123176
•
Leitura de 20 minutos
•


Esta lista de verificação descreve todas as porcas e parafusos de uma auditoria de local técnico, da teoria à prática.
Você aprenderá quais arquivos técnicos existem, por que ocorrem problemas de SEO e como corrigi-los e evitá-los no futuro, para que você esteja sempre protegido contra quedas repentinas de classificação .
Ao longo do caminho, mostrarei algumas ferramentas de auditoria de SEO, populares e pouco conhecidas, para conduzir uma auditoria técnica de site sem problemas.
O número de etapas em sua lista de verificação técnica de SEO dependerá dos objetivos e do tipo de sites que você examinará. Nosso objetivo era tornar esta lista de verificação universal, abrangendo todas as etapas importantes das auditorias técnicas de SEO.
1. Obtenha acesso à análise do site e ferramentas para webmasters
Para conduzir uma auditoria técnica do seu site, você precisará de ferramentas de análise e webmaster, e é ótimo se você já as tiver configurado em seu site. Com o Google Analytics , Google Search Console , Bing Webmaster Tools e similares, você já tem uma grande quantidade de dados necessários para uma verificação básica do site .
2. Verifique a segurança do domínio
Se você estiver auditando um site existente que caiu nas classificações, em primeiro lugar, exclua a possibilidade de que o domínio esteja sujeito a qualquer sanção do mecanismo de pesquisa.
Para fazer isso, consulte o Google Search Console. Se o seu site foi penalizado por criação de links de chapéu preto ou foi hackeado, você verá um aviso correspondente na guia Segurança e ações manuais do console. Certifique-se de abordar o aviso que você vê nesta guia antes de prosseguir com uma auditoria técnica do seu site. Se precisar de ajuda, consulte nosso guia sobre como lidar com penalidades manuais e de algoritmo .
Se você estiver auditando um novo site prestes a ser lançado, certifique-se de verificar se seu domínio não está comprometido. Para obter detalhes, consulte nossos guias sobre como escolher domínios expirados e como não ficar preso na caixa de areia do Google durante o lançamento de um site.
Agora que terminamos o trabalho preparatório, vamos passar para a auditoria técnica de SEO do seu site, passo a passo.
De um modo geral, existem dois tipos de problemas de indexação. Uma delas é quando um URL não é indexado, embora devesse ser. A outra é quando um URL é indexado, embora não deva ser. Então, como verificar o número de URLs indexados do seu site?
Para ver quanto do seu site realmente entrou no índice de pesquisa, verifique o relatório Cobertura no Google Search Console . O relatório mostra quantas de suas páginas estão atualmente indexadas, quantas foram excluídas e quais são alguns dos problemas de indexação em seu site.
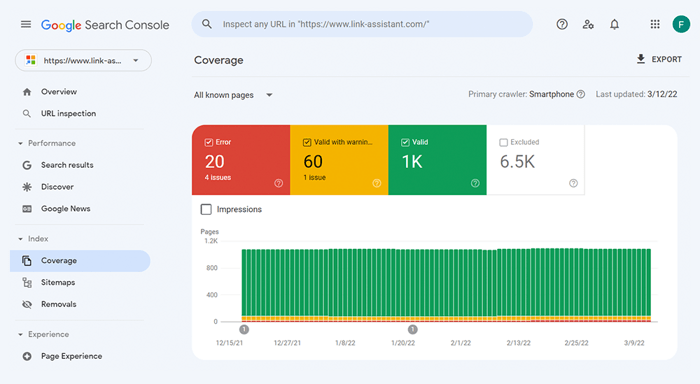

O primeiro tipo de problema de indexação geralmente é marcado como um erro. Erros de indexação acontecem quando você pede ao Google para indexar uma página, mas ela é bloqueada. Por exemplo, uma página foi adicionada a um sitemap, mas está marcada com a tag noindex ou bloqueada com robots.txt.
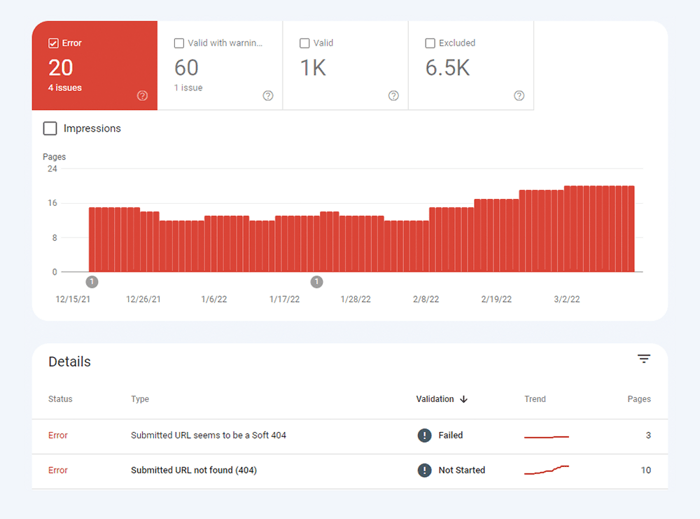
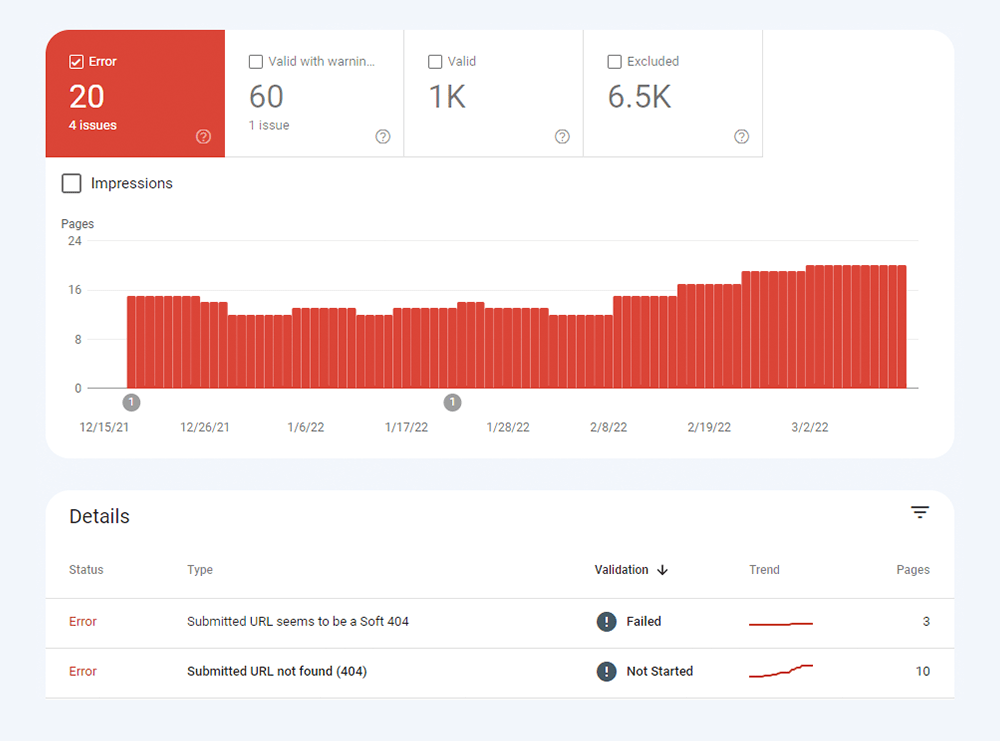
O outro tipo de problema de indexação é quando a página é indexada, mas o Google não tem certeza de que deveria ser indexada. No Google Search Console, essas páginas geralmente são marcadas como Válidas com avisos .
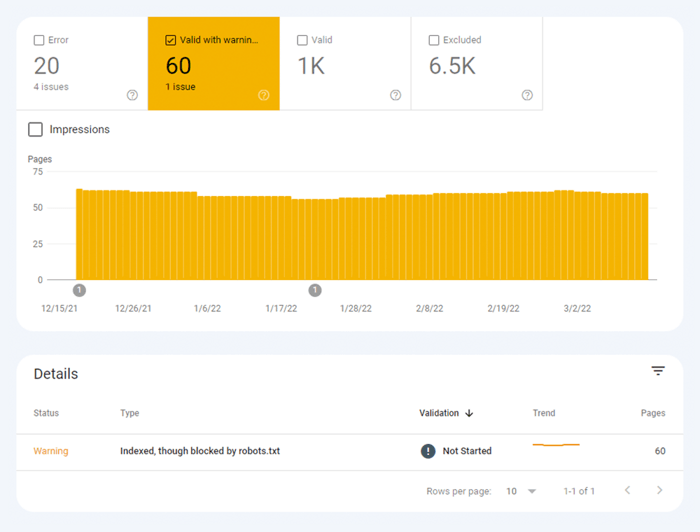

Para uma página individual, execute a ferramenta de inspeção de URL no Search Console para revisar como o bot de pesquisa do Google a vê. Clique na guia respectiva ou cole o URL completo na barra de pesquisa na parte superior e ele recuperará todas as informações sobre o URL, da maneira como foi verificado pela última vez pelo bot de pesquisa.
Em seguida, você pode clicar em Test Live URL e ver ainda mais detalhes sobre a página: o código de resposta, as tags HTML, a captura de tela da primeira tela etc.
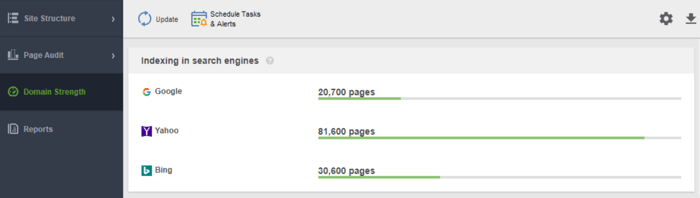
Outra ferramenta para monitorar sua indexação é o WebSite Auditor . Inicie o software e cole o URL do seu site para criar um novo projeto e proceder à auditoria do seu site. Depois que o rastreamento terminar, você verá todos os problemas e avisos no módulo Estrutura do site do WebSite Auditor. No relatório Domain Strength , confira o número de páginas indexadas, não apenas no Google, mas também em outros buscadores.
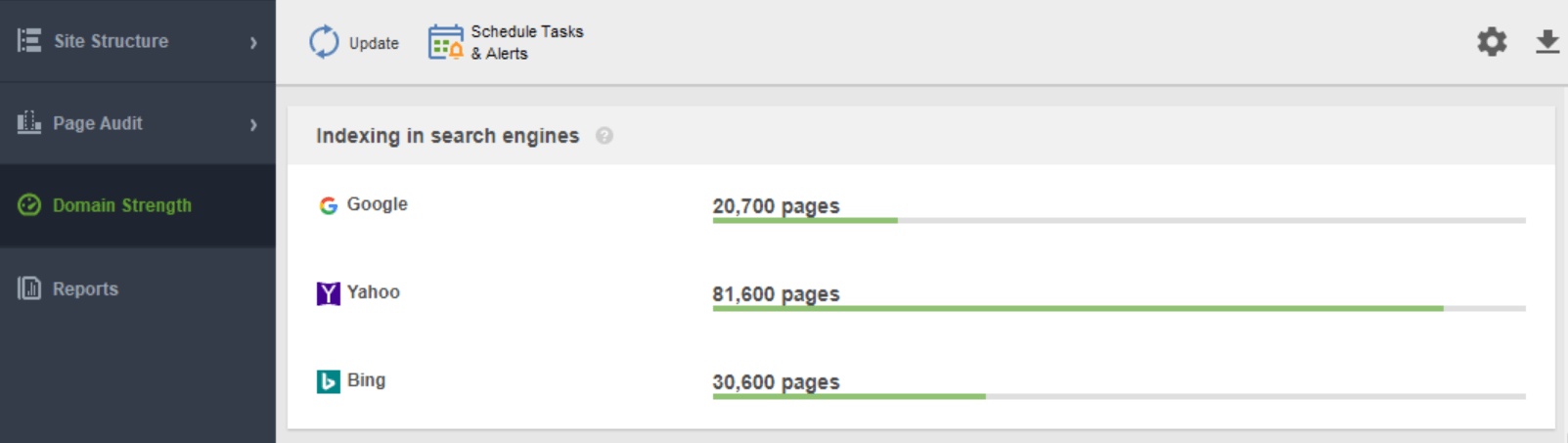
No WebSite Auditor, você pode personalizar a verificação do seu site, escolhendo um bot de pesquisa diferente e especificando as configurações de rastreamento. Nas Preferências de projeto do spider de SEO, defina o bot do mecanismo de pesquisa e um agente de usuário específico. Escolha quais tipos de recursos você deseja examinar durante o rastreamento (ou pule da verificação). Você também pode instruir o rastreador a auditar subdomínios e sites protegidos por senha, ignorar parâmetros de URL especiais e muito mais.
Assista a este passo a passo detalhado em vídeo para aprender como configurar seu projeto e analisar sites.
Sempre que um usuário ou um bot de pesquisa envia uma solicitação ao servidor que transporta os dados do site, o arquivo de log registra uma entrada sobre isso. Essas são as informações mais corretas e válidas sobre rastreadores e visitantes em seu site, erros de indexação, desperdícios de orçamento de rastreamento, redirecionamentos temporários e muito mais. Como pode ser difícil analisar arquivos de log manualmente, você precisará de um programa analisador de arquivo de log.
Qualquer que seja a ferramenta que você decida usar, o número de páginas indexadas deve ser próximo ao número real de páginas do seu site.
E agora vamos passar para como você pode controlar o rastreamento e a indexação do seu site.
Por padrão, se você não tiver nenhum arquivo técnico de SEO com controles de rastreamento, os bots de pesquisa ainda visitarão seu site e o rastrearão como ele está. No entanto, os arquivos técnicos permitem que você controle como os bots dos mecanismos de pesquisa rastreiam e indexam suas páginas, portanto, eles são altamente recomendados se o seu site for grande. Abaixo estão algumas maneiras de modificar as regras de indexação/rastreamento:
Então, como fazer o Google indexar seu site mais rápido usando cada um deles?
Um Sitemap é um arquivo técnico de SEO que lista todas as páginas, vídeos e outros recursos do seu site, bem como as relações entre eles. O arquivo informa aos mecanismos de pesquisa como rastrear seu site com mais eficiência e desempenha um papel crucial na acessibilidade do site.
Um site precisa de um Sitemap quando:
Existem diferentes tipos de sitemaps que você pode querer adicionar ao seu site, dependendo principalmente do tipo de site que você gerencia.
Um mapa do site HTML destina-se a leitores humanos e está localizado na parte inferior do site. Tem pouco valor de SEO, no entanto. Um mapa do site HTML mostra a navegação principal para as pessoas e geralmente replica os links nos cabeçalhos do site. Enquanto isso, os sitemaps HTML podem ser usados para melhorar a acessibilidade de páginas que não estão incluídas no menu principal.
Ao contrário dos sitemaps HTML, os sitemaps XML são legíveis por máquina graças a uma sintaxe especial. O Sitemap XML está no domínio raiz, por exemplo, https://www.link-assistant.com/sitemap.xml. Mais abaixo, discutiremos os requisitos e tags de marcação para criar um sitemap XML correto.
Este é um tipo alternativo de mapa do site disponível para bots de mecanismos de pesquisa. O mapa do site TXT simplesmente lista todos os URLs do site, sem fornecer nenhuma outra informação sobre o conteúdo.
Esse tipo de sitemap é útil para vastas bibliotecas de imagens e imagens de grande porte para ajudá-las a classificar na Pesquisa de imagens do Google. No Sitemap da imagem, você pode fornecer informações adicionais sobre a imagem, como geolocalização, título e licença. Você pode listar até 1.000 imagens para cada página.
Os Sitemaps de vídeo são necessários para o conteúdo de vídeo hospedado em suas páginas para ajudá-lo a se classificar melhor na Pesquisa de vídeo do Google. Embora o Google recomende o uso de dados estruturados para vídeos, um mapa do site também pode ser útil, especialmente quando você tem muito conteúdo de vídeo em uma página. No Sitemap de vídeo, você pode adicionar informações extras sobre o vídeo, como títulos, descrição, duração, miniaturas e até mesmo se for familiar para o Safe Search.
Para sites multilíngues e multirregionais, há várias maneiras de os mecanismos de pesquisa determinarem qual versão do idioma será veiculada em um determinado local. Hreflangs são uma das várias maneiras de servir páginas localizadas, e você pode usar um mapa do site hreflang especial para isso. O mapa do site hreflang lista o próprio URL junto com seu elemento filho, indicando o código de idioma/região da página.
Se você tem um blog de notícias, adicionar um Sitemap News-XML pode impactar positivamente sua classificação no Google Notícias. Aqui, você adiciona informações sobre o título, o idioma e a data de publicação. Você pode adicionar até 1.000 URLs no Sitemap de notícias. As URLs não devem ter mais de dois dias, após o que você pode excluí-las, mas elas permanecerão no índice por 30 dias.
Se o seu site tiver um feed RSS, você poderá enviar o URL do feed como um mapa do site. A maioria dos softwares de blog é capaz de criar um feed, mas essas informações são úteis apenas para a descoberta rápida de URLs recentes.
Hoje em dia, os mais usados são os sitemaps XML, então vamos revisar brevemente os principais requisitos para geração de sitemaps XML:
O mapa do site XML é codificado em UTF-8 e contém tags obrigatórias para um elemento XML:
Um exemplo simples de um mapa do site XML de entrada única será semelhante a
Existem tags opcionais para indicar a prioridade e a frequência dos rastreamentos de página – <priority>, <changefreq> (o Google atualmente as ignora) e o valor <lastmod> quando for preciso (por exemplo, em comparação com a última modificação em uma página) .
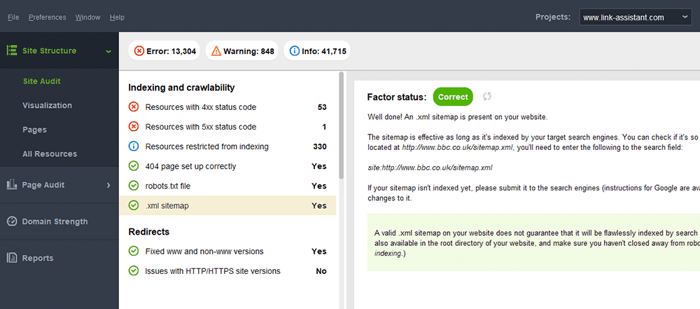
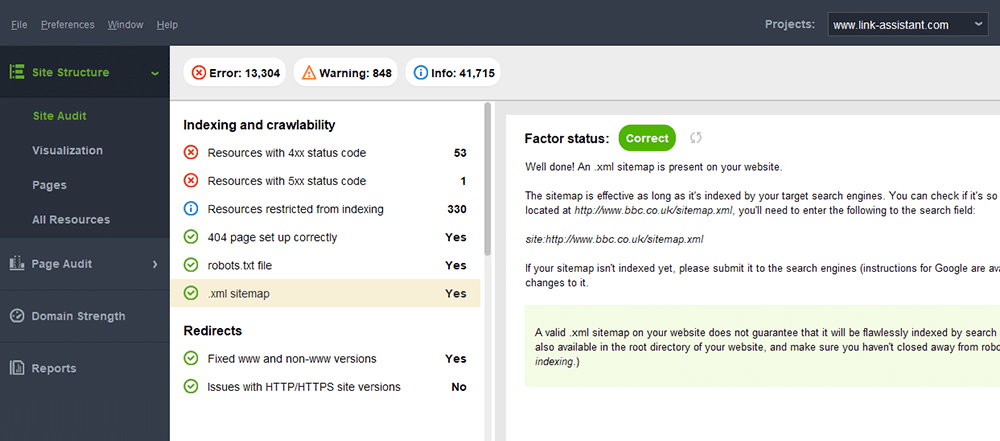
Um erro típico com sitemaps é não ter um sitemap XML válido em um domínio grande. Você pode verificar a presença de um mapa do site no seu com o WebSite Auditor . Encontre os resultados na seção Auditoria do site > Indexação e rastreabilidade .
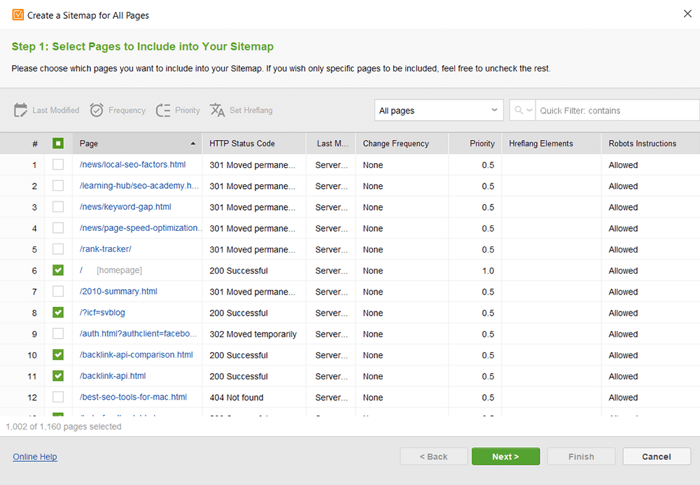
Se você não tem um mapa do site, você deve criar um agora mesmo. Você podegerar rapidamente o mapa do site usando as Ferramentas do site do WebSite Auditor ao alternar para a seção Páginas .
E deixe o Google saber sobre o seu mapa do site. Para fazer isso, você pode
O fato é que ter um sitemap em seu site não garante que todas as suas páginas serão indexadas ou mesmo rastreadas . Existem alguns outros recursos técnicos de SEO, voltados para melhorar a indexação do site. Vamos analisá-los nas próximas etapas.
Um arquivo robots.txt informa aos mecanismos de pesquisa quais URLs o rastreador pode acessar em seu site. Este arquivo serve para evitar sobrecarregar seu servidor com requisições, gerenciando o tráfego de rastreamento . O arquivo é normalmente usado para:
Robots.txt é colocado na raiz do domínio e cada subdomínio deve ter seu próprio arquivo separado. Lembre-se de que não deve exceder 500kB e deve responder com um código 200.
O arquivo robots.txt também possui sua sintaxe com regras de permissão e proibição :
Diferentes mecanismos de pesquisa podem seguir as diretivas de maneira diferente. Por exemplo, o Google abandonou o uso das diretivas noindex, crawl-delay e nofollow de robots.txt. Além disso, existem rastreadores especiais como Googlebot-Image, Bingbot, Baiduspider-image, DuckDuckBot, AhrefsBot, etc. Portanto, você pode definir as regras para todos os bots de pesquisa ou regras separadas para apenas alguns deles.
Escrever instruções para robots.txt pode se tornar bastante complicado, então a regra aqui é ter menos instruções e mais bom senso. Abaixo estão alguns exemplos de configuração das instruções do robots.txt.
Acesso total ao domínio. Neste caso, a regra de bloqueio não é preenchida.
Bloqueio total de um host.
A instrução não permite o rastreamento de todos os URLs começando com upload após o nome de domínio.
A instrução não permite que o Googlebot-News rastreie todos os arquivos gif na pasta de notícias.
Lembre-se de que, se você definir alguma instrução geral A para todos os mecanismos de pesquisa e uma instrução restrita B para um bot específico, o bot específico poderá seguir a instrução restrita e executar todas as outras regras gerais definidas por padrão para o bot, pois não será restringido pela regra A. Por exemplo, como na regra abaixo:
Aqui, o AdsBot-Google-Mobile pode rastrear arquivos na pasta tmp, apesar da instrução com a marca curinga *.
Um dos usos típicos dos arquivos robots.txt é indicar onde fica o Sitemap. Nesse caso, não é necessário mencionar os agentes do usuário, pois a regra se aplica a todos os rastreadores. O mapa do site deve começar com S maiúsculo (lembre-se de que o arquivo robots.txt diferencia maiúsculas de minúsculas) e o URL deve ser absoluto (ou seja, deve começar com o nome de domínio completo).
Lembre-se de que, se você definir instruções contraditórias, os robôs rastreadores darão prioridade à instrução mais longa. Por exemplo:
Aqui, o script /admin/js/global.js ainda será permitido para rastreadores, apesar da primeira instrução. Todos os outros arquivos na pasta admin ainda não serão permitidos.
Você pode verificar a disponibilidade do arquivo robots.txt no WebSite Auditor. Ele também permite que você gere o arquivo usando a ferramenta geradora robots.txt , salvando-o ou enviando-o diretamente para o site via FTP.
Esteja ciente de que o arquivo robots.txt está disponível publicamente e pode expor algumas páginas em vez de ocultá-las. Se você deseja ocultar algumas pastas particulares, torne-as protegidas por senha.
Finalmente, o arquivo robots.txt não garante que a página não permitida não seja rastreada ou indexada . Bloquear o Google de rastrear uma página provavelmente a removerá do índice do Google, no entanto, o bot de pesquisa ainda pode rastrear a página seguindo alguns backlinks apontando para ela. Então, aqui está outra maneira de bloquear o rastreamento e a indexação de uma página — meta robots.
As tags meta robots são uma ótima maneirade instruir os rastreadores sobre como tratar páginas individuais. As tags meta robots são adicionadas à seção <head> da sua página HTML, portanto, as instruções são aplicáveis a toda a página. Você pode criar várias instruções combinando diretivas de metatag de robôs com vírgulas ou usando várias metatags. Pode ser assim:
Você pode especificar tags meta robots para vários rastreadores, por exemplo
O Google entende tags como:
As tags opostas indexar/seguir/arquivar substituem as diretivas de proibição correspondentes. Existem algumas outras tags informando como a página pode aparecer nos resultados da pesquisa, como snippet / nosnippet / notranslate / nopagereadaloud / noimageindex .
Se você usar outras tags válidas para outros mecanismos de pesquisa, mas desconhecidas do Google, o Googlebot simplesmente as ignorará.
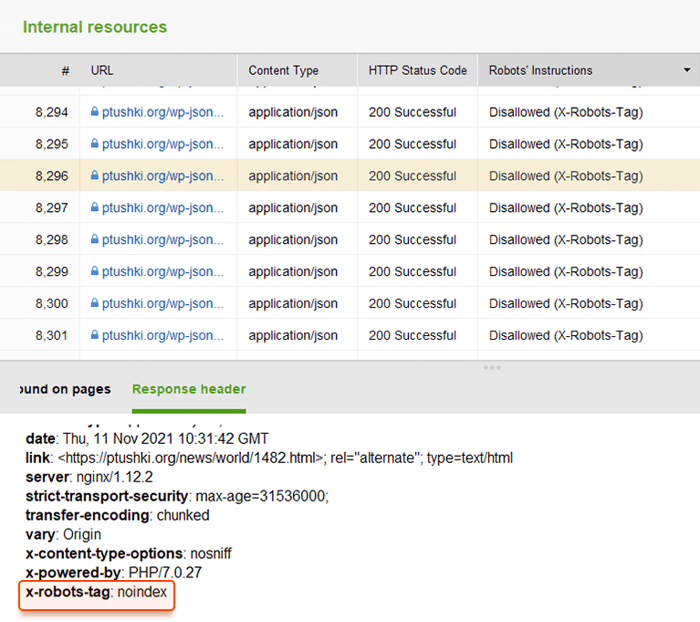
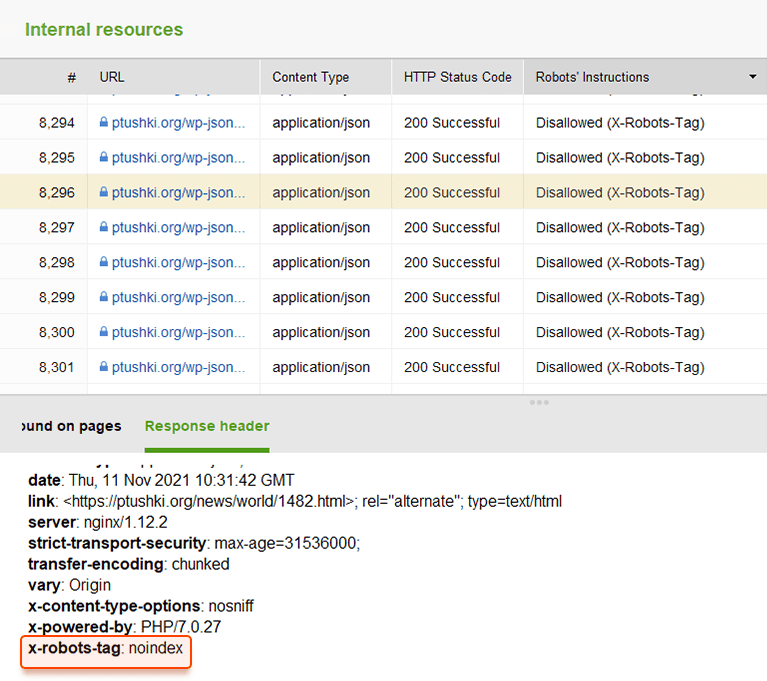
Em vez de metatags, você pode usar um cabeçalho de resposta para recursos não HTML , como PDFs, arquivos de vídeo e imagem. Defina para retornar um cabeçalho X-Robots-Tag com um valor de noindex ou nenhum em sua resposta.
Você também pode usar uma combinação de diretivas para definir a aparência do snippet nos resultados da pesquisa, por exemplo, max-image-preview: [setting] ou nosnippet ou max-snippet: [number] , etc.
Você pode adicionar o X-Robots-Tag às respostas HTTP de um site por meio dos arquivos de configuração do software do servidor da web do seu site. Suas diretivas de rastreamento podem ser aplicadas globalmente em todo o site para todos os arquivos, bem como para arquivos individuais se você definir seus nomes exatos.
Você pode revisar rapidamente todas as instruções de robôs com o WebSite Auditor . Vá para Estrutura do Site > Todos os Recursos > Recursos Internos e verifique a coluna Instruções dos Robôs . Aqui você encontrará as páginas não permitidas e qual método é aplicado, robots.txt, meta tags ou X-Robots-tag.
O servidor que hospeda um site gera um código de status HTTP ao responder a uma solicitação feita por um cliente, navegador ou rastreador. Se o servidor responder com um código de status 2xx, o conteúdo recebido pode ser considerado para indexação. Outras respostas de 3xx a 5xx indicam que há um problema com a renderização do conteúdo. Aqui estão alguns significados das respostas do código de status HTTP:
Redirecionamentos 301 são usados quando:
302 redirecionamento temporário
O redirecionamento 302 temporário deve ser usado apenas em páginas temporárias. Por exemplo, quando você está redesenhando uma página ou testando uma nova página e coletando feedback, mas não quer que o URL caia das classificações.
304 para verificar o cache
O código de resposta 304 é compatível com todos os mecanismos de pesquisa mais populares, como Google, Bing, Baidu, Yandex, etc. A configuração correta do código de resposta 304 ajuda o bot a entender o que mudou na página desde seu último rastreamento. O bot envia uma solicitação HTTP If-Modified-Since. Se nenhuma alteração for detectada desde a última data de rastreamento, o bot de pesquisa não precisará rastrear novamente a página. Para um usuário, isso significa que a página não será totalmente recarregada e seu conteúdo será retirado do cache do navegador.
O código 304 também ajuda a:
É importante verificar o cache não apenas do conteúdo da página, mas também de arquivos estáticos, como imagens ou estilos CSS. Existem ferramentas especiais, como esta , para verificar o código de resposta 304.


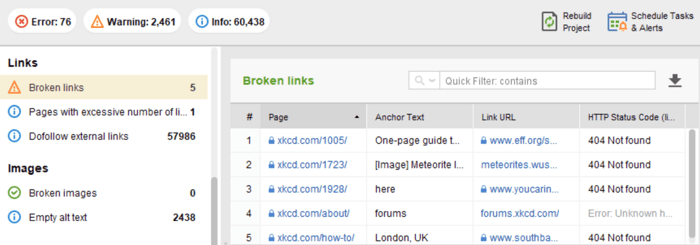
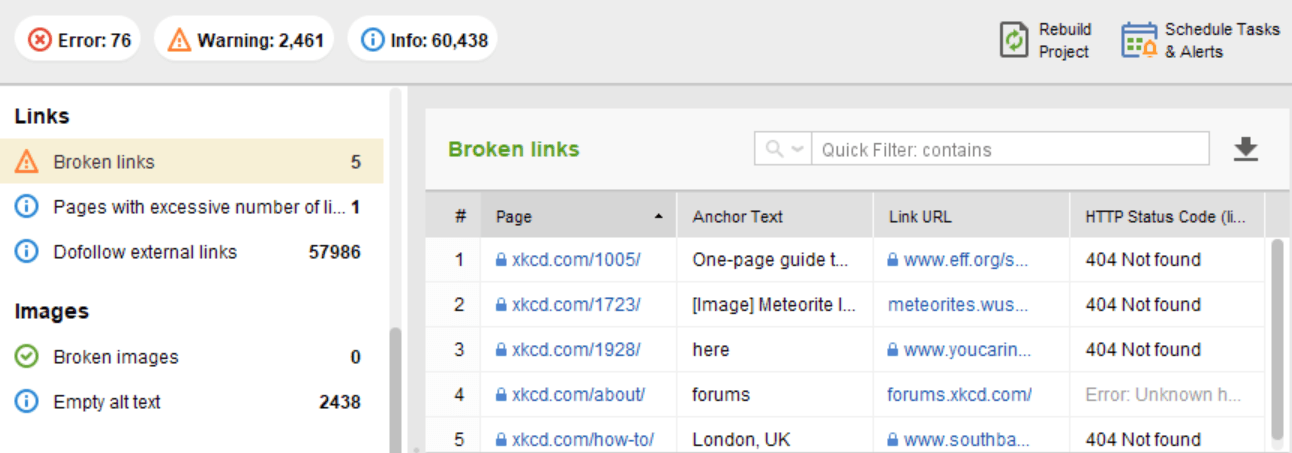
Na maioria das vezes, os problemas de código de resposta do servidor aparecem quando os rastreadores continuam seguindo os links internos e externos para as páginas excluídas ou movidas, obtendo respostas 3xx e 4xx.
Um erro 404 mostra que uma página não está disponível e o servidor envia o código de status HTTP correto para o navegador — um 404 Not Found.
No entanto, existem erros soft 404 quando o servidor envia o código de resposta 200 OK, mas o Google considera que deveria ser 404. Isso pode acontecer porque:
No módulo Site Audit do WebSite Auditor, revise os recursos com o código de resposta 4xx, 5xx na guia Indexação e rastreabilidade e uma seção separada para links quebrados na guia Links .
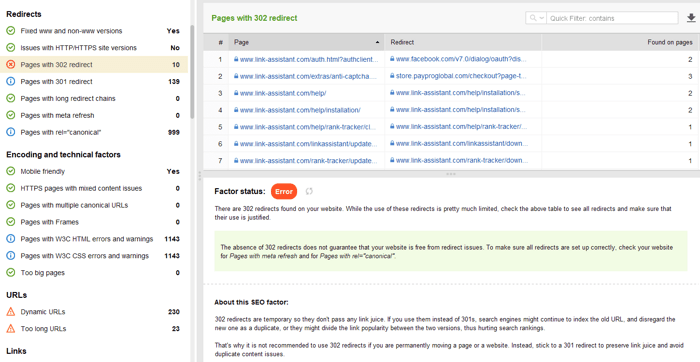
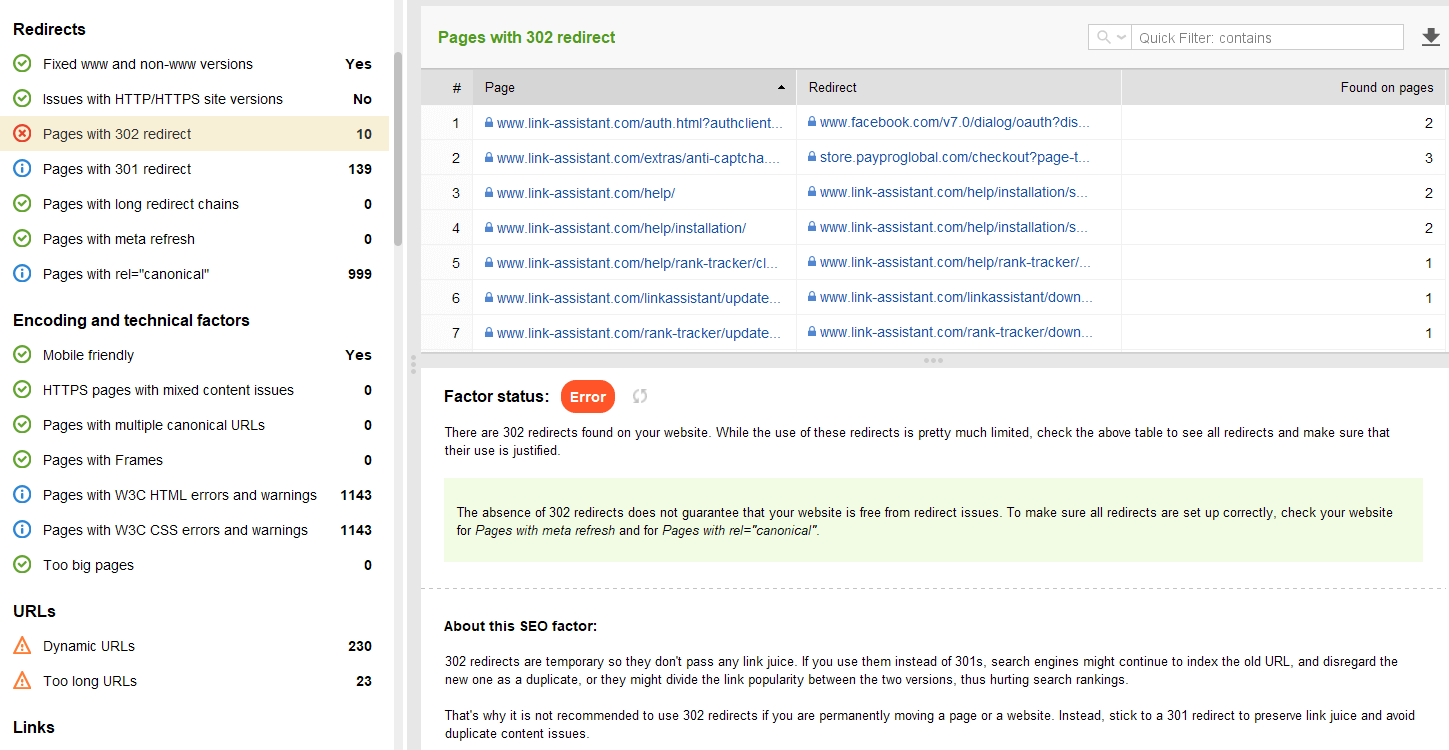
Alguns outros problemas comuns de redirecionamento envolvendo respostas 301/302:
Você pode revisar todas as páginas com redirecionamentos 301 e 302 na seção Site Audit > Redirects do WebSite Auditor.
A duplicação pode se tornar um problema grave para o rastreamento de sites. Se o Google encontrar URLs duplicados , ele decidirá qual deles é a página principal e a rastreará com mais frequência, enquanto as duplicatas serão rastreadas com menos frequência e poderão sair do índice de pesquisa. Uma solução infalível é indicar uma das páginas duplicadas como canônica, a principal. Isso pode ser feito com a ajuda do atributo rel=”canonical” , colocado no código HTML das páginas ou nas respostas do cabeçalho HTTP de um site.
O Google usa páginas canônicas para avaliar seu conteúdo e qualidade e, na maioria das vezes, links de resultados de pesquisa para páginas canônicas, a menos que os mecanismos de pesquisa identifiquem claramente que alguma página não canônica é mais adequada para o usuário (por exemplo, é um usuário móvel ou um pesquisador em um local específico).
Assim, a canonização de páginas relevantes ajuda a:
Problemas duplicados significam conteúdo idêntico ou semelhante que aparece em vários URLs. Muitas vezes, as duplicações aparecem automaticamente devido ao manuseio de dados técnicos em um site.
Alguns CMSs podem gerar problemas duplicados automaticamente devido às configurações incorretas. Por exemplo, vários URLs podem ser gerados em vários diretórios de sites, e estes são duplicados:
A paginação também pode causar problemas de duplicação se implementada incorretamente. Por exemplo, o URL da página da categoria e a página 1 mostram o mesmo conteúdo e, portanto, são tratados como duplicados. Essa combinação não deve existir ou a página da categoria deve ser marcada como canônica.
Os resultados de classificação e filtragem podem ser representados como duplicatas. Isso acontece quando seu site cria URLs dinâmicos para pesquisas ou consultas de filtragem. Você obterá parâmetros de URL que representam aliases de strings de consulta ou variáveis de URL, que são a parte de uma URL que segue um ponto de interrogação.
Para impedir que o Google rastreie várias páginas quase idênticas, defina para ignorar determinados parâmetros de URL. Para fazer isso, inicie o Google Search Console e vá para Ferramentas e relatórios herdados > Parâmetros de URL . Clique em Editar à direita e informe ao Google quais parâmetros ignorar - a regra será aplicada em todo o site. Lembre-se de que a Ferramenta de Parâmetros é para usuários avançados, por isso deve ser manuseada com precisão.
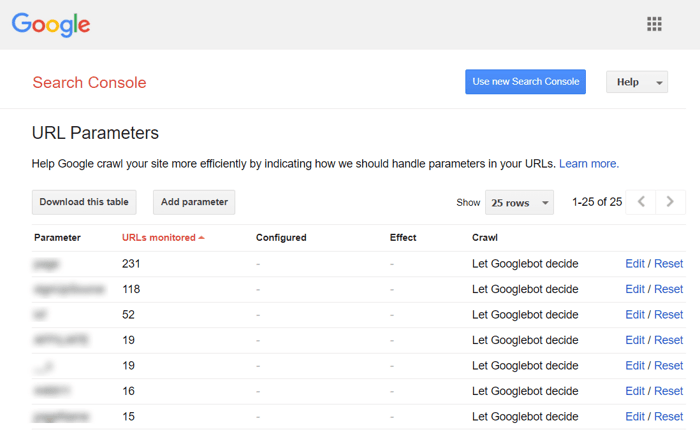
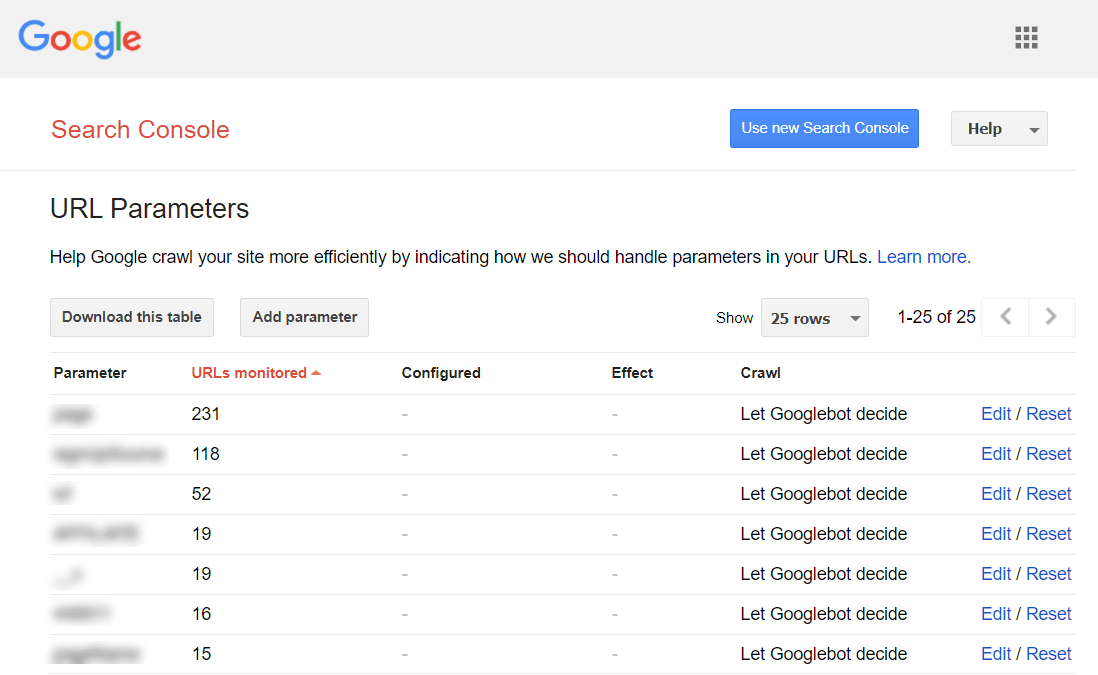
O problema de duplicação geralmente ocorre em sites de comércio eletrônico que permitem a navegação por filtro facetado , restringindo a pesquisa a três, quatro e mais critérios. Aqui está um exemplo de como configurar regras de rastreamento para um site de comércio eletrônico: armazene URLs com resultados de pesquisa mais longos e mais restritos em uma pasta específica e proíba-os por meio de uma regra robots.txt.
Problemas lógicos na estrutura do site podem causar duplicação. Esse pode ser o caso quando você está vendendo produtos e um produto pertence a diferentes categorias.
Nesse caso, os produtos devem ser acessíveis por apenas uma URL. As URLs são consideradas duplicatas completas e prejudicam o SEO. A URL deve ser atribuída através das configurações corretas do CMS, gerando uma única URL única para uma página.
A duplicação parcial geralmente acontece com o WordPress CMS, por exemplo, quando tags são usadas. Embora as tags melhorem a pesquisa no site e a navegação do usuário, os sites do WP geram páginas de tags que podem coincidir com os nomes das categorias e representam conteúdo semelhante da visualização do snippet do artigo. A solução é usar as tags com sabedoria, adicionando apenas um número limitado delas. Ou você pode adicionar um meta robots noindex dofollow nas páginas de tags.
Se você optar por veicular uma versão móvel separada de seu site e, em particular, gerar páginas AMP para pesquisa móvel, poderá ter duplicatas desse tipo.
Para indicar que uma página é duplicada, você pode usar uma tag <link> na seção head do seu HTML. Para versões móveis, esta será a tag de link com o valor rel=“alternate”, assim:
O mesmo se aplica às páginas AMP (que não são a tendência, mas ainda podem ser usadas para renderizar resultados móveis). Dê uma olhada em nosso guia sobre implementação de páginas AMP .
Existem várias maneiras de apresentar conteúdo localizado . Quando você apresenta conteúdo para diferentes variantes de idioma/localidade e traduziu apenas o cabeçalho/rodapé/navegação do site, mas o conteúdo permanece no mesmo idioma, os URLs serão tratados como duplicados.
Configure a exibição de sites multilíngues e multirregionais com a ajuda de tags hreflang , adicionando os códigos de idioma/região suportados no HTML, códigos de resposta HTTP ou no mapa do site.
Os sites geralmente estão disponíveis com e sem "www" no nome de domínio. Esse problema é bastante comum e as pessoas vinculam-se às versões www e não www. Corrigir isso ajudará a impedir que os mecanismos de pesquisa indexem duas versões de um site. Embora essa indexação não cause penalidade, definir uma versão como prioridade é uma prática recomendada.
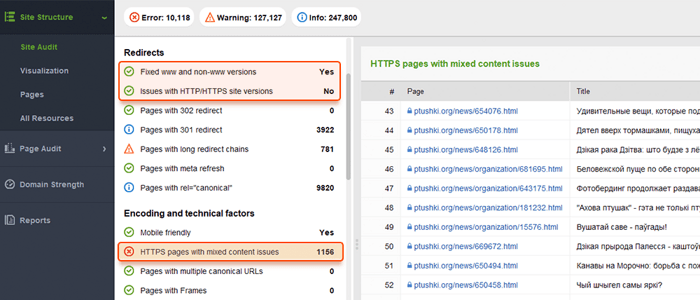

O Google prefere HTTPS a HTTP, pois a criptografia segura é altamente recomendada para a maioria dos sites (especialmente ao fazer transações e coletar informações confidenciais do usuário). Às vezes, os webmasters enfrentam problemas técnicos ao instalar certificados SSL e configurar as versões HTTP/HTTPS do site. Se um site tiver um certificado SSL inválido (não confiável ou expirado), a maioria dos navegadores da Web impedirá que os usuários visitem seu site, notificando-os sobre uma "conexão insegura".
Se as versões HTTP e HTTPS do seu site não estiverem definidas corretamente, ambas poderão ser indexadas pelos mecanismos de pesquisa e causar problemas de conteúdo duplicado que podem prejudicar a classificação do seu site.
Se o seu site já estiver usando HTTPS (parcial ou totalmente), é importante eliminar os problemas comuns de HTTPS como parte da auditoria do site de SEO. Em particular, lembre-se deverificar se há conteúdo misto na seção Auditoria do site > Codificação e fatores técnicos .
Problemas de conteúdo misto surgem quando uma página segura carrega parte de seu conteúdo (imagens, vídeos, scripts, arquivos CSS) em uma conexão HTTP não segura. Isso enfraquece a segurança e pode impedir que os navegadores carreguem o conteúdo não seguro ou até mesmo a página inteira.
Para evitar esses problemas, você pode configurar e exibir a versão www principal ou não www do seu site no arquivo .htaccess . Além disso, defina o domínio preferencial no Google Search Console e indique as páginas HTTPS como canônicas.
Uma vez que você tenha controle total do conteúdo em seu próprio site, certifique Website Auditor se de que não haja títulos, cabeçalhos, descrições, imagens etc. duplicados. painel. As páginas com títulos duplicados e tags de meta descrição provavelmente também terão conteúdo quase idêntico.
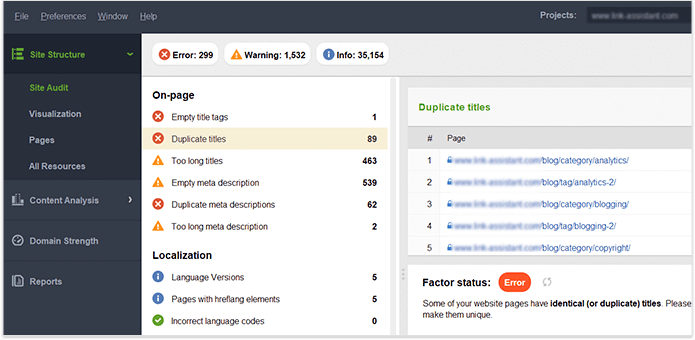
Vamos resumir como descobrimos e corrigimos problemas de indexação. Se você seguiu todas as dicas acima, mas algumas de suas páginas ainda não estão no índice, aqui está uma recapitulação do motivo pelo qual isso pode ter acontecido:
Por que uma página é indexada, embora não deva ser?
Lembre-se de que bloquear uma página no arquivo robots.txt e removê-la do sitemap não garante que ela não seja indexada. Você pode consultar nosso guia detalhado sobre como impedir que as páginas sejam indexadas corretamente.
A arquitetura de site lógica e rasa é importante tanto para os usuários quanto para os bots dos mecanismos de pesquisa. Uma estrutura de site bem planejada também desempenha um grande papel em seus rankings porque:
Ao revisar a estrutura e os links internos de seus sites, preste atenção aos seguintes elementos.
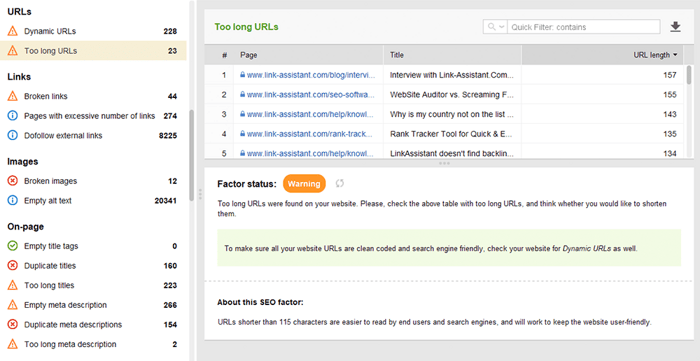
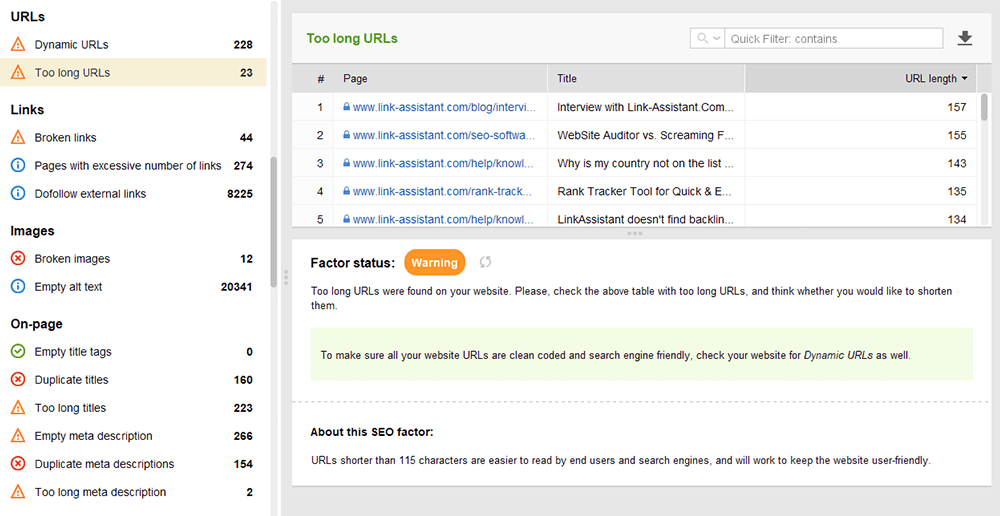
URLs otimizados são cruciais por dois motivos. Primeiro, é um fator de classificação menor para o Google. Em segundo lugar, os usuários podem ficar confusos com URLs muito longos ou desajeitados. Pensando em sua estrutura de URL, siga as seguintes práticas recomendadas :
Você pode verificar suas URLs na seção Auditoria do site > URLs do WebSite Auditor.
Existem muitos tipos de links, alguns deles são mais ou menos benéficos para o SEO do seu site. Por exemplo, os links contextuais dofollow passam o link juice e servem como um indicador adicional para os mecanismos de pesquisa sobre o que é o link. Os links são considerados de alta qualidade quando (e isso se refere a links internos e externos):
Os links de navegação nos cabeçalhos e nas barras laterais também são importantes para o SEO do site, pois ajudam os usuários e os mecanismos de pesquisa a navegar pelas páginas.
Outros links podem não ter valor de classificação ou até mesmo prejudicar a autoridade do site. Por exemplo, links de saída massivos em todo o site em modelos (que os modelos WP gratuitos costumavam ter muito). Este guia sobre os tipos de links em SEO mostra como criar links valiosos da maneira certa.
Você pode usar a ferramenta WebSite Auditor para examinar minuciosamente os links internos e sua qualidade.
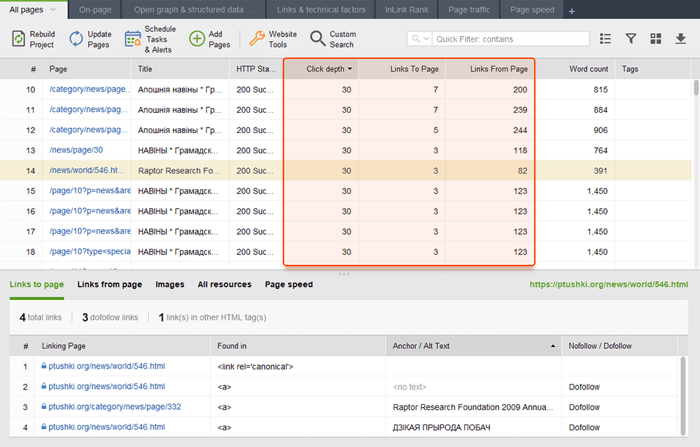
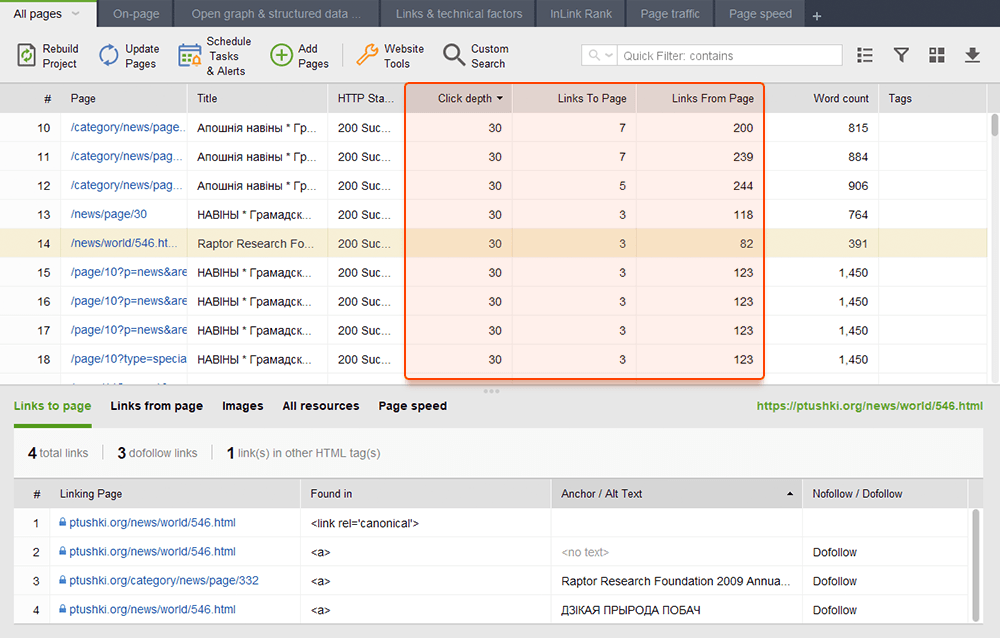
As páginas órfãs são páginas sem links que passam despercebidas e, finalmente, podem cair fora do índice de pesquisa. Para localizar páginas órfãs, vá para Auditoria do site > Visualização e revise o mapa do site visual . Aqui você verá facilmente todas as páginas sem links e longas cadeias de redirecionamento (os redirecionamentos 301 e 302 estão marcados em azul).
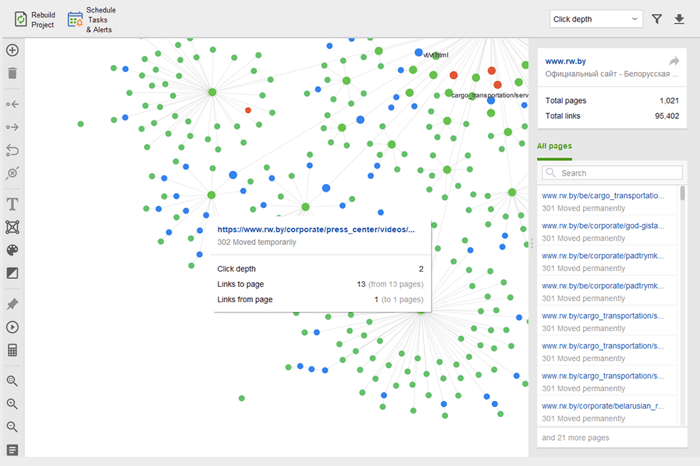
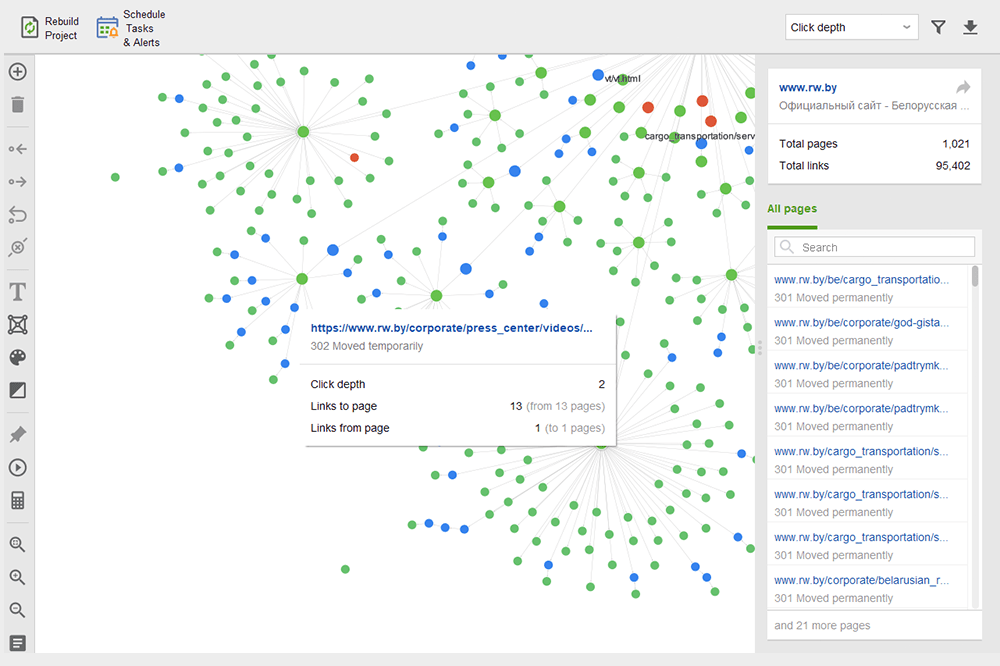
Você pode ter uma visão geral de toda a estrutura do site, examinar o peso de suas páginas principais - verificando as exibições de página (integradas do Google Analytics), PageRank e o link juice que eles obtêm dos links de entrada e saída. Você pode adicionar e remover links e reconstruir o projeto, recalculando o destaque de cada página.
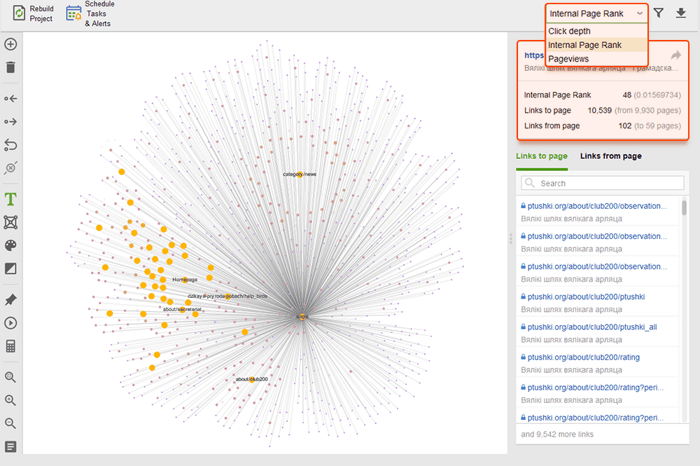
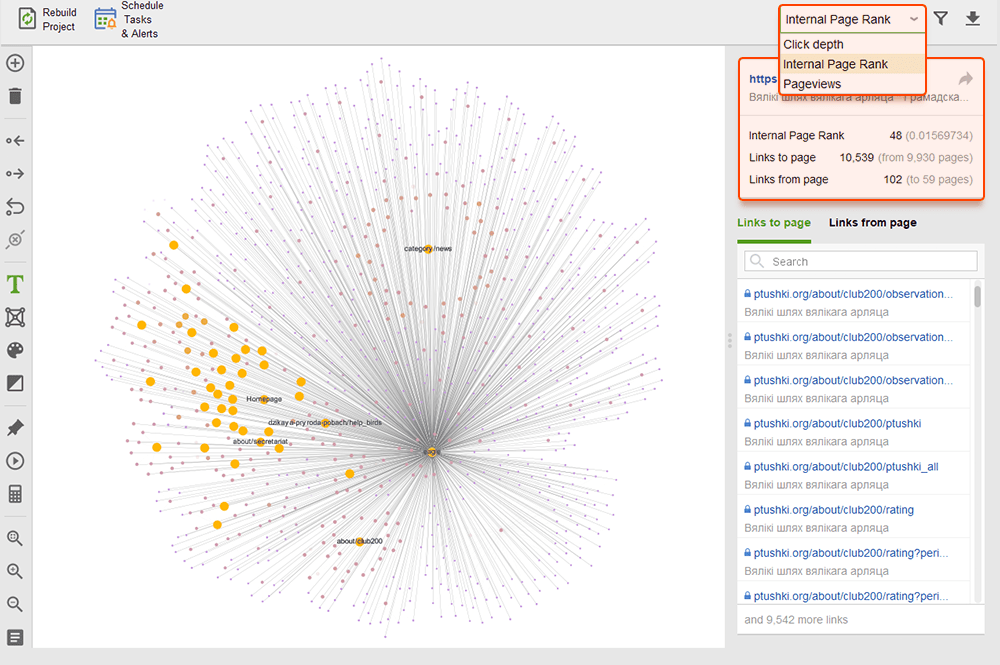
Ao auditar seus links internos, verifique a profundidade do clique. Certifique-se de que as páginas importantes do seu site não estejam a mais de três cliques da página inicial. Outro local para revisar a profundidade de cliques no WebSite Auditor é pular para Estrutura do site > Páginas . Em seguida, classifique os URLs por profundidade de clique em ordem decrescente clicando duas vezes no cabeçalho da coluna.
A paginação das páginas do blog é necessária para a descoberta pelos mecanismos de pesquisa, embora aumente a profundidade do clique. Use uma estrutura simples junto com uma pesquisa de site acionável para facilitar a localização de qualquer recurso pelos usuários.
Para obter mais detalhes, consulte nosso guia detalhado para paginação compatível com SEO .
Breadcrumb é um tipo de marcação que ajuda a criar resultados avançados na pesquisa, mostrando o caminho para a página dentro da estrutura do seu site. Breadcrumbs aparecem graças a links adequados, com âncoras otimizadas em links internos e dados estruturados implementados corretamente (vamos nos debruçar sobre o último alguns parágrafos abaixo).

Na verdade, os links internos podem afetar a classificação do seu site e a forma como cada página é apresentada na pesquisa. Para saber mais, consulte nosso guia de SEO para estratégias de links internos .
A velocidade do site e a experiência da página impactam diretamente as posições orgânicas. A resposta do servidor pode se tornar um problema para o desempenho do site quando muitos usuários o visitam ao mesmo tempo. Quanto à velocidade da página, o Google espera que o maior conteúdo da página seja carregado na janela de visualização em 2,5 segundos ou menos e, eventualmente, recompensa as páginas que apresentam melhores resultados. É por isso que a velocidade deve ser testada e melhorada tanto no lado do servidor quanto no lado do cliente.
O teste de velocidade de carga descobre problemas do lado do servidor quando muitos usuários visitam um site simultaneamente. Embora o problema esteja relacionado às configurações do servidor, os SEOs devem levá-lo em consideração antes de planejar campanhas de publicidade e SEO em grande escala. Teste a capacidade máxima de carga do servidor se você espera um aumento de visitantes. Preste atenção na correlação entre o aumento de visitantes e o tempo de resposta do servidor. Existem ferramentas de teste de carga que permitem simular várias visitas distribuídas e testar a capacidade do servidor.
Do lado do servidor, uma das métricas mais importantes é a medida TTFB , ou tempo até o primeiro byte . O TTFB mede a duração desde que o usuário faz uma solicitação HTTP até o primeiro byte da página recebida pelo navegador do cliente. O tempo de resposta do servidor afeta o desempenho de suas páginas da web. A auditoria TTFB falhará se o navegador aguardar mais de 600 ms para que o servidor responda. Observe que a maneira mais fácil de melhorar o TTFB é mudar de hospedagem compartilhada para hospedagem gerenciada , pois neste caso você terá um servidor dedicado apenas para o seu site.
Por exemplo, aqui está um teste de página feito com o Geekflare — uma ferramenta gratuita para verificar o desempenho do site . Como você pode ver, a ferramenta mostra que o TTFB para esta página excede 600ms, portanto deve ser melhorado.

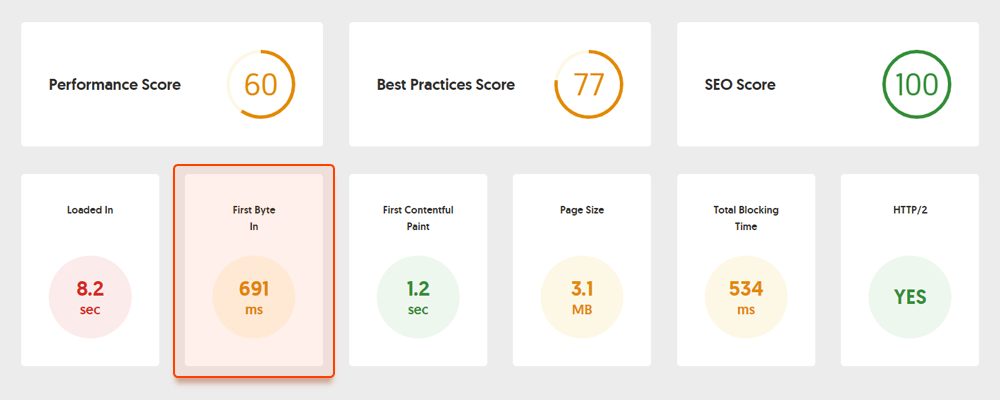
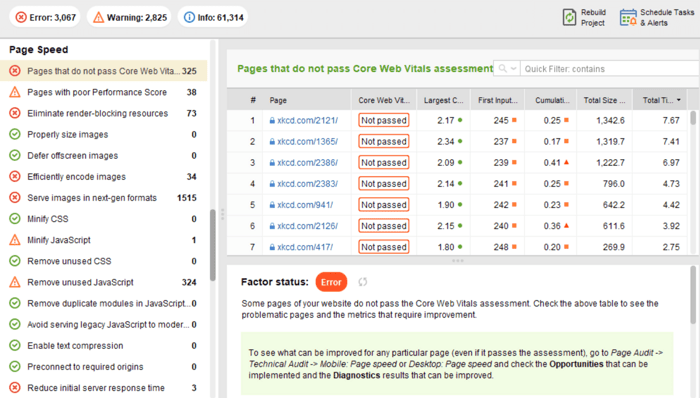
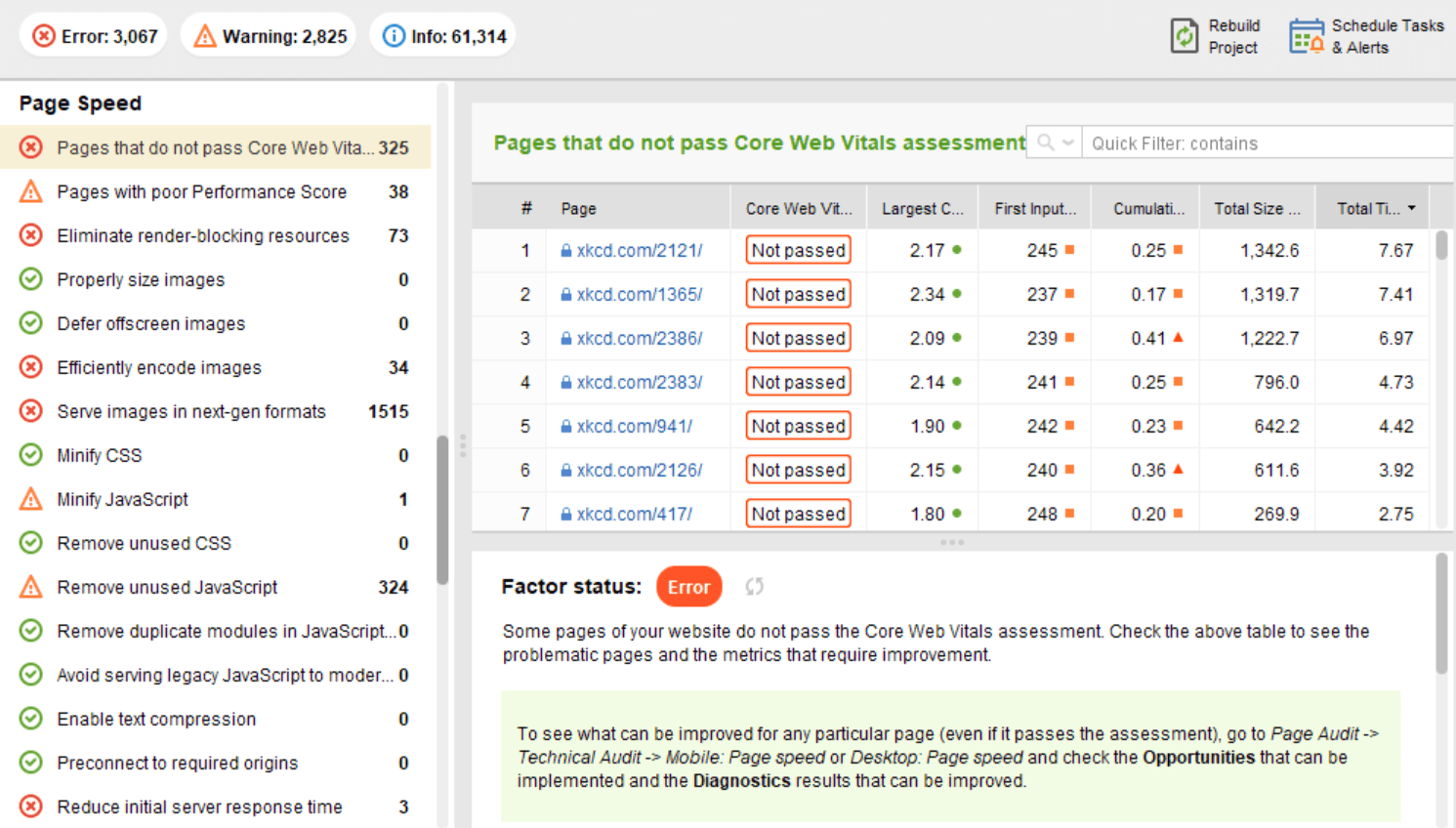
No lado do cliente, a velocidade da página não é algo fácil de medir, e o Google tem lutado com essa métrica há muito tempo. Por fim, chegou ao Core Web Vitals — três métricas projetadas para medir a velocidade percebida de qualquer página. Essas métricas são o maior problema de conteúdo (LCP), o primeiro atraso de entrada (FID) e o deslocamento cumulativo de layout (CLS). Eles mostram o desempenho de um site em relação à velocidade de carregamento, interatividade e estabilidade visual de suas páginas. Se precisar de mais detalhes sobre cada métrica CWV, confira nosso guia sobre Core Web Vitals .
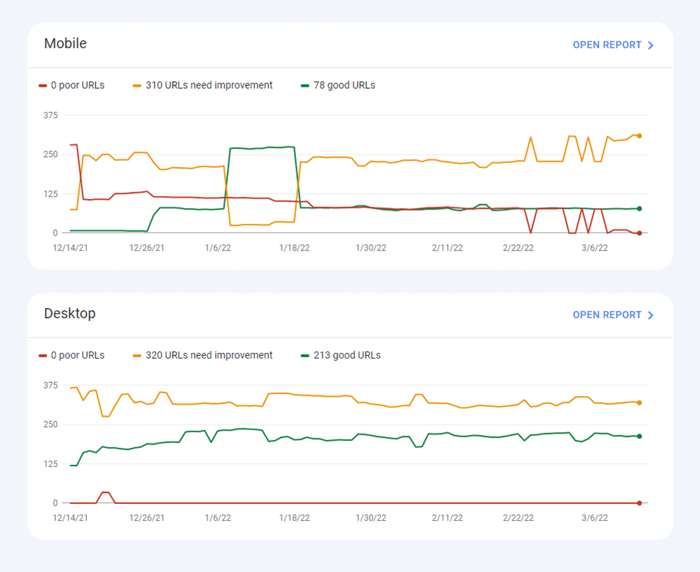
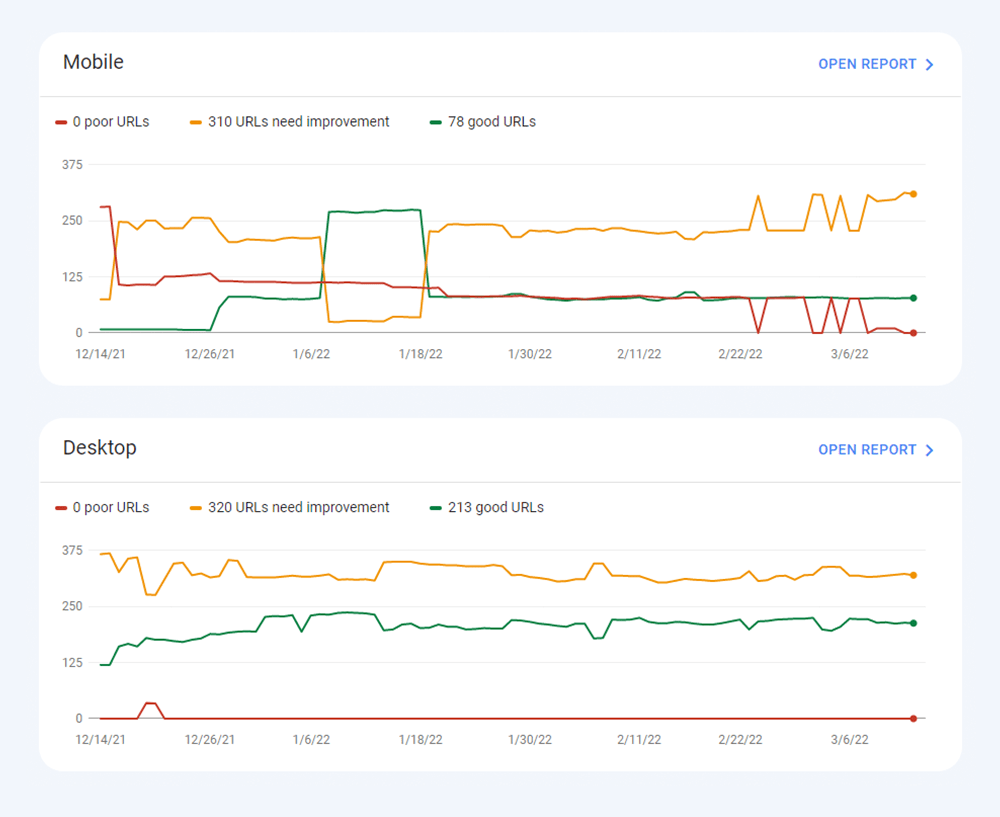
Recentemente, todas as três métricas do Core Web Vitalsforam adicionadas ao WebSite Auditor . Portanto, se você estiver usando essa ferramenta, poderá ver a pontuação de cada métrica, uma lista de problemas de velocidade de página em seu site e uma lista de páginas ou recursos afetados. Os dados são analisados através da chave da API PageSpeed que pode ser gerada gratuitamente.
O benefício de usar o WebSite Auditor para auditar o CWV é que você executa uma verificação em massa para todas as páginas de uma vez. Se você vir muitas páginas afetadas pelo mesmo problema, é provável que o problema esteja em todo o site e possa ser resolvido com uma única correção. Então, na verdade, não é tanto trabalho quanto parece. Tudo o que você precisa fazer é seguir as recomendações à direita e a velocidade da sua página aumentará rapidamente.
Hoje em dia, o número de buscadores móveis supera os de desktops. Em 2019, o Google implementou a indexação mobile-first , com o agente do smartphone rastreando sites à frente do Googlebot para desktop. Portanto, a compatibilidade com dispositivos móveis é de suma importância para as classificações orgânicas.
Notavelmente, existem diferentes abordagens para criar sites otimizados para dispositivos móveis:
Os prós e contras de cada solução são explicados em nosso guia detalhado sobre como tornar seu site compatível com dispositivos móveis . Além disso, você pode atualizar as páginas AMP — embora essa não seja uma tecnologia de ponta, ainda funciona bem para alguns tipos de páginas, por exemplo, para notícias.
A compatibilidade com dispositivos móveis continua sendo um fator vital para os sites que atendem a um URL para computadores e celulares. Além disso, alguns sinais de usabilidade, como a ausência de intersticiais intrusivos, continuam sendo um fator relevante para classificações de desktop e mobile. É por isso que os desenvolvedores web devem garantir a melhor experiência do usuário em todos os tipos de dispositivos.
O teste de compatibilidade com dispositivos móveis do Google inclui uma seleção de critérios de usabilidade, como configuração da janela de visualização, uso de plug-ins e tamanho do texto e elementos clicáveis. Também é importante lembrar que a compatibilidade com dispositivos móveis é avaliada com base na página, portanto, você precisa verificar a compatibilidade com dispositivos móveis de cada página de destino separadamente, uma de cada vez.
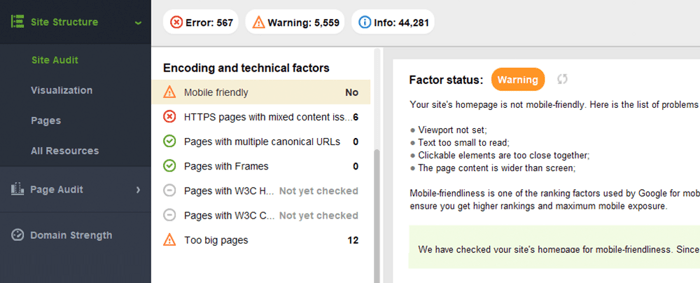
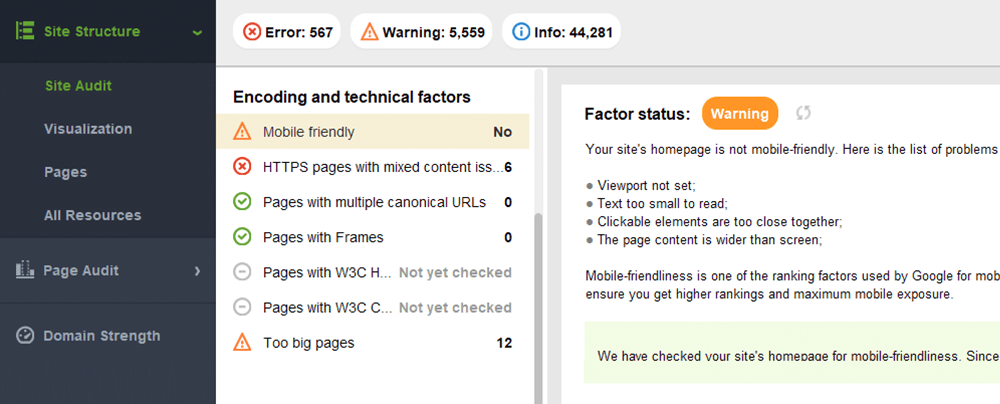
Para avaliar todo o seu site, mude para o Google Search Console. Vá para a guia Experiência e clique no relatório Usabilidade móvel para ver as estatísticas de todas as suas páginas. Abaixo do gráfico, você pode ver uma tabela com os problemas mais comuns que afetam suas páginas móveis. Ao clicar em qualquer problema abaixo do painel, você obterá uma lista de todos os URLs afetados.
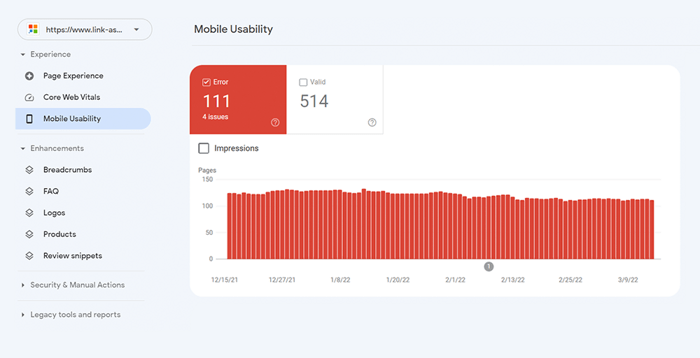

Os problemas típicos de compatibilidade com dispositivos móveis são:
O WebSite Auditor também analisa a compatibilidade com dispositivos móveis da página inicial e aponta para problemas na experiência do usuário móvel. Vá para Auditoria do local > Codificação e fatores técnicos . A ferramenta mostrará se o site é compatível com dispositivos móveis e listará os problemas, se houver:
Os sinais na página são fatores diretos de classificação e, não importa quão boa seja a solidez técnica do seu site, suas páginas nunca aparecerão na pesquisa sem a otimização adequada das tags HTML . Portanto, seu objetivo é verificar e organizar os títulos, as meta descrições e os cabeçalhos H1–H3 do seu conteúdo em todo o site.
O título e a meta descrição são usados pelos mecanismos de pesquisa para formar um snippet de resultado de pesquisa. Esse snippet é o que os usuários verão primeiro e, portanto , afeta bastante a taxa de cliques orgânicos .
Títulos, juntamente com parágrafos, listas com marcadores e outros elementos da estrutura da página da Web, ajudam a criar resultados de pesquisa avançados no Google. Além disso, eles melhoram naturalmente a legibilidade e a interação do usuário com a página, o que pode servir como um sinal positivo para os mecanismos de busca. Ficar de olho em:
Títulos, cabeçalhos e descrições duplicados em todo o site — corrija-os escrevendo títulos exclusivos para cada página.
Otimização dos títulos, títulos e descrições para os motores de busca (ou seja, o comprimento, palavras-chave, etc.)
Conteúdo fino — páginas com pouco conteúdo dificilmente serão ranqueadas e até podem prejudicar a autoridade do site (por causa do algoritmo Panda), portanto, certifique-se de que suas páginas cobrem o assunto em profundidade.
Otimização de imagens e arquivos multimídia — use formatos compatíveis com SEO, aplique carregamento lento, redimensione os arquivos para torná-los mais leves, etc. Para mais detalhes, leia nosso guia sobre otimização de imagens .
O WebSite Auditor pode te ajudar muito nessa tarefa. A seção Estrutura do site > Auditoria do site permite que você verifique os problemas de meta tags no site em massa. Se você precisar auditar o conteúdo da página individual com mais detalhes, vá para a seção Auditoria da página . O aplicativo também possui uma ferramenta de redação integrada Editor de conteúdo que oferece sugestões sobre como reescrever páginas com base em seus principais concorrentes SERP. Você pode editar as páginas em movimento ou baixar as recomendações como uma tarefa para redatores.
Para obter mais informações, leia nosso guia de otimização de SEO na página .
Os dados estruturados são uma marcação semântica que permite que os bots de pesquisa entendam melhor o conteúdo de uma página. Por exemplo, se sua página apresenta uma receita de torta de maçã, você pode usar dados estruturados para informar ao Google qual texto é o ingrediente, qual é o tempo de cozimento, contagem de calorias e assim por diante. O Google usa a marcação para criar rich snippets para suas páginas nas SERPs.
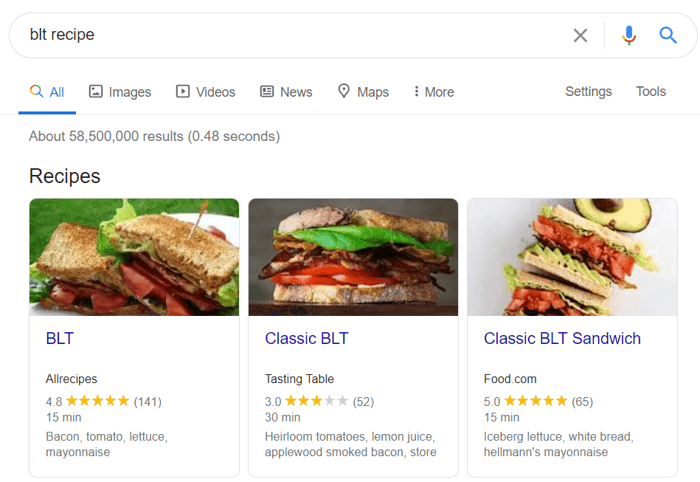
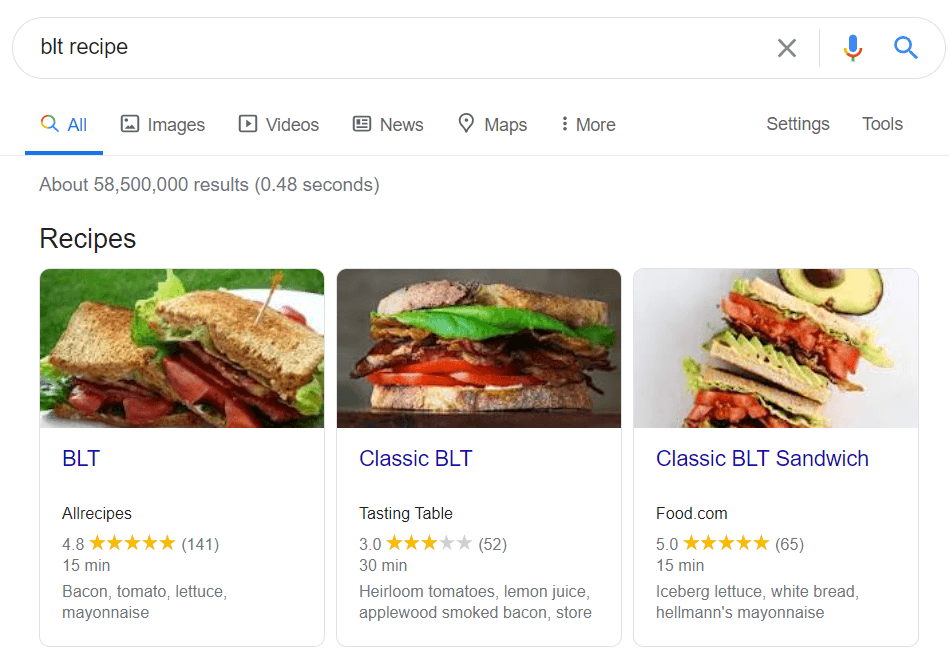
Existem dois padrões populares de dados estruturados, OpenGraph para belo compartilhamento em mídias sociais e Schema para mecanismos de pesquisa. As variantes da implementação de marcação são as seguintes: Microdata, RDFa e JSON-LD . Microdados e RDFa são adicionados ao HTML da página, enquanto JSON-LD é um código JavaScript. Este último é recomendado pelo Google.
Se o tipo de conteúdo da sua página for um dos mencionados abaixo, a marcação é especialmente recomendada:
Lembre-se de que a manipulação de dados estruturados pode causar penalidades dos mecanismos de pesquisa. Por exemplo, a marcação não deve descrever o conteúdo que está oculto para os usuários (ou seja, que não está localizado no HTML da página). Teste sua marcação com a Ferramenta de teste de dados estruturados antes da implementação.
Você também pode verificar sua marcação no Google Search Console na guia Aprimoramentos . O GSC exibirá as melhorias que você tentou implementar em seu site e informará se você conseguiu.
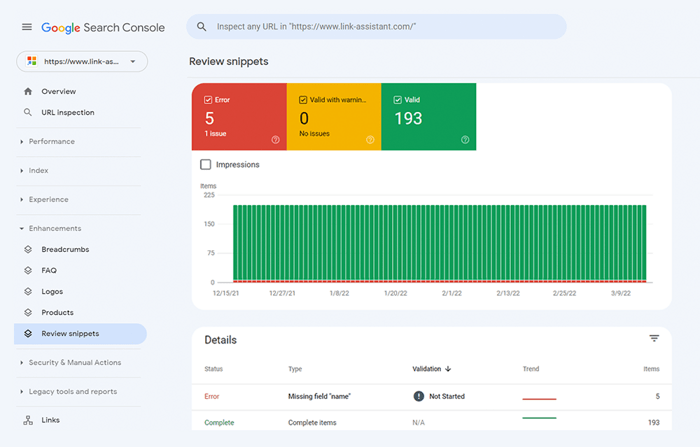
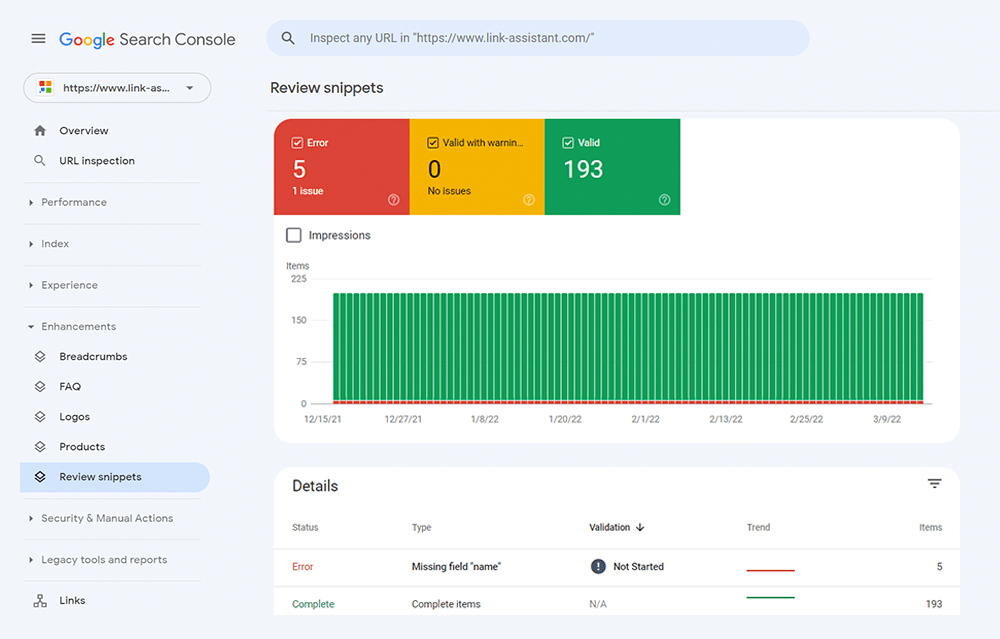
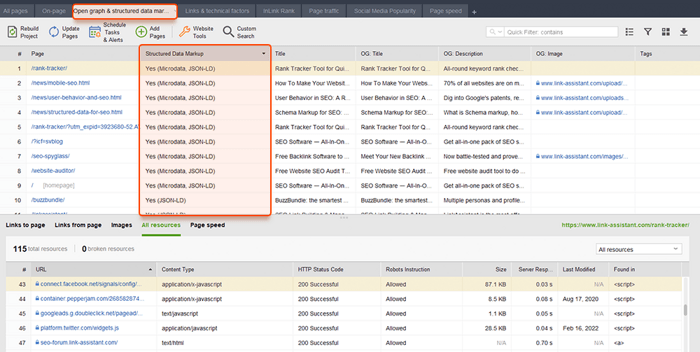
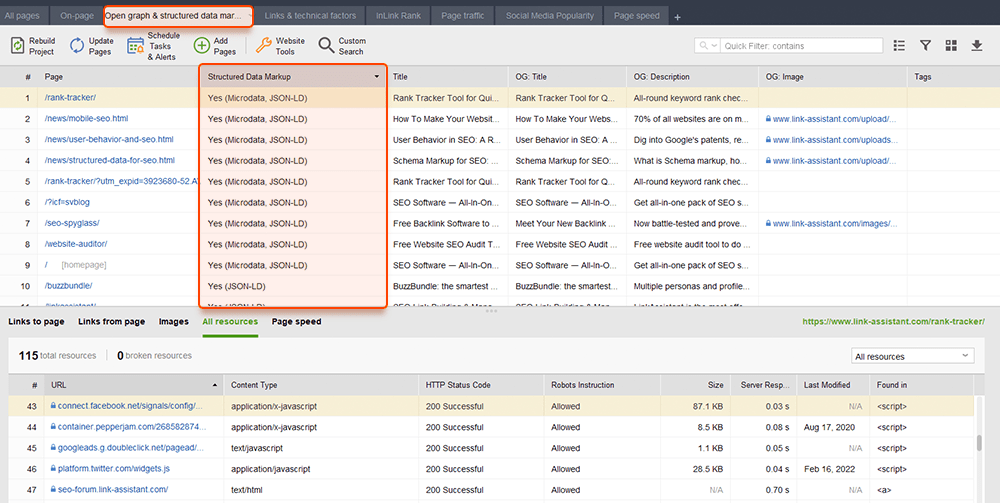
O WebSite Auditor também pode ajudá-lo aqui. A ferramenta pode revisar todas as suas páginas e mostrar a presença de dados estruturados em uma página, seu tipo, títulos, descrições e URLs de arquivos OpenGraph.
Se você ainda não implementou a marcação Schema, consulte este guia de SEO sobre dados estruturados . Observe que, se o seu site estiver usando um CMS, os dados estruturados podem ser implementados por padrão ou você pode adicioná-los instalando um plug-in (não exagere nos plug-ins).
Depois de auditar seu site e corrigir todos os problemas descobertos, você pode pedir ao Google para rastrear novamente suas páginas para que ele veja as alterações mais rapidamente.
No Google Search Console, envie o URL atualizado para a ferramenta de inspeção de URL e clique em Solicitar indexação . Você também pode aproveitar o recurso Testar URL ao vivo (anteriormente conhecido como Fetch as Google ) para ver sua página em seu formato atual e, em seguida, solicitar a indexação.
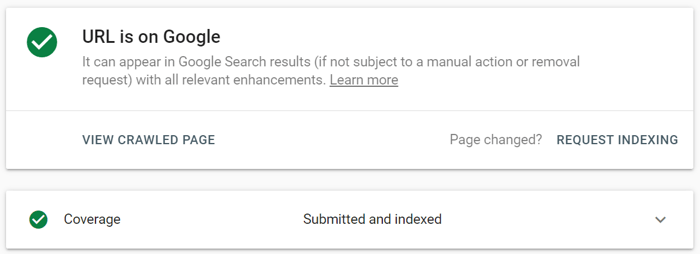
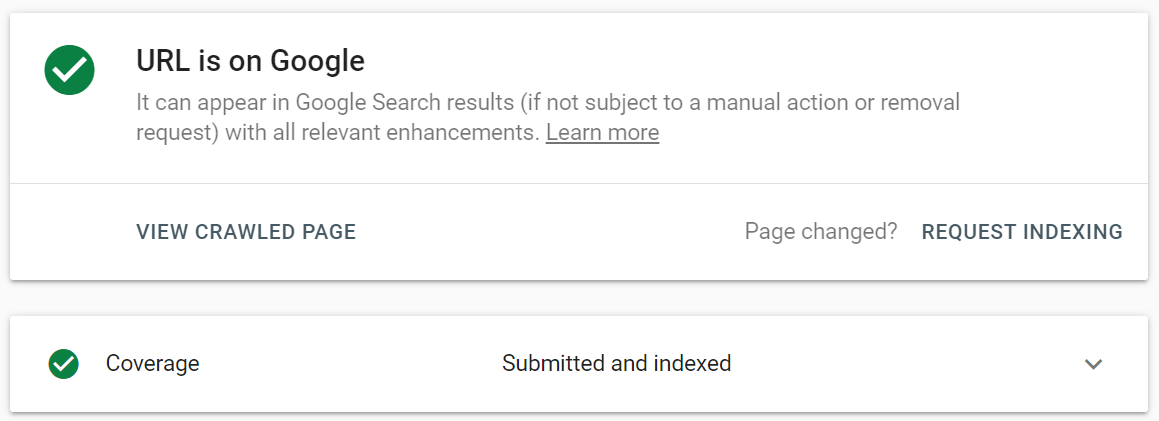
A ferramenta de inspeção de URL permite expandir o relatório para obter mais detalhes, testar URLs ativos e solicitar indexação.
Lembre-se de que você não precisa forçar um novo rastreamento sempre que alterar algo em seu site. Considere rastrear novamente se as alterações forem sérias: digamos, você mudou seu site de http para https, adicionou dados estruturados ou fez uma ótima otimização de conteúdo, lançou uma postagem de blog urgente que deseja aparecer no Google mais rapidamente etc. Observe que o Google tem um limite sobre o número de ações de novo rastreamento por mês, portanto, não abuse. Além do mais, a maioria dos CMS envia quaisquer alterações ao Google assim que você as faz, então você pode não se preocupar em rastrear novamente se usar um CMS (como Shopify ou WordPress).
O novo rastreamento pode levar de alguns dias a várias semanas, dependendo da frequência com que o rastreador visita as páginas. Solicitar um novo rastreamento várias vezes não acelerará o processo. Se você precisar rastrear novamente uma grande quantidade de URLs, envie um mapa do site em vez de adicionar manualmente cada URL à ferramenta de inspeção de URL.
A mesma opção está disponível no Bing Webmaster Tools. Basta escolher a seção Configurar meu site em seu painel e clicar em Enviar URLs . Preencha a URL que você precisa reindexar e o Bing irá rastreá-la em minutos. A ferramenta permite que os webmasters enviem até 10.000 URLs por dia para a maioria dos sites.
Muitas coisas podem acontecer na web, e a maioria delas provavelmente afetará sua classificação para melhor ou pior. É por isso que auditorias técnicas regulares do seu site devem ser uma parte essencial da sua estratégia de SEO.
Por exemplo, você pode automatizar auditorias técnicas de SEO no WebSite Auditor . Basta criar uma tarefa Rebuild Project e definir as configurações de agendamento (digamos, uma vez por mês) para que seu site seja rastreado automaticamente pela ferramenta e obtenha os dados atualizados.
Se você precisar compartilhar os resultados da auditoria com seus clientes ou colegas, escolha um dos modelos de relatórios de SEO para download do WebSite Auditor ou crie um personalizado.
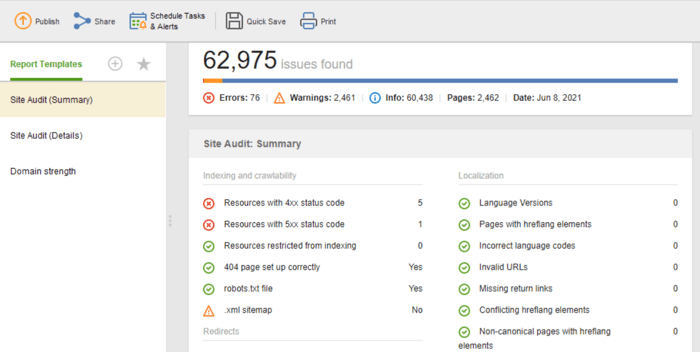
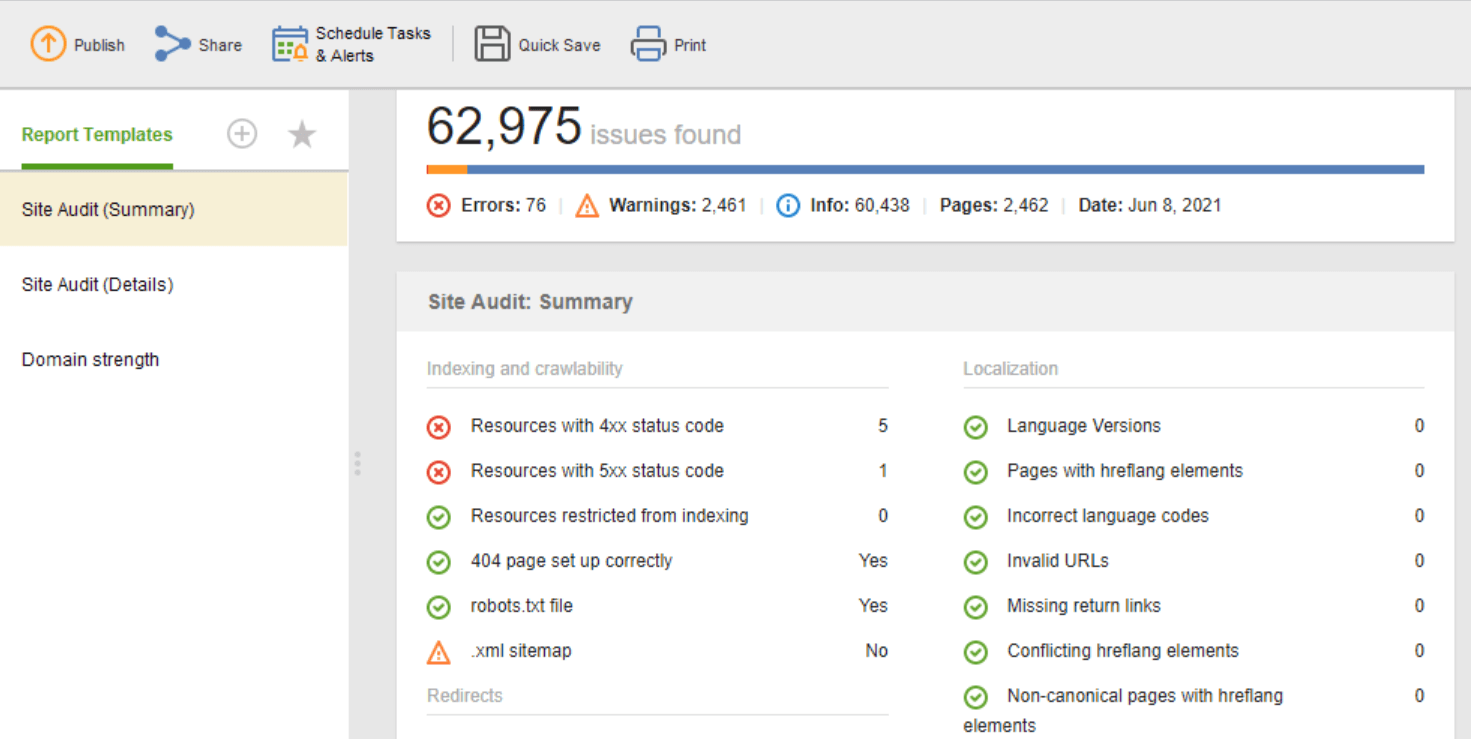
O modelo de Auditoria do Site (Resumo) é ótimo para os editores de sites verem o escopo do trabalho de otimização a ser feito. O modelo de Auditoria do Site (Detalhes) é mais explicativo, descrevendo cada problema e por que é importante corrigi-lo. No Website Auditor, você pode personalizar o relatório de auditoria do site para obter os dados que precisa monitorar regularmente (indexação, links quebrados, na página etc.). para os desenvolvedores para correções.
Além disso, você pode obter uma lista completa de problemas técnicos de SEO em qualquer site, reunidos automaticamente em um relatório de auditoria do site em nosso WebSite Auditor. Além disso, um relatório detalhado fornecerá explicações sobre cada problema e como corrigi-lo.
Estas são as etapas básicas de uma auditoria técnica regular do site. Espero que o guia descreva da melhor maneira quais ferramentas você precisa para realizar uma auditoria completa do site, quais aspectos de SEO devem ser observados e quais medidas preventivas devem ser tomadas para manter uma boa saúde de SEO do seu site.
O que é SEO técnico?
O SEO técnico lida com a otimização dos aspectos técnicos de um site que ajudam os bots de pesquisa a acessar suas páginas com mais eficiência. O SEO técnico abrange rastreamento, indexação, problemas do lado do servidor, experiência da página, geração de meta tags e estrutura do site.
Como você conduz uma auditoria técnica de SEO?
A auditoria técnica de SEO começa com a coleta de todos os URLs e a análise da estrutura geral do seu site. Em seguida, você verifica a acessibilidade das páginas, velocidade de carregamento, tags, detalhes na página etc. As ferramentas técnicas de auditoria de SEO variam de ferramentas gratuitas para webmasters a spiders de SEO, analisadores de arquivos de log etc.
Quando preciso auditar meu site?
As auditorias técnicas de SEO podem ter objetivos diferentes. Você pode querer auditar um site antes do lançamento ou durante o processo de otimização em andamento. Em outros casos, você pode estar implementando migrações de sites ou deseja suspender as sanções do Google. Para cada caso, o escopo e os métodos das auditorias técnicas serão diferentes.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |