muitos anos se passaram desde então e, claro, os algoritmos de classificação do Google tornaram-se muito mais complicados. Eles ainda são baseados no PageRank? Como exatamente o PageRank influencia a classificação, poderia ser um dos motivos pela qual sua classificação caiu e para o que os SEOs devem se preparar no futuro? Agora vamos encontrar e resumir todos os fatos e mistérios em torno do PageRank para deixar a imagem mais clara. Bem, tanto quanto pudermos.
Como mencionado acima, no seu projecto de investigação universitária, Brin e Page tentaram inventar um sistema para estimar a autoridade das páginas web. Eles decidiram construir esse sistema com base em links, que serviam como votos de confiança dados a uma página. De acordo com a lógica desse mecanismo, quanto mais recursos externos estiverem vinculados a uma página, mais informações valiosas ela terá para os usuários. E o PageRank (uma pontuação de 0 a 10 calculada com base na quantidade e qualidade dos links recebidos) mostrou a autoridade relativa de uma página na Internet.
Vamos dar uma olhada em como funciona o PageRank. Cada link de uma página (A) para outra (B) dá um chamado voto, cujo peso depende do peso coletivo de todas as páginas vinculadas à página A. E não podemos saber seu peso até calcularmos isso, então o processo ocorre em ciclos.
A fórmula matemática do PageRank original é a seguinte:
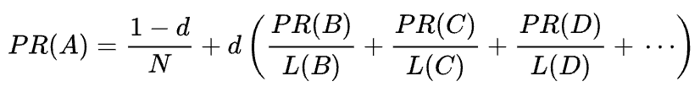
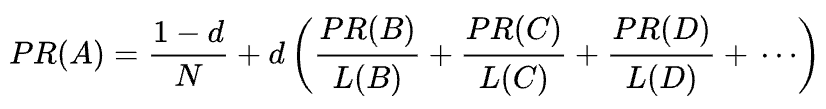
Onde A, B, C e D são algumas páginas, L é o número de links que saem de cada uma delas e N é o número total de páginas na coleção (ou seja, na Internet).
Quanto a d, d é o chamado fator de amortecimento. Considerando que o PageRank é calculado simulando o comportamento de um usuário que chega aleatoriamente a uma página e clica em links, aplicamos esse fator de amortecimento como a probabilidade de o usuário ficar entediado e sair de uma página.
Como você pode ver na fórmula, se não houver páginas apontando para a página, seu PR não será zero, mas
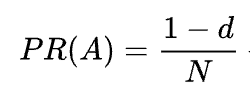
Como existe a probabilidade de o usuário chegar a esta página não a partir de outras páginas, mas, digamos, de marcadores.
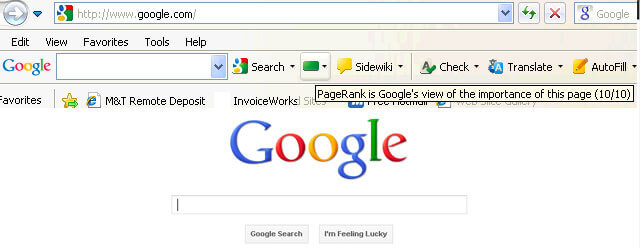
No início, a pontuação do PageRank era publicamente visível na Barra de Ferramentas Google, e cada página tinha sua pontuação de 0 a 10, provavelmente em escala logarítmica.
Os algoritmos de classificação do Google daquela época eram realmente simples - alto PR e densidade de palavras-chave eram as únicas duas coisas que uma página precisava para ter uma classificação elevada em uma SERP. Como resultado, as páginas da web ficaram cheias de palavras-chave e os proprietários de sites começaram a manipular o PageRank aumentando artificialmente backlinks com spam. Isso foi fácil de fazer - link farms e vendas de links estavam lá para dar uma “ajuda” aos proprietários de sites.
O Google decidiu combater o spam de links. Em 2003, o Google penalizou o site da empresa de rede de anúncios SearchKing por manipulação de links. SearchKing processou o Google, mas o Google venceu. Foi uma forma que o Google tentou impedir que todos manipulassem links, mas não deu em nada. As fazendas de links simplesmente passaram à clandestinidade e sua quantidade se multiplicou enormemente.
Além disso, os comentários com spam em blogs também se multiplicaram. Os bots atacaram os comentários de qualquer, digamos, blog WordPress e deixaram um enorme número de comentários do tipo “clique aqui para comprar pílulas mágicas”. Para evitar spam e manipulação de relações públicas nos comentários, o Google introduziu a tag nofollow em 2005. E mais uma vez, o que o Google pretendia ser um passo bem-sucedido na guerra de manipulação de links foi implementado de forma distorcida. As pessoas começaram a usar tags nofollow para canalizar artificialmente o PageRank para as páginas de que precisavam. Essa tática ficou conhecida como escultura de PageRank.
Para evitar a escultura de relações públicas, o Google mudou a forma como o PageRank flui. Anteriormente, se uma página tivesse links nofollow e dofollow, todo o volume de PR da página era passado para outras páginas vinculadas aos links dofollow. Em 2009, o Google começou a dividir o PR de uma página igualmente entre todos os links que a página tinha, mas repassando apenas os compartilhamentos que eram dados aos links dofollow.


Feito a escultura do PageRank, o Google não interrompeu a guerra de spam de links e, conseqüentemente, começou a tirar a pontuação do PageRank dos olhos do público. Primeiro, o Google lançou o novo navegador Chrome sem a Barra de Ferramentas Google, onde a pontuação de PR era mostrada. Então eles pararam de reportar a pontuação de PR no Google Search Console. Então o navegador Firefox parou de oferecer suporte à Barra de Ferramentas Google. Em 2013, o PageRank foi atualizado para o Internet Explorer pela última vez e, em 2016, o Google encerrou oficialmente a Barra de Ferramentas para o público.


Mais uma maneira que o Google usou para combater esquemas de links foi a atualização do Penguin, que desclassificou sites com perfis de backlinks duvidosos. Lançado em 2012, o Penguin não se tornou parte do algoritmo de tempo real do Google, mas sim um “filtro” atualizado e reaplicado aos resultados de pesquisa de vez em quando. Se um site fosse penalizado pelo Penguin, os SEOs teriam que revisar cuidadosamente seus perfis de links e remover links tóxicos ou adicioná-los a uma lista de rejeição (um recurso introduzido naquela época para informar ao Google quais links recebidos ignorar ao calcular o PageRank). Depois de auditar os perfis de links dessa forma, os SEOs tiveram que esperar cerca de meio ano até que o algoritmo Penguin recalculasse os dados.
Em 2016, o Google incluiu o Penguin em seu algoritmo de classificação principal. Desde então, ele tem trabalhado em tempo real, lidando com spam de forma algorítmica com muito mais sucesso.
Ao mesmo tempo, o Google trabalhou para facilitar a qualidade e não a quantidade de links, fixando-o em suas diretrizes de qualidade contra esquemas de links.
Bem, terminamos com o passado do PageRank. O que está acontecendo agora?
Em 2019, um ex-funcionário do Google disse que o algoritmo PageRank original não era usado desde 2006 e foi substituído por outro algoritmo menos intensivo em recursos à medida que a Internet crescia. O que pode muito bem ser verdade, já que em 2006 o Google apresentou a nova patente Produzindo uma classificação para páginas usando distâncias em um gráfico de links da web.
É sim. Não é o mesmo PageRank do início dos anos 2000, mas o Google continua confiando fortemente na autoridade do link. Por exemplo, um ex-funcionário do Google, Andrey Lipattsev, mencionou isso em 2016. Em um hangout de perguntas e respostas do Google, um usuário perguntou quais eram os principais sinais de classificação que o Google usava. A resposta de Andrey foi bastante direta.

Posso te dizer quais são. É conteúdo e links que apontam para o seu site.
Em 2020, John Mueller confirmou que mais uma vez:

Sim, usamos o PageRank internamente, entre muitos, muitos outros sinais. Não é exatamente igual ao artigo original, há muitas peculiaridades (por exemplo, links rejeitados, links ignorados etc.) e, novamente, usamos muitos outros sinais que podem ser muito mais fortes.
Como você pode ver, o PageRank ainda está vivo e é usado ativamente pelo Google ao classificar páginas na web.
O interessante é que os funcionários do Google continuam nos lembrando que existem muitos, muitos, MUITOS outros fatores de classificação do Google. Mas olhamos para isso com cautela. Considerando quanto esforço o Google dedicou ao combate ao spam de links, poderia ser do interesse do Google desviar a atenção dos SEOs dos fatores vulneráveis à manipulação (como são os backlinks) e direcionar essa atenção para algo inocente e agradável. Mas como os SEOs são bons em ler nas entrelinhas, eles continuam considerando o PageRank um forte sinal de classificação e aumentam os backlinks de todas as maneiras que podem. Eles ainda usam PBNs, praticam algum link building em camadas, compram links e assim por diante, como era há muito tempo. Enquanto o PageRank existir, o spam de links também existirá. Não recomendamos nada disso, mas a realidade do SEO é essa, e temos que entender isso.
Bem, você entendeu que o PageRank agora não é o PageRank de 20 anos atrás.
Uma das principais modernizações do PR foi passar do modelo Random Surfer brevemente mencionado acima para o modelo Reasonable Surfer em 2012. O Reasonable Surfer pressupõe que os usuários não se comportam de maneira caótica em uma página e clicam apenas nos links nos quais estão interessados. momento. Digamos que, ao ler um artigo de blog, é mais provável que você clique em um link no conteúdo do artigo do que em um link de Termos de Uso no rodapé.
Além disso, o Reasonable Surfer pode potencialmente usar uma grande variedade de outros fatores ao avaliar a atratividade de um link. Todos esses fatores foram revisados cuidadosamente por Bill Slawski em seu artigo, mas eu gostaria de focar nos dois fatores, que os SEOs discutem com mais frequência. Estes são a posição do link e o tráfego da página. O que podemos dizer sobre esses fatores?
Um link pode estar localizado em qualquer lugar da página – em seu conteúdo, menu de navegação, biografia do autor, rodapé e, na verdade, em qualquer elemento estrutural que a página contenha. E diferentes locais de link afetam o valor do link. John Mueller confirmou isso, dizendo que os links colocados no conteúdo principal pesam mais do que todos os outros:
Esta é a área da página onde você tem seu conteúdo principal, o conteúdo do qual esta página realmente trata, não o menu, a barra lateral, o rodapé, o cabeçalho… Então isso é algo que levamos em consideração e tentamos para usar esses links.
Portanto, diz-se que os links de rodapé e os links de navegação passam menos peso. E esse fato de tempos em tempos é confirmado não apenas pelos porta-vozes do Google, mas também por casos da vida real.
Em um caso recente apresentado por Martin Hayman no BrightonSEO, Martin adicionou o link que já tinha em seu menu de navegação ao conteúdo principal das páginas. Como resultado, essas páginas de categoria e as páginas às quais elas vinculavam tiveram um aumento de tráfego de 25%.
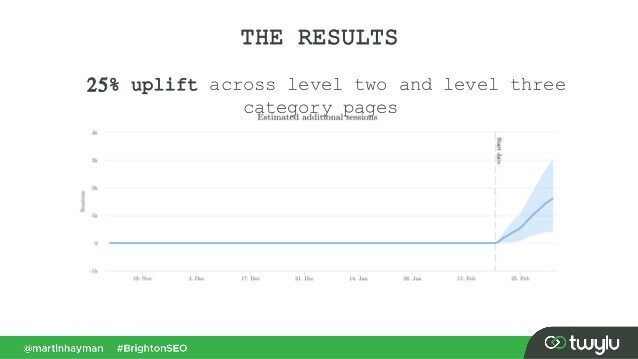
Este experimento prova que os links de conteúdo têm mais peso do que quaisquer outros.
Quanto aos links na biografia do autor, os SEOs presumem que os links biológicos pesam alguma coisa, mas são menos valiosos do que, digamos, links de conteúdo. Embora não tenhamos muitas provas aqui, exceto o que Matt Cutts disse quando o Google estava lutando ativamente contra o excesso de guest blogging por backlinks.
John Mueller esclareceu a maneira como o Google trata o tráfego e o comportamento do usuário em termos de passagem de links em um dos hangouts do Search Console Central. Um usuário perguntou a Mueller se o Google considera a probabilidade de cliques e o número de cliques em links ao avaliar a qualidade de um link. As principais conclusões da resposta de Mueller foram:
O Google não considera cliques em links e probabilidade de cliques ao avaliar a qualidade do link.
O Google entende que os links são frequentemente adicionados ao conteúdo como referências, e não se espera que os usuários cliquem em todos os links que encontrarem.
Ainda assim, como sempre, os SEOs duvidam se vale a pena acreditar cegamente em tudo o que o Google diz e continuam experimentando. Então, o pessoal do Ahrefs fez um estudo para verificar se a posição de uma página em uma SERP está ligada ao número de backlinks que ela possui de páginas de alto tráfego. O estudo revelou que quase não há correlação. Além disso, algumas páginas bem classificadas não tinham nenhum backlink de páginas ricas em tráfego.
Este estudo nos aponta em uma direção semelhante às palavras de John Mueller - você não precisa construir backlinks que gerem tráfego para sua página para obter posições elevadas em uma SERP. Por outro lado, o tráfego extra nunca prejudicou nenhum site. A única mensagem aqui é que backlinks ricos em tráfego não parecem influenciar as classificações do Google.
Como você se lembra, o Google introduziu a tag nofollow em 2005 como uma forma de combater spam de links. Algo mudou hoje? Na verdade sim.
Primeiro, o Google introduziu recentemente mais dois tipos de atributo nofollow. Antes disso, o Google sugeria marcar todos os backlinks que você não deseja que participem do cálculo do PageRank como nofollow, sejam comentários de blogs ou anúncios pagos. Hoje, o Google recomenda usar rel="patrocinado" para links pagos e afiliados e rel="ugc" para conteúdo gerado pelo usuário.

É interessante que essas novas tags não sejam obrigatórias (pelo menos ainda não), e o Google ressalta que você não precisa alterar manualmente todos os rel=”nofollow” para rel="born" e rel=”ugc”. Esses dois novos atributos agora funcionam da mesma maneira que uma tag nofollow comum.
Em segundo lugar, o Google agora diz que as tags nofollow, bem como as novas, patrocinadas e ugc, são tratadas como dicas, em vez de uma diretiva ao indexar páginas.
Além dos links de entrada, também existem links de saída, ou seja, links que apontam para outras páginas da sua.
Muitos SEOs acreditam que os links de saída podem impactar as classificações, mas essa suposição tem sido tratada como um mito do SEO. Mas há um estudo interessante para dar uma olhada a esse respeito.
A Reboot Online realizou um experimento em 2015 e o executou novamente em 2020. Eles queriam descobrir se a presença de links de saída para páginas de alta autoridade influenciava a posição da página em uma SERP. Eles criaram 10 sites com artigos de 300 palavras, todos otimizados para uma palavra-chave inexistente – Phylandocic. 5 sites ficaram sem nenhum link de saída e 5 sites continham links de saída para recursos de alta autoridade. Como resultado, os sites com links de saída confiáveis começaram a ter a classificação mais alta, e aqueles que não tinham nenhum link ocuparam as posições mais baixas.

Por um lado, os resultados desta pesquisa podem nos dizer que os links de saída influenciam as posições das páginas. Por outro lado, o termo de busca na pesquisa é totalmente novo e o conteúdo dos sites tem como tema remédios e drogas. Portanto, há grandes chances de a consulta ter sido classificada como YMYL. E o Google afirmou muitas vezes a importância do EAT para os sites YMYL. Portanto, os outlinks podem muito bem ter sido tratados como um sinal EAT, provando que as páginas têm conteúdo factualmente preciso.
Quanto às consultas comuns (não YMYL), John Mueller disse muitas vezes que você não precisa ter medo de criar links para fontes externas de seu conteúdo, pois os links de saída são bons para seus usuários.
Além disso, os links de saída também podem ser benéficos para o SEO, pois podem ser levados em consideração pela IA do Google ao filtrar spam na web. Porque páginas com spam tendem a ter poucos links de saída, se é que têm algum. Eles possuem links para páginas do mesmo domínio (se pensarem em SEO) ou contêm apenas links pagos. Portanto, se você criar links para alguns recursos confiáveis, você meio que mostra ao Google que sua página não contém spam.
Houve uma vez uma opinião de que o Google poderia aplicar uma penalidade manual por ter muitos links de saída, mas John Mueller disse que isso só é possível quando os links de saída fazem obviamente parte de algum esquema de troca de links, e o site é em geral de má qualidade. O que o Google quer dizer com óbvio é na verdade um mistério, portanto, tenha em mente o bom senso, o conteúdo de alta qualidade e o SEO básico.
Enquanto o PageRank existir, os SEOs procurarão novas maneiras de manipulá-lo.
Em 2012, era mais provável que o Google liberasse ações manuais para manipulação de links e spam. Mas agora, com seus algoritmos anti-spam bem treinados, o Google é capaz de simplesmente ignorar certos links com spam ao calcular o PageRank, em vez de rebaixar todo o site em geral. Como disse John Mueller,
Links aleatórios coletados ao longo dos anos não são necessariamente prejudiciais, nós os vemos há muito tempo também e podemos ignorar todos aqueles estranhos grafites da web de muito tempo atrás.
Isso também se aplica ao SEO negativo quando seu perfil de backlink é comprometido por seus concorrentes:
Em geral, levamos isso automaticamente em consideração e tentamos… ignorá-los automaticamente quando os vemos acontecendo. Na maior parte, suspeito que funcione bastante bem. Vejo muito poucas pessoas com problemas reais em torno disso. Então, acho que está funcionando bem. No que diz respeito à rejeição desses links, suspeito que se forem apenas links normais de spam que estão aparecendo no seu site, então eu não me preocuparia muito com eles. Provavelmente descobrimos isso sozinhos.
No entanto, isso não significa que você não tenha nada com que se preocupar. Se os backlinks do seu site forem ignorados com muita frequência, você ainda terá uma grande chance de obter uma ação manual. Como diz Marie Haynes em seu conselho sobre gerenciamento de links em 2021:

As ações manuais são reservadas para casos em que um site decente possui links artificiais apontando para ele em uma escala tão grande que os algoritmos do Google não se sentem confortáveis em ignorá-los.
Para tentar descobrir quais links estão causando o problema, leia este guia sobre como verificar a qualidade do backlink. Resumindo, você pode usar um verificador de backlinks como o SEO SpyGlass. Na ferramenta, vá para Perfil de backlink > seção Risco de penalidade. Preste atenção aos backlinks de alto e médio risco.
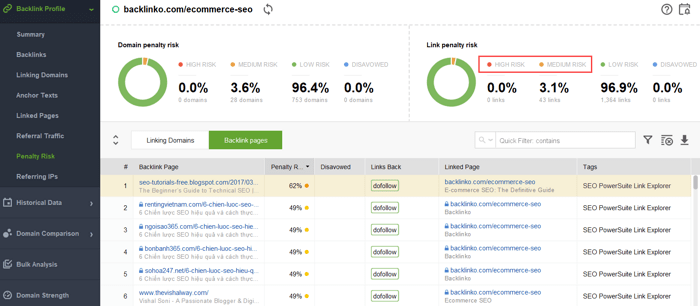
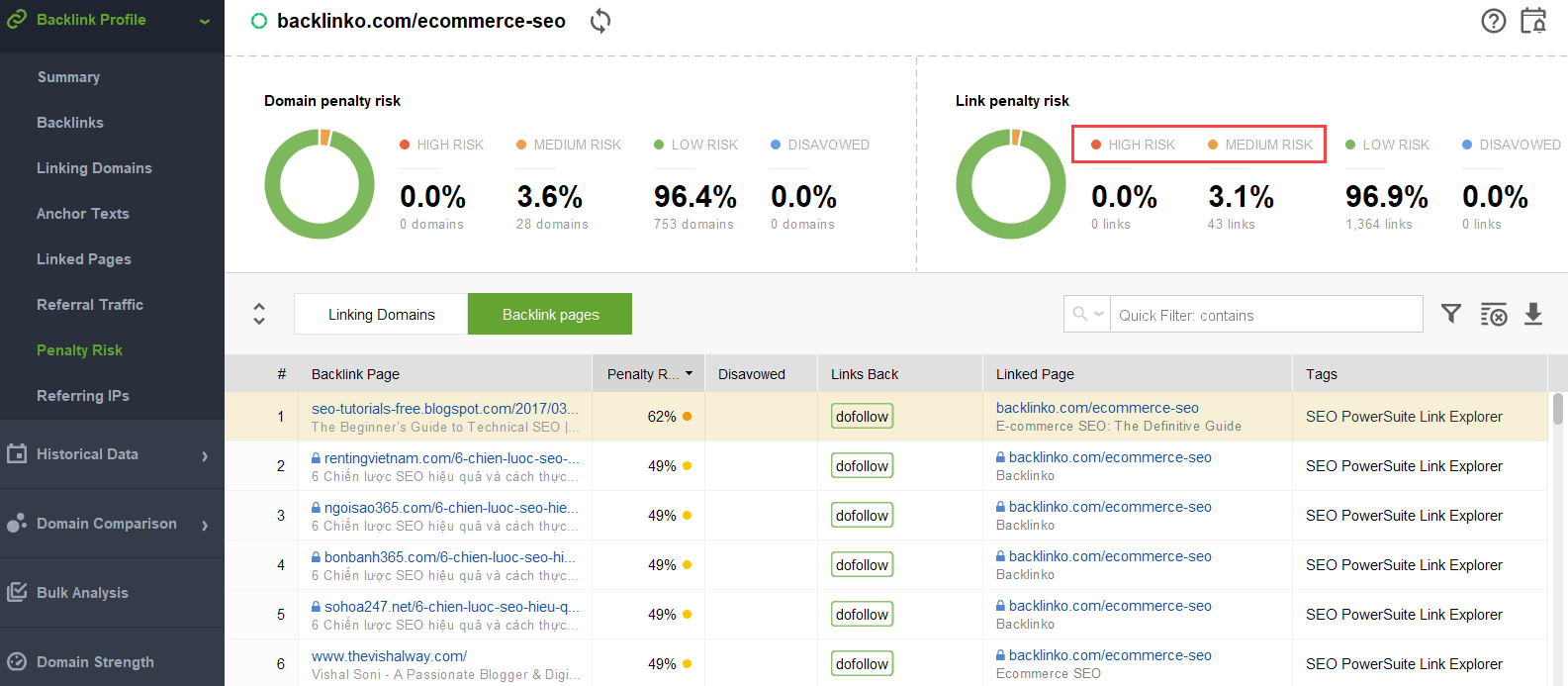
Para investigar melhor por que este ou aquele link é relatado como prejudicial, clique no sinal i na coluna Risco de penalidade. Aqui você verá por que a ferramenta considerou o link ruim e decidirá se rejeitaria um link ou não.
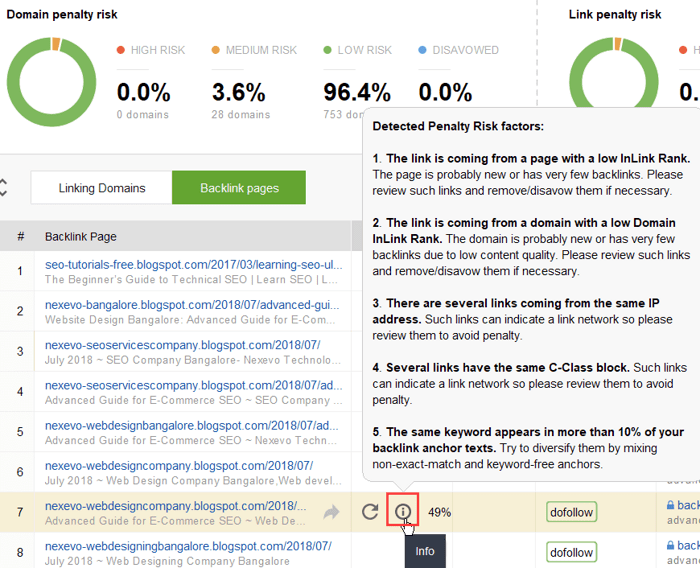
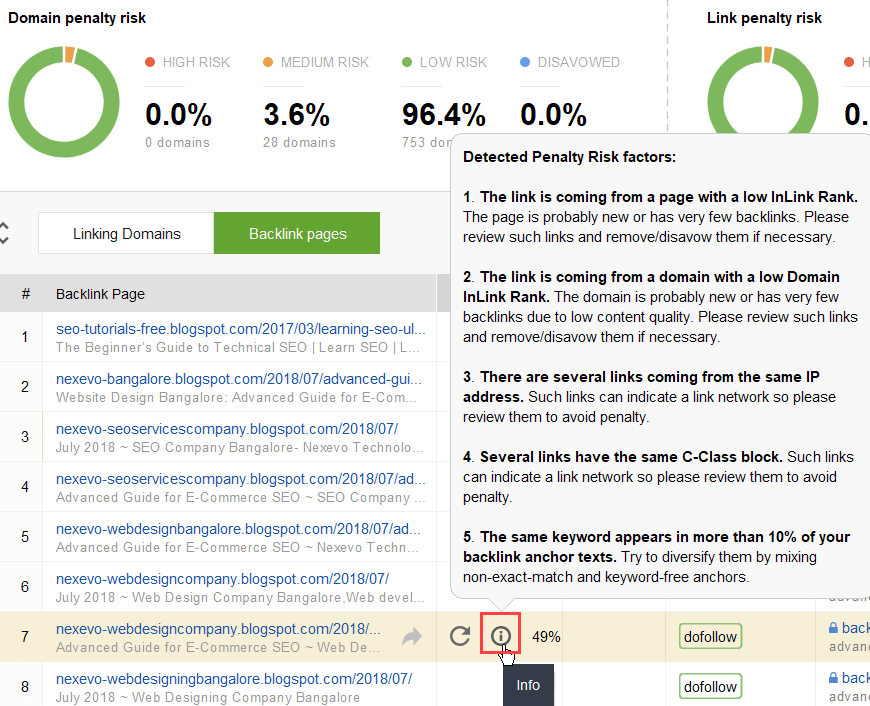
Se você decidir rejeitar um link de um grupo de links, clique com o botão direito neles e escolha a opção Rejeitar backlink(s):
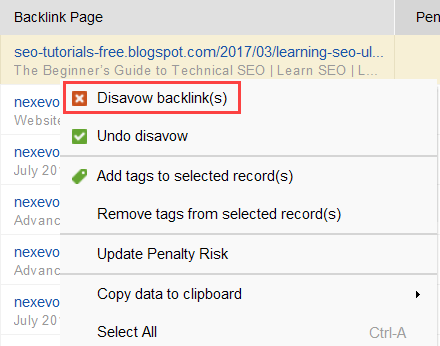
Depois de formar uma lista de links a serem excluídos, você pode exportar o arquivo rejeitado do SEO SpyGlass e enviá-lo ao Google via GSC.
Falando em PageRank, não podemos deixar de mencionar os links internos. O PageRank recebido é algo que não podemos controlar, mas podemos controlar totalmente a forma como as relações públicas são espalhadas pelas páginas do nosso site.
O Google também afirmou muitas vezes a importância dos links internos. John Mueller sublinhou isso mais uma vez em um dos últimos hangouts do Search Console Central. Um usuário perguntou como tornar algumas páginas da web mais poderosas. E John Mueller disse o seguinte:
...Você pode ajudar com links internos. Assim, dentro do seu site, você pode realmente destacar as páginas que deseja que sejam mais destacadas e ter certeza de que elas estão realmente bem vinculadas internamente. E talvez as páginas que você não acha tão importantes, certifique-se de que elas estejam um pouco menos vinculadas internamente.
Links internos significam muito. Ele ajuda você a compartilhar o PageRank recebido entre diferentes páginas do seu site, fortalecendo assim as páginas com baixo desempenho e tornando o seu site mais forte em geral.
Quanto às abordagens de links internos, os SEOs têm muitas teorias diferentes. Uma abordagem popular está relacionada à profundidade de cliques no site. Essa ideia diz que todas as páginas do seu site devem estar a uma distância máxima de 3 cliques da página inicial. Embora o Google também tenha sublinhado muitas vezes a importância da estrutura superficial do site, na realidade isso parece inacessível para todos os sites maiores que os pequenos.
Mais uma abordagem baseia-se no conceito de ligação interna centralizada e descentralizada. Como Kevin Indig descreve:

Sites centralizados têm um único fluxo de usuário e funil que aponta para uma página principal. Sites com links internos descentralizados possuem vários pontos de contato de conversão ou diferentes formatos de inscrição.
No caso de links internos centralizados, temos um pequeno grupo de páginas de conversão ou uma página, que queremos que seja poderosa. Se aplicarmos links internos descentralizados, queremos que todas as páginas do site sejam igualmente poderosas e tenham PageRank igual para que todas sejam classificadas para suas consultas.
Qual opção é melhor? Tudo depende das peculiaridades do seu site e do nicho de negócios e das palavras-chave que você vai segmentar. Por exemplo, links internos centralizados são mais adequados para palavras-chave com volumes de pesquisa altos e médios, pois resultam em um conjunto restrito de páginas superpoderosas.
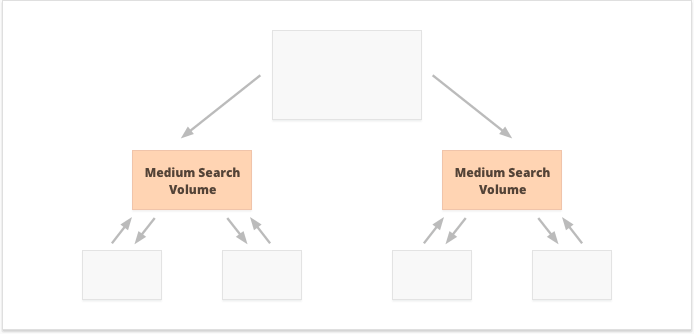
Palavras-chave de cauda longa com baixo volume de pesquisa, por outro lado, são melhores para links internos descentralizados, pois espalham as relações públicas igualmente entre várias páginas do site.
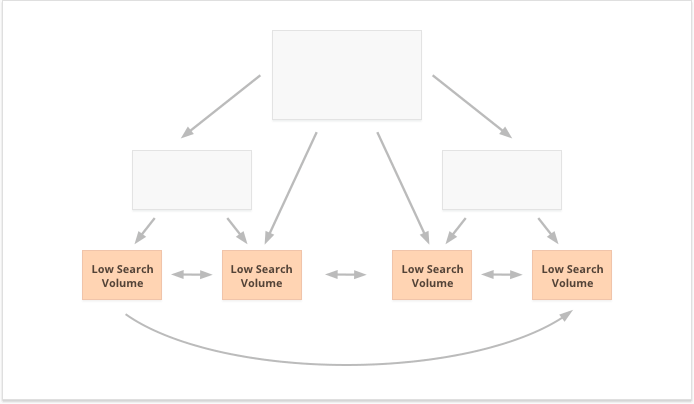
Mais um aspecto da vinculação interna bem-sucedida é o equilíbrio dos links de entrada e saída na página. Nesse sentido, muitos SEOs usam CheiRank (CR), que na verdade é um PageRank inverso. Mas enquanto o PageRank é o poder recebido, o CheiRank é o poder do link distribuído. Depois de calcular PR e CR para suas páginas, você pode ver quais páginas apresentam anomalias de link, ou seja, os casos em que uma página recebe muito PageRank, mas passa um pouco mais longe e vice-versa.
Um experimento interessante aqui é o nivelamento de anomalias de link de Kevin Indig. O simples fato de garantir que o PageRank de entrada e saída esteja equilibrado em todas as páginas do site trouxe resultados impressionantes. A seta vermelha aqui aponta para o momento em que as anomalias foram corrigidas:
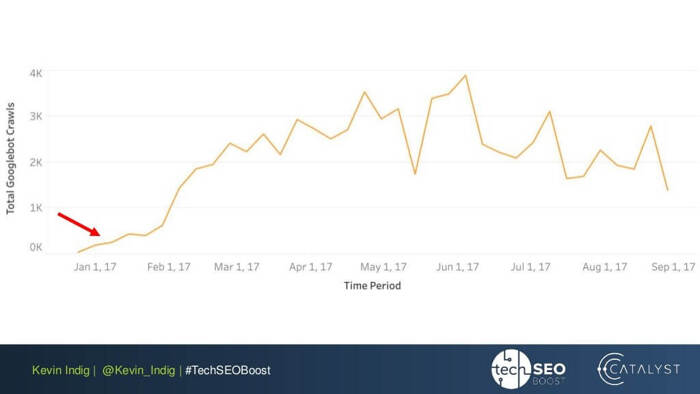
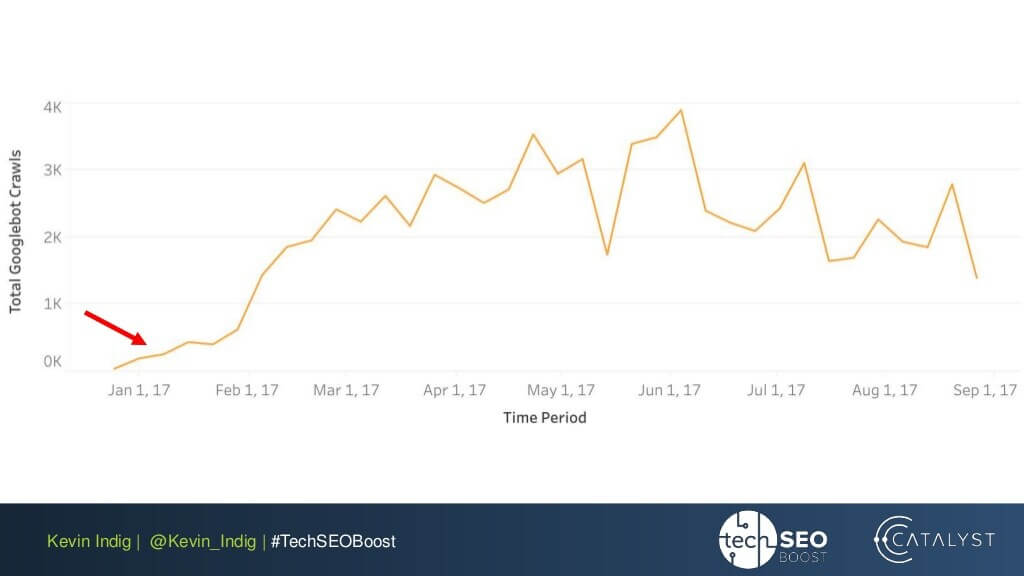
Anomalias de link não são a única coisa que pode prejudicar o fluxo do PageRank. Certifique-se de não ficar preso a nenhum problema técnico, que pode destruir seu PR conquistado com tanto esforço:
Páginas órfãs. As páginas órfãs não estão vinculadas a nenhuma outra página do seu site, portanto, ficam ociosas e não recebem nenhum link juice. O Google não consegue vê-los e não sabe que eles realmente existem.
Redirecionar cadeias. Embora o Google diga que os redirecionamentos agora ultrapassam 100% do PR, ainda é recomendado evitar longas cadeias de redirecionamento. Primeiro, eles consomem seu orçamento de rastreamento de qualquer maneira. Em segundo lugar, sabemos que não podemos acreditar cegamente em tudo o que o Google diz.
Links em JavaScript não analisável. Como o Google não pode lê-los, eles não passarão no PageRank.
404 ligações. Links 404 não levam a lugar nenhum, então o PageRank também não leva a lugar nenhum.
Links para páginas sem importância. Claro, você não pode deixar nenhuma de suas páginas sem nenhum link, mas as páginas não são criadas iguais. Se alguma página for menos importante, não é racional se esforçar muito para otimizar o perfil do link dessa página.
Páginas muito distantes. Se uma página estiver localizada muito profundamente em seu site, é provável que receba pouco ou nenhum PR. Como o Google pode não conseguir encontrá-lo e indexá-lo.
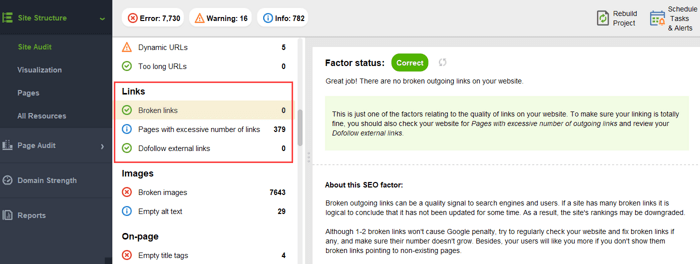
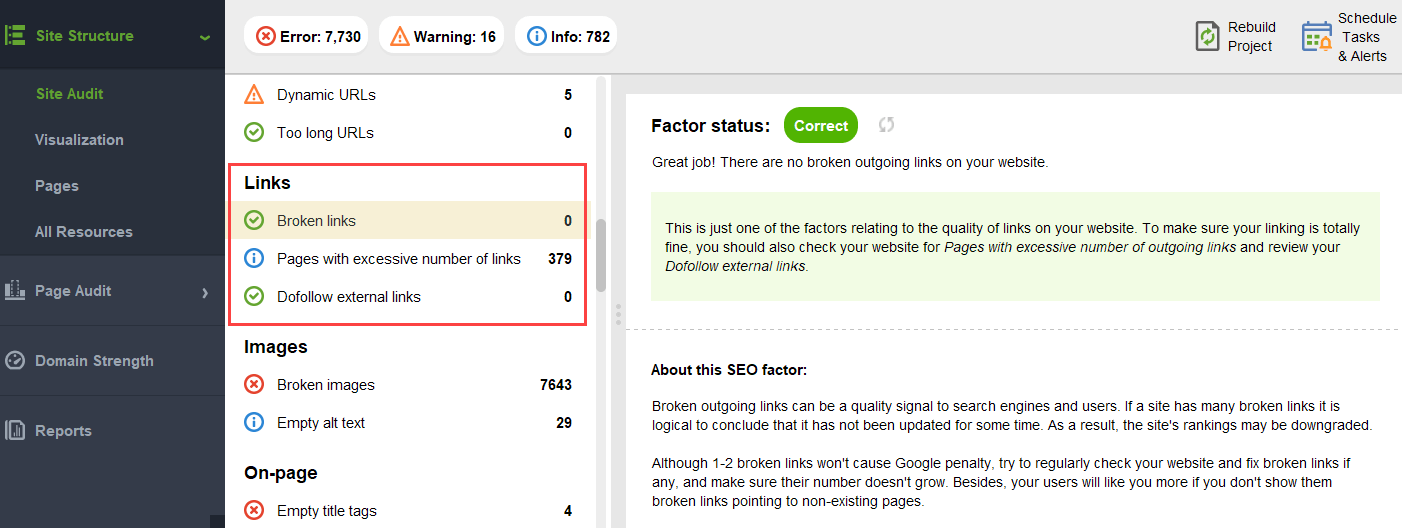
Para garantir que seu site esteja livre desses perigos do PageRank, você pode auditá-lo com o WebSite Auditor. Esta ferramenta possui um conjunto abrangente de módulos na seção Estrutura do Site > Auditoria do Site, que permitem verificar a otimização geral do seu site e, claro, encontrar e corrigir todos os problemas relacionados ao link, como redirecionamentos longos:
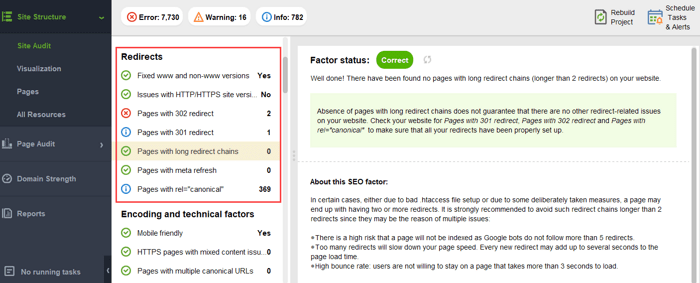
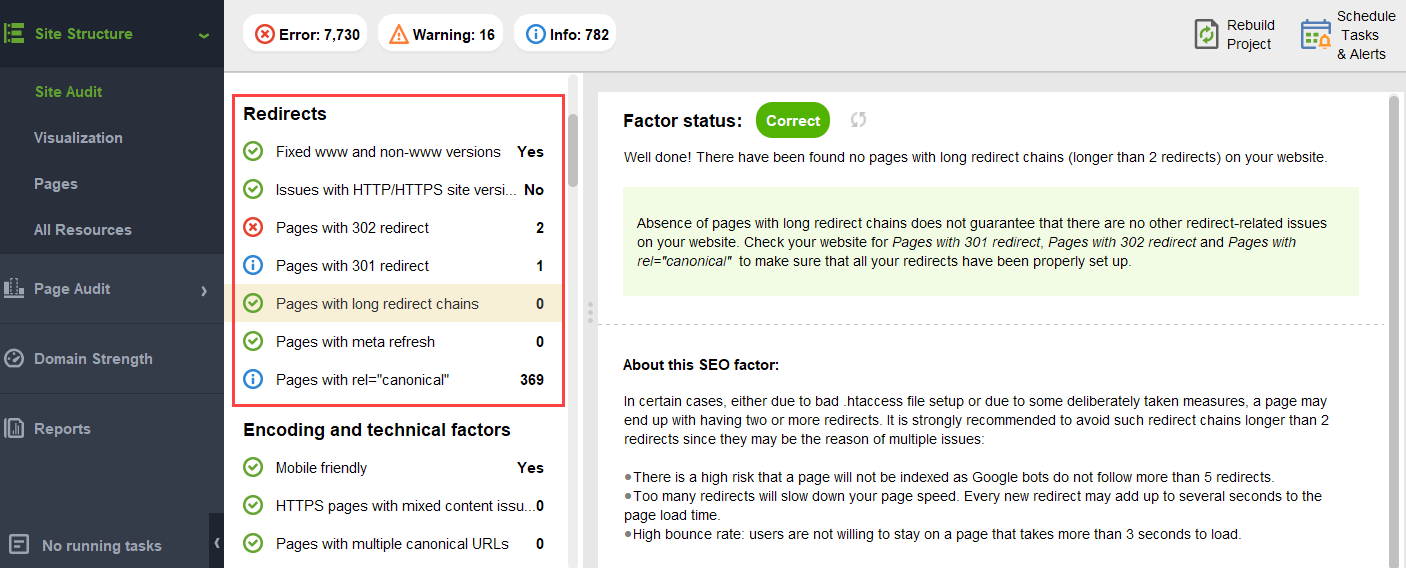
e links quebrados:
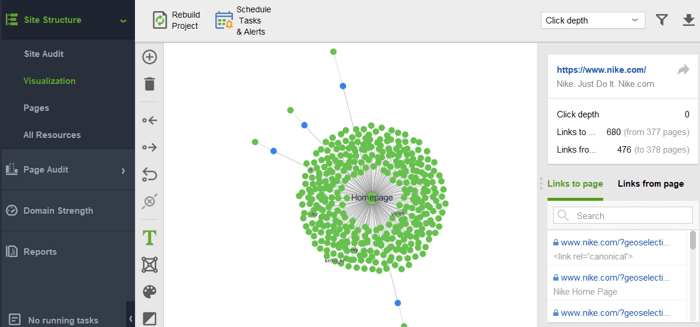
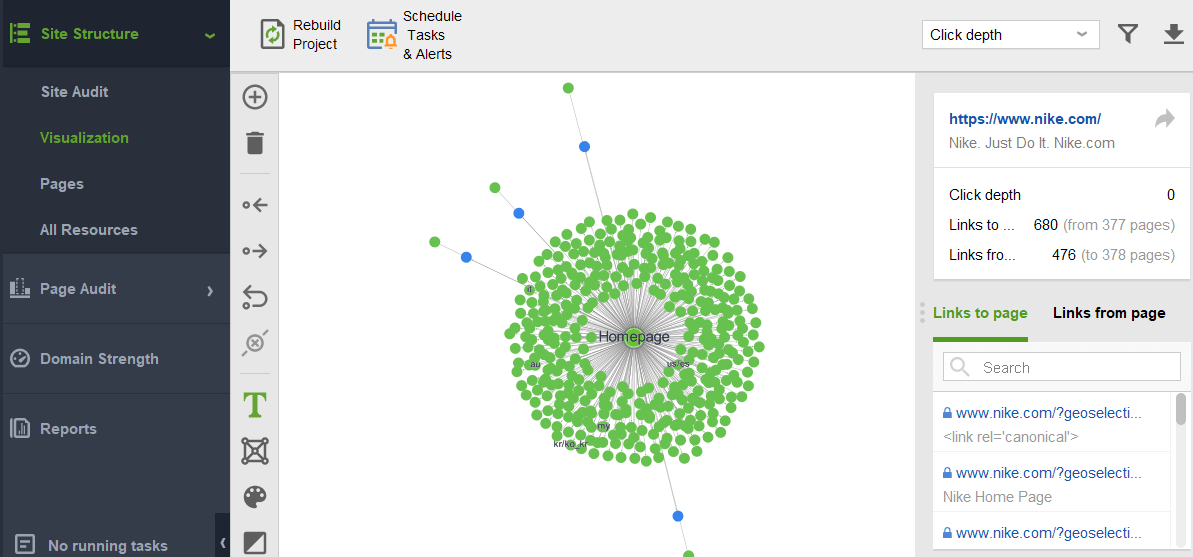
Para verificar se há páginas órfãs ou muito distantes em seu site, alterne para Estrutura do site > Visualização:
Este ano o PageRank completou 23 anos. E acho que é mais velho do que alguns de nossos leitores hoje:) Mas o que está por vir para o PageRank no futuro? Será que um dia vai desaparecer completamente?
Ao tentar pensar em um mecanismo de pesquisa popular que não usa backlinks em seu algoritmo, a única ideia que consigo ter é o experimento Yandex em 2014. O mecanismo de busca anunciou que retirar backlinks de seu algoritmo pode finalmente impedir as manipulações dos spammers de links e ajudar a direcionar seus esforços para a criação de sites de qualidade.
Pode ter sido um esforço genuíno para avançar em direção a fatores de classificação alternativos ou apenas uma tentativa de persuadir as massas a abandonar o spam de links. Mas, de qualquer forma, apenas um ano após o anúncio, Yandex confirmou que os fatores de backlink estavam de volta ao seu sistema.
Mas por que os backlinks são tão indispensáveis para os motores de busca?
Embora tenha inúmeros outros pontos de dados para reorganizar os resultados da pesquisa depois de começar a exibi-los (como comportamento do usuário e ajustes de BERT), os backlinks continuam sendo um dos critérios de autoridade mais confiáveis necessários para formar o SERP inicial. Seu único concorrente aqui são, provavelmente, as entidades.
Como diz Bill Slawski quando questionado sobre o futuro do PageRank:
.png)
O Google está explorando o aprendizado de máquina e a extração de fatos e a compreensão de pares de valores-chave para entidades empresariais, o que significa um movimento em direção à pesquisa semântica e melhor uso de dados estruturados e qualidade dos dados.
Ainda assim, é pouco provável que o Google descarte algo em que investiu dezenas de anos de desenvolvimento.
O Google é muito bom em análise de links, que agora é uma tecnologia web muito madura. Por causa disso, é bem possível que o PageRank continue a ser usado para classificar SERPs orgânicos.
Outra tendência apontada por Bill Slawski foram notícias e outros tipos de resultados de pesquisa de curta duração:
O Google nos disse que tem confiado menos no PageRank para páginas onde a atualidade é mais importante, como resultados em tempo real (como do Twitter), ou de resultados de notícias, onde a atualidade é muito importante.
Na verdade, uma notícia permanece muito pouco nos resultados da pesquisa para acumular backlinks suficientes. Portanto, o Google tem trabalhado e pode continuar trabalhando para substituir backlinks por outros fatores de classificação ao lidar com notícias.
No entanto, por enquanto, as classificações de notícias são altamente determinadas pela autoridade do nicho do editor, e ainda lemos autoridade como backlinks:
"Os sinais de autoridade ajudam a priorizar informações de alta qualidade provenientes das fontes mais confiáveis disponíveis. Para fazer isso, nossos sistemas são projetados para identificar sinais que podem ajudar a determinar quais páginas demonstram experiência, autoridade e confiabilidade em um determinado tópico, com base no feedback dos avaliadores de pesquisa. Esses sinais podem incluir se outras pessoas valorizam a fonte para consultas semelhantes ou se outros sites importantes sobre o assunto têm links para a história.
Por último, mas não menos importante, fiquei bastante surpreso com o esforço que o Google fez para identificar backlinks patrocinados e gerados por usuários e distingui-los de outros links nofollowed.
Se todos esses backlinks devem ser ignorados, por que se preocupar em diferenciar um do outro? Especialmente com John Muller sugerindo que, mais tarde, o Google poderá tentar tratar esses tipos de links de maneira diferente.
Meu palpite mais ousado aqui é que talvez o Google esteja validando se a publicidade e os links gerados pelos usuários podem se tornar um sinal de classificação positivo.
Afinal, a publicidade em plataformas populares exige orçamentos enormes, e orçamentos enormes são um atributo de uma marca grande e popular.
O conteúdo gerado pelo usuário, quando considerado fora do paradigma do spam de comentários, trata-se de clientes reais dando seu endosso na vida real.
No entanto, os especialistas com quem procurei não acreditavam que isso fosse possível:

Duvido que o Google algum dia considere os links patrocinados um sinal positivo.
A ideia aqui, ao que parece, é que, ao distinguir diferentes tipos de links, o Google tentaria descobrir quais dos links nofollow devem ser seguidos para fins de construção de entidades:

O Google não tem problemas com conteúdo gerado pelo usuário ou conteúdo patrocinado em um site; no entanto, ambos têm sido usados historicamente como métodos de manipulação do pagerank. Como tal, os webmasters são incentivados a colocar um atributo nofollow nesses links (entre outros motivos para usar o nofollow). No entanto, os links nofollowed ainda podem ser úteis para o Google (como reconhecimento de entidade, por exemplo), então eles observaram anteriormente que eles pode tratar isso mais como uma sugestão, e não como uma diretiva como uma regra de proibição de robots.txt estaria em seu próprio site. A declaração de John Mueller foi “Eu poderia imaginar em nossos sistemas que poderíamos aprender com o tempo a tratá-los de maneira ligeiramente diferente.” Isso pode estar se referindo aos casos em que o Google trata o nofollow como uma sugestão. Hipoteticamente, é possível que os sistemas do Google possam aprender quais links nofollow seguir com base em insights coletados dos tipos de links marcados como ugc e patrocinados. Novamente, isso não deveria ter muito impacto nas classificações de um site - mas poderia, teoricamente, ter um impacto no site vinculado também.
Espero ter conseguido esclarecer o papel dos backlinks nos algoritmos de busca atuais do Google. Alguns dos dados que encontrei durante a pesquisa para o artigo foram uma surpresa até para mim. Portanto, estou ansioso para participar de sua discussão nos comentários.
Alguma dúvida que ainda não foi respondida? Você tem alguma ideia sobre o futuro do PageRank?
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |



