123120
•
Lectura de 20 minutos
•


Esta lista de verificación describe todos los elementos básicos de una auditoría técnica del sitio, desde la teoría hasta la práctica.
Aprenderá qué archivos técnicos existen, por qué ocurren los problemas de SEO y cómo solucionarlos y prevenirlos en el futuro para que siempre esté a salvo de caídas repentinas en la clasificación .
En el camino, mostraré algunas herramientas de auditoría SEO, tanto populares como poco conocidas, para realizar una auditoría técnica del sitio web sin problemas.
La cantidad de pasos en su lista de verificación técnica de SEO dependerá de los objetivos y el tipo de sitios que vaya a examinar. Nuestro objetivo era hacer que esta lista de verificación fuera universal, cubriendo todos los pasos importantes de las auditorías técnicas de SEO.
1. Obtenga acceso a análisis del sitio y herramientas para webmasters
Para realizar una auditoría técnica de su sitio, necesitará herramientas de análisis y webmaster, y es excelente si ya las tiene configuradas en su sitio web. Con Google Analytics , Google Search Console , Bing Webmaster Tools y similares, ya tiene una gran cantidad de datos necesarios para una verificación básica del sitio .
2. Comprueba la seguridad del dominio
Si está auditando un sitio web existente que ha caído de las clasificaciones, en primer lugar, descarte la posibilidad de que el dominio esté sujeto a sanciones de motores de búsqueda.
Para ello, consulta Google Search Console. Si su sitio ha sido penalizado por la construcción de enlaces de sombrero negro, o ha sido pirateado, verá un aviso correspondiente en la pestaña Seguridad y acciones manuales de la Consola. Asegúrese de abordar la advertencia que ve en esta pestaña antes de continuar con una auditoría técnica de su sitio. Si necesita ayuda, consulte nuestra guía sobre cómo manejar penalizaciones manuales y algorítmicas .
Si está auditando un sitio nuevo que se lanzará, asegúrese de verificar que su dominio no esté comprometido. Para obtener más información, consulte nuestras guías sobre cómo elegir dominios vencidos y cómo no quedar atrapado en la zona de pruebas de Google durante el lanzamiento de un sitio web.
Ahora que hemos terminado con el trabajo preparatorio, pasemos a la auditoría técnica de SEO de su sitio web, paso a paso.
En términos generales, hay dos tipos de problemas de indexación. Una es cuando una URL no está indexada aunque se supone que debería estarlo. La otra es cuando se indexa una URL aunque no se supone que deba estarlo. Entonces, ¿cómo verificar el número de URL indexadas de su sitio?
Para ver cuánto de su sitio web ha llegado realmente al índice de búsqueda, consulte el informe Cobertura en Google Search Console . El informe muestra cuántas de sus páginas están indexadas actualmente, cuántas están excluidas y cuáles son algunos de los problemas de indexación en su sitio web.
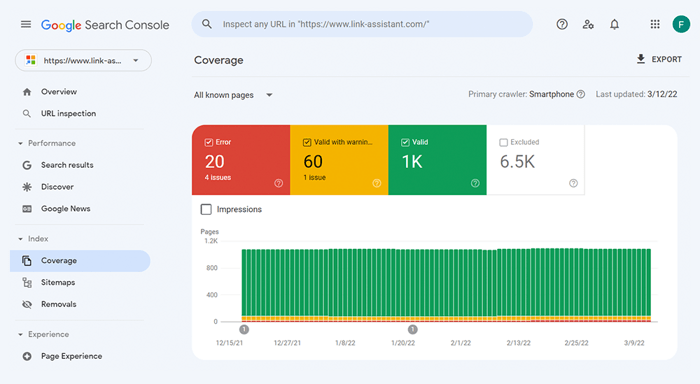

El primer tipo de problemas de indexación generalmente se marca como un error. Los errores de indexación ocurren cuando le pides a Google que indexe una página, pero está bloqueada. Por ejemplo, una página se agregó a un mapa del sitio, pero está marcada con la etiqueta noindex o está bloqueada con robots.txt.
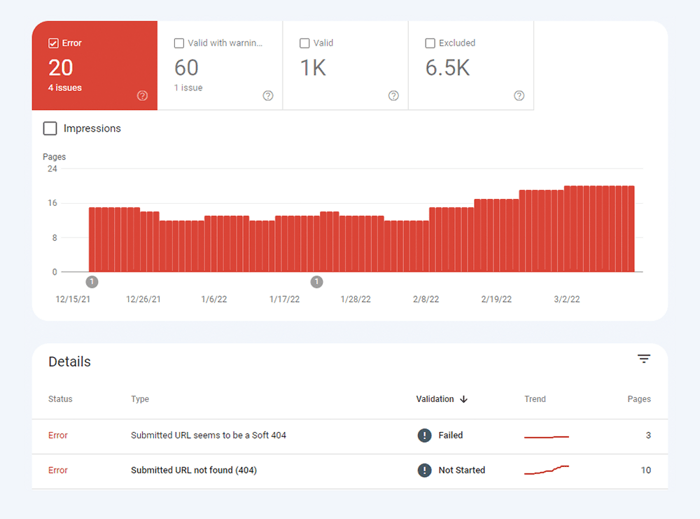
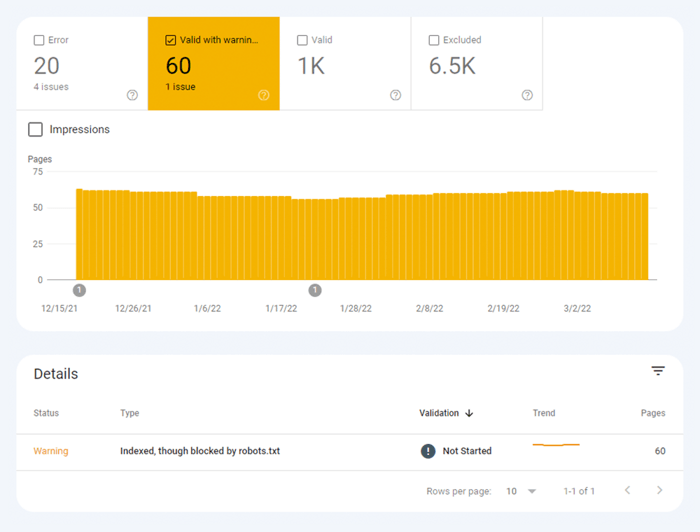
El otro tipo de problemas de indexación es cuando la página está indexada, pero Google no está seguro de que se suponía que debía indexarse. En Google Search Console, estas páginas suelen estar marcadas como Válidas con advertencias .

Para una página individual, ejecute la herramienta de inspección de URL en Search Console para revisar cómo la ve el robot de búsqueda de Google. Presione la pestaña respectiva o pegue la URL completa en la barra de búsqueda en la parte superior, y recuperará toda la información sobre la URL, de la misma forma en que fue escaneada la última vez por el robot de búsqueda.
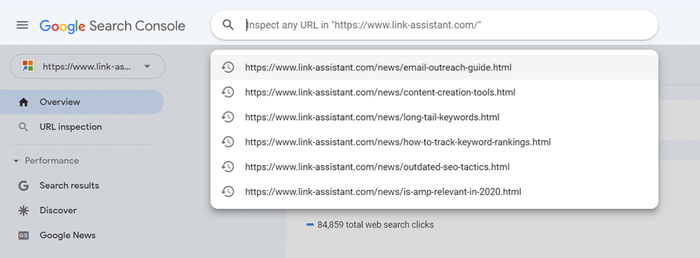
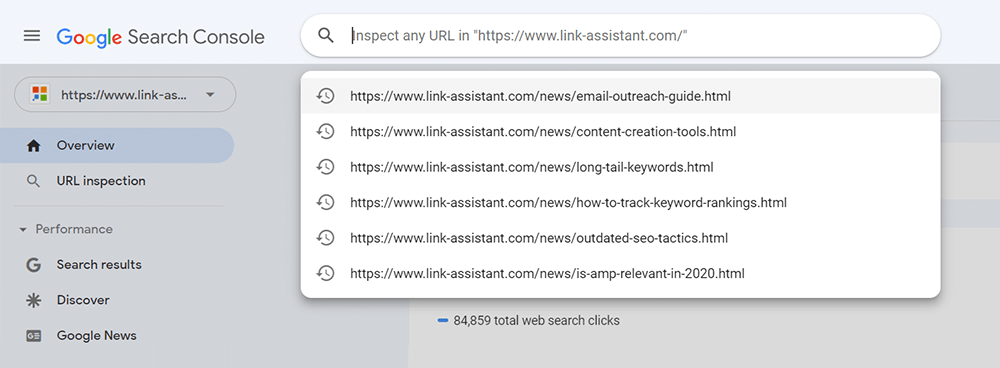
Luego, puede hacer clic en Test Live URL y ver aún más detalles sobre la página: el código de respuesta, las etiquetas HTML, la captura de pantalla de la primera pantalla, etc.
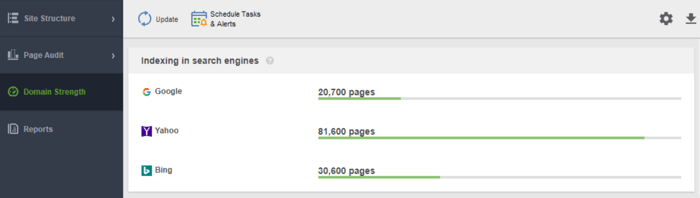
Otra herramienta para monitorear su indexación es WebSite Auditor . Inicie el software y pegue la URL de su sitio web para crear un nuevo proyecto y proceda a auditar su sitio. Una vez que termine el rastreo, verá todos los problemas y advertencias en el módulo Estructura del sitio de WebSite Auditor. En el informe de Intensidad del dominio , consulte la cantidad de páginas indexadas, no solo en Google, sino también en otros motores de búsqueda.
En WebSite Auditor, puede personalizar el escaneo de su sitio, eligiendo un bot de búsqueda diferente y especificando la configuración de rastreo. En las Preferencias del proyecto de la araña SEO, defina el bot del motor de búsqueda y un agente de usuario específico. Elija qué tipos de recursos desea examinar durante el rastreo (o, por el contrario, omita el análisis). También puede indicarle al rastreador que audite subdominios y sitios protegidos con contraseña, ignore parámetros de URL especiales y más.
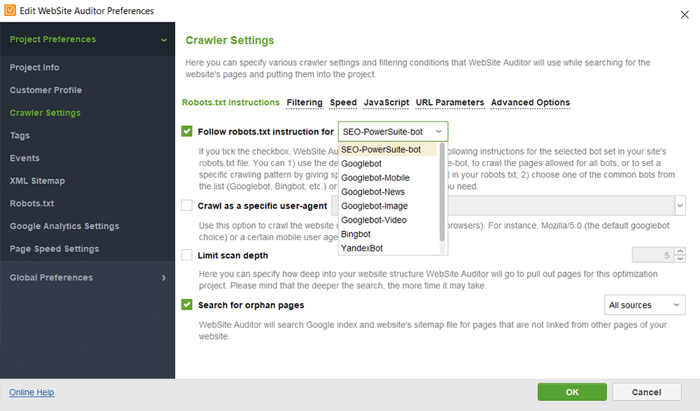
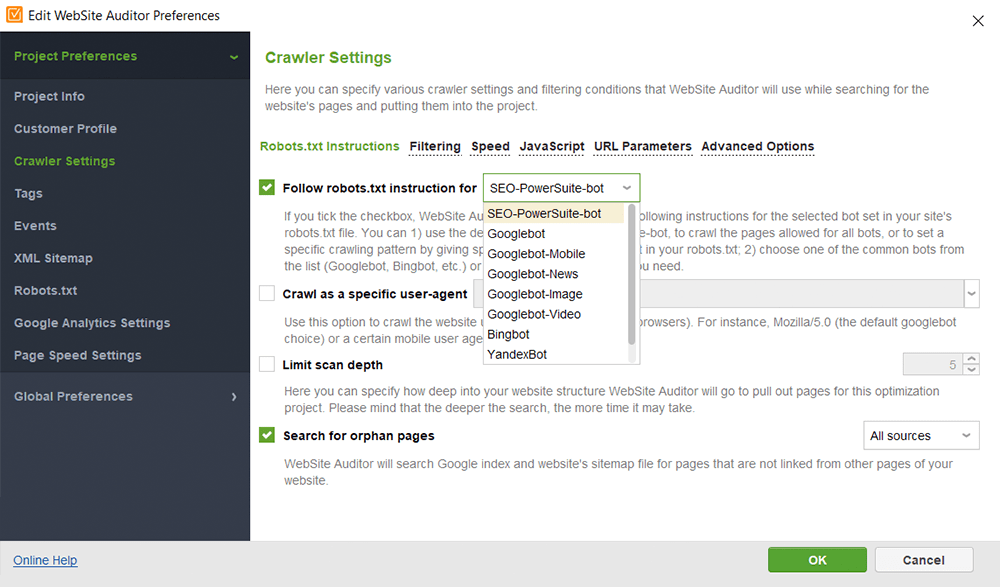
Mire este tutorial detallado en video para aprender a configurar su proyecto y analizar sitios web.
Cada vez que un usuario o un robot de búsqueda envía una solicitud al servidor que contiene los datos del sitio web, el archivo de registro registra una entrada al respecto. Esta es la información más correcta y válida sobre rastreadores y visitantes en su sitio, errores de indexación, desperdicio de presupuesto de rastreo, redireccionamientos temporales y más. Dado que puede ser difícil analizar los archivos de registro manualmente, necesitará un programa analizador de archivos de registro.
Cualquiera que sea la herramienta que decida utilizar, la cantidad de páginas indexadas debe estar cerca de la cantidad real de páginas en su sitio web.
Y ahora pasemos a cómo puede controlar el rastreo y la indexación de su sitio web.
De forma predeterminada, si no tiene ningún archivo técnico de SEO con controles de rastreo, los robots de búsqueda aún visitarán su sitio y lo rastrearán tal como está. Sin embargo, los archivos técnicos le permiten controlar cómo los robots de los motores de búsqueda rastrean e indexan sus páginas, por lo que son muy recomendables si su sitio es grande. A continuación se muestran algunas formas de modificar las reglas de indexación/rastreo:
Entonces, ¿cómo hacer que Google indexe su sitio más rápido usando cada uno de ellos?
Un Sitemap es un archivo técnico de SEO que enumera todas las páginas, videos y otros recursos en su sitio, así como las relaciones entre ellos. El archivo le dice a los motores de búsqueda cómo rastrear su sitio de manera más eficiente y juega un papel crucial en la accesibilidad de su sitio web.
Un sitio web necesita un Sitemap cuando:
Existen diferentes tipos de mapas de sitio que puede querer agregar a su sitio, dependiendo principalmente del tipo de sitio web que administre.
Un mapa del sitio HTML está destinado a lectores humanos y se encuentra en la parte inferior del sitio web. Sin embargo, tiene poco valor SEO. Un mapa del sitio HTML muestra la navegación principal a las personas y, por lo general, replica los enlaces en los encabezados del sitio. Mientras tanto, los mapas de sitio HTML se pueden usar para mejorar la accesibilidad de las páginas que no están incluidas en el menú principal.
A diferencia de los mapas de sitio HTML, los mapas de sitio XML son legibles por máquina gracias a una sintaxis especial. El mapa del sitio XML se encuentra en el dominio raíz, por ejemplo, https://www.link-assistant.com/sitemap.xml. Más adelante, analizaremos los requisitos y las etiquetas de marcado para crear un mapa del sitio XML correcto.
Este es un tipo alternativo de mapa del sitio disponible para los robots de los motores de búsqueda. El mapa del sitio TXT simplemente enumera todas las URL de los sitios web, sin proporcionar ninguna otra información sobre el contenido.
Este tipo de mapas de sitio es útil para grandes bibliotecas de imágenes e imágenes de gran tamaño para ayudarlos a clasificarse en la Búsqueda de imágenes de Google. En el mapa del sitio de la imagen, puede proporcionar información adicional sobre la imagen, como la ubicación geográfica, el título y la licencia. Puede listar hasta 1,000 imágenes para cada página.
Los sitemaps de video son necesarios para el contenido de video alojado en sus páginas para ayudarlo a clasificarse mejor en la Búsqueda de videos de Google. Aunque Google recomienda usar datos estructurados para videos, un mapa del sitio también puede ser beneficioso, especialmente cuando tiene mucho contenido de video en una página. En el mapa del sitio del video, puede agregar información adicional sobre el video, como títulos, descripción, duración, miniaturas e incluso si es apto para familias para la Búsqueda Segura.
Para los sitios web multilingües y multirregionales, los motores de búsqueda tienen varias formas de determinar qué versión de idioma publicar en una determinada ubicación. Los hreflangs son una de las varias formas de servir páginas localizadas, y puedes usar un mapa del sitio hreflang especial para eso. El mapa del sitio hreflang enumera la propia URL junto con su elemento secundario que indica el código de idioma/región de la página.
Si ejecuta un blog de noticias, agregar un mapa del sitio News-XML puede tener un impacto positivo en su clasificación en Google News. Aquí, agrega información sobre el título, el idioma y la fecha de publicación. Puede agregar hasta 1000 URL en el Sitemap de noticias. Las URL no deben tener más de dos días de antigüedad, después de lo cual puede eliminarlas, pero permanecerán en el índice durante 30 días.
Si su sitio web tiene una fuente RSS, puede enviar la URL de la fuente como un mapa del sitio. La mayoría del software de blog es capaz de crear un feed, pero esta información es útil solo para el descubrimiento rápido de URL recientes.
Hoy en día, los más utilizados son los mapas de sitio XML, así que repasemos brevemente los principales requisitos para la generación de mapas de sitio XML:
El mapa del sitio XML está codificado en UTF-8 y contiene etiquetas obligatorias para un elemento XML:
Un ejemplo simple de un mapa del sitio XML de una entrada se verá como
Hay etiquetas opcionales para indicar la prioridad y la frecuencia de los rastreos de páginas: <priority>, <changefreq> (actualmente, Google las ignora) y el valor de <lastmod> cuando es preciso (por ejemplo, en comparación con la última modificación en una página) .
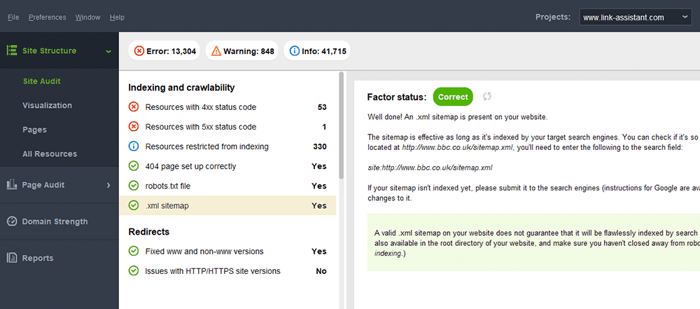
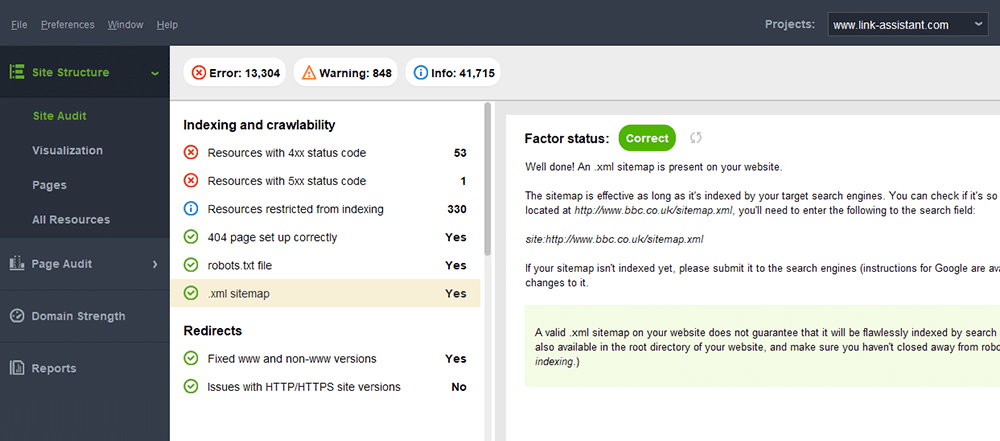
Un error típico con los mapas de sitio es no tener un mapa de sitio XML válido en un dominio grande. Puedes comprobar la presencia de un sitemap en el tuyo con WebSite Auditor . Encuentre los resultados en la sección Auditoría del sitio > Indexación y rastreabilidad .
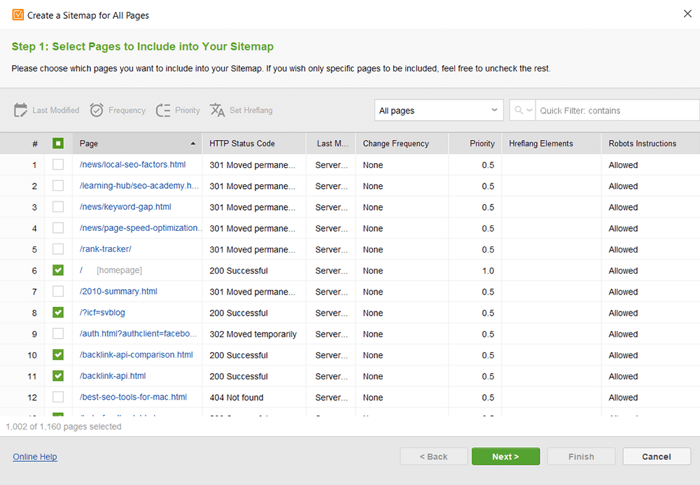
Si no tiene un mapa del sitio, realmente debería ir y crear uno ahora mismo. Puede generar rápidamente el mapa del sitio utilizando las Herramientas para sitios web de WebSite Auditor cuando cambia a la sección Páginas .
Y hágale saber a Google acerca de su mapa del sitio. Para hacer esto, puedes
El hecho es que tener un mapa del sitio en su sitio web no garantiza que todas sus páginas se indexen o incluso se rastreen . Hay algunos otros recursos técnicos de SEO, destinados a mejorar la indexación del sitio. Los revisaremos en los próximos pasos.
Un archivo robots.txt le dice a los motores de búsqueda a qué URL puede acceder el rastreador en su sitio. Este archivo sirve para evitar sobrecargar su servidor con solicitudes, administrando el tráfico de rastreo . El archivo se utiliza normalmente para:
Robots.txt se coloca en la raíz del dominio y cada subdominio debe tener un archivo independiente propio. Tenga en cuenta que no debe exceder los 500kB y debe responder con un código 200.
El archivo robots.txt también tiene su sintaxis con reglas Permitir y Disallow :
Diferentes motores de búsqueda pueden seguir las directivas de manera diferente. Por ejemplo, Google abandonó el uso de las directivas noindex, crawl-delay y nofollow de robots.txt. Además, hay rastreadores especiales como Googlebot-Image, Bingbot, Baiduspider-image, DuckDuckBot, AhrefsBot, etc. Por lo tanto, puede definir las reglas para todos los bots de búsqueda o reglas separadas solo para algunos de ellos.
Escribir instrucciones para robots.txt puede volverse bastante complicado, por lo que la regla aquí es tener menos instrucciones y más sentido común. A continuación se muestran algunos ejemplos de configuración de las instrucciones de robots.txt.
Acceso completo al dominio. En este caso, la regla de rechazo no se completa.
Bloqueo completo de un host.
La instrucción no permite rastrear todas las URL que comiencen con la carga después del nombre de dominio.
La instrucción no permite que Googlebot-News rastree todos los archivos gif en la carpeta de noticias.
Tenga en cuenta que si establece alguna instrucción general A para todos los motores de búsqueda y una instrucción específica B para un bot específico, entonces el bot específico puede seguir la instrucción específica y realizar todas las demás reglas generales establecidas de forma predeterminada para el bot, ya que no estará restringido por la regla A. Por ejemplo, como en la siguiente regla:
Aquí, AdsBot-Google-Mobile puede rastrear archivos en la carpeta tmp a pesar de las instrucciones con el comodín *.
Uno de los usos típicos de los archivos robots.txt es indicar dónde descansa el Sitemap. En este caso, no es necesario que mencione los agentes de usuario, ya que la regla se aplica a todos los rastreadores. El mapa del sitio debe comenzar con la S en mayúscula (recuerde que el archivo robots.txt distingue entre mayúsculas y minúsculas) y la URL debe ser absoluta (es decir, debe comenzar con el nombre de dominio completo).
Tenga en cuenta que si establece instrucciones contradictorias, los bots rastreadores darán prioridad a la instrucción más larga. Por ejemplo:
Aquí, el script /admin/js/global.js seguirá estando permitido para los rastreadores a pesar de la primera instrucción. Todos los demás archivos en la carpeta de administración aún no estarán permitidos.
Puede comprobar la disponibilidad del archivo robots.txt en WebSite Auditor. También le permite generar el archivo usando la herramienta de generación de robots.txt , y luego guardarlo o cargarlo directamente al sitio web a través de FTP.
Tenga en cuenta que el archivo robots.txt está disponible públicamente y puede exponer algunas páginas en lugar de ocultarlas. Si desea ocultar algunas carpetas privadas, protéjalas con contraseña.
Por último, el archivo robots.txt no garantiza que la página no permitida no se rastreará ni indexará . Es probable que bloquear a Google para que no rastree una página la elimine del índice de Google; sin embargo, el robot de búsqueda aún puede rastrear la página siguiendo algunos vínculos de retroceso que apuntan a ella. Entonces, aquí hay otra forma de bloquear el rastreo y la indexación de una página: meta robots.
Las etiquetas de meta robots son una excelente manera de instruir a los rastreadores sobre cómo tratar páginas individuales. Las etiquetas de meta robots se agregan a la sección <head> de su página HTML, por lo que las instrucciones se aplican a toda la página. Puede crear varias instrucciones combinando directivas de etiquetas meta de robots con comas o usando varias etiquetas meta. Puede verse así:
Puede especificar etiquetas de meta robots para varios rastreadores, por ejemplo
Google entiende etiquetas como:
Las etiquetas opuestas index / follow / archive anulan las directivas de prohibición correspondientes. Hay otras etiquetas que indican cómo puede aparecer la página en los resultados de búsqueda, como snippet / nosnippet / notranslate / nopagereadaloud / noimageindex .
Si usa algunas otras etiquetas válidas para otros motores de búsqueda pero desconocidas para Google, Googlebot simplemente las ignorará.
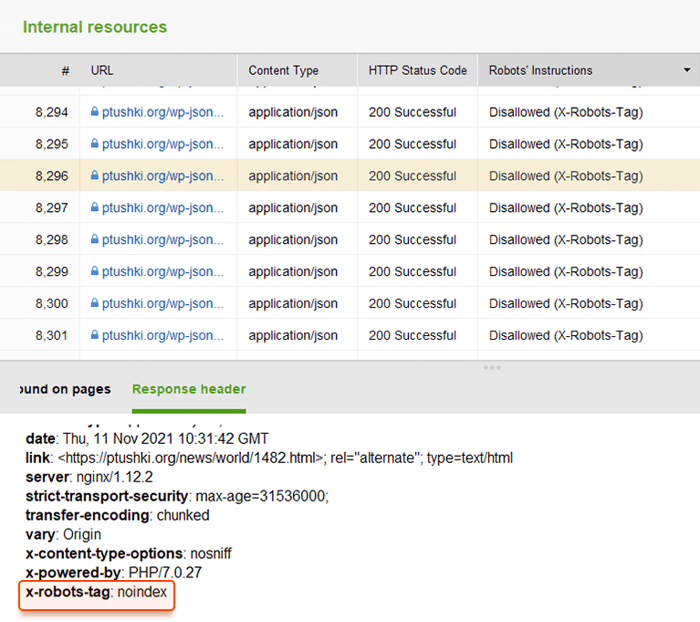
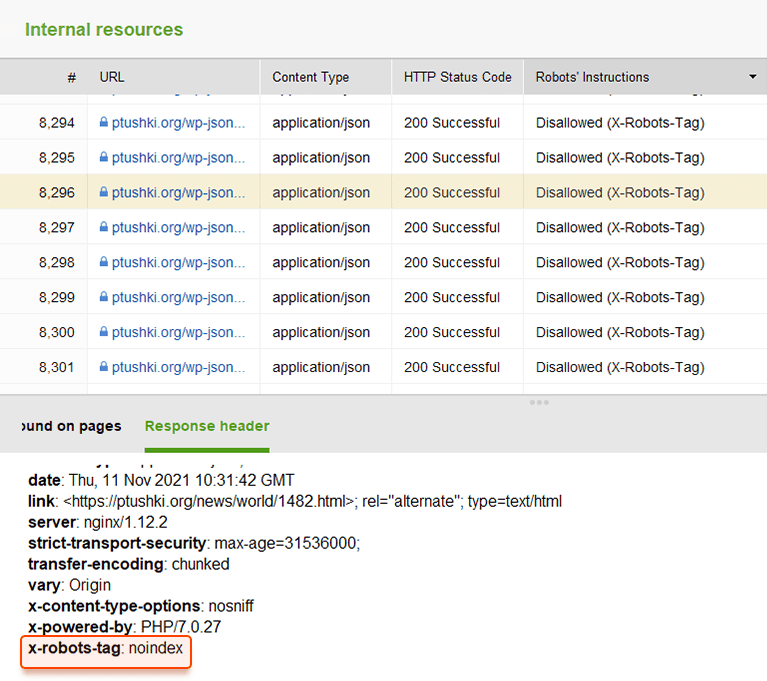
En lugar de etiquetas meta, puede usar un encabezado de respuesta para recursos que no sean HTML , como archivos PDF, de video y de imagen. Configure para devolver un encabezado X-Robots-Tag con un valor de noindex o none en su respuesta.
También puede usar una combinación de directivas para definir cómo se verá el fragmento en los resultados de búsqueda, por ejemplo, max-image-preview: [configuración] o nosnippet o max-snippet: [número] , etc.
Puede agregar la etiqueta X-Robots a las respuestas HTTP de un sitio web a través de los archivos de configuración del software del servidor web de su sitio. Sus directivas de rastreo se pueden aplicar globalmente en todo el sitio para todos los archivos, así como para archivos individuales si define sus nombres exactos.
Puede revisar rápidamente todas las instrucciones de los robots con WebSite Auditor . Vaya a Estructura del sitio > Todos los recursos > Recursos internos y verifique la columna Instrucciones de los robots . Aquí encontrará las páginas no permitidas y qué método se aplica, robots.txt, metaetiquetas o X-Robots-tag.
El servidor que aloja un sitio genera un código de estado HTTP cuando responde a una solicitud realizada por un cliente, navegador o rastreador. Si el servidor responde con un código de estado 2xx, el contenido recibido puede considerarse para la indexación. Otras respuestas de 3xx a 5xx indican que hay un problema con la representación de contenido. Estos son algunos significados de las respuestas del código de estado HTTP:
Las redirecciones 301 se utilizan cuando:
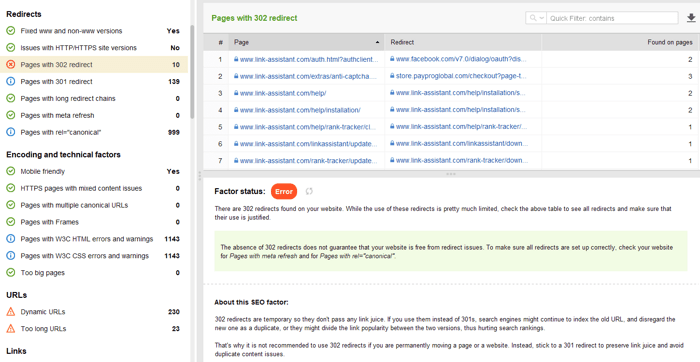
302 redirección temporal
La redirección 302 temporal debe usarse solo en páginas temporales. Por ejemplo, cuando está rediseñando una página o probando una nueva página y recopilando comentarios, pero no desea que la URL se pierda en las clasificaciones.
304 para comprobar el caché
El código de respuesta 304 es compatible con todos los motores de búsqueda más populares, como Google, Bing, Baidu, Yandex, etc. La configuración correcta del código de respuesta 304 ayuda al bot a comprender qué ha cambiado en la página desde su último rastreo. El bot envía una solicitud HTTP If-Modified-Since. Si no se detectan cambios desde la última fecha de rastreo, entonces el robot de búsqueda no necesita volver a rastrear la página. Para un usuario, significa que la página no se volverá a cargar por completo y su contenido se tomará del caché del navegador.
El código 304 también ayuda a:
Es importante verificar el almacenamiento en caché no solo del contenido de la página, sino también de los archivos estáticos, como imágenes o estilos CSS. Existen herramientas especiales, como esta , para comprobar el código de respuesta 304.


La mayoría de las veces, los problemas con el código de respuesta del servidor aparecen cuando los rastreadores siguen los enlaces internos y externos a las páginas eliminadas o movidas, y obtienen respuestas 3xx y 4xx.
Un error 404 muestra que una página no está disponible y el servidor envía el código de estado HTTP correcto al navegador: un 404 No encontrado.
Sin embargo, hay errores suaves 404 cuando el servidor envía el código de respuesta 200 OK, pero Google considera que debería ser 404. Esto puede suceder porque:
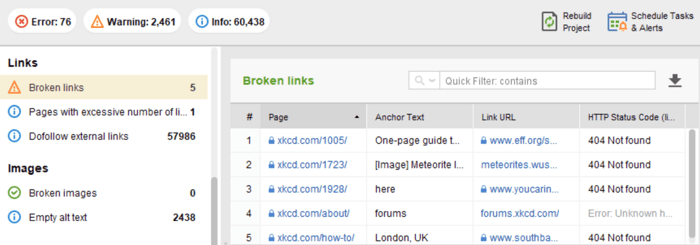
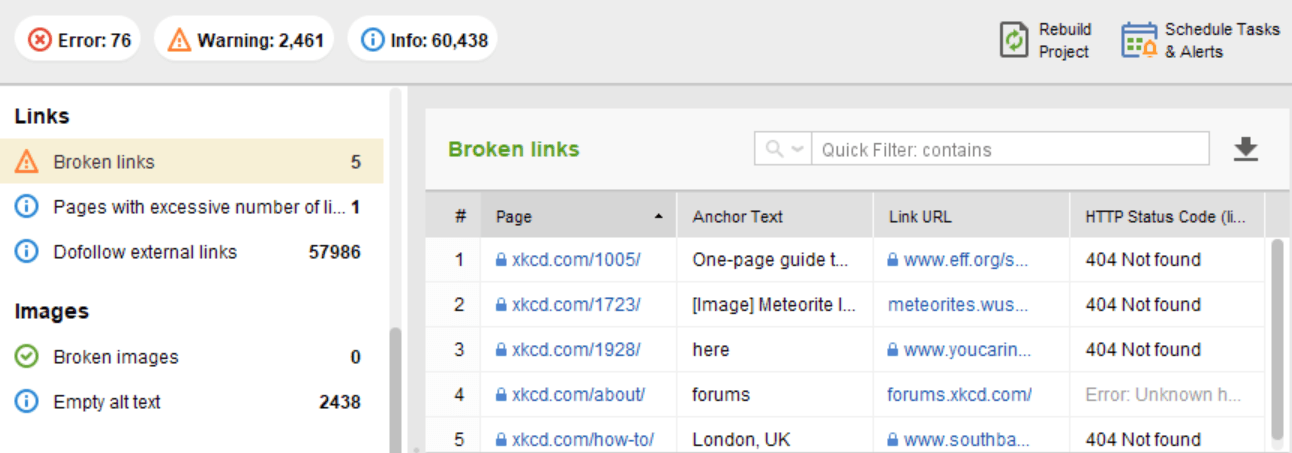
En el módulo Auditoría del sitio de WebSite Auditor, revise los recursos con código de respuesta 4xx, 5xx en la pestaña Indexación y rastreabilidad , y una sección separada para enlaces rotos en la pestaña Enlaces .
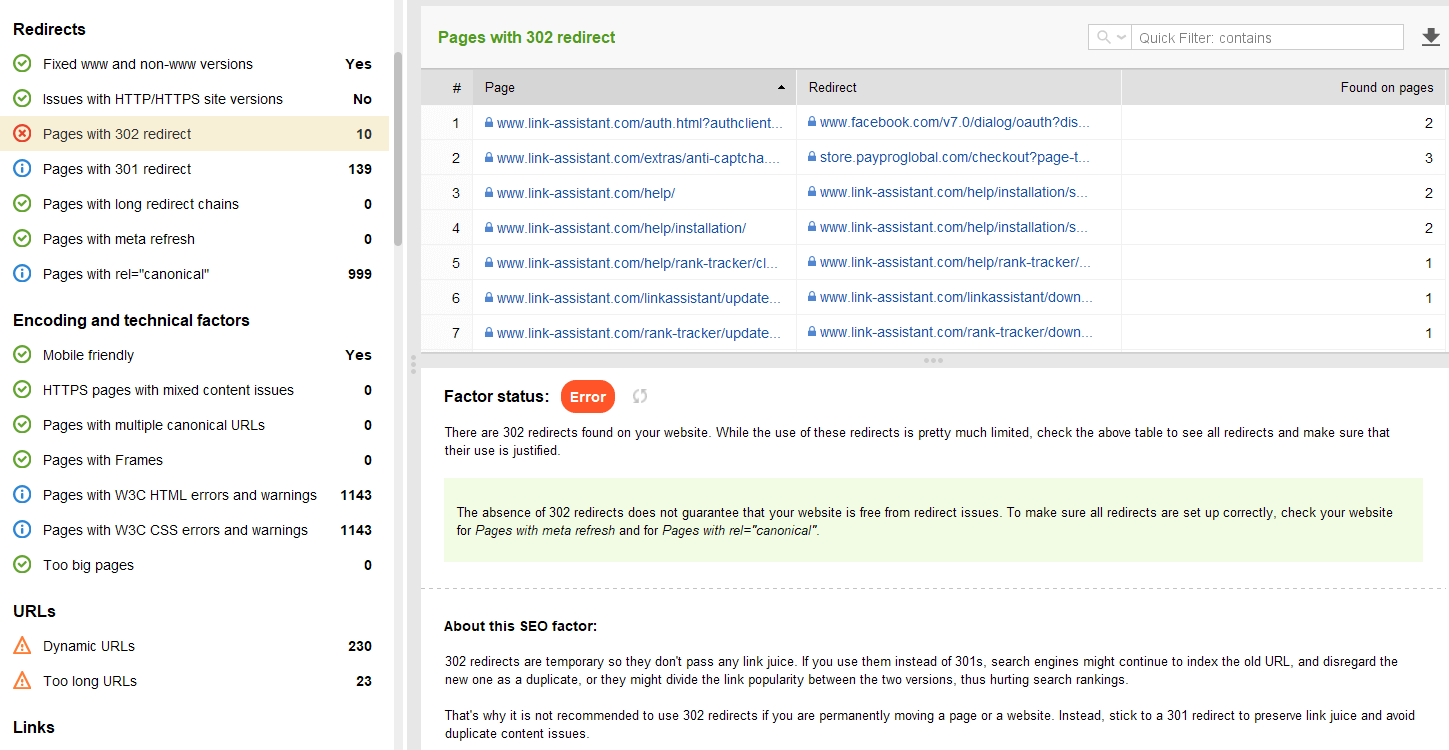
Algunos otros problemas comunes de redirección que involucran respuestas 301/302:
Puede revisar todas las páginas con redirecciones 301 y 302 en la sección Auditoría del sitio > Redirecciones de WebSite Auditor.
La duplicación puede convertirse en un problema grave para el rastreo de sitios web. Si Google encuentra URL duplicadas , decidirá cuál de ellas es una página principal y la rastreará con más frecuencia, mientras que los duplicados se rastrearán con menos frecuencia y es posible que no aparezcan en el índice de búsqueda. Una solución segura es indicar una de las páginas duplicadas como canónica, la principal. Esto se puede hacer con la ayuda del atributo rel=”canonical” , colocado en el código HTML de las páginas o en las respuestas del encabezado HTTP de un sitio.
Google utiliza páginas canónicas para evaluar su contenido y calidad y, en la mayoría de los casos, los resultados de búsqueda enlazan con páginas canónicas, a menos que los motores de búsqueda identifiquen claramente que alguna página no canónica es más adecuada para el usuario (por ejemplo, es un usuario móvil o un buscador en una ubicación específica).
Por lo tanto, la canonicalización de páginas relevantes ayuda a:
Los problemas duplicados significan contenido idéntico o similar que aparece en varias URL. Muy a menudo, las duplicaciones aparecen automáticamente debido al manejo de datos técnicos en un sitio web.
Algunos CMS pueden generar automáticamente problemas duplicados debido a una configuración incorrecta. Por ejemplo, se pueden generar múltiples URL en varios directorios de sitios web, y estos son duplicados:
La paginación también puede causar problemas de duplicación si se implementa incorrectamente. Por ejemplo, la URL de la página de categoría y la página 1 muestran el mismo contenido y, por lo tanto, se tratan como duplicados. Dicha combinación no debería existir, o la página de categoría debería marcarse como canónica.
Los resultados de clasificación y filtrado pueden representarse como duplicados. Esto sucede cuando su sitio crea URL dinámicas para consultas de búsqueda o filtrado. Obtendrá parámetros de URL que representan alias de cadenas de consulta o variables de URL, estas son la parte de una URL que sigue a un signo de interrogación.
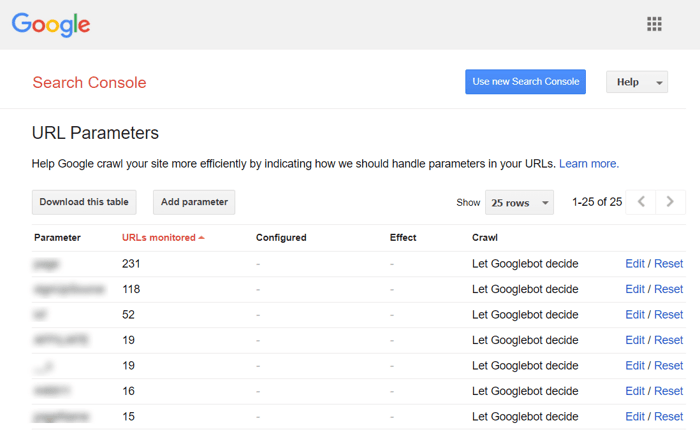
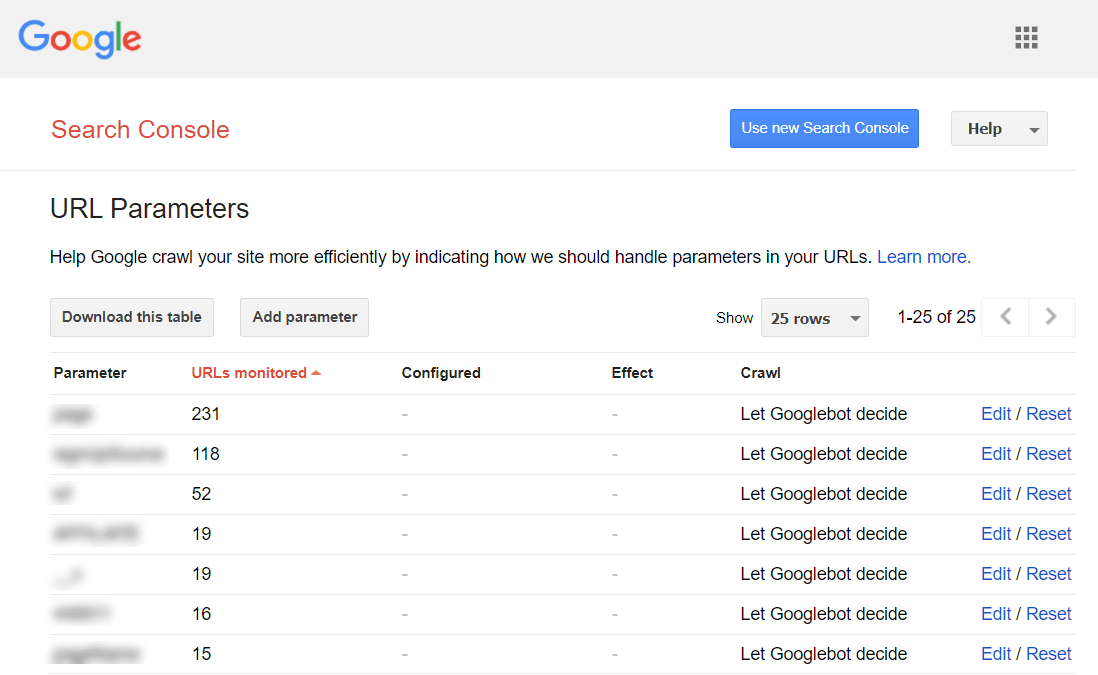
Para evitar que Google rastree un montón de páginas casi idénticas, configúrelo para ignorar ciertos parámetros de URL. Para hacerlo, inicie Google Search Console y vaya a Herramientas e informes heredados > Parámetros de URL . Haga clic en Editar a la derecha y dígale a Google qué parámetros ignorar: la regla se aplicará en todo el sitio. Tenga en cuenta que la Herramienta de parámetros es para usuarios avanzados, por lo que debe manejarse con precisión.
El problema de la duplicación suele ocurrir en los sitios web de comercio electrónico que permiten la navegación con filtros facetados , lo que reduce la búsqueda a tres, cuatro y más criterios. Este es un ejemplo de cómo configurar reglas de rastreo para un sitio de comercio electrónico: almacene las URL con resultados de búsqueda más largos y estrechos en una carpeta específica y desactívela mediante una regla de robots.txt.
Los problemas lógicos en la estructura del sitio web pueden causar duplicación. Este puede ser el caso cuando estás vendiendo productos y un producto pertenece a diferentes categorías.
En este caso, los productos deben ser accesibles a través de una sola URL. Las URL se consideran duplicados completos y dañarán el SEO. La URL debe asignarse a través de la configuración correcta del CMS, generando una única URL única para una página.
La duplicación parcial a menudo ocurre con WordPress CMS, por ejemplo, cuando se usan etiquetas. Si bien las etiquetas mejoran la búsqueda del sitio y la navegación del usuario, los sitios web de WP generan páginas de etiquetas que pueden coincidir con los nombres de las categorías y representar contenido similar de la vista previa del fragmento de artículo. La solución es usar las etiquetas de manera inteligente, agregando solo un número limitado de ellas. O puede agregar un meta robots noindex dofollow en las páginas de etiquetas.
Si elige publicar una versión móvil separada de su sitio web y, en particular, generar páginas AMP para la búsqueda móvil, es posible que tenga duplicados de este tipo.
Para indicar que una página es un duplicado, puede usar una etiqueta <link> en la sección de encabezado de su HTML. Para las versiones móviles, esta será la etiqueta de enlace con el valor rel=“alternativo”, así:
Lo mismo se aplica a las páginas AMP (que no son la tendencia, pero aún se pueden usar para generar resultados móviles). Consulte nuestra guía sobre la implementación de páginas AMP .
Hay varias formas de presentar contenido localizado . Cuando presenta contenido a diferentes variantes de idioma/configuración regional, y ha traducido solo el encabezado/pie de página/navegación del sitio, pero el contenido permanece en el mismo idioma, las URL se tratarán como duplicadas.
Configure la visualización de sitios multilingües y multirregionales con la ayuda de etiquetas hreflang , agregando los códigos de región/idioma admitidos en el HTML, los códigos de respuesta HTTP o en el mapa del sitio.
Los sitios web suelen estar disponibles con y sin "www" en el nombre de dominio. Este problema es bastante común, y las personas se vinculan a versiones con www y sin www. Arreglar esto te ayudará a evitar que los motores de búsqueda indexen dos versiones de un sitio web. Si bien dicha indexación no causará una penalización, establecer una versión como prioridad es una buena práctica.
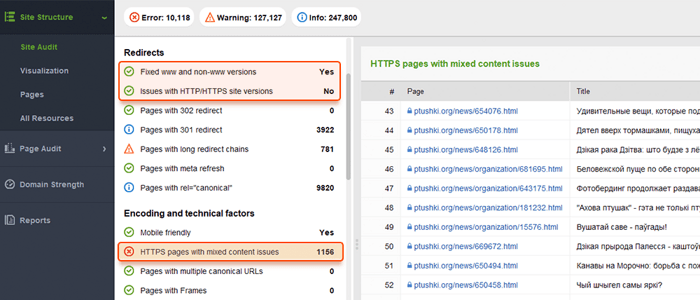

Google prefiere HTTPS a HTTP, ya que el cifrado seguro es muy recomendable para la mayoría de los sitios web (especialmente cuando se realizan transacciones y se recopila información confidencial del usuario). A veces, los webmasters se enfrentan a problemas técnicos al instalar certificados SSL y configurar las versiones HTTP/HTTPS del sitio web. Si un sitio tiene un certificado SSL no válido (no confiable o caducado), la mayoría de los navegadores web evitarán que los usuarios visiten su sitio notificándoles una "conexión insegura".
Si las versiones HTTP y HTTPS de su sitio web no están configuradas correctamente, los motores de búsqueda pueden indexar ambas y causar problemas de contenido duplicado que pueden socavar la clasificación de su sitio web.
Si su sitio ya usa HTTPS (ya sea parcial o totalmente), es importante eliminar los problemas comunes de HTTPS como parte de la auditoría de su sitio de SEO. En particular, recuerda comprobar si hay contenido mixto en la sección Auditoría del sitio > Codificación y factores técnicos .
Los problemas de contenido mixto surgen cuando una página segura carga parte de su contenido (imágenes, videos, scripts, archivos CSS) a través de una conexión HTTP no segura. Esto debilita la seguridad y puede impedir que los navegadores carguen el contenido no seguro o incluso la página completa.
Para evitar estos problemas, puede configurar y ver la versión principal con www o sin www de su sitio en el archivo .htaccess . Además, establezca el dominio preferido en Google Search Console e indique las páginas HTTPS como canónicas.
Una vez que tenga Website Auditor control total del contenido de su propio sitio web, asegúrese de que no haya títulos , encabezados, descripciones, imágenes, etc. duplicados. panel. Es probable que las páginas con títulos duplicados y etiquetas de meta descripción también tengan un contenido casi idéntico.
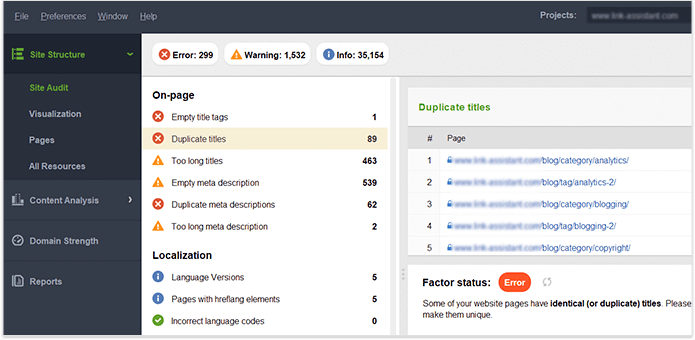
Resumamos cómo descubrimos y solucionamos los problemas de indexación. Si siguió todos los consejos anteriores, pero algunas de sus páginas aún no están en el índice, aquí hay un resumen de por qué podría haber sucedido esto:
¿Por qué una página está indexada, aunque no debería estarlo?
Tenga en cuenta que bloquear una página en el archivo robots.txt y eliminarla del mapa del sitio no garantiza que no se indexará. Puede consultar nuestra guía detallada sobre cómo restringir que las páginas se indexen correctamente.
La arquitectura del sitio lógica y poco profunda es importante tanto para los usuarios como para los robots de los motores de búsqueda. Una estructura de sitio bien planificada también juega un papel importante en su clasificación porque:
Cuando revise la estructura de sus sitios y los enlaces internos, preste atención a los siguientes elementos.
Las URL optimizadas son cruciales por dos razones. En primer lugar, es un factor de clasificación menor para Google. En segundo lugar, los usuarios pueden confundirse con URL demasiado largas o torpes. Pensando en la estructura de su URL, siga las siguientes prácticas recomendadas :
Puede comprobar sus URL en la sección Auditoría del sitio > URL de WebSite Auditor.
Hay muchos tipos de enlaces, algunos de ellos son más o menos beneficiosos para el SEO de su sitio web. Por ejemplo, los enlaces contextuales dofollow transmiten el jugo del enlace y sirven como un indicador adicional para los motores de búsqueda de qué se trata el enlace. Se considera que los enlaces son de alta calidad cuando (y esto se refiere tanto a enlaces internos como externos):
Los enlaces de navegación en los encabezados y las barras laterales también son importantes para el SEO del sitio web, ya que ayudan a los usuarios y a los motores de búsqueda a navegar por las páginas.
Otros enlaces pueden no tener valor de clasificación o incluso dañar la autoridad del sitio. Por ejemplo, enlaces salientes masivos en todo el sitio en plantillas (que las plantillas gratuitas de WP solían tener mucho). Esta guía sobre los tipos de enlaces en SEO explica cómo crear enlaces valiosos de la manera correcta.
Puede utilizar la herramienta WebSite Auditor para examinar a fondo los enlaces internos y su calidad.
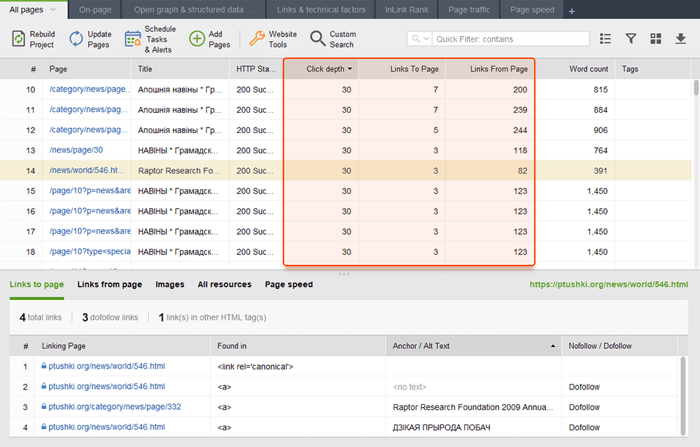
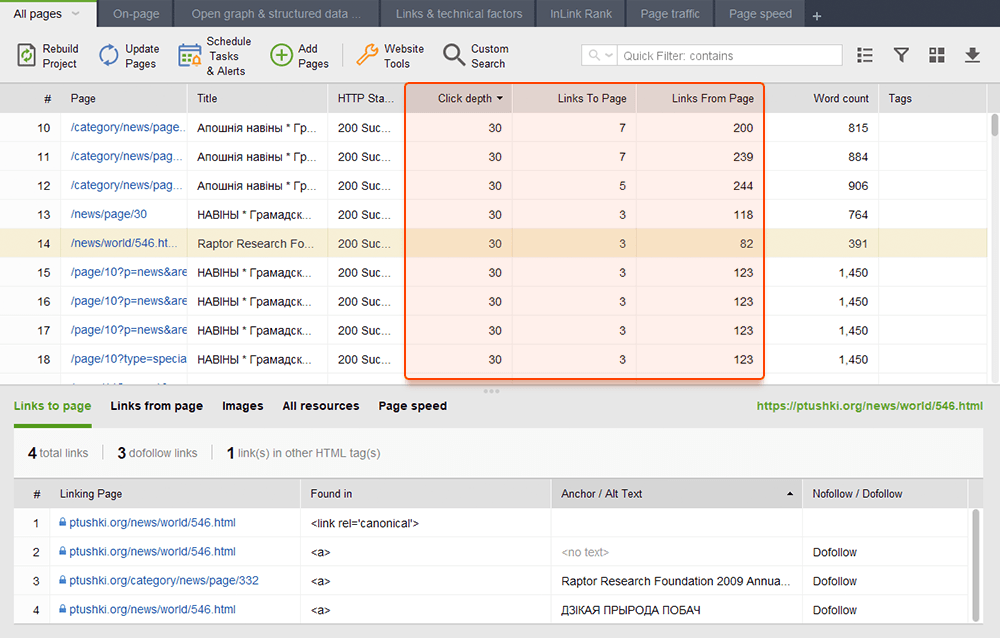
Las páginas huérfanas son páginas desvinculadas que pasan desapercibidas y finalmente pueden caer fuera del índice de búsqueda. Para encontrar páginas huérfanas, vaya a Auditoría del sitio > Visualización y revise el mapa del sitio visual . Aquí verá fácilmente todas las páginas no vinculadas y las largas cadenas de redireccionamiento (las redirecciones 301 y 302 están marcadas en azul).
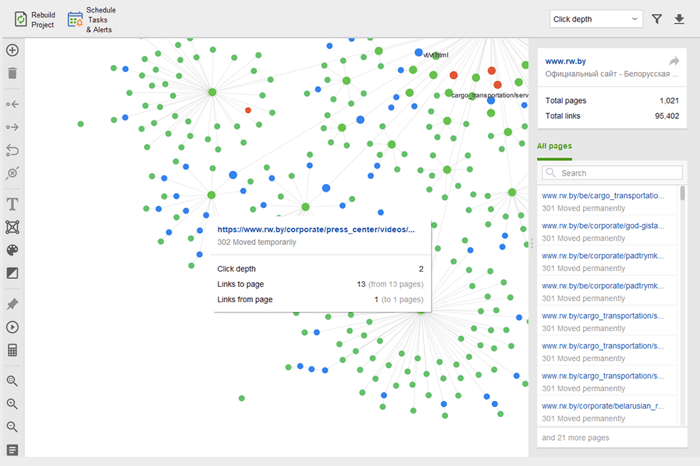
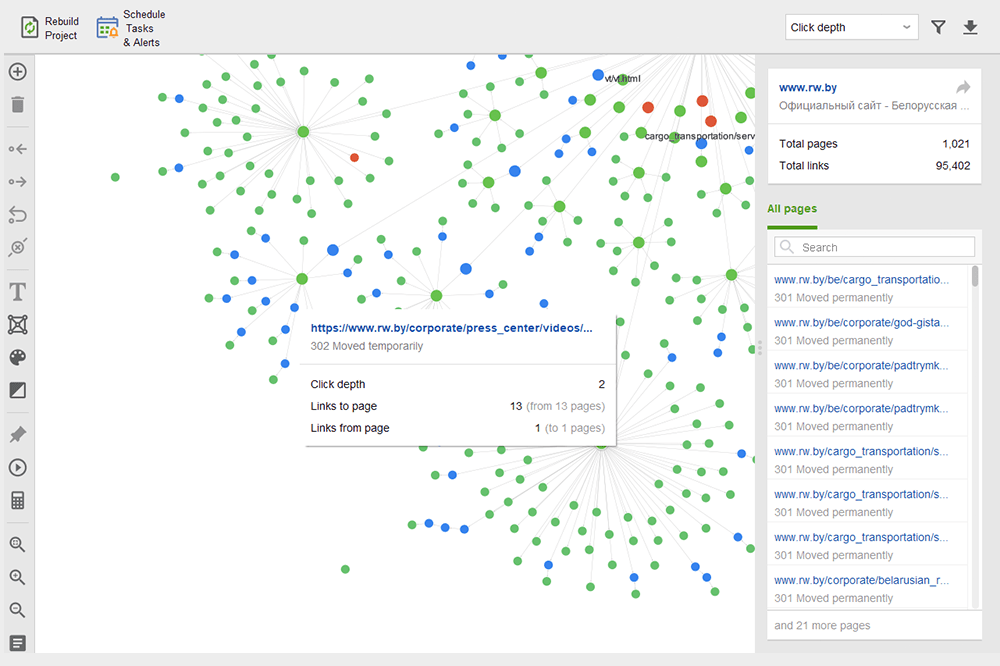
Puede obtener una visión general de toda la estructura del sitio, examinar el peso de sus páginas principales, comprobando las vistas de página (integradas desde Google Analytics), el PageRank y el contenido de enlaces que obtienen de los enlaces entrantes y salientes. Puede agregar y eliminar enlaces y reconstruir el proyecto, recalculando la prominencia de cada página.
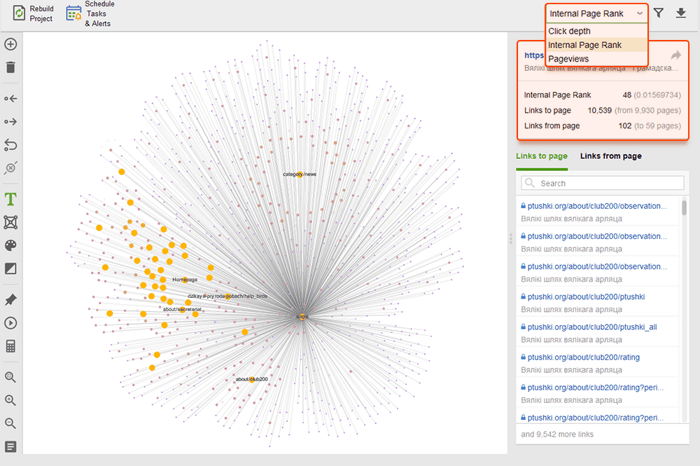
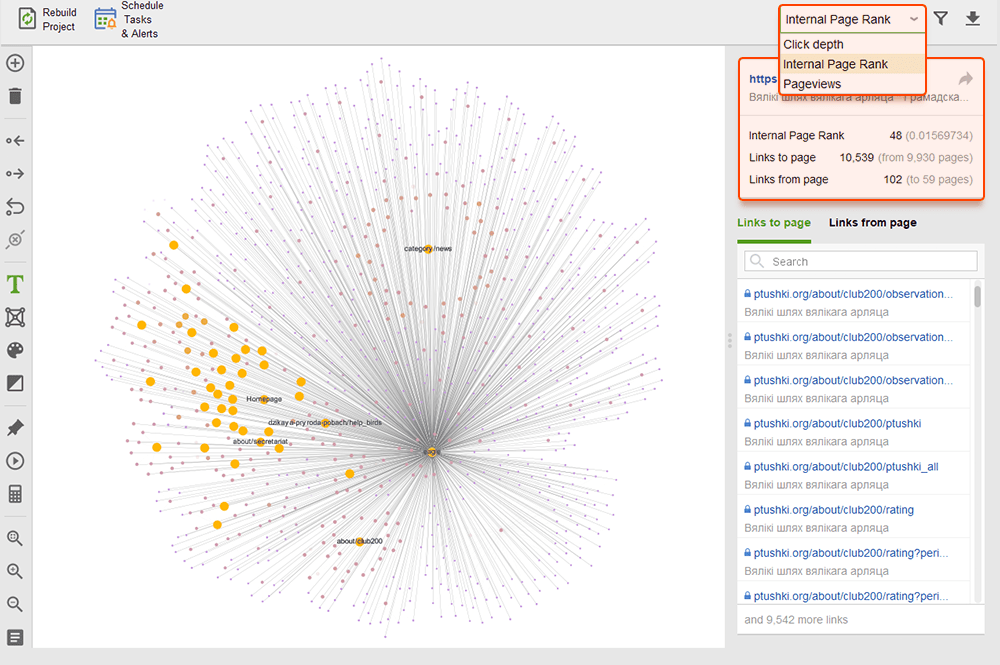
Mientras audita sus enlaces internos, verifique la profundidad de los clics. Asegúrese de que las páginas importantes de su sitio no estén a más de tres clics de distancia de la página de inicio. Otro lugar para revisar la profundidad de clics en WebSite Auditor es ir a Estructura del sitio > Páginas . Luego ordene las URL por profundidad de clic en orden descendente haciendo clic en el encabezado de la columna dos veces.
La paginación de las páginas del blog es necesaria para que los motores de búsqueda las detecten, aunque aumenta la profundidad de los clics. Use una estructura simple junto con una búsqueda procesable en el sitio para que sea más fácil para los usuarios encontrar cualquier recurso.
Para obtener más detalles, consulte nuestra guía detallada para la paginación compatible con SEO .
Breadcrumb es un tipo de marcado que ayuda a crear resultados enriquecidos en la búsqueda, mostrando la ruta a la página dentro de la estructura de su sitio. Las migas de pan aparecen gracias a la vinculación adecuada, con anclajes optimizados en los enlaces internos y datos estructurados implementados correctamente (nos detendremos en esto último unos párrafos más abajo).

De hecho, los enlaces internos pueden afectar la clasificación de su sitio y la forma en que se presenta cada página en la búsqueda. Para saber más, consulta nuestra guía SEO de estrategias de enlaces internos .
La velocidad del sitio y la experiencia de la página impactan directamente en las posiciones orgánicas. La respuesta del servidor puede convertirse en un problema para el rendimiento del sitio cuando demasiados usuarios lo visitan a la vez. En cuanto a la velocidad de la página, Google espera que el contenido de la página más grande se cargue dentro de la ventana gráfica en 2,5 segundos o menos y, finalmente, recompensa las páginas que ofrecen mejores resultados. Es por eso que la velocidad debe probarse y mejorarse tanto en el lado del servidor como en el del cliente.
Las pruebas de velocidad de carga descubren problemas del lado del servidor cuando demasiados usuarios visitan un sitio web simultáneamente. Aunque el problema está relacionado con la configuración del servidor, los SEO deben tenerlo en cuenta antes de planificar campañas publicitarias y de SEO a gran escala. Pruebe la capacidad máxima de carga de su servidor si espera un aumento en el número de visitantes. Preste atención a la correlación entre el aumento de visitantes y el tiempo de respuesta del servidor. Hay herramientas de prueba de carga que le permiten simular numerosas visitas distribuidas y probar la capacidad de su servidor.
Del lado del servidor, una de las métricas más importantes es la medición TTFB , o tiempo hasta el primer byte . TTFB mide la duración desde que el usuario realiza una solicitud HTTP hasta que el navegador del cliente recibe el primer byte de la página. El tiempo de respuesta del servidor afecta el rendimiento de sus páginas web. La auditoría TTFB falla si el navegador espera más de 600 ms para que el servidor responda. Tenga en cuenta que la forma más fácil de mejorar TTFB es cambiar de alojamiento compartido a alojamiento administrado , ya que en este caso tendrá un servidor dedicado solo para su sitio.
Por ejemplo, aquí hay una prueba de página realizada con Geekflare, una herramienta gratuita para verificar el rendimiento del sitio . Como puede ver, la herramienta muestra que el TTFB para esta página supera los 600 ms, por lo que debe mejorarse.

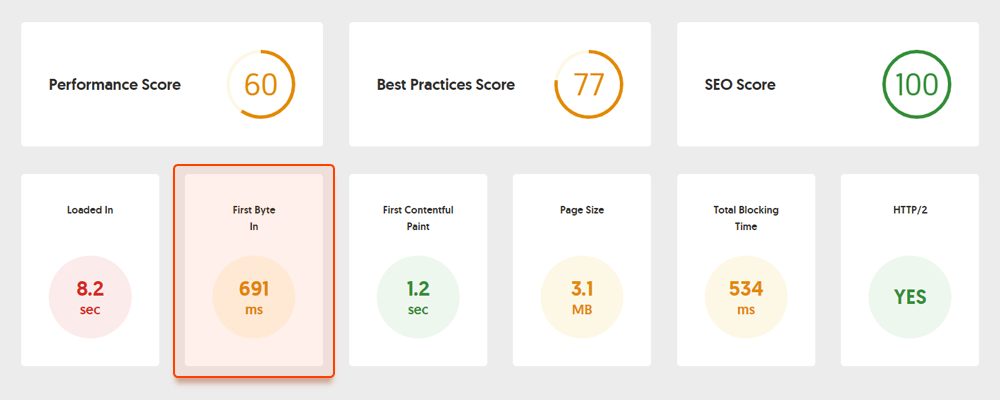
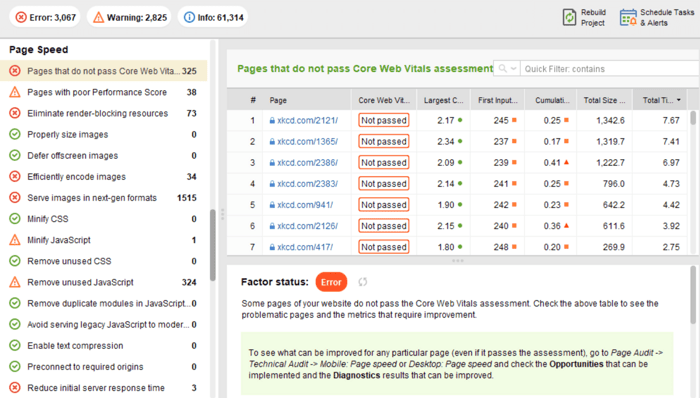
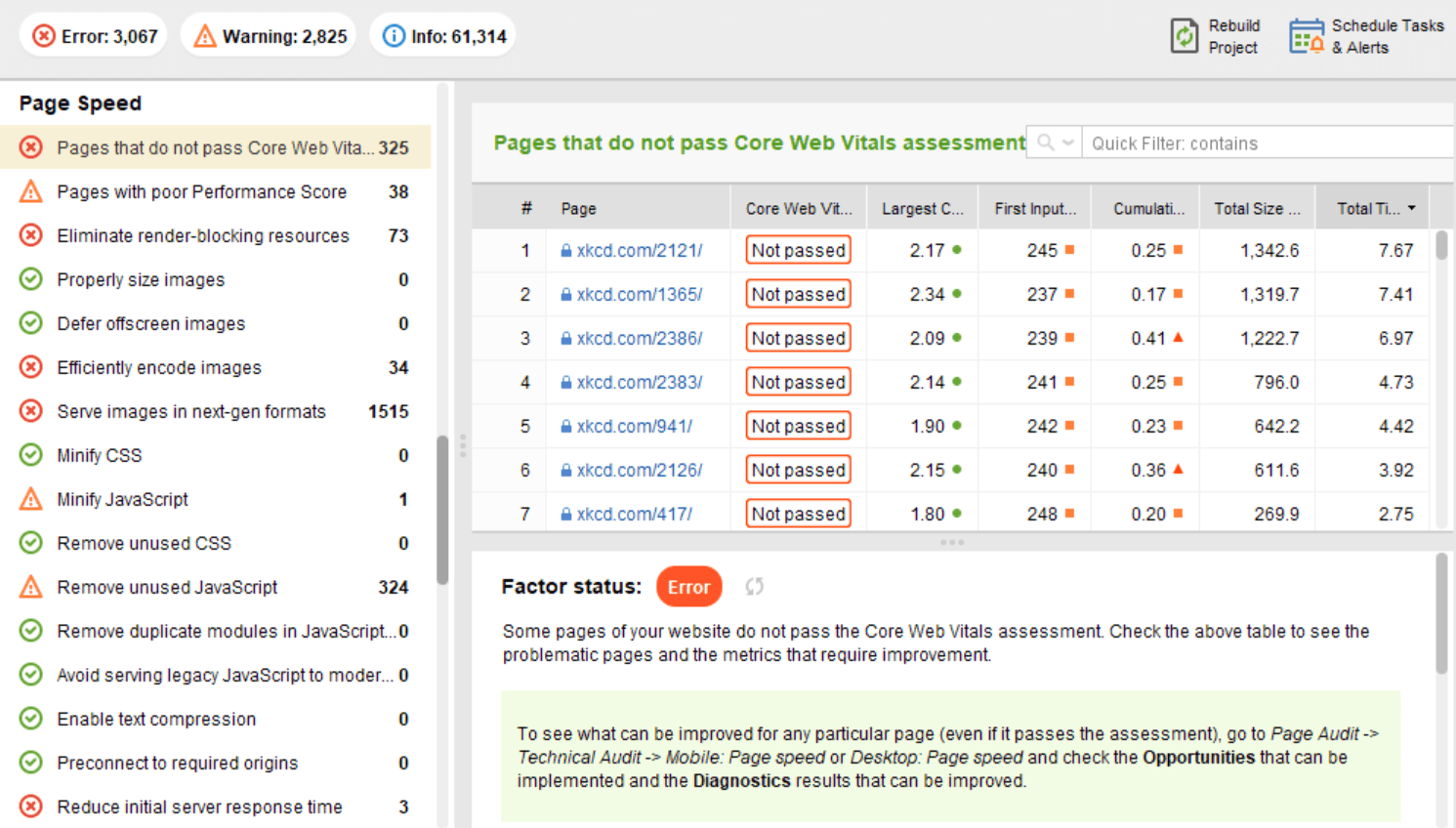
Sin embargo, en el lado del cliente, la velocidad de la página no es algo fácil de medir, y Google ha tenido problemas con esta métrica durante mucho tiempo. Finalmente, llegó a Core Web Vitals, tres métricas diseñadas para medir la velocidad percibida de cualquier página determinada. Estas métricas son Mayor dolor de contenido (LCP), Primera demora de entrada (FID) y Cambio de diseño acumulativo (CLS). Muestran el rendimiento de un sitio web en cuanto a velocidad de carga, interactividad y estabilidad visual de sus páginas web. Si necesita más detalles sobre cada métrica de CWV, consulte nuestra guía sobre Core Web Vitals .
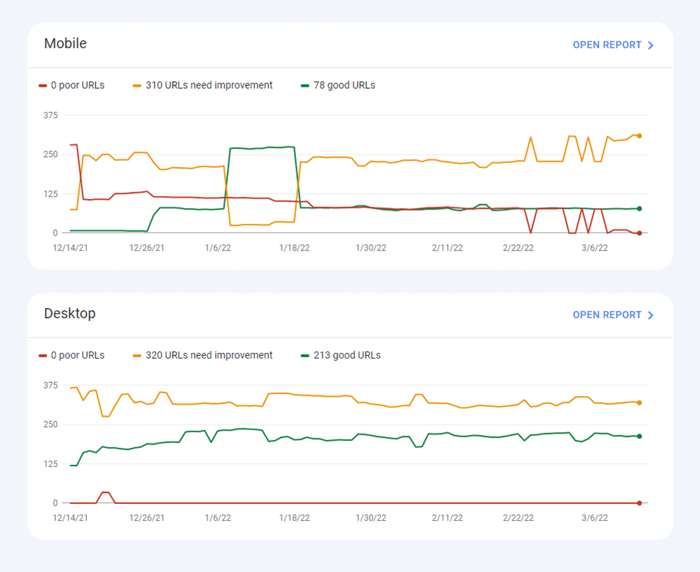
Recientemente, las tres métricas de Core Web Vitals se agregaron a WebSite Auditor . Entonces, si está utilizando esta herramienta, puede ver cada puntuación métrica, una lista de problemas de velocidad de página en su sitio web y una lista de páginas o recursos afectados. Los datos se analizan a través de la clave API de PageSpeed que se puede generar de forma gratuita.
El beneficio de usar WebSite Auditor para auditar CWV es que realiza una verificación masiva de todas las páginas a la vez. Si ve muchas páginas afectadas por el mismo problema, es probable que el problema sea de todo el sitio y se pueda resolver con una sola corrección. Así que en realidad no es tanto trabajo como parece. Todo lo que tiene que hacer es seguir las recomendaciones a la derecha, y la velocidad de su página aumentará en poco tiempo.
Hoy en día, el número de buscadores móviles supera a los de escritorio. En 2019, Google implementó la indexación móvil primero , con el agente de teléfonos inteligentes rastreando sitios web antes que el escritorio de Googlebot. Por lo tanto, la compatibilidad con dispositivos móviles tiene una importancia primordial para las clasificaciones orgánicas.
Sorprendentemente, existen diferentes enfoques para crear sitios web optimizados para dispositivos móviles:
Los pros y los contras de cada solución se explican en nuestra guía detallada sobre cómo hacer que su sitio web sea compatible con dispositivos móviles . Además, puede repasar las páginas de AMP ; aunque no se trata de una tecnología de vanguardia, aún funciona bien para algunos tipos de páginas, por ejemplo, para noticias.
La compatibilidad con dispositivos móviles sigue siendo un factor vital para los sitios web que ofrecen una URL tanto para computadoras de escritorio como para dispositivos móviles. Además, algunas señales de usabilidad, como la ausencia de intersticiales intrusivos, siguen siendo un factor relevante para las clasificaciones de escritorio y móviles. Es por eso que los desarrolladores web deben garantizar la mejor experiencia de usuario en todo tipo de dispositivos.
La prueba de compatibilidad con dispositivos móviles de Google incluye una selección de criterios de usabilidad, como la configuración de la ventana gráfica, el uso de complementos y el tamaño del texto y los elementos en los que se puede hacer clic. También es importante recordar que la compatibilidad con dispositivos móviles se evalúa por página, por lo que debe verificar la compatibilidad con dispositivos móviles de cada una de sus páginas de destino por separado, una a la vez.
Para evaluar todo su sitio web, cambie a Google Search Console. Vaya a la pestaña Experiencia y haga clic en el informe de Usabilidad móvil para ver las estadísticas de todas sus páginas. Debajo del gráfico, puede ver una tabla con los problemas más comunes que afectan a sus páginas móviles. Al hacer clic en cualquier problema debajo del tablero, obtendrá una lista de todas las URL afectadas.
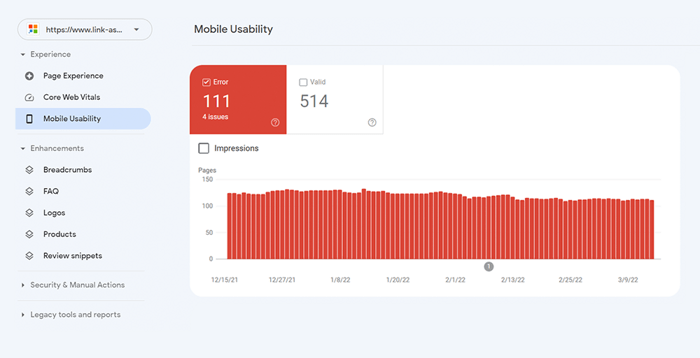

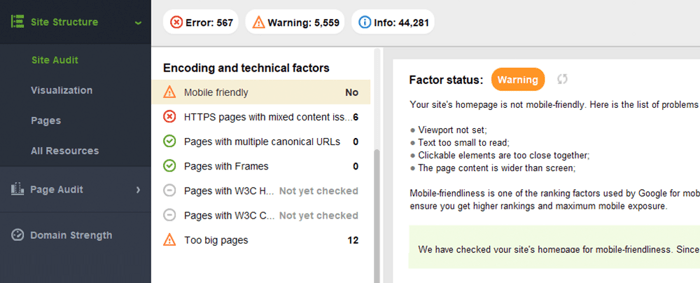
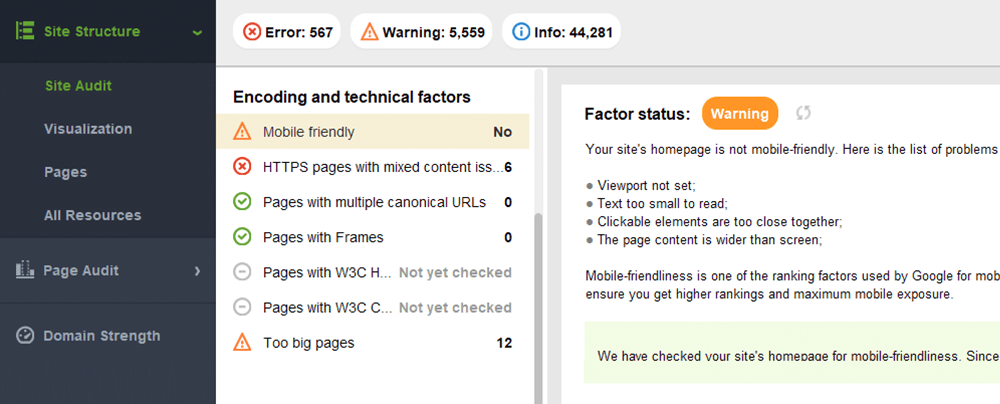
Los problemas típicos de compatibilidad con dispositivos móviles son:
WebSite Auditor también revisa la facilidad de uso móvil de la página de inicio y señala problemas en la experiencia del usuario móvil. Vaya a Auditoría del sitio > Codificación y factores técnicos . La herramienta mostrará si el sitio es compatible con dispositivos móviles y enumerará los problemas, si los hay:
Las señales en la página son factores directos de clasificación y, sin importar cuán buena sea la solidez técnica de su sitio web, sus páginas nunca aparecerán en la búsqueda sin la optimización adecuada de las etiquetas HTML . Por lo tanto, su objetivo es verificar y ordenar los títulos, las metadescripciones y los encabezados H1–H3 de su contenido en su sitio web.
Los motores de búsqueda utilizan el título y la meta descripción para formar un fragmento de resultado de búsqueda. Este fragmento es lo que los usuarios verán primero, por lo que afecta en gran medida la tasa de clics orgánicos .
Los encabezados, junto con los párrafos, las listas con viñetas y otros elementos de la estructura de la página web, ayudan a crear resultados de búsqueda enriquecidos en Google. Además, mejoran naturalmente la legibilidad y la interacción del usuario con la página, lo que puede servir como una señal positiva para los motores de búsqueda. Mantener vigilado:
Duplica títulos, encabezados y descripciones en todo el sitio: corrígelos escribiendo títulos únicos para cada página.
Optimización de los títulos, encabezados y descripciones para los motores de búsqueda (es decir, la longitud, las palabras clave, etc.)
Contenido delgado: las páginas con poco contenido casi nunca se clasificarán e incluso pueden arruinar la autoridad del sitio (debido al algoritmo Panda), así que asegúrese de que sus páginas cubran el tema en profundidad.
Optimización de imágenes y archivos multimedia: use formatos compatibles con SEO, aplique carga diferida, cambie el tamaño de los archivos para hacerlos más ligeros, etc. Para obtener más detalles, lea nuestra guía sobre optimización de imágenes .
WebSite Auditor puede ayudarte mucho con esta tarea. La sección Estructura del sitio > Auditoría del sitio le permite verificar los problemas de metaetiquetas en todo el sitio web de forma masiva. Si necesita auditar el contenido de la página individual con más detalle, vaya a la sección Auditoría de la página . La aplicación también tiene una herramienta de escritura incorporada Editor de contenido que le ofrece sugerencias sobre cómo reescribir páginas en función de sus principales competidores SERP. Puede editar las páginas sobre la marcha o descargar las recomendaciones como una tarea para los redactores.
Para obtener más información, lea nuestra guía de optimización SEO en la página .
Los datos estructurados son un marcado semántico que permite a los robots de búsqueda comprender mejor el contenido de una página. Por ejemplo, si su página presenta una receta de pastel de manzana, puede usar datos estructurados para decirle a Google qué texto son los ingredientes, cuál es el tiempo de cocción, el número de calorías, etc. Google usa el marcado para crear fragmentos enriquecidos para sus páginas en SERP.
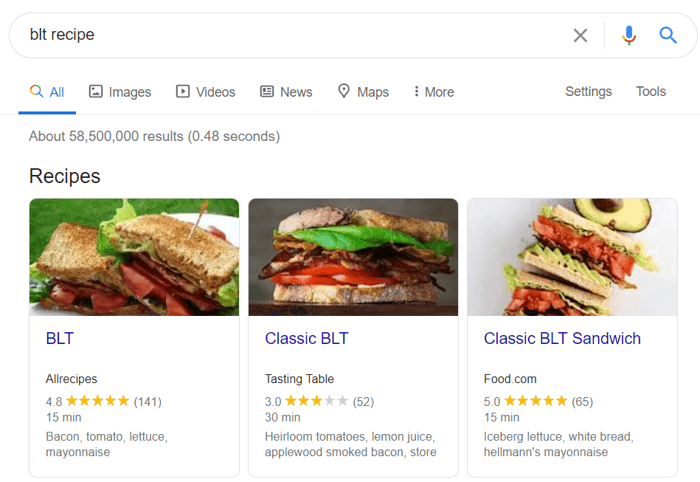
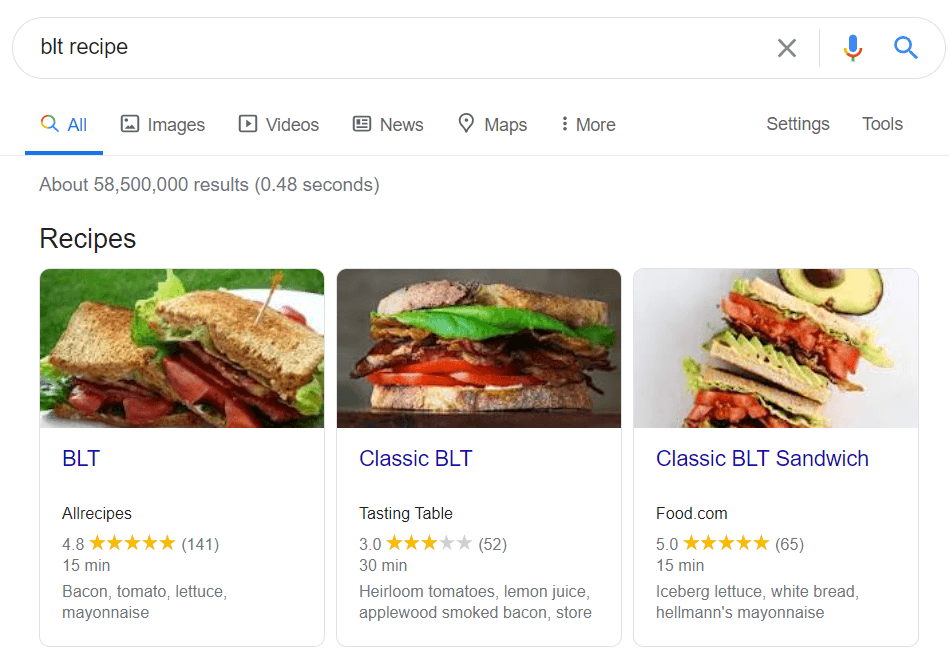
Hay dos estándares populares de datos estructurados, OpenGraph para compartir de forma atractiva en las redes sociales y Schema para los motores de búsqueda. Las variantes de la implementación del marcado son las siguientes: Microdata, RDFa y JSON-LD . Los microdatos y RDFa se agregan al HTML de la página, mientras que JSON-LD es un código JavaScript. Este último es recomendado por Google.
Si el tipo de contenido de su página es uno de los mencionados a continuación, se recomienda especialmente el marcado:
Tenga en cuenta que la manipulación de datos estructurados puede causar penalizaciones de los motores de búsqueda. Por ejemplo, el marcado no debe describir el contenido que está oculto para los usuarios (es decir, que no se encuentra en el HTML de la página). Pruebe su marcado con la Herramienta de prueba de datos estructurados antes de la implementación.
También puede verificar su marcado en Google Search Console en la pestaña Mejoras . GSC mostrará las mejoras que ha intentado implementar en su sitio web y le dirá si ha tenido éxito.
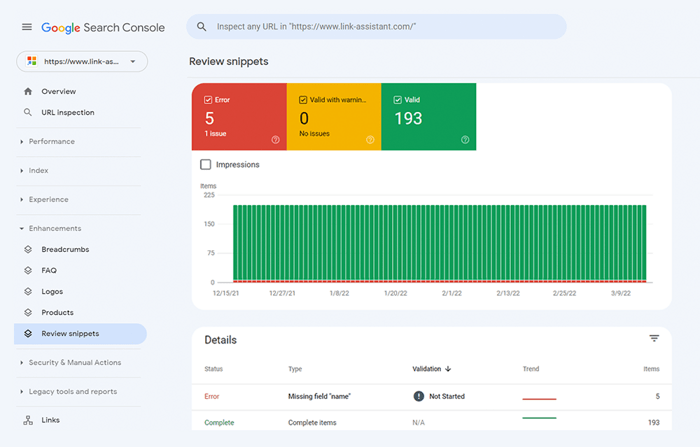
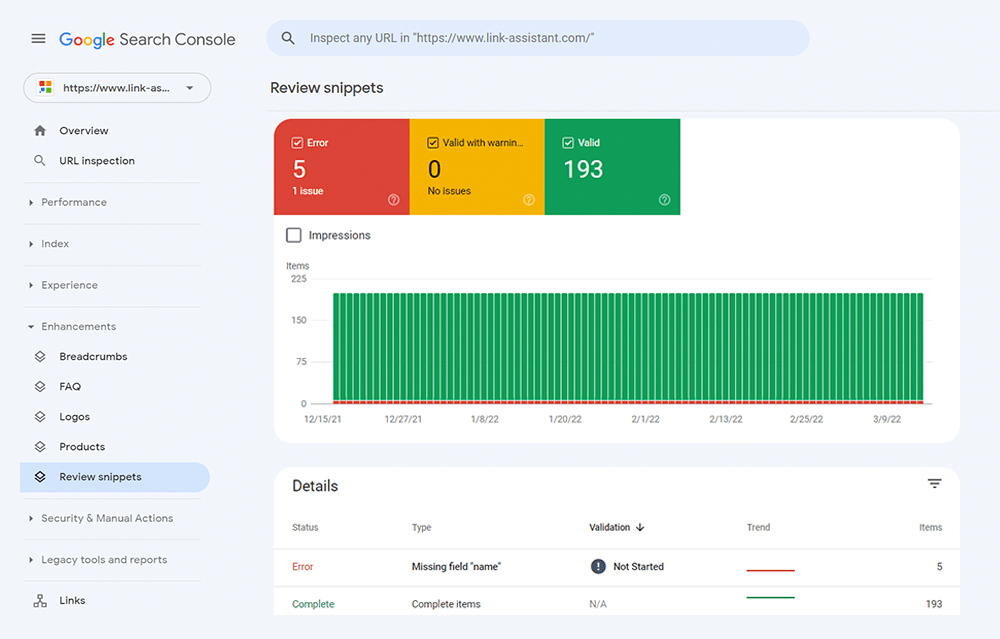
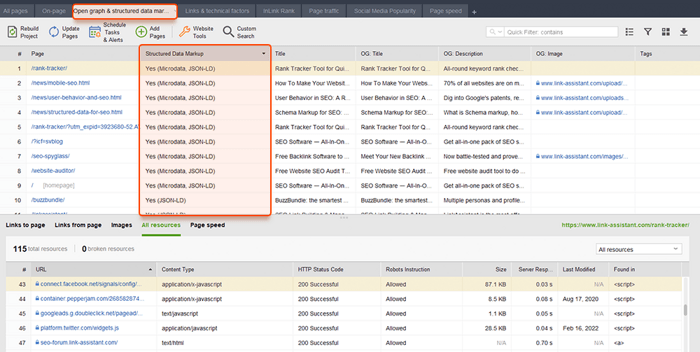
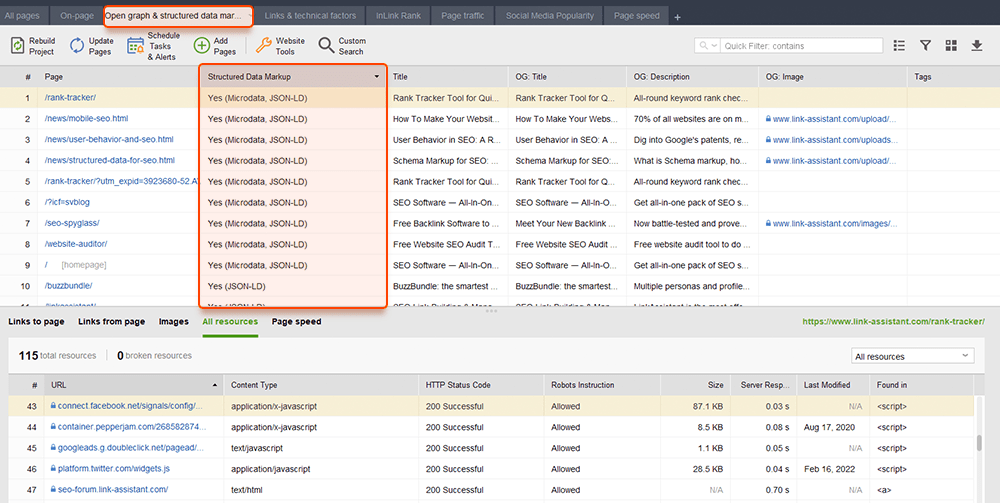
WebSite Auditor también puede ayudarlo aquí. La herramienta puede revisar todas sus páginas y mostrar la presencia de datos estructurados en una página, su tipo, títulos, descripciones y URL de archivos OpenGraph.
Si aún no ha implementado el marcado Schema, consulte esta guía de SEO sobre datos estructurados . Tenga en cuenta que si su sitio web utiliza un CMS, los datos estructurados pueden implementarse de forma predeterminada, o puede agregarlos instalando un complemento (de todos modos, no se exceda con los complementos).
Una vez que audite su sitio web y solucione todos los problemas descubiertos, puede pedirle a Google que vuelva a rastrear sus páginas para que vea los cambios más rápido.
En Google Search Console, envíe la URL actualizada a la herramienta de inspección de URL y haga clic en Solicitar indexación . También puede aprovechar la función Probar URL en vivo (anteriormente conocida como la función Explorar como Google ) para ver su página en su forma actual y luego solicitar la indexación.
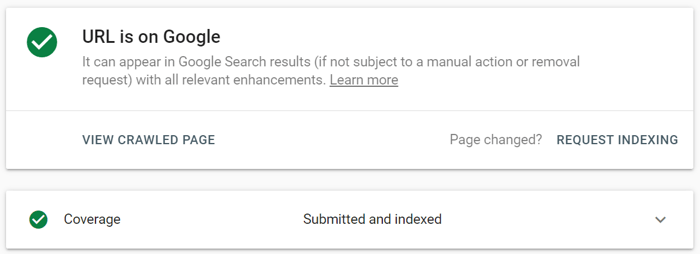
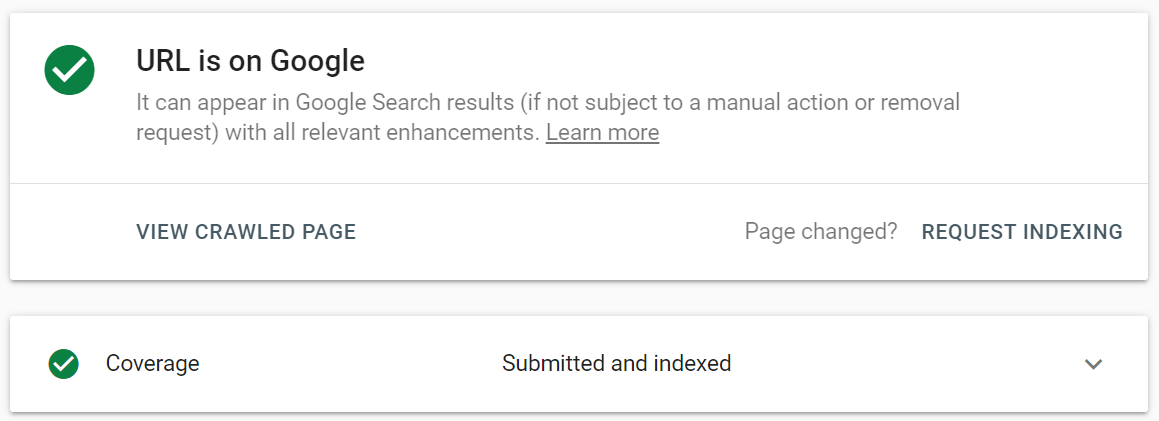
La herramienta de inspección de URL permite expandir el informe para obtener más detalles, probar las URL en vivo y solicitar la indexación.
Tenga en cuenta que en realidad no necesita forzar el rastreo cada vez que cambia algo en su sitio web. Considere volver a rastrear si los cambios son serios: por ejemplo, movió su sitio de http a https, agregó datos estructurados o realizó una excelente optimización de contenido, publicó una publicación de blog urgente que desea que aparezca en Google más rápido, etc. Tenga en cuenta que Google tiene un límite. en la cantidad de acciones de rastreo por mes, así que no abuses. Además, la mayoría de los CMS envían cualquier cambio a Google tan pronto como los realiza, por lo que es posible que no se moleste en volver a rastrear si usa un CMS (como Shopify o WordPress).
Volver a rastrear puede tardar desde unos pocos días hasta varias semanas, según la frecuencia con la que el rastreador visite las páginas. Solicitar un nuevo rastreo varias veces no acelerará el proceso. Si necesita volver a rastrear una gran cantidad de URL, envíe un mapa del sitio en lugar de agregar manualmente cada URL a la herramienta de inspección de URL.
La misma opción está disponible en Bing Webmaster Tools. Simplemente elija la sección Configurar mi sitio en su tablero y haga clic en Enviar URL . Complete la URL que necesita volver a indexar y Bing la rastreará en minutos. La herramienta permite a los webmasters enviar hasta 10 000 URL por día para la mayoría de los sitios.
Muchas cosas pueden suceder en la web, y es probable que la mayoría de ellas afecten su clasificación mejor o peor. Es por eso que las auditorías técnicas periódicas de su sitio web deben ser una parte esencial de su estrategia de SEO.
Por ejemplo, puede automatizar auditorías técnicas de SEO en WebSite Auditor . Simplemente cree una tarea de proyecto de reconstrucción y configure los ajustes de programación (por ejemplo, una vez al mes) para que la herramienta vuelva a rastrear automáticamente su sitio web y obtenga los datos actualizados.
Si necesita compartir los resultados de la auditoría con sus clientes o colegas, elija una de las plantillas de informes SEO descargables de WebSite Auditor o cree una personalizada.
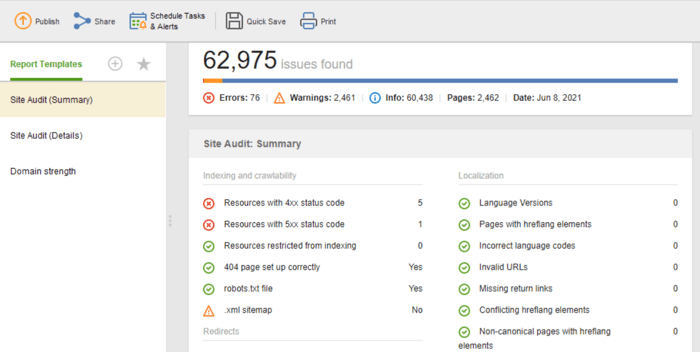
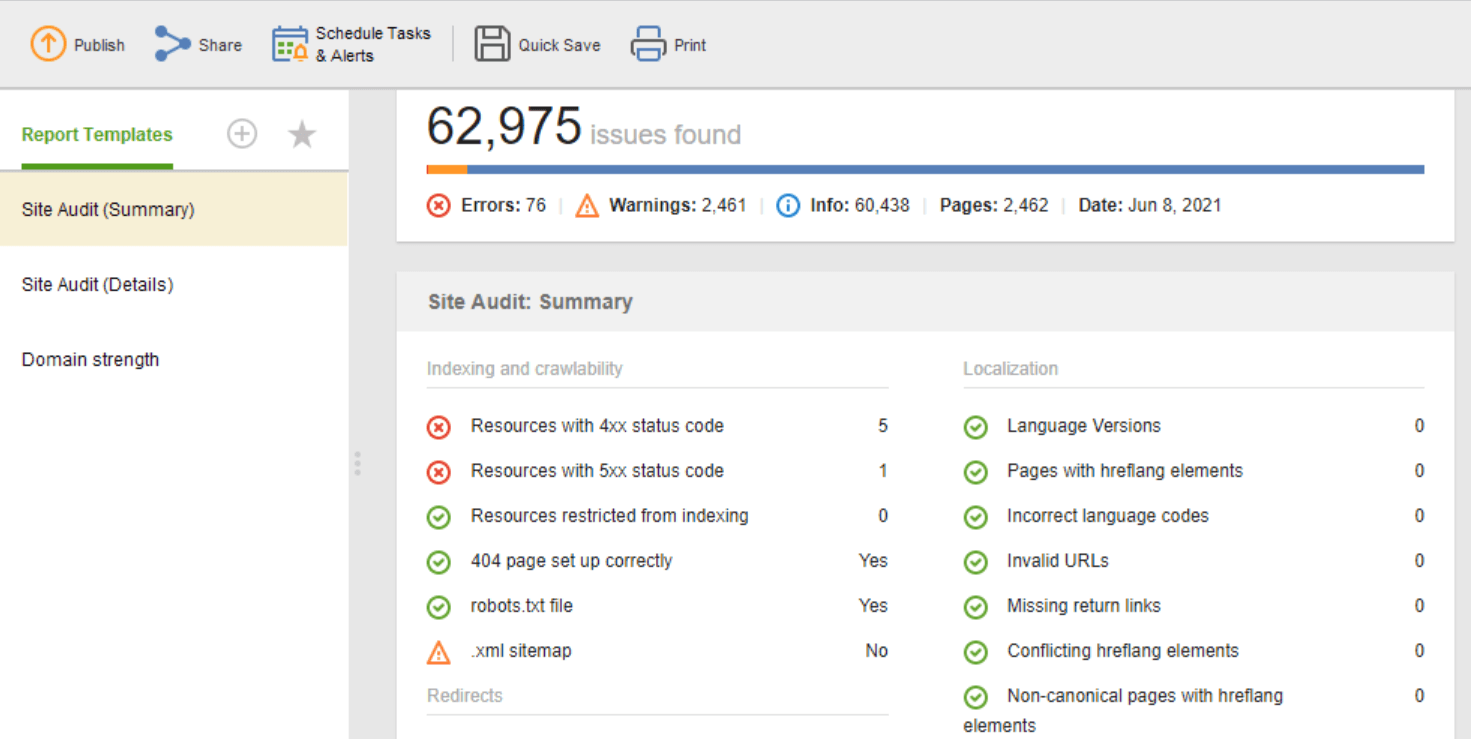
La plantilla Auditoría del sitio (resumen) es excelente para que los editores de sitios web vean el alcance del trabajo de optimización que deben realizar. La plantilla Auditoría del sitio (Detalles) es más explicativa, describe cada problema y por qué es importante solucionarlo. En Website Auditor, puede personalizar el informe de auditoría del sitio para obtener los datos que necesita monitorear regularmente (indexación, enlaces rotos, en la página, etc.). Luego, exporte como CSV/PDF o copie y pegue cualquier dato en una hoja de cálculo a mano. a los desarrolladores para las correcciones.
Además, puede obtener una lista completa de problemas técnicos de SEO en cualquier sitio web recopilados automáticamente en un informe de Auditoría del sitio en nuestro Auditor del sitio web. Además de eso, un informe detallado proporcionará explicaciones sobre cada problema y cómo solucionarlo.
Estos son los pasos básicos de una auditoría técnica regular del sitio. Espero que la guía describa de la mejor manera qué herramientas necesita para realizar una auditoría exhaustiva del sitio, qué aspectos de SEO debe cuidar y qué medidas preventivas debe tomar para mantener una buena salud de SEO de su sitio web.
¿Qué es el SEO técnico?
El SEO técnico se ocupa de la optimización de los aspectos técnicos de un sitio web que ayudan a los robots de búsqueda a acceder a sus páginas de manera más efectiva. El SEO técnico cubre el rastreo, la indexación, los problemas del lado del servidor, la experiencia de la página, la generación de metaetiquetas, la estructura del sitio.
¿Cómo se realiza una auditoría técnica de SEO?
La auditoría técnica de SEO comienza con la recopilación de todas las URL y el análisis de la estructura general de su sitio web. Luego, verifica la accesibilidad de las páginas, la velocidad de carga, las etiquetas, los detalles en la página, etc. Las herramientas técnicas de auditoría de SEO van desde herramientas gratuitas para webmasters hasta arañas de SEO, analizadores de archivos de registro, etc.
¿Cuándo necesito auditar mi sitio?
Las auditorías técnicas de SEO pueden perseguir diferentes objetivos. Es posible que desee auditar un sitio web antes del lanzamiento o durante el proceso de optimización en curso. En otros casos, es posible que esté implementando migraciones de sitios o desee levantar las sanciones de Google. Para cada caso, el alcance y los métodos de las auditorías técnicas serán diferentes.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |