Rank Tracker User Manual
Rank Tracker User Manual WebSite Auditor User Manual
WebSite Auditor User Manual SEO SpyGlass User Manual
SEO SpyGlass User Manual LinkAssistant User Manual
LinkAssistant User Manual
- Rank Tracker User Manual
- WebSite Auditor User Manual
- SEO SpyGlass User Manual
- LinkAssistant User Manual
Crawler Settings
WebSite Auditor is equipped with a powerful SEO spider that crawls your site just like search engine bots do.
Not only it looks at your site's HTML, but also sees your CSS, JavaScript, Flash, images, videos, PDFs, and other resources, both internal and external, and shows you how all pages and resources interlink. This allows you to see the whole picture and make decisions based on the complete comprehensive data.
Crawler settings can be tailored to your needs and preferences: for instance, to collect or exclude certain sections of a site, crawl a site on behalf of any search engine bot, find pages that are unlinked from site, etc. To configure the settings, simply tick Enable expert options box once you are creating a project.
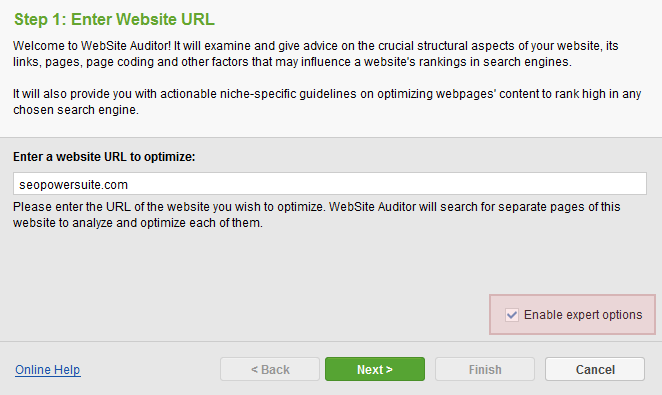
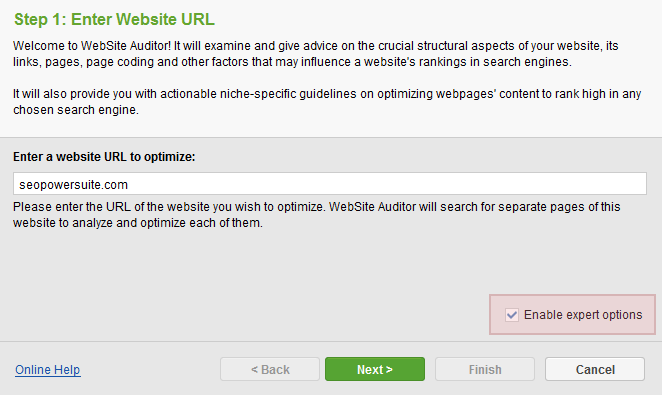
In Step 2 you’ll be able to specify crawler settings for the current project.
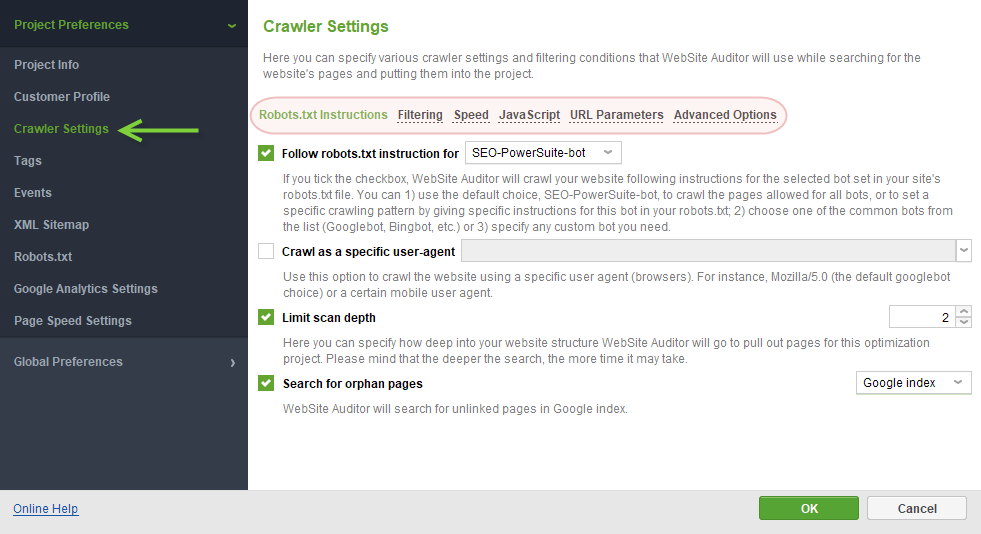
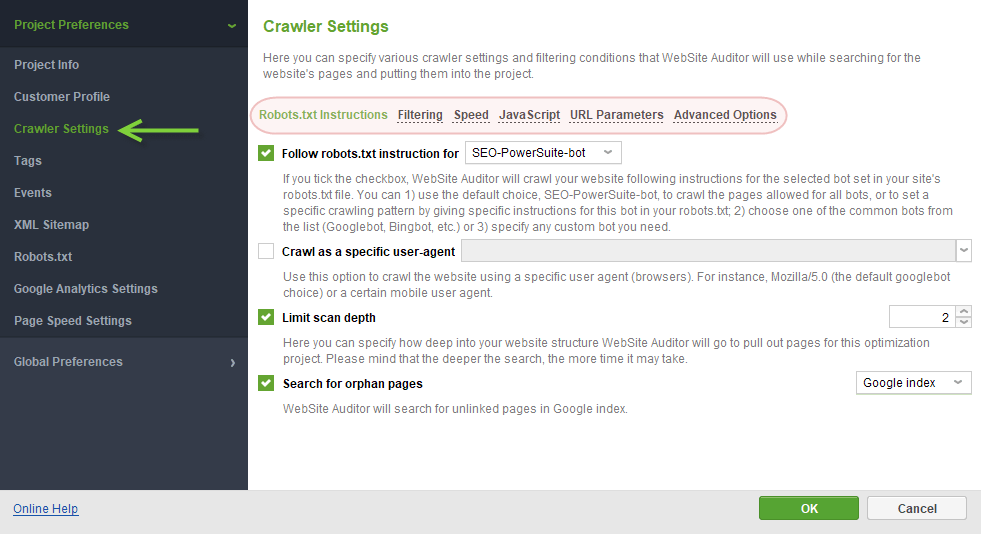
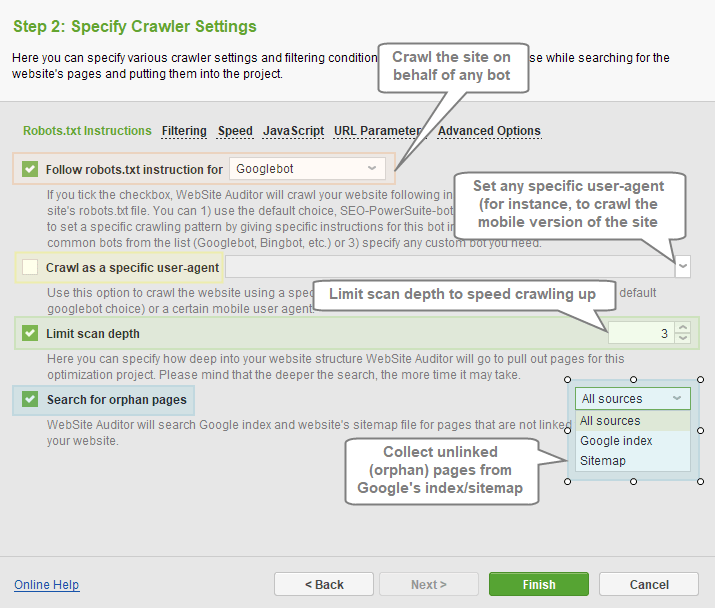
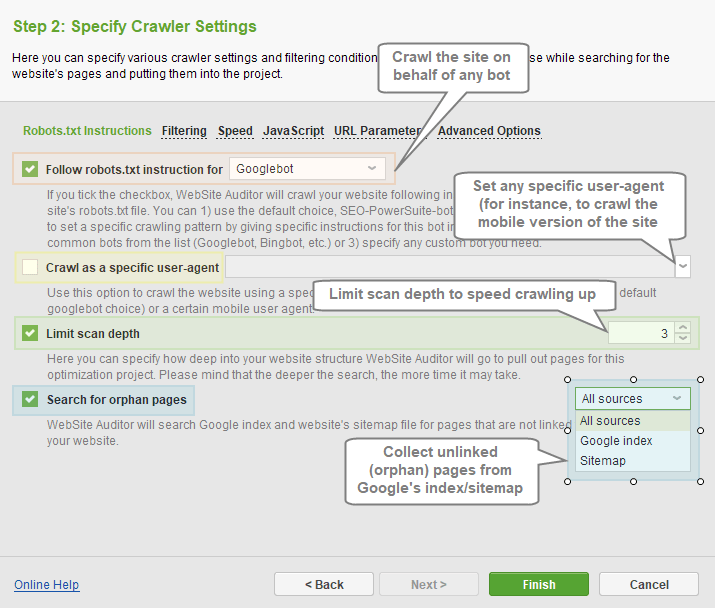
Robots.txt Instructions section features the following settings:
- Follow robots.txt instructions: lets you crawl a site following robots instructions, either for all spiders or any specific bot of your choice (from the dropdown menu).
- Crawl as a specific user-agent: allows to crawl the site using a specific user agent (including mobile agents).
- Limit scan depth: controls how deep into your site’s structure the tool should go to pull the pages for the project. The deeper the search is, the more time the crawl may take.
- Search for orphan pages: allows to collect pages that are not linked to the site, but are present either in Google’s index, or in your Sitemap, or both. Orphan pages will receive corresponding tags in the project, showing the source they were found in.
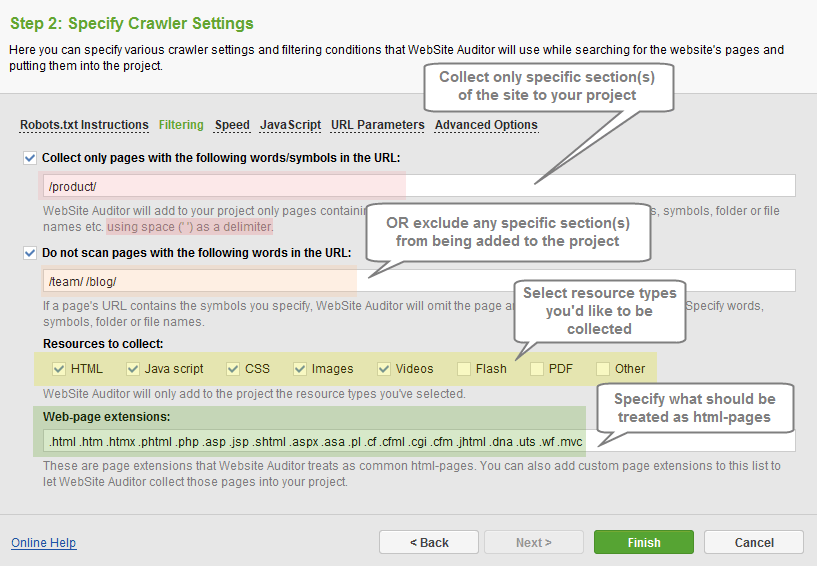
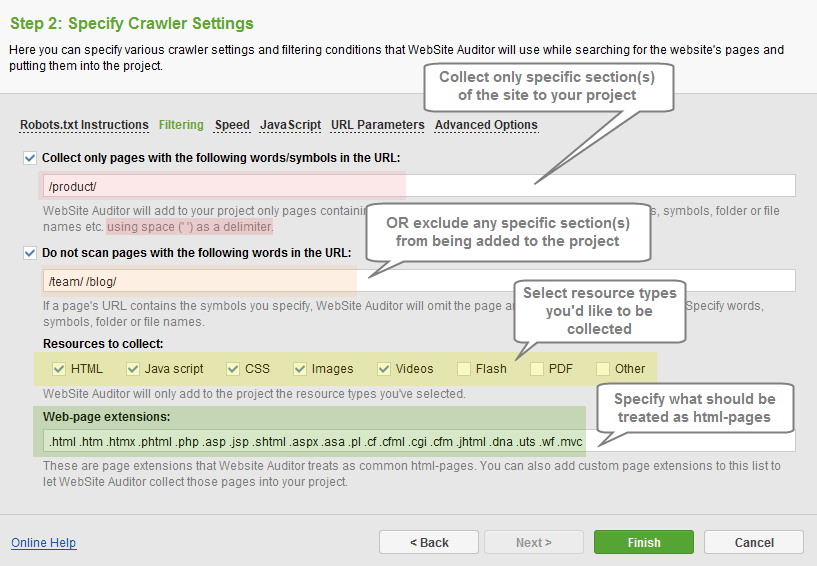
In the Filtering section you can specify various filtering conditions WebSite Auditor will use while collecting pages and resources to your project.
- Collect only pages with the following words/symbols in the URL: only the pages containing specific words/symbols in URLs will be added to your project. Symbols, words, file or category names should be entered using a single space (‘ ‘) as a delimiter.
- Do not scan pages with the following words in the URL: pages containing specific words/symbols in URLs will be excluded from your project. Please note the program will have to crawl the site in full, as the pages to be excluded may contain links to pages that don’t match the conditions; unnecessary pages simply won’t be loaded into the project once the crawl is complete.
- Resources to collect: check or uncheck the types of resources to be collected to the project.
- Web-page extension: specify what should be treated as common html pages. Add custom extensions to let the tool collect those pages into the project.
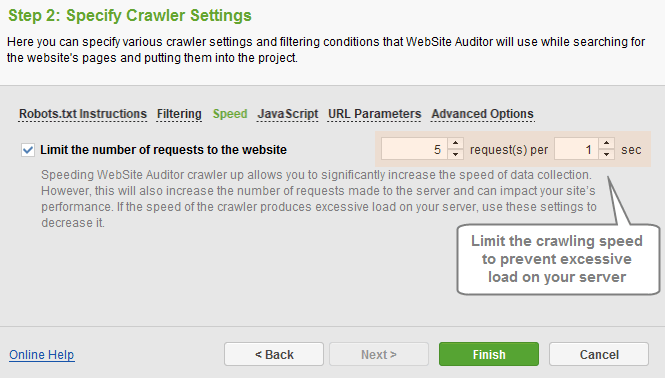
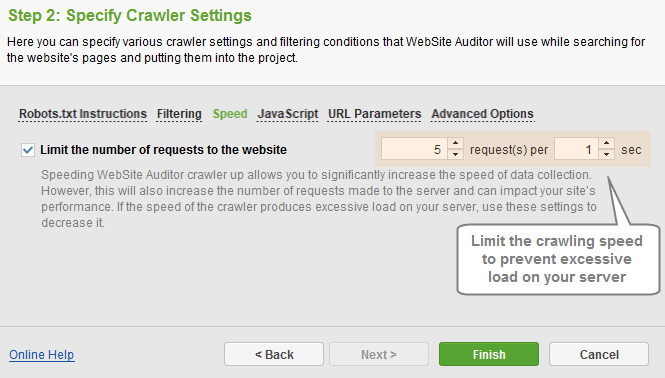
The Speed section allows limit the number of requests to the website, to decrease the load on the server. This prevents slower sites (or sites with high security restrictions) from blocking the crawler.
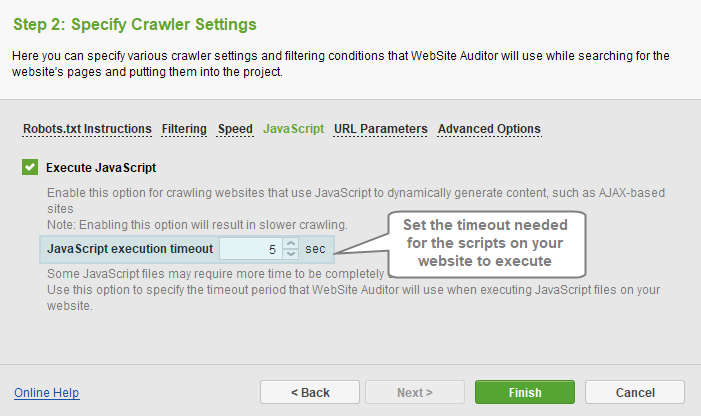
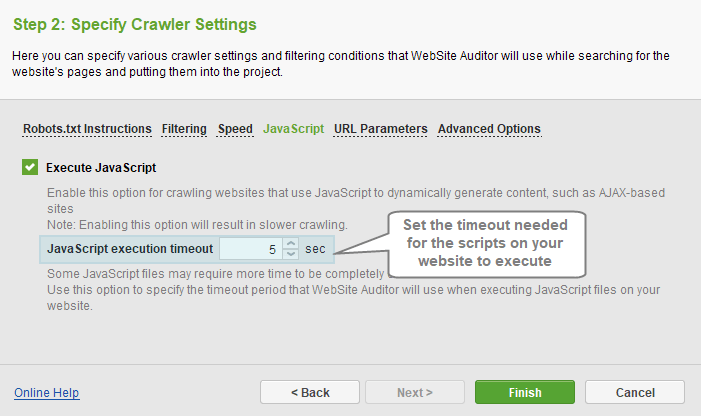
In the JavaScript section, you can control whether the app should execute the scripts while crawling your website pages - this will allow crawling websites built with Ajax, for instance, and/or parsing any script-generated content in full.
- Enable JavaScript to execute scripts.
- Set the timeout long enough for your scripts to be executed.
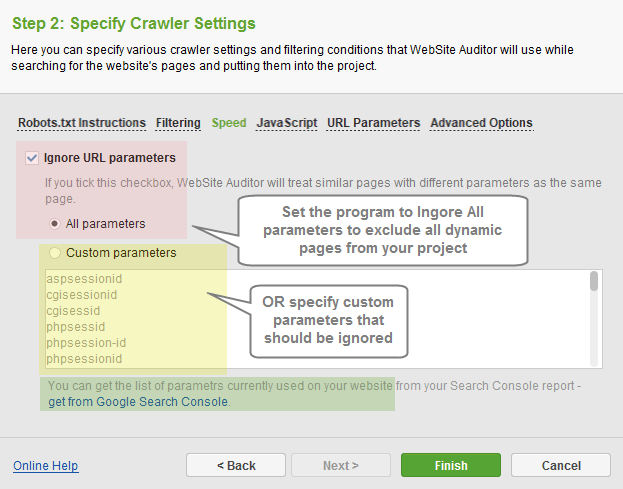
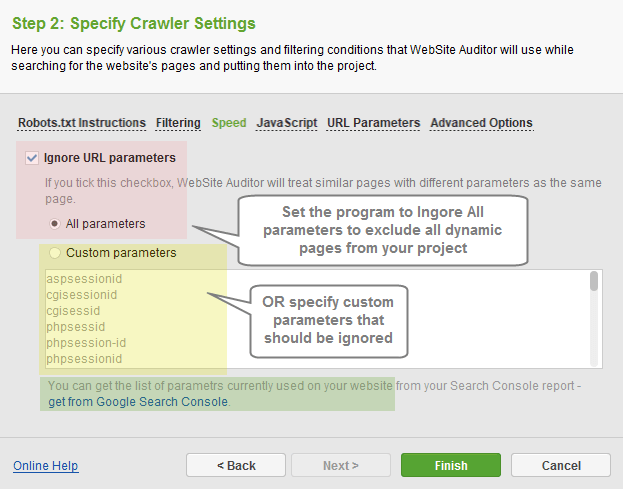
In the URL Parameters section, you can specify whether the program should collect the dynamic pages.
- Disable the option to collect all dynamically generated pages with parameters in URLs into your project.
- Set the program to Ignore All parameters to treat all similar pages with different parameters as the same page (no dynamic pages will be collected).
- Specify Custom parameters that should be ignored (optionally, get the list of parameters used on your site from your Google Search Console account).
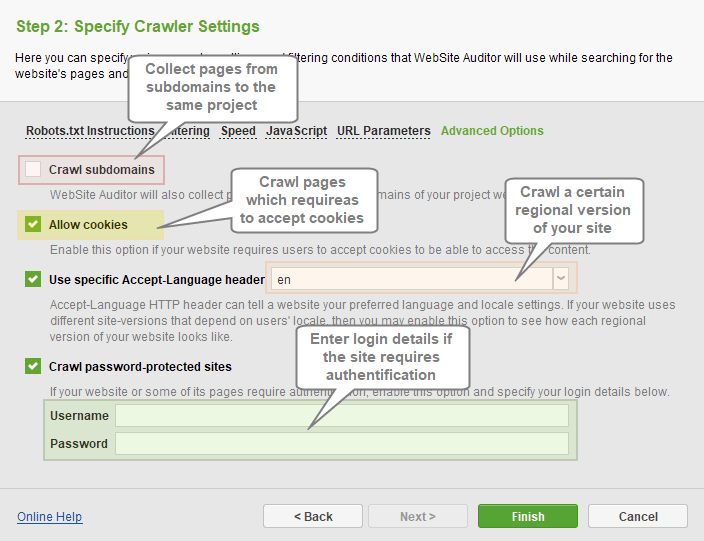
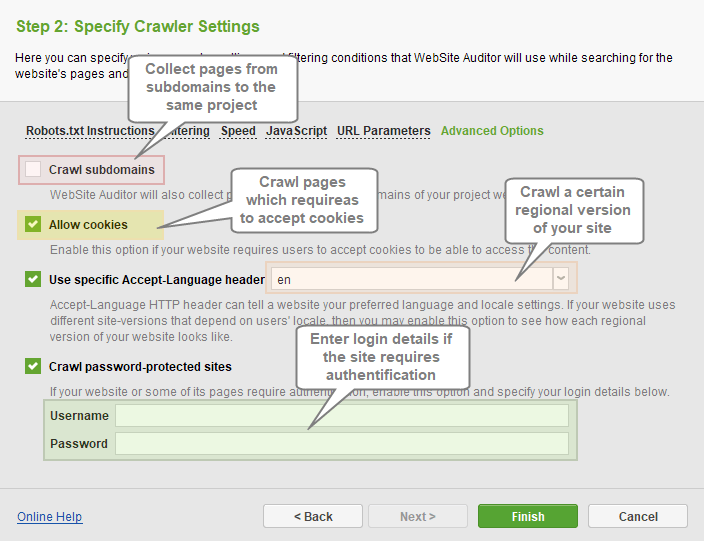
Advanced Options section contains additional crawler settings such as:
- Crawl Subdomains: WebSite Auditor will collect pages that belong to subdomains of your project domain.
- Allow cookies: this will allow you to crawl a website that requires users to accept cookies.
- Use specific Accept-Language header: allows you to crawl certain regional versions of your site.
- Crawl password-protected sites: allows you to enter login credentials if your site or some of its pages require authentication.
After configuring Crawler Settings, hit Finish for the program to start crawling your site. The settings can be accessed and changed any time later under ‘Preferences > Crawler Settings’ in each project.